1 | 史上最全大数据笔记-HDFS
最近几年,IT行业最火的名词中,少不了"大数据"、"人工智能"、"云计算"、"物联网"、"区块链"等等这些名词。针对于"大数据"这个名词,现在更是全国老百姓,老少皆知的一个词语。但是什么是大数据,除了IT行业的专业人士外,其他人乃至其他行业的人,除了能说出"数据量大"之外,好像真的不能再更深层次的解释了。维基百科:数据规模巨大到无法通过人工在合理的时间内达到截取,管理,处理并整理成为人类所解读的信
一、内容回顾
请一边努力,一遍快乐!!!
二、目标
2.1. 重点
-
完全分布式集群搭建
-
HDFS的Shell操作
-
HDFS的块的概念
-
HDFS的工作机制
-
HDFS的读写流程
2.2. 难点
-
完全分布式集群搭建
-
检查点机制
-
HDFS的读写流程
三、导读
Hadoop是大数据中非常基础,也非常重要的一个框架。是我们入门学习大数据课程必须要掌握的框架。我们要知道,我们开发人员要处理的数据量非常的庞大,通常是以TB、PB甚至EB为量级单位的。那么这么庞大的数据,我们应该如何高效率的去进行存储和读取呢?我们应该如何去处理这些数据呢?这些问题都可以在Hadoop中得到解决!
Let's go!
四、内容
4.1. 大数据简介【了解】
4.1.1. 什么是大数据
最近几年,IT行业最火的名词中,少不了"大数据"、"人工智能"、"云计算"、"物联网"、"区块链"等等这些名词。针对于"大数据"这个名词,现在更是全国老百姓,老少皆知的一个词语。但是什么是大数据,除了IT行业的专业人士外,其他人乃至其他行业的人,除了能说出"数据量大"之外,好像真的不能再更深层次的解释了。那么我们来看看下面几个权威机构给出的解释:
维基百科: 数据规模巨大到无法通过人工在合理的时间内达到截取,管理,处理并整理成为人类所解读的信息。
麦肯锡全球研究所: 一种规模大到在获取、存储、管理、分析方面都大大超出了传统数据库软件工具能力范围的数据集合。
高德纳: 需要新的处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
不同的权威机构给出了不同的概念定义,但是这些概念是大同小异的。我们提炼出来这些机构给出的定义中的共同点,总结如下:
海量数据,具有高增长率、数据类型多样化、一定时间内无法使用常规软件工具进行捕捉、管理和处理的数据集合。
4.1.2. 大数据的特征
早在1980年,著名未来学家托夫勒在其所著的《第三次浪潮》中就热情地将“大数据”称颂为“第三次浪潮的华彩乐章”。《自然》杂志在2008年9月推出了名为“大数据”的封面专栏。从2009年开始“大数据”才成为互联网技术行业中的热门词汇。最早应用“大数据”的是世界著名的管理咨询公司麦肯锡公司,它看到了各种网络平台记录的个人海量信息具备潜在的商业价值,于是投入大量人力物力进行调研, 对“大数据”进行收集和分析的设想,在2011年6月发布了关于“大数据”的报告,该报告对“大数据”的影响、关键技术和应用领域等都进行了详尽的分析。麦肯锡的报告得到了金融界的高度重视,而后逐渐受到了各行各业关注。 那么大数据到底有什么特征呢?我们怎么去理解大数据呢?有专业人士总结了4V说法,也有相关机构总结了5V说法,甚至6V说法。不管哪种说法,下面四个特征,是大家普遍认可的。
-
Volume: 数据量非常庞大
-
Variety: 数据类型多样化,组成庞大的数据集的数据,有结构化的、半结构化的和非结构化的数据
-
Velocity: 数据增长的速度非常快
-
Value: 数据的价值密度低
4.1.3. 大数据的应用场景
时至今日,大数据已经在生活的各行各业中都有应用了,在各个领域中影响着我们的生活。这里列举了一些常见的场景:
-
OFO故障报警
- 星期天,我扫一UFO,刚扫完..... - 一黄框蹦跶出来,温馨提示:"编号***车16人已上报维修,左侧脚踏板可能已坏,建议您换一辆,以免影响您行程" - 差点影响俺见富婆的速度,点赞赞赞
-
杀熟外卖会员
-《我被美团会员割了韭菜》爆料称,在美团上的同一家店铺,统一配送地址,同一时间点单,会员配送费仍为6元,而非会员账号仅为2元。此外不仅是一家店有这种情况,一部开通美团会员的手机,附近几乎所有外卖商户的配送费都要超出非会员配送0.5-1倍。 - 你被某团会员割韭菜了吗? - 外卖时,什么都相同,会员比非会员配送费贵3倍。有你吗? - 你开通某外卖会员的手机,附近几乎所有外卖商户配送费贵了几块呢?
-
苹果打车比安卓贵吗
- 约车,你被舒适了吗? - 假期,孙教授带一帮弟兄,去北、上、深、成和重5座城市,以不同距离、工作日早晚高峰、日间非高峰和晚间非高峰4个时间段进行了分层抽样调查。 - 一共采样821个样本。其中,苹果手机样本占比1/3,安卓手机占比2/3,和现实生活中苹果、安卓手机的占比基本一致。 - 最后选取233个样本进行调查,结果发现苹果手机“被舒适”的比例比非苹果手机高,高出3倍。 - 苹果手机支付时平均获取2.07优惠,非苹果手机用户平均优惠是4.12元。优惠折扣低了1半
-
啤酒和尿不湿的故事
- 周末,已婚小明来到全球零售巨头沃尔玛,溜达溜达,买打啤酒 - 咦,还有尿不湿,顺便给娃带包尿不湿 - 强大数据分析发现,买啤酒的很多还买尿不湿。从此,啤酒+尿不湿组合卖,销量果真与日俱增 - 这就是啤酒+尿不湿的故事 - 由于受启发,于是有了红酒+??
-
猜你喜欢
- 又是无聊一天,小A和小B又开始冲浪...... - 小A:打开百度浏览器,随意搜索,左右、上下都是千锋大数据、好程序员大数据等小广告 - 小B:打开,随意搜索,居然满屏的亚洲、欧美、一堆羞羞 - 小A说我喜欢大数据,我喜欢千锋,我信 - 小B说我喜欢大数据,我喜欢千锋,我信。他说他不喜欢日本片、不喜欢欧美片,你们信吗?我信你个鬼
-
贷款要看大数据
- 专员:个人征信好么? - 我:这是征信 - 专员:还行 或者 (拖二连三贷不了) - 专员:个人大数据咋样呀? - 大数据是指您个人的生活,工作,消费习惯,网贷,网购,网上搜索内容等等,覆盖到您的方方面面。 - 专员:比如信用百分百查大数据征信-108项深度检测,信用风险早预防 - 专员:主要是怕还款不稳定,怕坏账
-
马云给各省女性罩杯的排名
- 你们都知道全中国胸罩最大的 - 女的叫Bra是吧,是那几个省? - 我这儿都有 - 最小的是那几个,知道吧? - 浙江省 ......浙江网友表示不服 - C罩杯及以上尺寸所占购买比例最大的地区依次是:新疆、香港、北京、云南和山西,它们因而被视为女性平均胸围最大的地区。
4.1.4. 大数据的发展前景
大数据技术目前正处在落地应用的初期,从大数据自身发展和行业发展的趋势来看,大数据未来的前景还是不错的,具体原因有以下几点:
-
大数据本身的价值体现
本身的数据价值化就会开辟出很大的市场空间。目前在互联网领域,大数据技术已经得到了较为广泛的应用。 大数据造就了新兴行业。
-
大数据推动了科技领域的发展
不仅体现在互联网领域,还体现在金融、教育、医疗等诸多领域,尤其是现在的人工智能。
-
大数据产业链的形成
经过近些年的发展,大数据已经初步形成了一个较为完整的产业链,包括数据采集、整理、传输、存储、分析、呈现和应用,众多企业开始参与到大数据产业链中,并形成了一定的产业规模,相信随着大数据的不断发展,相关产业规模会进一步扩大。
-
国家大力扶持大数据行业的发展
-
高校大数据专业井喷发展
4.1.5. 企业大数据的一般处理流程
4.1.5.1. 数据源
数据的来源有如下内容: - 关系型数据库 * 各种关系表,如订单表、账号表、基本信息表 - 日志文件 * 用户行为数据 * 浏览了哪些页面(网页、App、电视机顶盒),导航栏上的哪些选项等等 - 三方数据 * 第三方的接口提供数据 * 爬虫等
4.1.5.2. 数据采集或者同步
常用数据采集导入框架: - sqoop: 用于RDBMS与HDFS之间数据导入与导出 - flume: 采集日志文件数据,动态采集日志文件,数据流 flume采集到的数据,一份给HDFS,用于做离线分析;一份给Kafka,实时处理 - kafka: 主要用于实时的数据流处理 flume与kafka都有类似消息队列的机制,来缓存大数据环境处理不了的数据
4.1.5.3. 数据存储
常用数据存储框架 - HDFS、 HBase、ES
4.1.5.4. 数据清洗
即对数据进行过滤,得到具有一定格式的数据源 常用框架(工具):MapReduce、Hive(ETL)、SparkCore、sparksql等
4.1.5.5. 数据分析
对经过数据清洗后的数据进行分析,得到某个指标 常用框架(工具):MapReduce、Hive、SparkSQL、impala(impa:le)、kylin
4.1.5.6. 数据展示
即将数据分析后的结果展示出来,也可以理解为数据的可视化、以图或者表具体的形式展示出来 常用工具: metastore、Javaweb、hcharts、echarts
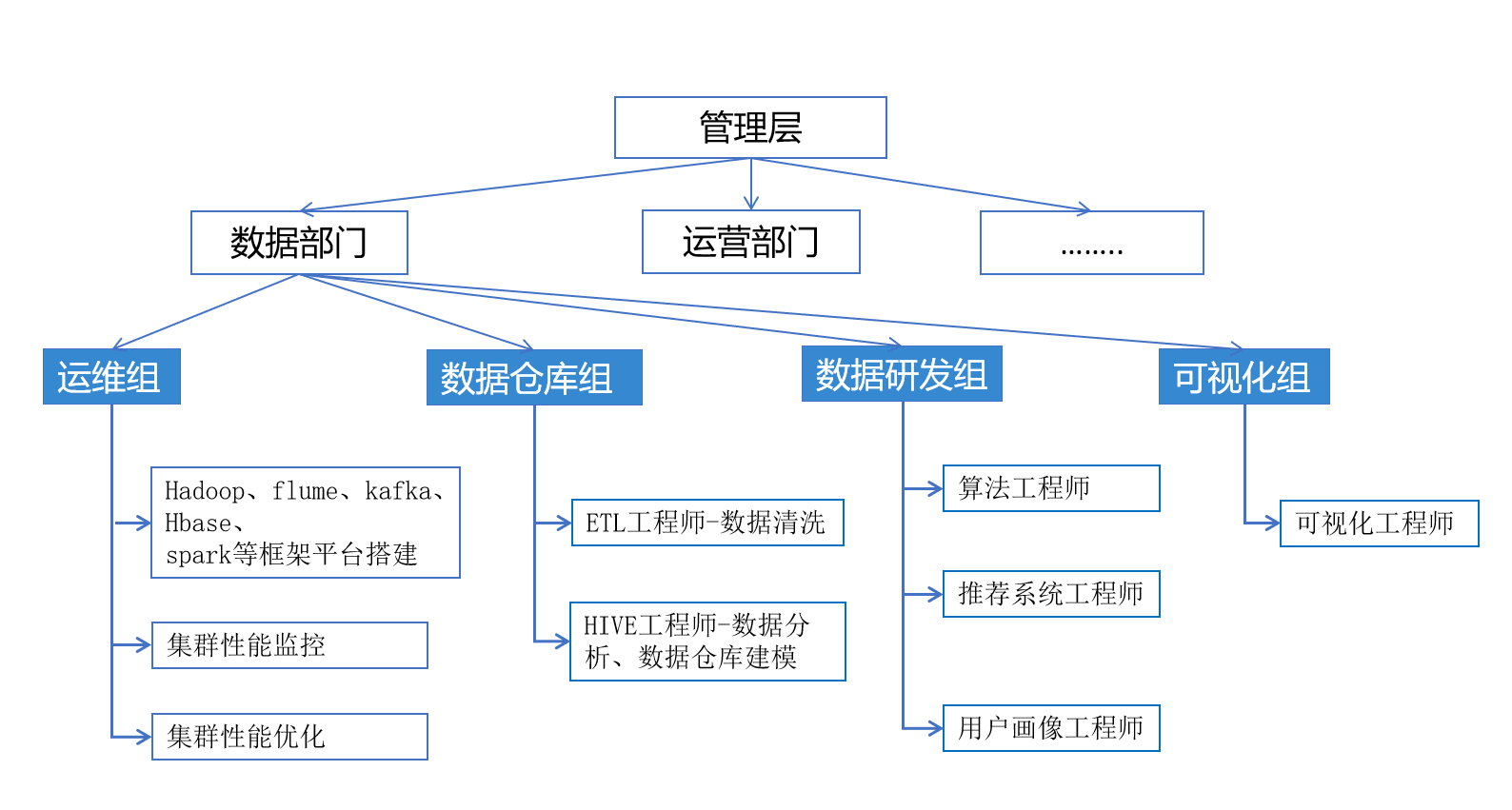
4.1.6. 数据部门的组织架构

4.1.7. 云计算的概念
4.1.7.1. 概念
云计算是以虚拟技术为核心,进行统一管理硬件设施,平台,软件等;它通过网络提供了可伸缩的、廉价的分布式计算能力;它用出租的方式提供给用户,用户只要花低价,在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源;类似于国家统一管理水,电,煤气等等。
4.1.7.2. 云计算的种类
- 公有云:公有云面向所有用户提供服务,只要是注册付费的用户都可以使用 - 私有云:私有云只为特定用户提供服务 - 混合云:混合云综合了公有云和私有云的特点
4.1.7.3. 服务的种类
-1. IaaS(基础设施即服务):IaaS将基础设施(计算资源和存储)作为服务出租。 在这种服务模型中,普通用户不用自己构建一个数据中心等硬件设施,而是通过租用的方式,利用 Internet从IaaS服务提供商获得计算机基础设施服务,包括服务器、存储和网络等服务。 举个例子:假如你现在要做一个网站,你肯定要有一台服务器或者虚拟机,要么自己搭建,要么买服务器运营商的。说白了,IaaS就是解决企业硬件问题的,包括服务器、存储设备、网络设备等基础设施。基础设施有了,你就可以搭建环境了。 -2. PaaS(平台即服务):PaaS把平台作为服务出租 举个例子:假如你现在要做一个网站,你不想自己买服务器搭环境,你就直接购买别人的PaaS服务。PaaS一般会为企业解决硬件的租赁问题,以及操作系统的选装,开发测试环境的搭建,及各种编程语言的选装等,提供一个运行的直接用的软件平台。有了PaaS你就可以在上面做开发工作了,当然,一些别的程序及软件还得你自己安装配置。 -3. SaaS(软件即服务)。SaaS把软件作为服务出租。 举个例子:你现在想做一个网站,你不会做,你只要购买别人的成熟软件,配置几下就能使用了。说白了就是卖软件的,你不用租用服务器,开发软件等费时间的工作,你直接购买别人的软件通过互联网就能使用,也不需要本地安装,也就是软件即服务的意思,你出钱,别人出软件服务。
4.1.7.4. 云计算的关键技术
-1. 虚拟化 云计算的核心技术之一就是虚拟化技术。所谓虚拟化,是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。 虚拟化的核心软件VMM,是一种运行在物理服务器和操作系统之间的中间层软件。VMM是一种在虚拟环境中的“元”操作系统。他们可以访问服务器上包括CPU、内存、磁盘、网卡在内的所有物理设备。VMM不但协调着这些硬件资源的访问,也同时在各个虚拟机之间施加防护。当服务器启动并执行VMM时,它会加载所有虚拟机客户端的操作系统同时会分配给每一台虚拟机适量的内存,CPU,网络和磁盘。 -2. 分布式存储 云计算的另一大优势就是能够快速、高效地处理海量数据。在数据爆炸的今天,这一点至关重要。为了保证数据的高可靠性,云计算通常会采用分布式存储技术,将数据存储在不同的物理设备中。这种模式不仅摆脱了硬件设备的限制,同时扩展性更好,能够快速响应用户需求的变化。 分布式存储与传统的网络存储并不完全一样,传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。 在当前的云计算领域,Google的GFS和Hadoop开发的开源系统HDFS是比较流行的两种云计算分布式存储系统。 GFS(GoogleFileSystem)技术:谷歌的非开源的GFS(GoogleFileSystem)云计算平台满足大量用户的需求,并行地为大量用户提供服务。使得云计算的数据存储技术具有了高吞吐率和高传输率的特点。 HDFS(HadoopDistributedFileSystem)技术:大部分ICT厂商,包括Yahoo、Intel的“云”计划采用的都是HDFS的数据存储技术。未来的发展将集中在超大规模的数据存储、数据加密和安全性保证、以及继续提高I/O速率等方面 -3. 分布式计算 问题分解为若干小问题,分配给各个计算机再综合起来 -4. 多租户
4.1.8. 物联网的概念
4.1.8.1 概念
物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人员和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
4.1.8.2 物联网关键技术
物联网是物与物相连的网络,通过为物体加装二维码、RFID标签、传感器等,就可以实现物体身份唯一标识和各种信息的采集,再结合各种类型网络连接,就可以实现人和物、物和物之间的信息交换。因此,物联网中的关键技术包括识别和感知技术(二维码、RFID、传感器等)、网络与通信技术、数据挖掘与融合技术等。
4.1.8.3 扩展
射频识别(RFID)是 Radio Frequency Identification 的缩写。其原理为阅读器与标签之间进行非接触式的数据通信,达到识别目标的目的。RFID 的应用非常广泛,典型应用有动物晶片、汽车晶片防盗器、门禁管制、停车场管制、生产线自动化、物料管理。
4.1.9. 大数据与云计算、物联网的概念
云计算、大数据和物联网代表了IT领域最新的技术发展趋势,三者既有区别又有联系。从云计算和大数据概念的诞生到现在,二者之间的关系非常微妙,既密不可分,又千差万别。因此,我们不能把云计算和大数据割裂开来作为截然不同的两类技术来看待。此外,物联网也是和云计算、大数据相伴相生的技术。
4.1.9.1 大数据、云计算和物联网的区别
- 大数据侧重于对海量数据的存储、处理与分析,从海量数据中发现价值,服务于生产和生活; - 云计算本质上旨在整合和优化各种IT资源并通过网络以服务的方式,廉价地提供给用户; - 物联网的发展目标是实现物物相连,应用创新是物联网发展的核心。
4.1.9.2 大数据、云计算和物联网的联系
从整体上看,大数据、云计算和物联网这三者是相辅相成的。
物联网的传感器源源不断产生的大量数据,构成了大数据的重要数据来源,没有物联网的飞速发展,就不会带来数据产生方式的变革,即由人工产生阶段转向自动产生阶段,大数据时代也不会这么快就到来。同时,物联网需要借助于云计算和大数据技术,实现物联网大数据的存储、分析和处理。
4.2. Hadoop的概述【了解】
4.2.1. 为什么要用hadoop
现在的我们,生活在数据大爆炸的年代。国际数据公司已经预测在2020年,全球的数据总量将达到44ZB,经过单位换算后,至少在440亿TB以上,也就是说,全球每人一块1TB的硬盘都存储不下。
扩展:数据大小单位:Byte,KB,MB,GB,TB,PB,EB,ZB,YB,DB,NB
一些数据集的大小更远远超过了1TB,也就是说,数据的存储是一个要解决的问题。同时,硬盘技术也面临一个技术瓶颈,就是硬盘的传输速度(读数据的速度)的提升远远低于硬盘容量的提升。我们看下面这个表格:

可以看到,容量提升了将近1000倍,而传输速度才提升了20倍,读完一个硬盘的所需要的时间相对来说,更长更久了(已经违反了数据价值的即时性)。读数据都花了这么长时间,更不用说写数据了。
对于如何提高读取数据的效率,我们已经想到解决的方法了,那就是将一个数据集存储到多个硬盘里,然后并行读取。比如1T的数据,我们平均100份存储到100个1TB硬盘上,同时读取,那么读取完整个数据集的时间用不上两分钟。至于硬盘剩下的99%的容量,我们可以用来存储其他的数据集,这样就不会产生浪费。解决读取效率问题的同时,我们也解决了大数据的存储问题。
但是,我们同时对多个硬盘进行读/写操作时,又有了新的问题需要解决:
1、硬件故障问题。一旦使用多个硬件,相对来说,个别硬件产生故障的几率就高,为了避免数据丢失,最常见的做法就是复制(replication):文件系统保存数据的多个复本,一旦发生故障,就可以使用另外的复本。 2、读取数据的正确性问题。大数据时代的一个分析任务,就需要结合大部分数据来共同完成分析,因此从一个硬盘上读取的数据要与从其他99个硬盘上读取的数据结合起来使用。那么,在读取过程中,如何保证数据的正确性,就是一个很大的挑战。
针对于上述几个问题,Hadoop为我们提供了一个可靠的且可扩展的存储和分析平台,此外,由于Hadoop运行在商用硬件上且是开源的,因此Hadoop的使用成本是比较低了,在用户的承受范围内。
4.2.2. Hadoop的简要介绍
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储
Apache lucene是一个应用广泛的文本搜索系统库。该项目的创始人道格·卡丁在2002年带领团队开发该项目中的子项目Apache Nutch,想要从头打造一个网络搜索引擎系统,在开发的过程中,发现了两个问题,一个是硬件的高额资金投入,另一个是存储问题。 2003年和2004年Google先后发表的《GFS》和《MapReduce》论文,给这个团队提供了灵感,并进行了实现,于是NDFS(Nutch分布式文件系统)和MapReduce相继问世。2006年2月份,开发人员将NDFS和MapReduce移出Nutch形成一个独立的子项目,命名为Hadoop(该名字据Doug Cutting所说,是借用了他的孩子给毛绒玩具取得名字)。
4.2.3. 谷歌的三篇论文
- 2003年发表的《GFS》 基于硬盘不够大、数据存储单份的安全隐患问题,提出的分布式文件系统用于存储的理论思想。 · 解决了如何存储大数据集的问题 - 2004年发表的《MapReduce》 基于分布式文件系统的计算分析的编程框架模型。移动计算而非移动数据,分而治之。 · 解决了如何快速分析大数据集的问题 - 2006年发表的《BigTable》 针对于传统型关系数据库不适合存储非结构化数据的缺点,提出了另一种适合存储大数据集的解决方案
4.2.4. Hadoop的发展历史
- 起源于Apache Nutch项目(一个网页爬取工具和搜索引擎系统,后来遇到大数据量的网页存储问题) - 2003年,谷歌发表的一篇论文(描述的是“谷歌分布式文件系统”,简称GFS),给了Apache Nutch项目的开发者灵感 - 2004年,Nutch的开发者开始着手NDFS(Nutch的分布式文件系统) - 2004年,谷歌又发表了一篇介绍MapReduce系统的论文 - 2005年,Nutch项目实现了一个MapReduce系统 - 2006年,开发人员将NDFS和MapReduce移出Nutch项目,形成一个子项目,命名Hadoop - 2008年,Hadoop已成为Apache的顶级项目 - 2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,排序时间为209秒 - 2009年,Hadoop把1TB数据的排序时间缩短到62秒,从此名声大噪 - 现在很多公司都在使用,如雅虎、last.fm、Facebook、纽约时报等
4.2.5. Hadoop的版本介绍
Hadoop是Apache的一个开源项目,所以很多公司在这个基础上都进行了商业化,加入了自己的特色。Hadoop的发行版中除了有Apache社区提供的hadoop之外,比较出名的公司如cloudera,hortonworks,mapR,华为,DKhadoop等都提供了自己的商业版本,主要是大型公司提供更为专业的技术支持,多数都收费。
- Apache Hadoop(社区版): 原生的Hadoop、开源、免费、社区活跃,更新速度快,适合学习阶段 - Cloudera Hadoop(CDH版):最成型的商业发行版本。有免费版和收费版本。版本划分清晰,版本更新速度快,对生态圈的其他软件做了很好的兼容性,安全性、稳定性都有增强。支持多种安装方式(Cloudera Manager、YUM、RPM、Tarball) - Hortonworks Hadoop(HDP):完全开源,安装方便,提供了直观的用户安装界面和配置工具
4.2.6. Hadoop的官网介绍
Hadoop是Apache的顶级项目,但凡是Apache的顶级项目,官网的地址始终是: 项目名.apache.org。
因此,Hadoop的官网是: hadoop.apache.org

4.2.7. Hadoop的组成部分
hadoop2.0以后的四个模块: - Hadoop Common:Hadoop模块的通用组件 - Hadoop Distributed File System:分布式文件系统 - Hadoop YARN:作业调度和资源管理框架 - Hadoop MapReduce:基于YARN的大型数据集并行计算处理框架 hadoop3.0新扩展的两个模块: - Hadoop Ozone:Hadoop的对象存储机制 - Hadoop Submarine:Hadoop的机器学习引擎
4.2.8. Hadoop的生态系统

* Hbase 是一个可扩展的分布式数据库,支持大型表格的结构化数据存储。 HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的,而不是基于行的模式。 * Hive 数据仓库基础架构,提供数据汇总和临时查询,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。Hive提供的是一种结构化数据的机制,定义了类似于传统关系数据库中的类SQL语言:Hive QL,通过该查询语言,数据分析人员可以很方便地运行数据分析 业务。 * Spark Hadoop数据的快速和通用计算引擎。 Spark提供了一个简单而富有表现力的编程模型,支持广泛的应用程序,包括ETL,机器学习,流处理和图计算。 * ZooKeeper 一个面向分布式应用程序的高性能协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。 * Sqoop(数据ETL/同步工具) Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。 * Flume(日志收集工具) Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。 * Kafka(分布式消息队列) Kafka是Linkedin于2010年12月份开源的消息系统,它主要用于处理活跃的流式数据。这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。 * Ambari 用于供应,管理和监控Apache Hadoop集群的基于Web的工具。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。Ambari还提供了一个用于查 看集群健康状况的仪表板,例如热图以及可视化查看MapReduce,Pig和Hive应用程序的功能以及用于诊断其性能特征的功能,以方便用户使用。 * Avro 数据序列化系统。可以将数据结构或者对象转换成便于存储和传输的格式,其设计目标是用于支持数据密集型应用,适合大规模数据的存储与交换。Avro提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程调用RPC和简单动态语言集成等功能。 * Cassandra 可扩展的多主数据库,没有单点故障。是一套开源分布式NoSQL数据库系统。 * Chukwa 于管理大型分布式系统的数据收集系统(2000+以上的节点, 系统每天产生的监控数据量在T级别)。它构建在Hadoop的HDFS和MapReduce基础之上,继承了Hadoop的可伸缩性和鲁棒性。Chukwa包含一个强大和灵活的工具集,提供了数据的生成、收集、排序、去重、分析和展示等一系列功能,是Hadoop使用者、集群运营人员和管理人员的必备工具。 * Mahout Apache旗下的一个开源项目,可扩展的机器学习和数据挖掘库 * Pig 用于并行计算的高级数据流语言和执行框架。它简化了使用Hadoop进行数据分析的要求,提供了一个高层次的、面向领域的抽象语言:Pig Latin。 * Tez 一个基于Hadoop YARN的通用数据流编程框架,它提供了一个强大而灵活的引擎,可执行任意DAG任务来处理批处理和交互式用例的数据Hado™生态系统中的Hive™,Pig™和其他框架以及其他商业软件(例如ETL工具)正在采用Tez,以替代Hadoop™MapReduce作为底层执行引擎。 * Oozie(工作流调度器) 一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。 * Pig(ad-hoc脚本) 由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具,通常用于进行离线分析。它定义了一种数据流语言—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
4.3. Hadoop的安装部署【掌握】
4.3.1. 本地模式
4.3.1.1. 本地模式的介绍
本地模式,即运行在单台机器上。没有分布式的思想,使用的是本地文件系统。使用本地模式主要是用于对MapReduce的程序的逻辑进行调试,确保程序的正确性。由于在本地模式下测试和调试MapReduce程序较为方便,因此,这种模式适合用在开发阶段。
4.3.1.2. 平台软件说明
| 平台&软件 | 说明 |
|---|---|
| 宿主机操作系统 | Windows / MacOS |
| 虚拟机操作系统 | CentOS 7 |
| 虚拟机软件 | Windows: VMWare MacOS: Parallels Desktop |
| SSH工具 | Windows: MobaXterm / FinalShell MacOS: FinalShell / iTerm2 |
| 软件包上传路径 | /root/softwares |
| 软件安装路径 | /usr/local |
| JDK | X64: jdk-8u321-linux-x64.tar.gz ARM: jdk-8u321-linux-aarch64.tar.gz |
| Hadoop | X64: hadoop-3.3.1.tar.gz ARM: hadoop-3.3.1-aarch64.tar.gz |
| 用户 | root |
4.3.1.3. 安装JDK
-
卸载之前的JDK
# 卸载之前的原因,主要是需要保证安装的JDK版本的正确性。 [root@hadoop01 ~]# rpm -qa | grep jdk # 如果有,请卸载 [root@hadoop01 ~]# rpm -e xxxxxxxx --nodeps # 将查询到的内置jdk强制卸载
-
上传JDK安装包到指定的路径
使用MobaXterm或者FinalShell直接上传即可,上传到 /root/softwares 下
-
解压JDK到指定安装路径
[root@hadoop01 ~]# cd /root/softwares && tar -zxvf jdk-8u321-linux-x64.tar.gz -C /usr/local
-
配置环境变量
[root@hadoop01 local]# vim /etc/profile ...上述内容省略,在末尾添加即可... # Java Environment export JAVA_HOME=/usr/local/jdk1.8.0_321 export PATH=$PATH:$JAVA_HOME/bin
-
重新引导,使得环境变量生效
[root@hadoop01 local]# source /etc/profile
-
验证JDK是否配置完成
[root@hadoop01 local]# java -version
4.3.1.4. 安装Hadoop
-
上传Hadoop到指定的路径
使用MobaXterm或者FinalShell上传到 /root/softwares 下即可
-
解压安装
[root@hadoop01 ~]# cd /root/softwares && tar -zxvf hadoop-3.3.1.tar.gz -C /usr/local
-
配置环境变量
[root@hadoop01 ~]# vim /etc/profile ...上述内容省略,在最下方添加即可... # Hadoop Environment export HADOOP_HOME=/usr/local/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
-
重新引导,使得环境变量生效
[root@hadoop01 ~]# source /etc/profile
-
验证是否配置成功
[root@hadoop01 ~]# hadoop version
4.3.1.5. Hadoop的目录说明

4.3.1.6. 案例演示: wordcount
-
新建一个目录,存放文本文件
# 将若干个存储单词的文件放入这个目录下 [root@hadoop01 ~]# mkdir ~/input
-
执行wordcount
[root@hadoop01 ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount ~/input ~/output
-
查看结果
[root@hadoop01 ~]# cat ~/output/*
4.3.1.7. 案例演示: pi
直接计算pi的结果
[root@hadoop01 ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10
4.3.2. 伪分布式模式
4.3.2.1. 伪分布式的介绍
伪分布式模式也是只需要一台机器,但是与本地模式的不同,伪分布式使用的是分布式的思想,具有完整的分布式文件存储和分布式计算的思想。只不过在进行存储和计算的时候涉及到的相关的守护进程都运行在同一台机器上,都是独立的Java进程。因而称为伪分布式集群。比本地模式多了代码调试功能,允许检查内存使用情况、HDFS输入输出、以及其他的守护进程交互。
总结来说: 伪分布式集群就是只有一个节点的分布式集群。
4.3.2.2. 平台软件说明
| 平台&软件 | 说明 |
|---|---|
| 宿主机操作系统 | Windows / MacOS |
| 虚拟机操作系统 | CentOS 7 |
| 虚拟机软件 | Windows: VMWare MacOS: Parallels Desktop |
| SSH工具 | Windows: MobaXterm / FinalShell MacOS: FinalShell / iTerm2 |
| 软件包上传路径 | /root/softwares |
| 软件安装路径 | /usr/local |
| JDK | X64: jdk-8u321-linux-x64.tar.gz ARM: jdk-8u321-linux-aarch64.tar.gz |
| Hadoop | X64: hadoop-3.3.1.tar.gz ARM: hadoop-3.3.1-aarch64.tar.gz |
| 用户 | root |
4.3.2.3. 安装JDK
见 4.3.1.3. 安装JDK 章节
4.3.2.4. 安装Hadoop
见 4.3.1.4. 安装Hadoop 章节
4.3.2.5. 搭建环境准备
-
总纲
1. 确保防火墙是关闭状态。 2. 确保NAT模式和静态IP的确定 (192.168.10.101) 3. 确保/etc/hosts文件里, ip和hostname的映射关系 4. 确保免密登陆localhost有效 5. jdk和hadoop的环境变量配置
-
防火墙关闭
[root@hadoop01 ~]# systemctl stop firewalld [root@hadoop01 ~]# systemctl disable firewalld [root@hadoop01 ~]# systemctl stop NetworkManager [root@hadoop01 ~]# systemctl disable NetworkManager #最好也把selinux关闭掉,这是linux系统的一个安全机制,进入文件中将SELINUX设置为disabled [root@hadoop01 ~]# vi /etc/selinux/config ......... SELINUX=disabled .........
-
修改host映射
# 进入hosts文件,配置一下ip和hostname [root@hadoop01 ~]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.101 qianfeng01 # 添加本机的静态IP和本机的主机名之间的映射关系
-
确保ssh对localhost的免密登陆认证有效
# 1. 使用rsa加密技术,生成公钥和私钥。一路回车即可 [root@hadoop01 ~]# ssh-keygen -t rsa # 2. 进入~/.ssh目录下,使用ssh-copy-id命令 [root@hadoop01 .ssh]# ssh-copy-id root@qianfeng01 # 3. 进行验证,去掉第一次的询问(yes/no) [hadoop@hadoop01 .ssh]# ssh localhost
-
确保JDK与Hadoop已经安装完成,并且已经配置好环境变量
4.3.2.6. 配置文件修改
-
core-site.xml
<configuration> <!-- 设置namenode节点 --> <!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9820</value> </property> <!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-3.3.1/tmp</value> </property> </configuration> -
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop01:9868</value> </property> <!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop01:9870</value> </property> </configuration> -
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_321 # Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
4.3.2.7. 格式化集群
注意事项:
我们在core-site.xml中配置过hadoop.tmp.dir的路径,在集群格式化的时候需要保证在这个路径不存在!如果之前存在数据,先将其删除,再进行格式化!
hdfs namenode -format

4.3.2.8. 启动集群
[root@hadoop01 hadoop]# start-dfs.sh Starting namenodes on [qianfeng01] Starting datanodes Starting secondary namenodes [qianfeng01] [root@hadoop01 hadoop]# jps 11090 Jps 10595 NameNode 10938 SecondaryNameNode 10763 DataNode
4.3.2.9. WebUI查看
在电脑的浏览器中输入虚拟机的IP地址,如果做过了主机名映射,可以直接使用主机名

4.3.2.10. 案例演示: wordcount
-
数据准备
[root@hadoop01 ~]# mkdir input && cd input [root@hadoop01 input]# echo "hello world hadoop linux hadoop" >> file1 [root@hadoop01 input]# echo "hadoop linux hadoop linux hello" >> file1 [root@hadoop01 input]# echo "hadoop linux mysql linux hadop" >> file1 [root@hadoop01 input]# echo "hadoop linux hadoop linux hello" >> file1 [root@hadoop01 input]# echo "linux hadoop good programmer" >> file2
-
上传到集群
# 因为伪分布式集群也应用到了分布式的思想,分布式的存储。任务处理的数据是HDFS的数据,而并不是Linux本地的。 [root@hadoop01 input]# hdfs dfs -put ~/input/ / # 检查是否已经上传成功 [root@hadoop01 input]# hdfs dfs -ls -R / drwxr-xr-x - root supergroup 0 2022-01-28 13:11 /input -rw-r--r-- 1 root supergroup 31 2022-01-28 13:11 /input/file -rw-r--r-- 1 root supergroup 127 2022-01-28 13:11 /input/file1 -rw-r--r-- 1 root supergroup 59 2022-01-28 13:11 /input/file2
-
执行任务
[root@hadoop01 input]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
-
查看结果
[root@hadoop01 input]# hdfs dfs -cat /output/* good 3 hadoop 9 hadop 2 hello 3 linux 10 mysql 2 programmer 2 world 1
4.3.3. 完全分布式模式
4.3.3.1. 完全分布式介绍
在真实的企业环境中,服务器集群会使用到多台机器,共同配合,来构建一个完整的分布式文件系统。而在这样的分布式文件系统中,HDFS相关的守护进程也会分布在不同的机器上,例如:
-
NameNode守护进程,尽可能的单独部署在一台硬件性能较好的机器中。
-
其他的每台机器上都会部署一个DataNode守护进程,一般的硬件环境即可。
-
SecondaryNameNode守护进程最好不要和NameNode在同一台机器上。
4.3.3.2. 平台软件说明
| 平台&软件 | 说明 |
|---|---|
| 宿主机操作系统 | Windows / MacOS |
| 虚拟机操作系统 | CentOS 7 |
| 虚拟机软件 | Windows: VMWare MacOS: Parallels Desktop |
| 虚拟机 | 主机名: qianfeng01, IP地址: 192.168.10.101 主机名: qianfeng02, IP地址: 192.168.10.102 主机名: qianfeng03, IP地址: 192.168.10.103 |
| SSH工具 | Windows: MobaXterm / FinalShell MacOS: FinalShell / iTerm2 |
| 软件包上传路径 | /root/softwares |
| 软件安装路径 | /usr/local |
| JDK | X64: jdk-8u321-linux-x64.tar.gz ARM: jdk-8u321-linux-aarch64.tar.gz |
| Hadoop | X64: hadoop-3.3.1.tar.gz ARM: hadoop-3.3.1-aarch64.tar.gz |
| 用户 | root |
4.3.3.3. 守护进程布局
| NameNode | DataNode | SecondaryNameNode | |
|---|---|---|---|
| hadoop01 | √ | √ | |
| hadoop02 | √ | √ | |
| hadoop03 | √ |
4.3.3.4. 集群搭建准备
-
总纲
1. 三台机器的防火墙必须是关闭的. 2. 确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置) 3. 确保/etc/hosts文件配置了ip和hostname的映射关系 4. 确保配置了三台机器的免密登陆认证(克隆会更加方便) 5. 确保所有机器时间同步 6. jdk和hadoop的环境变量配置
-
防火墙关闭
[root@hadoop01 ~]# systemctl stop firewalld [root@hadoop01 ~]# systemctl disable firewalld [root@hadoop01 ~]# systemctl stop NetworkManager [root@hadoop01 ~]# systemctl disable NetworkManager #最好也把selinux关闭掉,这是linux系统的一个安全机制,进入文件中将SELINUX设置为disabled [root@hadoop01 ~]# vi /etc/selinux/config ......... SELINUX=disabled ........
-
主机映射
[root@hadoop01 ~]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.101 hadoop01 #添加本机的静态IP和本机的主机名之间的映射关系 192.168.10.102 hadoop02 192.168.10.103 hadoop03
-
免密登录
# 1. 使用rsa加密技术,生成公钥和私钥。一路回车即可 [root@hadoop01 ~]# ssh-keygen -t rsa # 2. 使用ssh-copy-id命令 [root@hadoop01 .ssh]# ssh-copy-id root@hadoop01 [root@hadoop01 .ssh]# ssh-copy-id root@hadoop02 [root@hadoop01 .ssh]# ssh-copy-id root@hadoop03 # 3. 进行验证 [hadoop@hadoop01 .ssh]# ssh hadoop01 [hadoop@hadoop01 .ssh]# ssh hadoop02 [hadoop@hadoop01 .ssh]# ssh hadoop03 # 4. 继续在hadoop02和hadoop03生成公钥和私钥,给三台节点拷贝
-
时间同步
参考Linux部分,可以让三台节点都同步网络时间,或者选择其中一台作为时间同步服务器。
-
安装JDK和配置环境变量
参考4.3.1.3和4.3.1.4章节内容。
4.3.3.5. 配置文件
-
core-site.xml
<configuration> <!-- 设置namenode节点 --> <!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9820</value> </property> <!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-3.3.1/data</value> </property> </configuration> -
hdfs-site.xml
<configuration> <!-- 块的副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop02:9868</value> </property> <!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop01:9870</value> </property> </configuration> -
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_321 # Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
-
works
hadoop01 hadoop02 hadoop03
-
分发
# 我们已经完成了一个节点的环境配置,其他的节点也需要保持完全相同的配置。我们只需要将qianfeng01节点的配置拷贝到其他的节点即可。 # 分发之前,先检查自己的节点数据文件是否存在 # 如果之间格式化过集群,那么会在core-site.xml中配置的hadoop.tmp.dir路径下生成文件,先将其删除 [root@hadoop01 ~]# stop-dfs.sh [root@hadoop01 ~]# rm -rf $HADOOP_HOME/tmp
[root@hadoop01 ~]# cd /usr/local [root@hadoop01 local]# scp -r jdk1.8.0_321/ hadoop02:$PWD [root@hadoop01 local]# scp -r jdk1.8.0_321/ hadoop03:$PWD [root@hadoop01 local]# scp -r hadoop-3.2.1/ hadoop02:$PWD [root@hadoop01 local]# scp -r hadoop-3.3.1/ hadoop03:$PWD [root@hadoop01 local]# scp /etc/profile hadoop02:/etc/ [root@hadoop01 local]# scp /etc/profile hadoop03:/etc/
4.3.3.6. 格式化集群
hdfs namenode -format
4.3.3.7. 启动集群
start-dfs.sh # 启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode) stop-dfs.sh # 停止HDFS所有进程(NameNode、SecondaryNameNode、DataNode) hadoop-daemon.sh start namenode # 只开启NameNode hadoop-daemon.sh start secondarynamenode # 只开启SecondaryNameNode hadoop-daemon.sh start datanode # 只开启DataNode hadoop-daemon.sh stop namenode # 只关闭NameNode hadoop-daemon.sh stop secondarynamenode # 只关闭SecondaryNameNode hadoop-daemon.sh stop datanode # 只关闭DataNode
4.3.3.8. 进程查看
# hadoop01节点 [root@hadoop01 hadoop]# jps 13442 NameNode 13618 DataNode 13868 Jps # hadoop02节点 [root@hadoop02 ~]# jps 10514 SecondaryNameNode 10548 Jps 10405 DataNode # hadoop03节点 [root@hadoop03 ~]# jps 10931 DataNode 11001 Jps
每次在查看集群的进程分布的时候,都需要在不同的节点之间进行切换,非常的麻烦。所以,我们可以设计一个小脚本。
#!/bin/bash
# 定义所有的节点
HOSTS=( hadoop01 hadoop02 hadoop03 )
# 遍历每一个节点
for HOST in ${HOSTS[@]}
do
# 远程登录到指定节点,执行jps命令
ssh -T $HOST << TERMINATER
echo "---------- $HOST ----------"
jps | grep -iv jps
exit
TERMINATER
done
执行效果
[root@hadoop01 ~]# jps-cluster.sh ---------- hadoop01 ---------- 13442 NameNode 13618 DataNode ---------- hadoop02 ---------- 10514 SecondaryNameNode 10405 DataNode ---------- hadoop03 ---------- 10931 DataNode
4.3.4.9. 启动日志查看
HDFS的角色有三个: NameNode、SecondaryNameNode、DataNode,启动的时候也会有对应的日志文件生成。如果在启动脚本执行之后,发现对应的角色没有启动起来,那就可以去查看日志文件,检查错误的详情,解决问题。
-
日志的位置: $HADOOP_HOME/logs
-
日志的命名: hadoop-username-daemon-host.log
例如: hadoop-root-namenode-hadoop01.log => hadoop01节点上的namenode的日志 hadoop-root-datanode-hadoop02.log => hadoop02节点上的datanode的日志
4.3.4.10. 集群常见问题
-
格式化集群时,报错原因
- 当前用户使用不当 - /etc/hosts里的映射关系填写错误 - 免密登录认证异常 - jdk环境变量配置错误 - 防火墙没有关闭
-
namenode进程没有启动的原因:
- 当前用户使用不当 - 重新格式化时,忘记删除${hadoop.tmp.dir}目录下的内容 - 网络震荡,造成edit日志文件的事务ID序号不连续 -
datanode出现问题的原因
- /etc/hosts里的映射关系填写错误 - 免密登录异常 - 重新格式化时,忘记删除${hadoop.tmp.dir}目录下的内容,造成datanode的唯一标识符不在新集群中。 -
上述问题暴力解决: 重新格式化
如果想重新格式化,那么需要先删除每台机器上的${hadoop.tmp.dir}指定路径下的所有内容,然后再格式化:最好也把logs目录下的内容也清空,因为日志内容已经是前一个废弃集群的日志信息了,留着也无用。
4.3.4.11. 案例演示: wordcount
-
数据准备
[root@hadoop01 ~]# mkdir input && cd input [root@hadoop01 input]# echo "hello world hadoop linux hadoop" >> file1 [root@hadoop01 input]# echo "hadoop linux hadoop linux hello" >> file1 [root@hadoop01 input]# echo "hadoop linux mysql linux hadop" >> file1 [root@hadoop01 input]# echo "hadoop linux hadoop linux hello" >> file1 [root@hadoop01 input]# echo "linux hadoop good programmer" >> file2 [root@hadoop01 input]# echo "good programmer hadoop good" >> file2
-
上传到集群
# 将数据上传到HDFS [root@hadoop01 input]# hd # 检查是否已经上传成功 [root@hadoop01 input]# hdfs dfs -ls -R / drwxr-xr-x - root supergroup 0 2022-01-28 13:11 /input -rw-r--r-- 1 root supergroup 31 2022-01-28 13:11 /input/file -rw-r--r-- 1 root supergroup 127 2022-01-28 13:11 /input/file1 -rw-r--r-- 1 root supergroup 59 2022-01-28 13:11 /input/file2
-
执行任务
[root@hadoop01 input]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
-
查看结果
[root@hadoop01 input]# hdfs dfs -cat /output/* good 3 hadoop 10 hadop 2 hello 3 linux 10 mysql 2 programmer 2 world 1
4.4. HDFS的Shell操作【重点】
HDFS是一个分布式文件系统,我们可以使用一些命令来操作HDFS集群上的文件。
例如: 文件上传、下载、移动、拷贝等操作。
HDFS的Shell操作主命令都是 hdfs dfs,其他的操作直接向后拼接即可。
4.4.1. 创建目录
[-mkdir [-p] <path> ...] # 在分布式文件系统上创建目录 -p,多层级创建
调用格式: hdfs dfs -mkdir (-p) /目录
例如:
- hdfs dfs -mkdir /data
- hdfs dfs -mkdir -p /data/a/b/c
4.4.2. 上传命令
[-put [-f] [-p] [-l] <localsrc> ... <dst>] # 将本地文件系统的文件上传到分布式文件系统
调用格式: hdfs dfs -put /本地文件 /分布式文件系统路径
注意: 直接写/是省略了文件系统的名称hdfs://ip:port
例如:
- hdfs dfs -put /root/a.txt /data/
- hdfs dfs -put /root/logs/* /data/
其他指令:
[-moveFromLocal <localsrc> ... <dst>] #将本地文件系统的文件上传到分布式文件系统
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
4.4.3. 查看命令
[-ls [-d] [-h] [-R] [<path> ...]] #查看分布式文件系统的目录里内容 调用格式: hdfs dfs -ls / [-cat [-ignoreCrc] <src> ...] #查看分布式文件系统的文件内容 调用格式: hdfs dfs -cat /xxx.txt [-tail [-f] <file>] #查看分布式文件系统的文件内容 调用格式: hdfs dfs -tail /xxx.txt 注意:默认最多查看1000行
4.4.4. 下载命令
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 注意:本地路径的文件夹可以不存在 [-moveToLocal <src> <localdst>] 注意:从hdfs的某个路径将数据剪切到本地,已经被遗弃了 [-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 调用格式:同copyToLocal
4.4.5. 合并下载
hdfs dfs [generic options] -getmerge [-nl] <src> <localdst> 调用格式: hdfs dfs -getmerge hdfs上面的路径 本地的路径 实例: hdfs dfs -getmerge /hadoopdata/*.xml /root/test.test
4.4.6. 删除命令
[-rm [-f] [-r|-R] [-skipTrash] <src> ...] 注意:如果删除文件夹需要加-r [-rmdir [--ignore-fail-on-non-empty] <dir> ...] 注意:必须是空文件夹,如果非空必须使用rm删除
4.4.7. 拷贝命令
hdfs dfs [generic options] -cp [-f] [-p | -p[topax]] <src> ... <dst> 调用格式: hdfs dfs -cp /hdfs路径_1 /hdfs路径_2 实例: hdfs dfs -cp /input /input2
4.4.8. 移动命令
hdfs dfds [generic options] -mv <src> ... <dst> 调用格式: hdfs dfs -mv /hdfs的路径1 /hdfs的另一个路径2 实例: hfds dfs -mv /aaa /bbb
4.4.9. 创建空文件
hdfs dfs [generic options] -touchz <path> ... 调用格式: hdfs dfs touchz /hadooptest.txt
4.4.10. 向文件中追加内容
HDFS的文件系统上的文件,不允许进行文件中的数据插入、删除、修改操作,只支持向文件的末尾追加内容
例如: 删除文件的第10行数据,在第11行插入数据,修改第12行数据等,这些都是不允许的。
[-appendToFile <localsrc> ... <dst>] 调用格式: hdfs dfs -appendToFile 本地文件 hdfs上的文件 注意: 不支持在中间随意增删改操作
4.4.11. 修改文件权限
跟本地的操作一致, -R是让子目录或文件也进行相应的修改 [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] 实例: hdfs dfs -chmod 777 /input
4.4.12. 修改文件副本数量
[-setrep [-R] [-w] <rep> <path> ...] 调用格式:hadoop fs -setrep 3 / 将hdfs根目录及子目录下的内容设置成3个副本 注意:当设置的副本数量与初始化时默认的副本数量不一致时,集群会作出反应,比原来多了会自动进行复制.
4.4.13. 文件测试
hdfs dfs [generic options] -test -[defsz] <path> 参数说明: -e:文件是否存在 存在返回0 -z:文件是否为空 为空返回0 -d:是否是路径(目录) ,是返回0 调用格式: hdfs dfs -test -d 文件 实例: hdfs dfs -test -d /shelldata/111.txt && echo "OK" || echo "no" 解释: 测试当前的内容是否是文件夹 ,如果是返回ok,如果不是返回no
4.4.14. 查看文件夹及子文件夹数量
hdfs dfs [generic options] -count [-q] [-h] <path> ... 调用格式: hdfs dfs -count /hadoop
4.4.15. 查看文件状态
hdfs dfs [generic options] -stat [format] <path> ... 命令的作用:当向hdfs上写文件时,可以通过dfs.blocksize配置项来设置文件的block的大小。这就导致了hdfs上的不同的文件block的大小是不相同的。有时候想知道hdfs上某个文件的block大小,可以预先估算一下计算的task的个数。stat的意义:可以查看文件的一些属性。 调用格式:hdfs dfs -stat [format] 文件路径 format的形式: %b:打印文件的大小(目录大小为0) %n:打印文件名 %o:打印block的size %r:打印副本数 %y:utc时间 yyyy-MM-dd HH:mm:ss %Y:打印自1970年1月1日以来的utc的微秒数 %F:目录打印directory,文件打印regular file 注意: 1)当使用-stat命令但不指定format时,只打印创建时间,相当于%y 2)-stat 后面只跟目录,%r,%o等打印的都是0,只有文件才有副本和大小 实例: hdfs dfs -stat %b-%n-%o-%r /input/file1
4.4.16. 查看磁盘利用率及文件大小
[-df [-h] [<path> ...]] 查看分布式系统的磁盘使用情况 [-du [-s] [-h] <path> ...] #查看分布式系统上当前路径下文件的情况 -h:human 以人类可读的方式显示
4.4.17. 回收站
1. 修改core-site.xml文件
注意: 我们需要在namenode和datanode同时设置垃圾回收
<property>
<name>fs.trash.interval</name>
<!-- 1440分钟后检查点会被清除,如果为0,垃圾回收站不会启用. -->
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
解释:
一: 检查点:
执行下面的语句后出现的.Trash/190907043825就是检查点
[root@hadoop01 sbin]# hadoop fs -ls /user/root/.Trash/
19/09/07 05:15:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
drwx------ - root supergroup 0 2019-09-07 04:36 /user/root/.Trash/190907043825
drwx------ - root supergroup 0 2019-09-07 05:15 /user/root/.Trash/Current
二: fs.trash.interval
分钟数,当超过这个分钟数后检查点会被删除。如果为零,回收站功能将被禁用。默认是0.单位分钟。这里我设置的是1天(60*24)
删除数据rm后,会将数据move到当前文件夹下的.Trash/current目录
三: fs.trash.checkpoint.interval
检查点创建的时间间隔(单位为分钟)。其值应该小于或等于fs.trash.interval。如果为零,则将该值设置为fs.trash.interval的值。
四: 删除过程分析
这里的Deletion interval表示检查点删除时间间隔(单位为分钟)
这里的Emptier interval表示在运行线程来管理检查点之前,NameNode需要等待多长时间(以分钟为单位),即检查点创建时间间隔.NameNode删除超过fs.trash.interval的检查点,并为/user/${username}/.Trash/Current创建一个新的检查点。该频率由fs.trash.checkpoint.interval的值确定,且不得大于Deletion interval。这确保了在emptier窗口内回收站中有一个或多个检查点。
[root@hadoop01 sbin]# hadoop fs -rm -r /hadoop4.txt
19/09/07 05:15:24 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1440 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://hadoop01:9000/hadoop4.txt' to trash at: hdfs://qianfeng01:9000/user/root/.Trash/Current
例如:
fs.trash.interval = 120 (deletion interval = 2 hours)
fs.trash.checkpoint.interval = 60 (emptier interval = 1 hour)
说明:
这导致NameNode为Current目录下的垃圾文件每小时创建一个新的检查点,并删除已经存在超过2个小时的检查点。
在回收站生命周期结束后,NameNode从HDFS命名空间中删除该文件。删除文件会导致与文件关联的块被释放。请注意,用户删除文件的时间与HDFS中相应增加可用空间的时间之间可能存在明显的时间延迟,即用户删除文件,HDFS可用空间不会立马增加,中间有一定的延迟。
五: expunge 清空回收站
要想使用这个命令,首先得有回收站,即fs.trash.interval的值不能为0
当我们执行expunge命令时,其实是会立刻创建一个新的检查点,并将/.Trash/Current中的内容立刻放入这个检查点.
实例: [root@qianfeng01 sbin]# hadoop fs -expunge
19/09/07 05:15:58 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1440 minutes, Emptier interval = 0 minutes.
19/09/07 05:15:58 INFO fs.TrashPolicyDefault: Created trash checkpoint: /user/root/.Trash/190907051558
六: 如果想绕过垃圾回收站并立即从文件系统中删除文件。可以执行 hadoop fs -rm -skipTrash
[root@hadoop01 sbin]# hadoop fs -rm -skipTrash /hadoop111.txt
19/09/07 05:50:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Deleted /hadoop111.txt
2.测试
1)新建目录input
[root@hadoop01:/data/soft]# hadoop fs -mkdir /input
2)上传文件
[root@hadoop01:/data/soft]# hadoop fs -copyFromLocal /data/soft/file0* /input
3)删除目录input
[root@hadoop01 data]# hadoop fs -rmr /input
Moved to trash: hdfs://hadoop01:9000/user/root/input
4)参看当前目录
[root@hadoop01 data]# hadoop fs -ls
Found 2 items
drwxr-xr-x - root supergroup 0 2011-02-12 22:17 /user/root/.Trash
发现input删除,多了一个目录.Trash
5)恢复刚刚删除的目录
[root@hadoop01 data]# hadoop fs -mv /user/root/.Trash/Current/user/root/input /user/root/input
6)检查恢复的数据
[root@qianfeng01 data]# hadoop fs -ls input
Found 2 items
-rw-r--r-- 3 root supergroup 22 2011-02-12 17:40 /user/root/input/file01
-rw-r--r-- 3 root supergroup 28 2011-02-12 17:40 /user/root/input/file02
7)删除.Trash目录(清理垃圾)
[root@qianfeng01 data]# hadoop fs -rmr .Trash
Deleted hdfs://qianfeng01:9000/user/root/.Trash
4.5. HDFS块的讲解【重点】
4.5.1. 传统型分布式文件系统的缺点
现在想象一下这种情况:有四个文件 0.5TB的file1,1.2TB的file2,50GB的file3,100GB的file4;有7个服务器,每个服务器上有10个1TB的硬盘。

在存储方式上,我们可以将这四个文件存储在同一个服务器上(当然大于1TB的文件需要切分),我们需要使用一个文件来记录这种存储的映射关系吧。用户是可以通过这种映射关系来找到节点硬盘相应的文件的。那么缺点也就暴露了出来:
第一、负载不均衡。
因为文件大小不一致,势必会导致有的节点磁盘的利用率高,有的节点磁盘利用率低。
第二、网络瓶颈问题。
一个过大的文件存储在一个节点磁盘上,当有并行处理时,每个线程都需要从这个节点磁盘上读取这个文件的内容,那么就会出现网络瓶颈,不利于分布式的数据处理。
4.5.2. HDFS的块
HDFS与其他普通文件系统一样,同样引入了块(Block)的概念,并且块的大小是固定的。但是不像普通文件系统那样小,而是根据实际需求可以自定义的。块是HDFS系统当中的最小存储单位,在hadoop2.0中默认大小为128MB(hadoop1.x中的块大小为64M)。在HDFS上的文件会被拆分成多个块,每个块作为独立的单元进行存储。多个块存放在不同的DataNode上,整个过程中 HDFS系统会保证一个块存储在一个数据节点上 。但值得注意的是,如果某文件大小或者文件的最后一个块没有到达128M,则不会占据整个块空间 。
我们来看看HDFS的设计思想:以下图为例,来进行解释。

4.5.3. HDFS的块大小
HDFS上的块大小为什么会远远大于传统文件?
1. 目的是为了最小化寻址开销时间。
在I/O开销中,机械硬盘的寻址时间是最耗时的部分,一旦找到第一条记录,剩下的顺序读取效率是非常高的,因此以块为单位读写数据,可以尽量减少总的磁盘寻道时间。
HDFS寻址开销不仅包括磁盘寻道开销,还包括数据块的定位开销,当客户端需要访问一个文件时,首先从名称节点获取组成这个文件的数据块的位置列表,然后根据位置列表获取实际存储各个数据块的数据节点的位置,最后,数据节点根据数据块信息在本地Linux文件系统中找到对应的文件,并把数据返回给客户端,设计成一个比较大的块,可以减少每个块儿中数据的总的寻址开销,相对降低了单位数据的寻址开销磁盘的寻址时间为大约在5~15ms之间,平均值为10ms,而最小化寻址开销时间普遍认为占1秒的百分之一是最优的,那么块大小的选择就参考1秒钟的传输速度,比如2010年硬盘的传输速率是100M/s,那么就选择块大小为128M。
2. 为了节省内存的使用率
一个块的元数据大约150个字节。1亿个块,不论大小,都会占用20G左右的内存。因此块越大,集群相对存储的数据就越多。所以暴漏了HDFS的一个缺点,不适合存储小文件。
不适合存储小文件解释: 1. 从存储能力出发(固定内存) 因为HDFS的文件是以块为单位存储的,且如果文件大小不到128M的时候,是不会占用整个块的空间的。但是,这个块依然会在内存中占用150个字节的元数据。因此,同样的内存占用的情况下,大量的小文件会导致集群的存储能力不足。 例如: 同样是128G的内存,最多可存储9.2亿个块。如果都是小文件,例如1M,则集群存储的数据大小为9.2亿*1M = 877TB的数据。但是如果存储的都是128M的文件,则集群存储的数据大小为109.6PB的数据。存储能力大不相同。 2. 从内存占用出发(固定存储能力) 同样假设存储1M和128M的文件对比,同样存储1PB的数据,如果是1M的小文件存储,占用的内存空间为1PB/1Mb*150Byte = 150G的内存。如果存储的是128M的文件存储,占用的内存空间为1PB/128M*150Byte = 1.17G的内存占用。可以看到,同样存储1PB的数据,小文件的存储比起大文件占用更多的内存。
4.5.4. 块的相关参数设置
当然块大小在默认配置文件hdfs-default.xml中有相关配置,我们可以在hdfs-site.xml中进行重置
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>默认块大小,以字节为单位。可以使用以下后缀(不区分大小写):k,m,g,t,p,e以重新指定大小(例如128k, 512m, 1g等)</description>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>1048576</value>
<description>以字节为单位的最小块大小,由Namenode在创建时强制执行时间。这可以防止意外创建带有小块的文件降低性能。</description>
</property>
<property>
<name>dfs.namenode.fs-limits.max-blocks-per-file</name>
<value>1048576</value>
<description>每个文件的最大块数,由写入时的Namenode执行。这可以防止创建降低性能的超大文件</description>
</property>
4.5.5. 块的存储位置
在hdfs-site.xml中我们配置过下面这个属性,这个属性的值就是块在linux系统上的存储位置
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>

4.5.6. HDFS的优点
1. 高容错性(硬件故障是常态):数据自动保存多个副本,副本丢失后,会自动恢复 2. 适合大数据集:GB、TB、甚至PB级数据、千万规模以上的文件数量,1000以上节点规模。 3. 数据访问: 一次性写入,多次读取;保证数据一致性,安全性 4. 构建成本低:可以构建在廉价机器上。 5. 多种软硬件平台中的可移植性 6. 高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。 7. 高可靠性:Hadoop的存储和处理数据的能力值得人们信赖.
4.5.7. HDFS的缺点
1. 不适合做低延迟数据访问:
HDFS的设计目标有一点是:处理大型数据集,高吞吐率。这一点势必要以高延迟为代价的。因此HDFS不适合处理用户要求的毫秒级的低延迟应用请求
2. 不适合小文件存取:
一个是大量小文件需要消耗大量的寻址时间,违反了HDFS的尽可能减少寻址时间比例的设计目标。第二个是内存有限,一个block元数据大内存消耗大约为150个字节,存储一亿个block和存储一亿个小文件都会消耗20G内存。因此相对来说,大文件更省内存。
3. 不适合并发写入,文件随机修改:
HDFS上的文件只能拥有一个写者,仅仅支持append操作。不支持多用户对同一个文件的写操作,以及在文件任意位置进行修改
4.6. HDFS的体系结构【重点】
4.6.1. 体系结构解析
HDFS采用的是master/slaves这种主从的结构模型来管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端)、Namenode(名称节点)、Datanode(数据节点)和SecondaryNameNode。真正的一个HDFS集群包括一个Namenode和若干数目的Datanode。 Namenode是一个中心服务器,负责管理文件系统的命名空间 (Namespace ),它在内存中维护着命名空间的最新状态,同时并持久性文件(fsimage和edit)进行备份,防止宕机后,数据丢失。namenode还负责管理客户端对文件的访问,比如权限验证等。 集群中的Datanode一般是一个节点运行一个Datanode进程,真正负责管理客户端的读写请求,在Namenode的统一调度下进行数据块的创建、删除和复制等操作。数据块实际上都是保存在Datanode本地的Linux文件系统中的。每个Datanode会定期的向Namenode发送数据,报告自己的状态(我们称之为心跳机制)。没有按时发送心跳信息的Datanode会被Namenode标记为“宕机”,不会再给他分配任何I/O请求。 用户在使用Client进行I/O操作时,仍然可以像使用普通文件系统那样,使用文件名去存储和访问文件,只不过,在HDFS内部,一个文件会被切分成若干个数据块,然后被分布存储在若干个Datanode上。 比如,用户在Client上需要访问一个文件时,HDFS的实际工作流程如此:客户端先把文件名发送给Namenode,Namenode根据文件名找到对应的数据块信息及其每个数据块所在的Datanode位置,然后把这些信息发送给客户端。之后,客户端就直接与这些Datanode进行通信,来获取数据(这个过程,Namenode并不参与数据块的传输)。这种设计方式,实现了并发访问,大大提高了数据的访问速度。 HDFS集群中只有唯一的一个Namenode,负责所有元数据的管理工作。这种方式保证了Datanode不会脱离Namenode的控制,同时,用户数据也永远不会经过Namenode,大大减轻了Namenode的工作负担,使之更方便管理工作。通常在部署集群中,我们要选择一台性能较好的机器来作为Namenode。当然,一台机器上也可以运行多个Datanode,甚至Namenode和Datanode也可以在一台机器上,只不过实际部署中,通常不会这么做的

4.6.2. HDFS进程之NameNode
- namenode进程只有一个(HA除外) - 管理HDFS的命名空间,并以fsimage和edit进行持久化保存。 - 在内存中维护数据块的映射信息 - 实施副本冗余策略 - 处理客户端的访问请求
4.6.3. HDFS进程之DataNode
- 存储真正的数据(块进行存储) - 执行数据块的读写操作 - 心跳机制(3秒)
4.6.4. HDFS进程之SecondaryNamennode
- 帮助NameNode合并fsimage和edits文件 - 不能实时同步,不能作为热备份节点
4.6.5. HDFS的Client接口
- HDFS实际上提供了各种语言操作HDFS的接口。 - 与NameNode进行交互,获取文件的存储位置(读/写两种操作) - 与DataNode进行交互,写入数据,或者读取数据 - 上传时分块进行存储,读取时分片进行读取
4.6.6. 映像文件fsimage
命名空间指的就是文件系统树及整棵树内的所有文件和目录的元数据,每个Namenode只能管理唯一的一命名空间。HDFS暂不支持软链接和硬连接。Namenode会在内存里维护文件系统的元数据,同时还使用fsimage和edit日志两个文件来辅助管理元数据,并持久化到本地磁盘上。
- fsimage 命名空间镜像文件,它是文件系统元数据的一个完整的永久检查点,内部维护的是最近一次检查点的文件系统树和整棵树内部的所有文件和目录的元数据,如修改时间,访问时间,访问权限,副本数据,块大小,文件的块列表信息等等。fsimage默认存储两份,是最近的两次检查点 - 使用XML格式查看fsimage文件: [root@hadoop01 current]# hdfs oiv -i 【fsimage_xxxxxxx】 -o 【目标文件路径】 -p XML 案例如下: [root@hadoop01 current]# hdfs oiv -i fsimage_00000000052 -o ~/fs52.xml -p XML
4.6.7. 日志文件edit
集群正常运行时,客户端的所有更新操作(如打开、关闭、创建、删除、重命名等)除了在内存中维护外,还会被写到edit日志文件中,而不是直接写入fsimage映像文件。
因为对于分布式文件系统而言,fsimage映像文件通常都很庞大,如果客户端所有的更新操作都直接往fsimage文件中添加,那么系统的性能一定越来越差。相对而言,edit日志文件通常都要远远小于fsimage,一个edit日志文件最大64M,更新操作写入到EditLog是非常高效的。
那么edit日志文件里存储的到底是什么信息呢,我们可以将edit日志文件转成xml文件格式,进行查看
查看editlog文件的方式: [root@hadoop01 current]# hdfs oev -i 【edits_inprogress_xxx】 -o 【目标文件路径】-p XML
参考xml文件后,我们可以知道日志文件里记录的内容有:
1. 行为代码:比如 打开、创建、删除、重命名、关闭 2. 事务id 3. inodeid 4. 副本个数 5. 修改时间 6. 访问时间 7. 块大小 8. 客户端信息 9. 权限等 10. 块id等

4.7. HDFS的工作机制【重点】
4.7.1. 开机启动Namenode过程
4.7.1.1. 非第一次启动集群的启动流程
我们应该知道,在启动namenode之前,内存里是没有任何有关于元数据的信息的。那么启动集群的过程是怎样的呢?下面来叙述一下:
第一步:
Namenode在启动时,会先加载name目录下最近的fsimage文件.
将fsimage里保存的元数据加载到内存当中,这样内存里就有了之前检查点里存储的所有元数据。但是还少了从最近一次检查时间点到关闭系统时的部分数据,也就是edit日志文件里存储的数据。
第二步:
加载剩下的edit日志文件
将从最近一次检查点到目前为止的所有的日志文件加载到内存里,重演一次客户端的操作,这样,内存里就是最新的文件系统的所有元数据了。
第三步:
进行检查点设置(满足条件会进行)
namenode会终止之前正在使用的edit文件,创建一个空的edit日志文件。然后将所有的未合并过的edit日志文件和fsimage文件进行合并,产生一个新的fsimage.
第四步:
处于安全模式下,等待datanode节点的心跳反馈,当收到99.9%的块的至少一个副本后,退出安全模式,开始转为正常状态。
不是第一次启动,直接加载编辑日志和edits文件的情况展示:

执行流程

4.7.1.2. 第一次启动集群的启动流程
第一次启动namenode格式化后的情况展示:

注意:格式化集群后,第一次启动集群的特点,参考下图

4.7.1.3. 小知识
(1) 滚动编辑日志(前提必须启动集群)
1.可以强制滚动
[bigdata@hadoop102 current]$ hdfs dfsadmin -rollEdits
2.可以等到edits.inprogress满64m生成edits文件
3.可以等操作数量达到100万次
4.时间到了,默认1小时
注意:在2,3,4时发生滚动,会进行checkpoint
(2) 镜像文件什么时候产生
可以在namenode启动时加载镜像文件和编辑日志
也可以在secondarynamenode生成的fsimage.chkpoint文件重新替换namenode原来的fsimage文件时
4.7.2. 安全模式介绍
Namenode启动时,首先要加载fsimage文件到内存,并逐条执行editlog文件里的事务操作,在这个期间一但在内存中成功建立文件系统元数据的映像,就会新创建一个fsimage文件(该操作不需要SecondaryNamenode)和一个空的editlog文件。在这个过程中,namenode是运行在安全模式下的,Namenode的文件系统对于客户端来说是只读的,文件修改操作如写,删除,重命名等均会失败。 系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,如果满足“最小副本条件”,namenode会在30秒钟之后就退出安全模式,开始高效运行文件系统.所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。 PS:启动一个刚刚格式化完的集群时,HDFS还没有任何操作呢,因此Namenode不会进入安全模式。
-
系统离开安全模式,需要满足哪些条件?
当namenode收到来自datanode的状态报告后,namenode根据配置确定 1. 可用的block占总数的比例 2. 可用的数据节点数量符合要求之后,离开安全模式。 1、2两个条件满足后维持的时间达到配置的要求。 注意: 如果有必要,也可以通过命令强制离开安全模式。
-
与安全模式相关的主要配置在hdfs-site.xml文件中,主要有下面几个属性
1. dfs.namenode.replication.min: 最小的文件block副本数量,默认为1 2. dfs.namenode.safemode.threshold-pct: 副本数达到最小要求的block占系统总block数的百分比,当实际比例超过该配置后,才能离开安全模式(但是还需要其他条件也满足)。默认为0.999f,也就是说符合最小副本数要求的block占比超过99.9%时,并且其他条件也满足才能离开安全模式。如果为小于等于0,则不会等待任何副本达到要求即可离开。如果大于1,则永远处于安全模式。 3. dfs.namenode.safemode.min.datanodes: 离开安全模式的最小可用(alive)datanode数量要求,默认为0.也就是即使所有datanode都不可用,仍然可以离开安全模式。 4. dfs.namenode.safemode.extension: 当集群可用block比例,可用datanode都达到要求之后,如果在extension配置的时间段之后依然能满足要求,此时集群才离开安全模式。单位为毫秒,默认为1。也就是当满足条件并且能够维持1毫秒之后,离开安全模式。这个配置主要是对集群的稳定程度做进一步的确认。避免达到要求后马上又不符合安全标准。
-
相关命令
-
查看namenode是否处于安全模式
[root@hadoop01 current]# hdfs dfsadmin -safemode get Safe mode is ON
-
管理员可以随时让Namenode进入或离开安全模式,这项功能在维护和升级集群时非常关键
[root@hadoop01 current]# hdfs dfsadmin -safemode enter Safe mode is ON [root@hadoop01 current]# hdfs dfsadmin -safemode leave Safe mode is OFF
-
将下面的属性的值设置为大于1,将永远不会离开安全模式
<property> <name>dfs.namenode.safemode.threshold-pct</name> <value>0.999f</value> </property> -
有时,在安全模式下,用户想要执行某条命令,特别是在脚本中,此时可以先让安全模式进入等待状态
[root@hadoop01 current]# hdfs dfsadmin -safemode wait # command to read or write a file
-
4.7.3. DataNode与NameNode通信(心跳机制)
1. hdfs是hadoop01/slave结构,qianfeng01包括namenode和resourcemanager,slave包括datanode和nodemanager 2. hadoop01启动时会开启一个IPC服务,等待slave连接 3. slave启动后,会主动连接IPC服务,并且每隔3秒链接一次,这个时间是可以调整的,设置heartbeat,这个每隔一段时间连接一次的机制,称为心跳机制。Slave通过心跳给qianfeng01汇报自己信息,hadoop01通过心跳下达命令。 4. Namenode通过心跳得知datanode状态。Resourcemanager通过心跳得知nodemanager状态 5. 当hadoop01长时间没有收到slave信息时,就认为slave挂掉了。
注意:超长时间计算结果:默认为10分钟30秒
属性:dfs.namenode.heartbeat.recheck-interval 的默认值为5分钟 #Recheck的时间单位为毫秒
属性:dfs.heartbeat.interval 的默认值时3秒 #heartbeat的时间单位为秒
计算公式:2*recheck+10*heartbeat
4.7.4. SecondayNamenode的工作机制(检查点机制)
SecondaryNamenode,是HDFS集群中的重要组成部分,它可以辅助Namenode进行fsimage和editlog的合并工作,减小editlog文件大小,以便缩短下次Namenode的重启时间,能尽快退出安全模式。
两个文件的合并周期,称之为检查点机制(checkpoint),是可以通过hdfs-default.xml配置文件进行修改的:
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>两次检查点间隔的秒数,默认是1个小时</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>txid执行的次数达到100w次,也执行checkpoint</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>60秒一检查txid的执行次数</description>
</property>

通过上图,可以总结如下:
1. SecondaryNamenode请求Namenode停止使用正在编辑的editlog文件,Namenode会创建新的editlog文件,同时更新seed_txid文件。 2. SecondaryNamenode通过HTTP协议获取Namenode上的fsimage和editlog文件。 3. SecondaryNamenode将fsimage读进内存当中,并逐步分析editlog文件里的数据,进行合并操作,然后写入新文件fsimage_x.ckpt文件中。 4. SecondaryNamenode将新文件fsimage_x.ckpt通过HTTP协议发送回Namenode。 5. Namenode再进行更名操作。
4.7.5. HDFS 管理命令

4.8. 数据流【重点】
4.8.1. 读流程的详解
读操作:
- hdfs dfs -get /file02 ./file02
- hdfs dfs -copyToLocal /file02 ./file02
- FSDataInputStream fsis = fs.open("/input/a.txt");
- fsis.read(byte[] a)
- fs.copyToLocal(path1,path2)

详细图解

1. 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是DistributedFileSystem,它通过使用远程过程调用(RPC)来调用namenode,以确定文件起始块的位置 2. 对于每一个块,NameNode返回存有该块副本的DataNode地址,并根据距离客户端的远近来排序。 3. DistributedFileSystem实例会返回一个FSDataInputStream对象(支持文件定位功能)给客户端以便读取数据,接着客户端对这个输入流调用read()方法 4. FSDataInputStream随即连接距离最近的文件中第一个块所在的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端 5. 当读取到块的末端时,FSInputStream关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode 6. 客户端从流中读取数据时,块是按照打开FSInputStream与DataNode的新建连接的顺序读取的。它也会根据需要询问NameNode来检索下一批数据块的DataNode的位置。一旦客户端完成读取,就对FSInputStream调用close方法 注意:在读取数据的时候,如果FSInputStream与DataNode通信时遇到错误,会尝试从这个块的最近的DataNode读取数据,并且记住那个故障的DataNode,保证后续不会反复读取该节点上后续的块。FInputStream也会通过校验和确认从DataNode发来的数据是否完整。如果发现有损坏的块,FSInputStream会从其他的块读取副本,并且将损坏的块通知给NameNode
4.8.2. 写流程的详解
写操作: - hdfs dfs -put ./file02 /file02 - hdfs dfs -copyFromLocal ./file02 /file02 - FSDataOutputStream fsout = fs.create(path);fsout.write(byte[]) - fs.copyFromLocal(path1,path2)

详细图解

实现过程
图中的1和2. 客户端(操作者)通过调用DistributedFileSystem对象的create()方法(内部会调用HDFSClient对象的create()方法),实现在namenode上创建新的文件并返回一个FSDataOutputStream对象 1、DistributedFileSystem要通过RPC调用namenode去创建一个没有blocks关联的新文件,此时该文件中还没有相应的数据块信息。 2、但是在新文件创建之前,namenode执行各种不同的检查,以确保这个文件不存在以及客户端有新建该文件的权限。如果 检查通过,namenode就会为创建新文件记录一条事务记录(否则,文件创建失败并向客户端抛出一个IOException异常)。DistributedFileSystem向客户端返回一个FSDataOuputStream对象。 3.FSDataOutputStream被封装成DFSOutputStream。DFSOutputStream能够协调namenode和datanode。客户端开始 写数据到DFSOutputStream,DFSOutputStream会把数据分成一个个的数据包(packet),并写入一个内部队列,这个队列称为“数据队列”(data queue) 4.DataStreamer会去处理接受data quene,它先询问namenode这个新的block最适合存储的在哪几个datanode里(比方副本数是3。那么就找到3个最适合的datanode),把他们排成一个pipeline。DataStreamer把packet按队列输出到管道的第一个datanode中。第一个datanode又把packet输出到第二个datanode中。以此类推。DataStreamer在将一个packet流式的传到第一个DataNode节点后,还会将packet从数据队列移动到另一个队列确认队列(ackqueue)中.确认队列也是由packet组成,作用是等待datanode完全接收完数据后接收响应. 5.datanode写入数据成功之后,会为ResponseProcessor线程发送一个写入成功的信息回执,当收到管道中所有的datanode确认信息后,ResponseProcessoer线程会将该数据包从确认队列中删除。 6.客户端写完数据后会调用close()方法,关闭写入流. 7.DataStreamer把剩余的包都刷到pipeline里,然后等待ack信息,收到最后一个ack后,客户端通过调用DistributedFileSystem对象的complete()方法来告知namenode数据传输完成.
注意点1: 如果任何datanode在写入数据期间发生故障,则执行以下操作:
1. 首先关闭管道,把确认队列中的所有数据包都添加回数据队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包 2. 为存储在另一正常datanode的当前数据块制定一个新标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块 3. 从管道中删除故障datanode,基于两个正常datanode构建一条新管道,余下数据块写入管道中正常的datanode 4. namenode注意到块复本不足时,会在一个新的Datanode节点上创建一个新的复本。
注意点2
注意:在一个块被写入期间可能会有多个datanode同时发生故障,但概率非常低。只要写入了dfs.namenode.replication.min的复本数(默认1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数dfs.replication的数量(默认3)
注意点3
client运行write操作后,写完的block才是可见的,正在写的block对client是不可见的,仅仅有调用sync方法。client才确保该文件的写操作已经全部完毕。当client调用close方法时,会默认调用sync方法。
4.9. IDE远程管理HDFS【掌握】
4.9.1. 本地环境配置
4.9.1.1. Windows
-
解压到本地磁盘

-
配置环境变量


-
添加winutils.exe和hadoop.dll
Hadoop本身对Windows的支持并不友好,如果需要完整使用,需要将winutils.exe和hadoop.dll两个文件移动到%HADOOP_HOME%\bin目录
-
修改hadoop-env.cmd
@rem 这个是注释的内容 @rem 设置JAVA_HOME,使用PROGRA~1表示Program Files文件夹 set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_311
-
验证
hadoop version
4.9.1.2. MacOS
-
解压解包
tar -zxvf hadoop-3.3.1-aarch64 -C /opt/softwares
-
配置环境变量
vim ~/.bash_profile export HADOOP_HOME=/opt/softwares/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOOME/sbin
-
验证
hadoop version
4.9.2. pom文件
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
4.9.3. API之文件系统对象
@Test
public void testGetFileSystem() throws IOException {
//创建配置对象,用于加载配置信息(四个默认的配置文件:core-default.xml,hdfs-default.xml,mapred-default.xml,yarn-default.xml)
Configuration conf = new Configuration();
//修改fs.defaultFS属性的值
conf.set("fs.defaultFS","hdfs://192.168.10.101:9820");
//使用FileSystem类的静态方法get(Configuration conf);返回fs.defaultFS定义的文件系统
FileSystem fs = FileSystem.get(conf);
System.out.println("文件系统对象的类型名:"+fs.getClass().getName());
}
4.9.4. API之文件上传
@Test
public void testFileUpload() throws IOException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.10.101:9820");
FileSystem fs = FileSystem.get(conf);
//将本地的一个文件D:/file1,上传到HDFS上 /file1
//1. 使用Path描述两个文件
Path localPath = new Path("D:/file1");
Path hdfsPath = new Path("/file1");
//2.调用上传方法
fs.copyFromLocalFile(localPath,hdfsPath);
//3.关闭
fs.close();
System.out.println("上传成功");
}
4.9.5. API之文件下载
@Test
public void testFileDownload() throws IOException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.10.101:8020");
FileSystem fs = FileSystem.get(conf);
//从HDFS上下载一个文件/file1,下载到本地 D:/file2
//1. 使用Path描述两个文件
Path hdfsfile = new Path("/file1");
Path local = new Path("D:/file2");
//2. 调用下载方法进行下载
fs.copyToLocalFile(hdfsfile,local);
fs.close();
System.out.println("下载成功");
}
4.9.6. API之创建目录
@Test
public void testMkdir() throws IOException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.10.101:9820");
FileSystem fs = FileSystem.get(conf);
//1. 测试创建目录,描述一个目录
Path hdfsfile = new Path("/dir1");
//2. 调用创建目录的方法
fs.mkdirs(hdfsfile);
fs.close();
System.out.println("创建成功");
}
4.9.7. API之删除目录
@Test
public void testDelete() throws IOException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.10.101:9820");
FileSystem fs = FileSystem.get(conf);
//1. 测试删除目录,描述一个目录
Path hdfsfile = new Path("/dir1");
//2. 调用创建目录的方法
fs.delete(hdfsfile,true);
fs.close();
System.out.println("删除成功");
}
4.9.8. API之重命名
@Test
public void testRename() throws IOException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.10.101:9820");
FileSystem fs = FileSystem.get(conf);
//1. 测试重命名,将file1改为file01
Path oldName = new Path("/file1");
Path newName = new Path("/file01");
//2.调用重命名方法
fs.rename(oldName,newName);
fs.close();
System.out.println("命名成功");
}
4.9.9. IOUtil上传文件
@Test
public void putFile() throws IOException, URISyntaxException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
//1 连接HDFS 文件系统
Configuration conf=new Configuration();
//获得文件系统
FileSystem fs=FileSystem.get(new URI("hdfs://182.168.10.101:9820"),conf);
// 创建输入流,读取输入文件
FileInputStream input=new FileInputStream(new File("c://a.txt"));
// 创建输出流
FSDataOutputStream out=fs.create(new Path("/gg.txt"));
//IO的流拷贝
IOUtils.copyBytes(input, out, conf);
//关闭资源
IOUtils.closeStream(input);
IOUtils.closeStream(out);
System.out.println("上传完毕");
}
4.9.10. IOUtil下载文件
@Test
public void getFile() throws IOException, URISyntaxException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
// 1 连接HDFS 文件系统
Configuration conf = new Configuration();
// 获得文件系统
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.10.101:9820"), conf);
// 获取输入流 从HDFS上读取
FSDataInputStream input=fs.open(new Path("/gg.txt"));
// 获取输出流
FileOutputStream out=new FileOutputStream(new File("c://gg.txt"));
//流拷贝
IOUtils.copyBytes(input, out, conf);
//关闭流
IOUtils.closeStream(input);
IOUtils.closeStream(out);
System.out.println("下载完成");
}
4.9.11. API之文件状态
@Test
public void testFileStatus() throws IOException {
// 在修改HDFS的文件的时候,如果出现权限不足的情况,可以修改操作HDFS的用户
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.10.101:9820");
FileSystem fs = FileSystem.get(conf);
//1. 描述你要读取的文件 /file02
Path path = new Path("/file02");
//获取文件的状态信息
RemoteIterator<LocatedFileStatus> it = fs.listLocatedStatus(path);
while(it.hasNext()){
// 取出对象
LocatedFileStatus status = it.next();
System.out.println("name:"+status.getPath());
//获取位置
BlockLocation[] locate = status.getBlockLocations();
for(BlockLocation bl:locate){
System.out.println("当前块的所有副本位置:"+Arrays.toString(bl.getHosts()));
System.out.println("当前块大小:"+bl.getLength());
System.out.println("当前块的副本的ip地址信息:"+Arrays.toString(bl.getNames()));
}
System.out.println("系统的块大小:"+status.getBlockSize());
System.out.println("文件总长度:"+status.getLen());
}
}
完结
建议收藏!
正在更新Zookeeper!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)