
领取云主机,带你基于PyTorch构建高效手写体识别系统
利用深度学习框架PyTorch,结合MNIST手写体数据集,构建一个高效、准确的手写体识别系统,在云主机中安装PyCharm,并且基于PyTorch框架实现手写体识别。
摘要:利用深度学习框架PyTorch,结合MNIST手写体数据集,构建一个高效、准确的手写体识别系统,在云主机中安装PyCharm,并且基于PyTorch框架实现手写体识别。
本文分享自华为云社区《【开发者空间实践指导】基于PyTorch的手写体识别》,作者:开发者空间小蜜蜂。
1.1 案例介绍
随着人工智能技术的飞速发展,图像识别技术在众多领域得到了广泛应用。手写体识别作为图像识别的一个重要分支,其在教育、金融、医疗等领域具有广泛的应用前景。本实验旨在利用深度学习框架PyTorch,结合MNIST手写体数据集,构建一个高效、准确的手写体识别系统,本实验是在云主机中安装PyCharm,并且基于PyTorch框架的手写体识别的案例。
本实验采用的MNIST数据库(Modified National Institute of Standards and Technology database)是一个大型数据库的手写数字是通常用于训练各种图像处理系统。该数据库还广泛用于机器学习领域的培训和测试。MNIST数据集共有训练数据60000项、测试数据10000项。每张图像的大小为28*28(像素),每张图像都为灰度图像,位深度为8(灰度图像是0-255)。
1.2 免费领取云主机
如您还没有云主机,可点击链接,领取专属云主机后进行操作。
如您已领取云主机,可直接开始实验。
1.3 实验流程
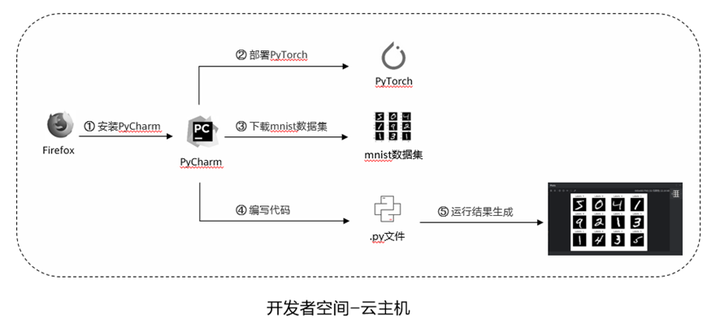
说明:
① 下载并安装PyCharm;
② 创建Python文件,部署PyTorch;
③ 下载测试数据集、训练数据集和验证数据集;
④ 编写代码,实现手写体识别;
⑤ 运行代码,生成结果。
1.4 实验资源
| 云资源 | 消耗/时 | 时长 |
| 开发者空间-云主机 | 免费 | 40分钟 |
合计:0元
1.5 安装PyCharm
1.下载PyCharm
进入云主机,打开左侧Firefox浏览器,搜索Thank you for downloading PyCharm!点击下载PyCharm。
下载好后是一个压缩文件,选择将文件压缩到此处。
解压后目录内容显示如下。
2.安装PyCharm
双击进入bin目录,双击PyCharm图标打开PyCharm。
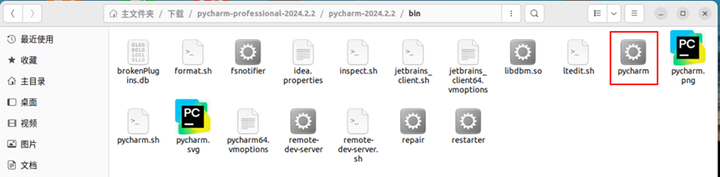
在PyCharm的左下角单击图标打开终端。
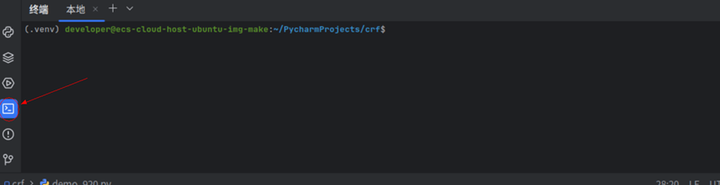
进入到终端后输入命令进入到bin目录下。
cd 下载
cd pycharm-2024.2.1
cd bin
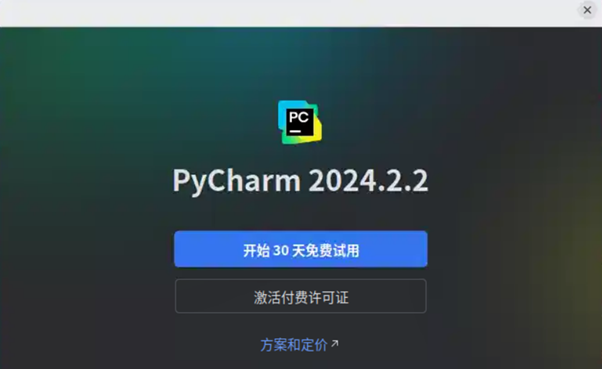
执行完命令后会自动弹出窗口,选择“开始30天免费试用”。
1.6 下载PyTorch框架
1.新建目录
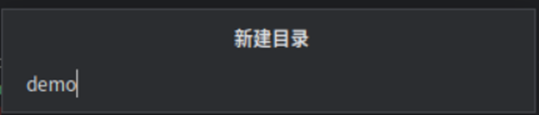
打开PyCharm,单击左上角图标在弹出的菜单中选择“新建>目录”。
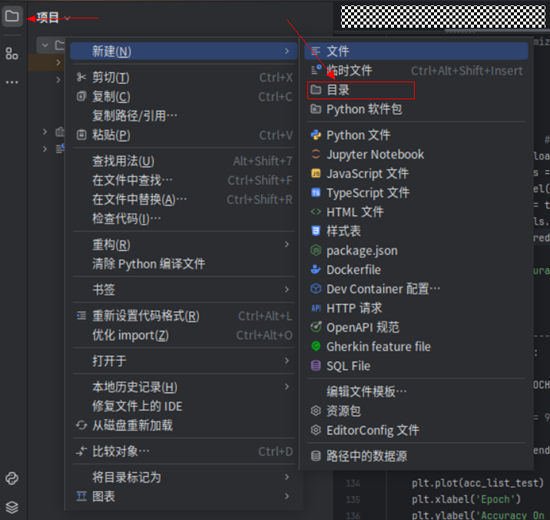
目录名称输入:demo。
2.新建文件
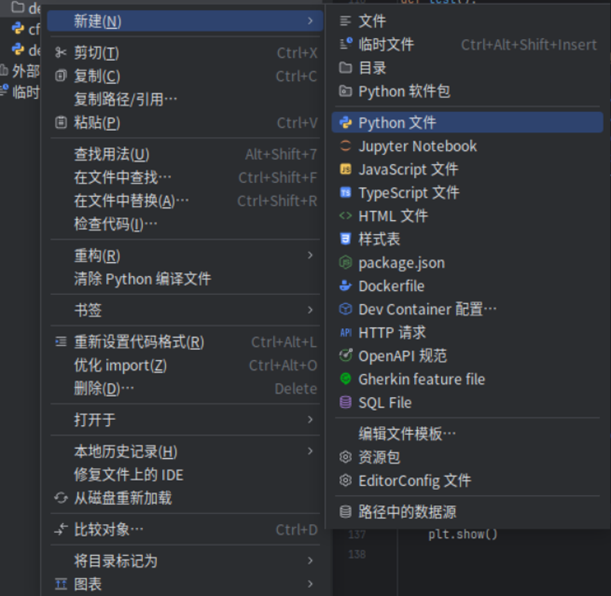
在PyCharm左侧新建的demo目录单击鼠标右键,在打开的菜单中选择“新建>Python文件”。
输入Python文件的名字,自定义即可。
3.部署Python框架
新建好后,在左侧找到新建好的Python文件双击打开。
单击左下角图标打开终端。
在终端输入命令,部署Python框架。
pip3 install torch torchvision torchaudio --index-url htt ps://download.pytorch.org/whl/cpu

1.7 数据集介绍
1.创建目录
在同一项目目录下创建文件夹data,在data目录下创建mnist目录。
2.数据集详细介绍
1)测试集图片,包含10000张图。
t10k-images.idx3-ubyte
2)标签集,包含10000张测试集图片所对应的标签。
t10k-labels.idx1-ubyte
3)训练集和验证集,包含55000张训练集和5000张验证集图片。
train-images.idx3-ubyte
4)标签集,包含训练集图片所对应的标签。
train-labels.idx1-ubyte1.8 编写代码
1.创建和编写文件
在demo目录下新建一个py文件进行代码编辑。(复制文档中的Python代码时,可能会造成格式错误,可以从下载的试验资料中获取的demo.txt中获取代码内容!)
import torch
import numpy as np
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
"""
卷积运算 使用mnist数据集,和10-4,11类似的,只是这里:1.输出训练轮的acc 2.模型上使用torch.nn.Sequential
"""
batch_size = 64
learning_rate = 0.01
momentum = 0.5
EPOCH = 10
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# softmax归一化指数函数,其中0.1307是mean均值和0.3081是std标准差
train_dataset = datasets.MNIST(root='./data/mnist', train=True, transform=transform,download=True) # 本地没有就加上download=True
test_dataset = datasets.MNIST(root='./data/mnist', train=False, transform=transform,download=True) # train=True训练集,=False测试集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i+1)
plt.tight_layout()
plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none')
plt.title("Labels: {}".format(train_dataset.train_labels[i]))
plt.xticks([])
plt.yticks([])
plt.show()
# 训练集乱序,测试集有序
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 10, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(10, 20, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.fc = torch.nn.Sequential(
torch.nn.Linear(320, 50),
torch.nn.Linear(50, 10),
)
def forward(self, x):
batch_size = x.size(0)
x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)
x = self.conv2(x) # 再来一次
x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320
x = self.fc(x)
return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)
model = Net()
# Construct loss and optimizer ------------------------------------------------------------------------------
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量
# Train and Test CLASS --------------------------------------------------------------------------------------
# 把单独的一轮一环封装在函数类里
def train(epoch):
running_loss = 0.0 # 这整个epoch的loss清零
running_total = 0
running_correct = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# 把运行中的loss累加起来,为了下面300次一除
running_loss += loss.item()
# 把运行中的准确率acc算出来
_, predicted = torch.max(outputs.data, dim=1)
running_total += inputs.shape[0]
running_correct += (predicted == target).sum().item()
if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率
print('[%d, %5d]: loss: %.3f , acc: %.2f %%'
% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))
running_loss = 0.0 # 这小批300的loss清零
running_total = 0
running_correct = 0 # 这小批300的acc清零
# torch.save(model.state_dict(), './model_Mnist.pth')
# torch.save(optimizer.state_dict(), './optimizer_Mnist.pth')
def test():
correct = 0
total = 0
with torch.no_grad(): # 测试集不用算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标
total += labels.size(0) # 张量之间的比较运算
correct += (predicted == labels).sum().item()
acc = correct / total
print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数
return acc
# Start train and Test --------------------------------------------------------------------------------------
if __name__ == '__main__':
acc_list_test = []
for epoch in range(EPOCH):
train(epoch)
# if epoch % 10 == 9: #每训练10轮 测试1次
acc_test = test()
acc_list_test.append(acc_test)
plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy On TestSet')
plt.show()当代码编写完毕后在导包的部分会出现爆红(在包名下面会出现红色波浪线)的情况,直接将鼠标放到爆红(代码下方会出现)部分,会自动弹出下载,然后点击“下载”即可。如果没有弹出下载,请打开终端,在终端输入命令:pip3 install matplotlib 指令下载。

2.代码部分讲解
1)导入数据包
首先对于导包部分导入,Pytorch、NumPy、Matplotlib等库,用于进行深度学习模型
的构建数据可视化。

2)设置超参数
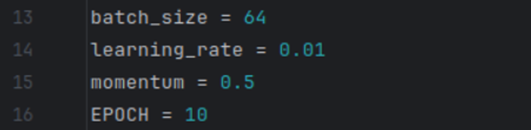
这里定义了几个训练过程中的重要参数:
batch_size:每次训练的样本数量;
Learning_rate:学习率,用于控制模型权重更新的幅度;
momentum:动量,用于加速训练过程中的权重更新;
EPOCH:训练的总轮数。
3)数据预处理
这一串代码定义了数据预处理的流程,包括将图片转换为张量,并进行标准理。
加载MNIST数据集,并将其分为训练集和测试集,同时用DataLoader来批量加载数据集。

使用Matplotlib显示部分训练数据,以便直观地了解数据集。
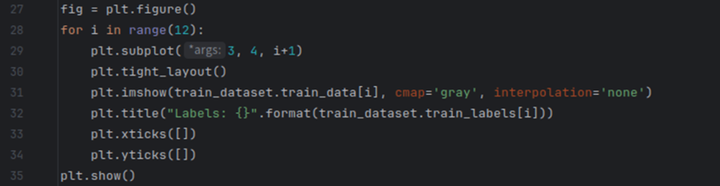
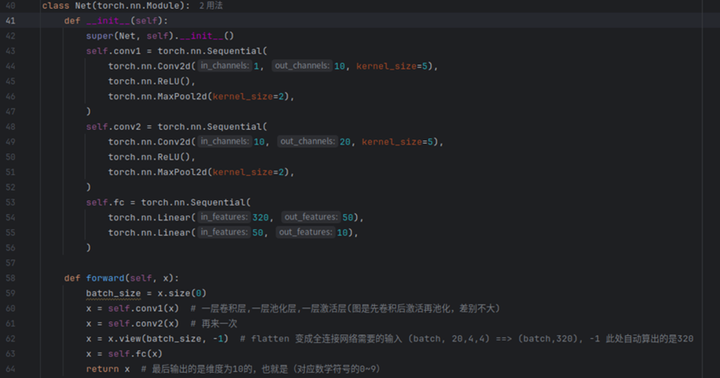
4)创建模型和函数
定义一个卷积神经网络模型NET,包括两个卷积层和两个全连接层。
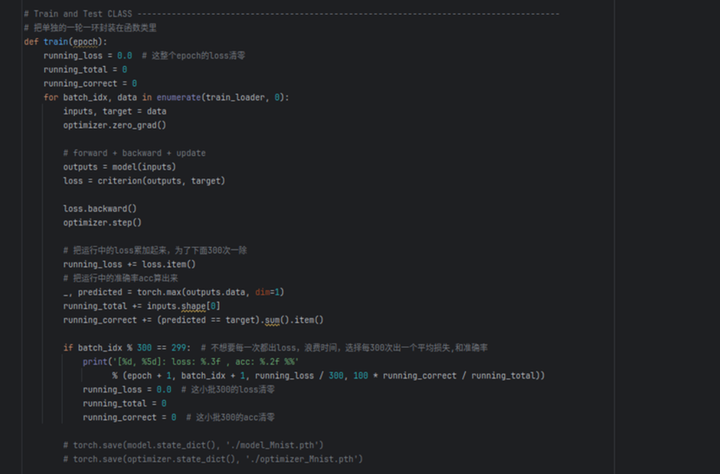
创建模型实例,交叉熵损失函数和梯度下降的优化器。

定义训练和测试的函数,分别用于训练模型和在测试集上评估模型性能训练函数。
编写测试函数。
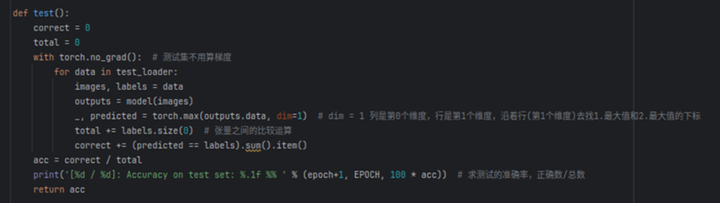
最后是主函数,这里:
1.对模型进行指定轮数的训练;
2.在每个训练轮数后,测试模型性能,并将其准确记录下来;
3.最后绘制测试集准确率随着训练轮数的变化图。
1.9 运行结果生成
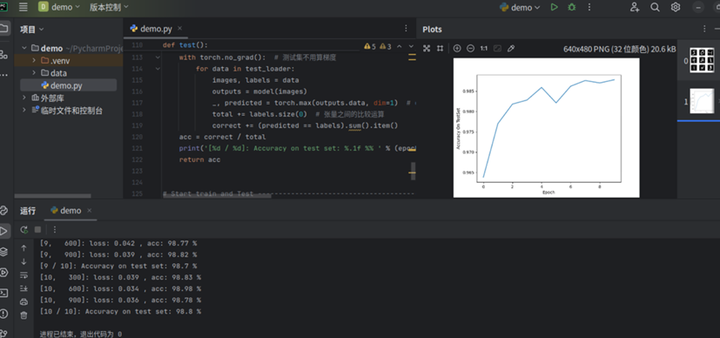
代码编写完毕后右击鼠标,点击运行。
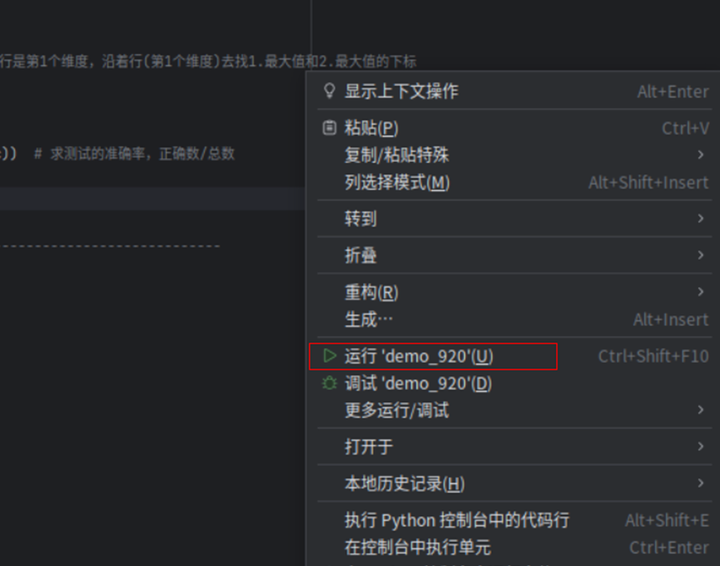
运行后会出现手写体识别的结果,可以看到在数据集图片上放有Labels字样,后面紧跟着就是手写体识别后识别出来的数字。
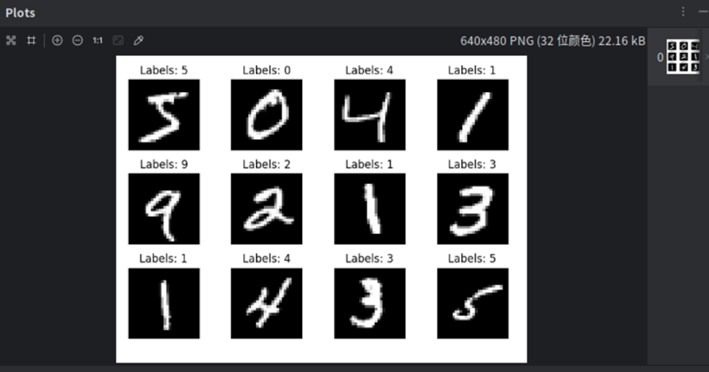
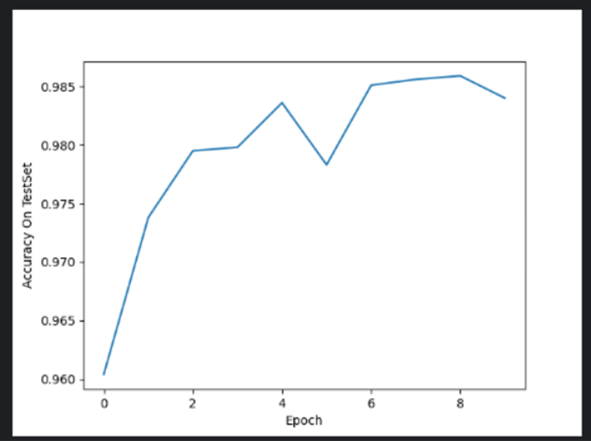
运行结果中有loss损失函数,以及acc准确率,可以看到loss损失函数在慢慢的降低,而acc准确率在慢慢的升高。acc准确率提高的原因是因为训练轮数的不断增加,交叉熵损失衡量了模型预测与真实标签之间的差异。在训练过程中,优化器的目标是使损失函数最小化。随着训练轮数的增加,损失函数的值逐渐降低,这意味着模型的预测越来越接近真实标签,从而提高准确率。
acc准确率折线图,横轴表示训练轮次,纵轴表示准确率,acc准确率的提高因为训练轮数的不断增加,模型通过不断地优化参数,逐步学习到数据中的特征和模式,减少预测误差,从而提高在测试集上的准确率。
至此,实验完毕。
想了解更多手写体识别的内容可以访问:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
想了解更多关于PyTorch框架的可以访问:https://pytorch.org/
华为开发者空间,汇聚鸿蒙、昇腾、鲲鹏、GaussDB、欧拉等各项根技术的开发资源及工具,致力于为每位开发者提供一台云主机、一套开发工具及云上存储空间,让开发者基于华为根生态创新。点击链接,领取您的专属云主机!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 17
17 0
0- 0



 已为社区贡献5832条内容
已为社区贡献5832条内容

所有评论(0)