
GaussDB性能调优
数据库性能调优是一项复杂且系统性的工作,需要综合考虑多方面的因素。因此,调优人员应对系统软件架构、软硬件配置、数据库配置参数、并发控制、查询处理和数据库应用拥有广泛而深刻的理解。本文旨在剖析GaussDB性能调优的总体思路,探讨系统整体性能问题,以及对锁阻塞问题进行分析和优化。
数据库性能调优是一项复杂且系统性的工作,需要综合考虑多方面的因素。因此,调优人员应对系统软件架构、软硬件配置、数据库配置参数、并发控制、查询处理和数据库应用拥有广泛而深刻的理解。
本文旨在剖析GaussDB性能调优的总体思路,探讨系统整体性能问题,以及对锁阻塞问题进行分析和优化。
一、性能调优思路
GaussDB总体性能调优的思路是:先进行性能瓶颈点分析,找到相应的瓶颈点之后,再针对性地进行优化,直到系统性能到达业务可接受的范围内。
调优思路,如图1所示:

图1 GaussDB总体性能调优思路
首先,应该确认应用压力是否传递到数据库,可以通过分析数据库节点的资源使用情况,如CPU、I/O、内存以及数据库线程池、活跃会话等信息来辅助判断。GaussDB数据库的管控平台提供了丰富的监控指标体系,便于性能分析人员查看数据库的实时或者历史资源使用情况。
登录管控平台后,进入监控巡检菜单,选择监控大盘,即可查看对应实例的CPU/内存使用率,如图2所示。

图2 对应实例的CPU/内存使用率
点击磁盘/存储菜单,可以查看磁盘I/O使用率,重点关注磁盘读写速率以及时延是否符合预期,如图3所示。

图3 磁盘读写速率以及时延情况
点击网络菜单,可以查看网络传输速率及网卡是否有丢包、错包等情况,如图4所示。
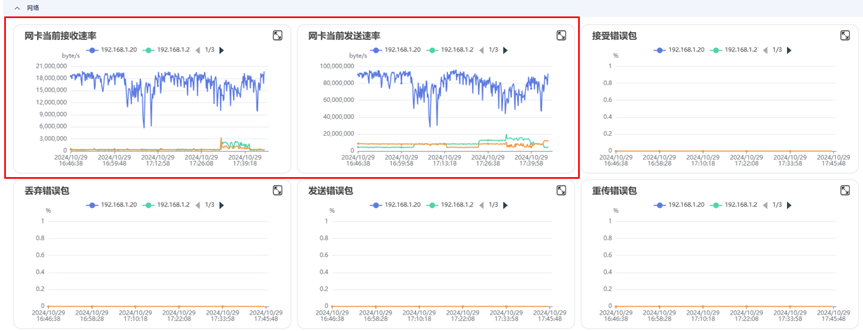
图4 网络传输速率及网卡发送速率
选择连接菜单,可以查看数据库的连接及会话状态,如图5所示。

图5 连接及会话状态
图5中,如果活跃会话的占比远低于应用的并发数,说明数据库中大量会话处于空闲状态。同时,如果CPU使用率也很低,那么,就可以判断压力没到达数据库,此时需要排查应用端是否存在瓶颈。
导致应用侧瓶颈的问题比较常见的原因有:
1)应用服务器资源瓶颈。比如,应用服务器的CPU满载,应用程序内存分配不足等;
2)应用到数据库网络问题。比如,网络时延高,带宽满,存在丢包现象等;
3)应用自身逻辑处理速度慢;
4)应用配置不优,比如连接池参数、内存相关配置等设置不当。
例如,某个客户通过 jmeter 做大并发压测,性能不及业务预期。经过分析,发现是 jmeter 工具分配的最大可用内存不足,导致压力没有到达数据库。通过修改如下配置,问题得到了解决。
编辑jmeter.sh文件:
set HEAP=-Xms1g -Xmx4g确认压力到达数据库后,再针对相应的瓶颈点进行分析优化。主要从以下两个方面进行:
1)排查数据库中是否存在性能不优的业务SQL语句,并对性能不优的SQL进行优化。通过如下语句,查看数据库中耗时高的TOP SQL语句,并对那些执行性能不符合预期的SQL语句逐一进行分析与调优。
select unique_sql_id,substr(query,1,50) as
query ,n_calls,round(total_elapse_time/n_calls/1000,2)
avg_time,round(total_elapse_time/1000,2) as total_time from
dbe_perf.summary_statement t where n_calls>10 and avg_time>3
and user_name='root' order by total_time desc;如图6所示,n_calls 表示该SQL语句在数据库中的执行次数,avg_time 为该SQL 语句的平均执行时间,total_time 为该SQL语句的总耗时。对于平均执行时间超过阈值的SQL语句,重点进行分析与优化。

图6 SQL语句指标及对应数据展示
针对执行性能不优的SQL语句,通过unique_sql_id可以查看该SQL语句的执行详情,帮助分析SQL语句的性能瓶颈点。
select * from dbe_perf.statement where
unique_sql_id=3508314654;如图7所示,该视图记录了SQL语句在数据库的详细执行情况,比如,总执行次数(n_calls)和总耗时(total_elapse_time),便于获取该SQL的总耗时以及平均耗时。
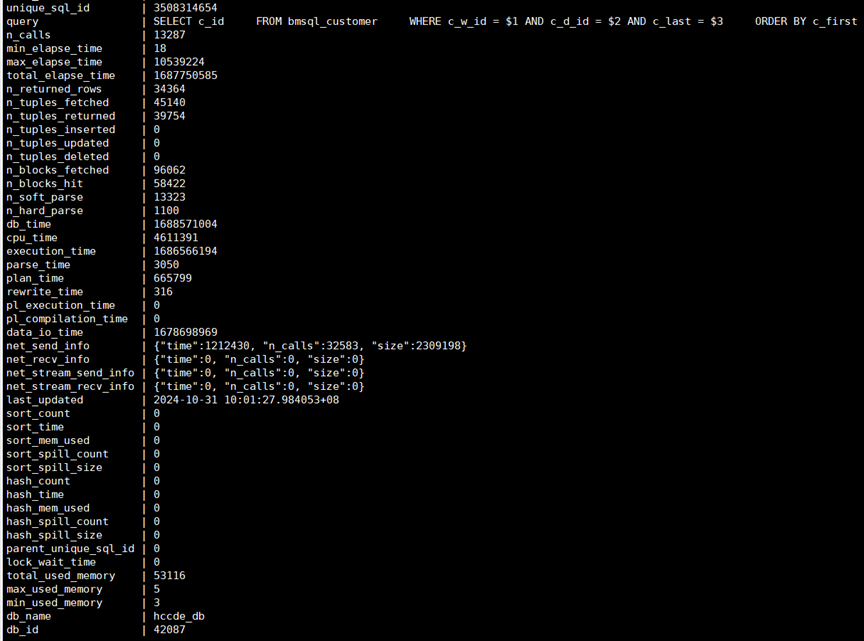
图7 SQL语句在数据库中的详细执行情况视图
行活动,包括随机扫描、顺序扫描行数、返回的行数、插入/更新/删除的行数以及buffer命中的页面数等信息。此外,还记录了软解析(n_soft_parse)、硬解析(n_hard_parse)的次数,比如SQL大量硬解析导致的数据库CPU飚高,可以通过该指标进行分析定位。
时间模型,包含db_time、cpu_time、execution_time、plan_time、data_io_time、net_send_info、net_recv_info、sort_time以及hash_time等指标,有助于判断SQL在数据库中的时间消耗在哪个阶段。例如,若某环境磁盘性能不佳,则data_io_time的耗时占比就会比较高。
如果需要进一步分析SQL本身的性能问题,比如执行计划是否最优、索引是否最优等性能问题,可以借助SQL的执行计划进行分析。
通过如下方式,可查看SQL的执行计划:
explain analyze SELECT c_id
FROM bmsql_customer
WHERE c_w_id = 1 AND c_d_id = 1 AND c_last = 'ABLEABLEABLE'
ORDER BY c_first;结合SQL的执行计划,分析SQL性能的瓶颈点,再进行性能优化,如图8所示。

图8 SQL性能优化过程
2)从系统层面进行操作系统级和数据库系统级的调优,充分利用机器的CPU、内存、I/O和网络资源,避免资源冲突,从而提升整个系统查询的吞吐量。
二、系统级性能问题分析
2.1 CPU使用率高
数据库的CPU使用率高,通常是由业务SQL语句引起的。我们可以通过如下方式,获取数据库中消耗CPU资源高的SQL语句,并对相应的业务SQL语句进行优化。
select unique_sql_id,substr(query,1,50) as
query ,n_calls,round(total_elapse_time/n_calls/1000,2)
avg_time,round(total_elapse_time/1000,2) as
total_time,round(cpu_time/1000,2) as cup_time from dbe_perf.statement
t where n_calls>10 and avg_time>3 and user_name='root'
order by cpu_time desc limit 5;常见的导致CPU资源消耗高的原因有:
1)SQL语句大量使用了全表扫描,这可能是由索引缺失、索引失效、执行计划不优等因素所导致。
2)SQL语句大量进行硬解析,通常是因为应用逻辑未使用PBE(Prepare Bind Execute)。
3)SQL语句扫描了大量的元组,比如,分区表分区剪枝失效,扫描了全分区,表中存在大量的死元组,导致扫描了大量无用页面等。
如果CPU使用率高是由非业务SQL语句引起的,可以借助火焰图来进行分析定位。通过火焰图,可以直观地了解程序中哪些函数占用了大量的 CPU 时间或资源,并且可以追踪函数调用路径。
GaussDB在内核505版本中内置了火焰图工具,默认每5分钟会自动采集一次,保存在$GAUSSLOG/gs_flamegraph/{datanode}路径下,详细信息可参考GaussDB产品文档《内置perf工具》章节。
例如,某客户在压测过程中发现数据库服务器的CPU SYS占用率超过70%,通过抓取压测期间的火焰图进行分析,如图9所示,发现数据库加载时区文件的线程占比超过40%。
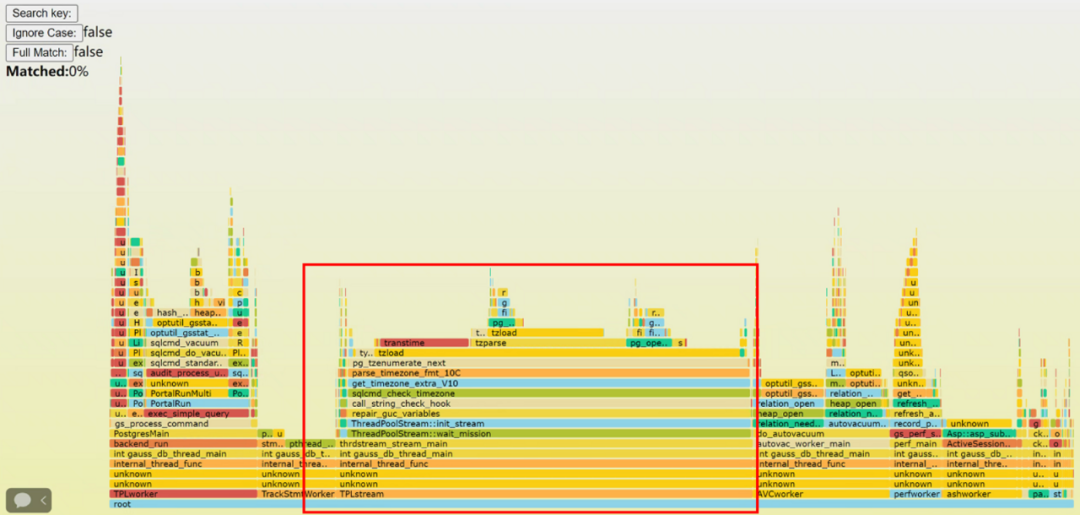
图9 某客户压测期间的火焰图
经分析,原因是在高并发频繁建立连接时,数据库每次建连都需要读取时区文件以获取时区信息,而应用未使用长连接,导致CPU SYS使用率飙升。
2.2 内存不足
内存资源,也是影响数据库性能的关键因素之一。在分析内存问题之前,我们先了解一下GaussDB的内存管理机制。
如图10所示,GaussDB的内存管理采用动态内存与静态内存相结合的方式,由参数 max_process_memory控制数据库可用的最大内存。
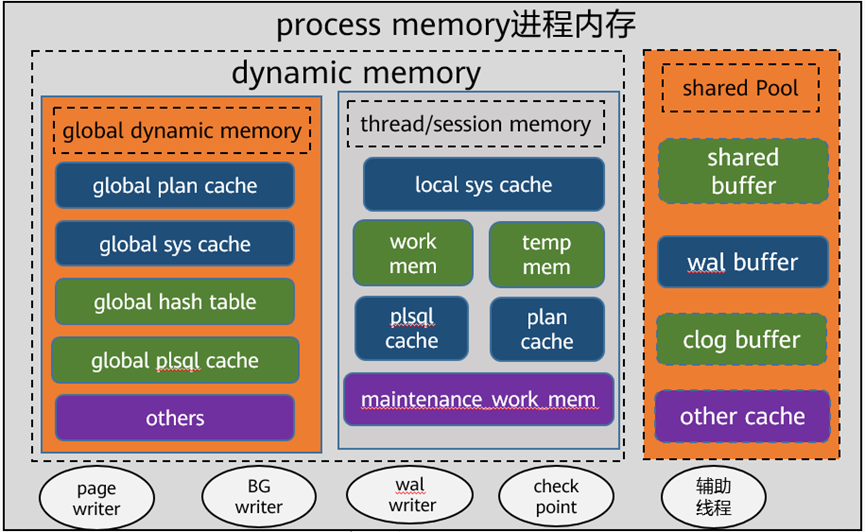
图10 GaussDB的内存管理机制
其中,静态内存区域主要用作数据库的共享缓冲区,用于缓存数据页面,由shared_buffers参数控制。动态内存区域,则由数据库根据需要进行动态分配,主要包括元数据的缓存、执行计划的缓存、用户建连以及内部线程的内存消耗等。
内存导致的性能问题,通常分为以下几个方面:
1)共享缓存区不足,导致SQL的buffer命中率低。为了查看相应的性能指标,可以借助GaussDB的管控平台或者WDR报告。通常情况下,TP数据库的buffer命中率应该在99%以上。如果数据库的buffer命中率较低,建议排查数据库的shared_buffers参数设置是否合理(如图11所示)。
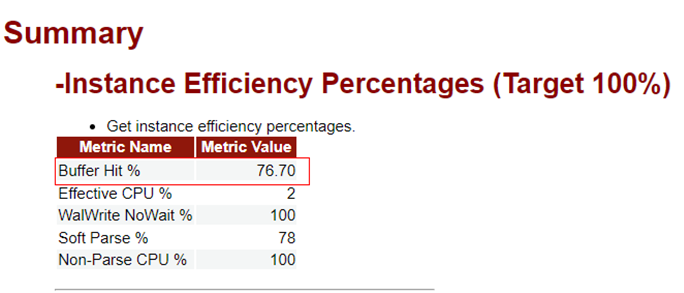
图11 数据库的buffer命中率
2)在GaussDB中,SQL的hash join或者sort算子存在数据落盘操作,work_mem参数控制可下盘算子可用的物理内存空间。如果work_mem所限定的物理内存不够,算子运算的数据将被写入临时表空间,会带来5-10倍的性能下降。为了优化性能,可以查看SQL的执行计划,如果算子存在落盘的情况(如图12所示),可适当调整work_mem参数值。

图12 算子落盘情况
3)数据库动态内存不足,导致业务执行报错(ERROR:memory is temporarily unavailable )或者性能不足。当动态内存不足时,可以通过如下SQL语句找出内存消耗高的SQL语句,以便排查是否存在不优的SQL 语句。借助SQL的执行计划分析,可以检查是否有不合理的join顺序,或者是否存在非必要的排序操作,从而避免消耗大量内存。
select unique_sql_id,substr(query,1,50) as
query ,n_calls,round(total_elapse_time/n_calls/1000,2)
avg_time,round(total_elapse_time/1000,2) as
total_time,hash_mem_used,sort_mem_used
from dbe_perf.statement t
where n_calls>10 and avg_time>3
and user_name='root' order by (hash_mem_used+sort_mem_used) desc;如果需要排查由非业务SQL语句导致的异常的内存消耗问题,比如内存堆积、内存泄露等,GaussDB提供了丰富的内存相关的监控视图,可以通过下面的视图(如图13所示),查看数据库节点的内存消耗情况。

图13 GaussDB内存相关的监控视图
基于上面的查询结果,如果dynamic_used_shrctx的占用率高,说明是全局共享动态内存的占用高。可以通过如下SQL语句,查看全局共享动态内存上下文的消耗情况。
select contextname, sum(totalsize)/1024/1024 totalsize,
sum(freesize)/1024/1024 freesize, count(*) count from
gs_shared_memory_detail group by contextname order by
totalsize desc limit 10;如果max_dynamic_memory的占用率高,但是dynamic_used_shrctx的占用率低,那么说明是线程或者会话占用的内存多。可以通过如下SQL语句,查询数据库线程的内存上下文消耗情况。
select contextname, sum(totalsize)/1024/1024 totalsize,
sum(freesize)/1024/1024 freesize, count(*) sum from
gs_thread_memory_context group by contextname order by sum desc limit 10;查询结果如图14所示,可以看出,当前数据库中内存占用最高的为元数据的缓存(LocalSysCacheShareMemory)。结合图14中的查询结果,排查是否存在不合理的内存占用情况。

图14 数据库线程的内存上下文消耗情况
2.3 IO瓶颈
通过 iostat 命令,可以查看数据库节点 I/O 的繁忙度和吞吐量,分析是否存在由于I/O 导致的性能瓶颈。如图15所示:

图15 数据库节点 I/O 的繁忙度和吞吐量
重点关注磁盘的读写吞吐量和读写时延。通常情况下,SSD盘的读写时延在2ms以下,单盘带宽在300MB以上。如果磁盘性能存在异常,优先排查硬件是否存在故障,如磁盘存在坏盘、慢盘、RAID卡故障或磁盘读写策略不正确等;如果磁盘硬件性能正常,而I/O 压力大,可以适当调整数据库I/O 相关的参数,以降低数据的I/O 消耗,从而优化数据库的整体性能。
I/O 相关的关键参数链接如下:
后端写进程:https://support.huaweicloud.com/distributed-devg-v2-gaussdb/gaussdb-12-1124.html
异步I/O:https://support.huaweicloud.com/distributed-devg-v2-gaussdb/gaussdb-12-1125.html
2.4 网络异常
在传统集中式数据库环境下,应用服务器与数据库服务器通常部署在同一个机房内,从而确保应用与数据库间的网络开销较小。然而,在云+分布式数据库环境下,应用服务器到数据库服务器的网络链路较长,网络耗时对交易性能至关重要。在此情境下,我们不仅需要关注应用与数据库之间的网络状况(通常应该小于0.2ms),还需考虑数据库内部节点之间的网络情况,也会对性能产生较大的影响。
GaussDB要求AZ内网络时延小于0.2ms,AZ间的网络时延小于2ms,region间网络时延小于100ms。可以通过linux的ping命令,排查两个服务器之间的网络时延及丢包等情况,如图16所示。
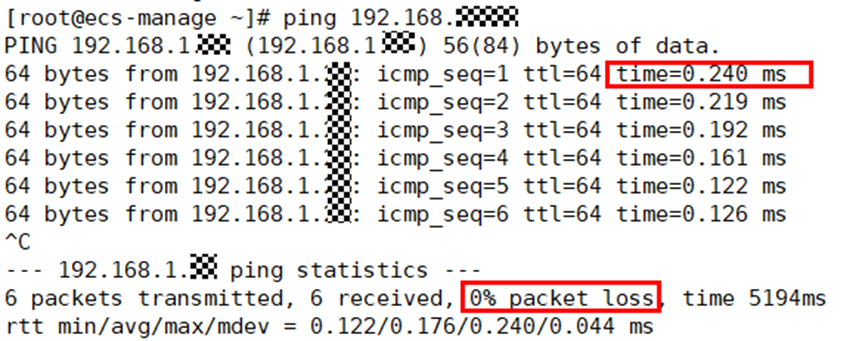
图16 ping命令,排查两个服务器之间的网络时延及丢包等情况
通过 sar -n DEV 1 命令,查看网络的传输情况。
如图17所示,“rxkB/s”为每秒接收的千字节数,“txkB/s”为每秒发送的千字节数,主要关注每个网卡的传输量是否达到传输上限。

图17 sar -n DEV 1 命令,网络传输情况
三、锁阻塞问题分析
数据库锁机制是一种用于管理并发访问的技术。它通过对数据库中的数据进行锁定,来确保在多个用户并发访问数据库时数据的一致性和完整性。
在并发访问的场景下,经常会遇到因为锁冲突导致的性能问题。下面我们看一下在GaussDB中应该如何定位和分析锁冲突的问题。
如果应用正在运行,可以通过下面的SQL语句,查看当前数据库中正在执行的会话是否存在锁阻塞。
集中式场景:
SELECT a.pid as w_pid,a.query as w_query,a.state,d.query as locking_query,d.state as l_state,d.pid as l_pid,d.sessionid as l_sessionid
FROM pg_stat_activity AS a
JOIN pg_thread_wait_status b ON b.query_id = a.query_id
JOIN pg_thread_wait_status c
ON c.sessionid = b.block_sessionid and c.node_name=b.node_name
JOIN pg_stat_activity d
on d.sessionid=c.sessionid
;分布式场景:
SELECT a.pid as w_pid,a.query as w_query,a.state as w_state, a.datname, a.usename,d.query as lock_query,d.state as l_state,d.pid as l_pid,d.sessionid as l_sessionid
FROM pgxc_stat_activity AS a
JOIN pgxc_thread_wait_status b ON b.query_id = a.query_id
JOIN pgxc_thread_wait_status c ON c.sessionid = b.block_sessionid and c.node_name=b.node_name
JOIN pgxc_stat_activity d
on substring(d.global_sessionid,0,instr(d.global_sessionid,'#')) ilike substring(c.global_sessionid,0,instr(c.global_sessionid,'#'))
;查询结果如图18所示,可以获取当前库中存在锁阻塞的SQL语句,同时获取到阻塞它的会话ID、线程ID以及对应的查询。

图18 锁阻塞查询结果展示
要找到并结束阻塞当前查询的会话,可以使用以下语句。
SELECT PG_TERMINATE_BACKEND(pid);如果是历史的锁阻塞导致的性能问题,可以通过下面语句查询指定时间段内的数据库等待事件。如果发现有大量的acquire lock(包括transaction ID、relation、tuple)事件,表示该时间段内数据库存在锁阻塞问题。
select wait_status,event,count(*) from gs_asp
where sample_time>='20241016 18:45:00' and sample_time <='20241016 19:00:00'
group by 1,2 order by 3 desc;ASP(Active Session Profile,活跃会话概要信息),通过采样实例中活跃会话的状态信息,以低成本的方式复现过去一段时间内的系统活动,主要包含会话基本信息、会话事务、执行的语句、等待事件、会话状态(如active、idle等)、当前正阻塞在哪个事件上、正在等待哪个锁或被哪个会话阻塞。
如图19所示,该时间段数据库占比最高的两个等待事件,一个是等待dn_6004_6005_6006分片返回执行结果,这需要进一步排查该分片上性能瓶颈的原因;另外一个等待事件是acquire lock(relation),表示存在大量的表级锁等待。
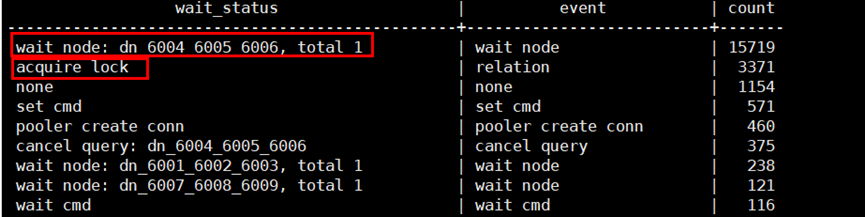
图19 特定事件内数据库占比最高的两个等待事件
结合数据库的归一化视图,可以获取数据库中存在锁等待的SQL语句,如图20所示。
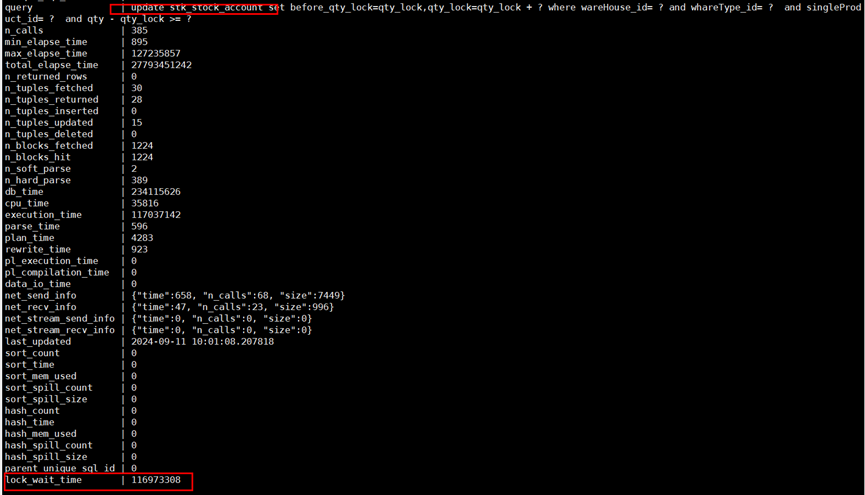
图20 获取数据库中存在锁等待的SQL语句
通过该语句的Unique_query_id,获得查询阻塞该语句的query_id。
execute direct on datanodes $$select
t1.unique_query_id,t1.thread_id,t1.sessionid,t1.wait_status,t1.event,t1.state,
t2.query_id as lock_query_id
from gs_asp t1,gs_asp t2
where t1.block_sessionid=t2.sessionid and
t1.unique_query_id=168353725$$;如图21所示,lock_query_id 为阻塞该SQL语句的query_id。

图21 获取阻塞锁等待SQL语句的query_id
利用上一步查询出来的query_id,并结合gs_asp视图,可以通过如下语句获取该SQL语句的详情。查询结果如图22所示,可以看到,阻塞该语句的也是同一张表的update语句,这表明是由于并发更新同一行数据所导致的锁冲突。

图22 锁等待的SQL语句查询结果
通常情况下,解决并发更新锁冲突问题的解决思路需要从业务角度出发,审视存在并发更新同一行的情况是否符合业务场景。如果业务中不存在这样的场景,那应该从业务逻辑或者业务数据上进行优化,以避免并发更新同一行的情况发生。
四、总结
数据库性能调优涉及硬件、操作系统、数据库、应用等多个层面,因此,在性能调优过程中,需要综合考虑各方面因素的影响。本文介绍了在GaussDB中分析性能问题时常见的手段和思路,帮助大家熟悉GaussDB数据库性能诊断常用的工具及使用方法。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 34
34 0
0- 0



 已为社区贡献475条内容
已为社区贡献475条内容

所有评论(0)