Hadoop入门系列(1) -- Hadoop简介
Hadoop主要由HDFS、MapReduce和Hbase组成。 它是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下开发分布式程序。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。本文将主要从Hadoop的MapReduce并行框架出发,HDFS和HBase不会涉及,有兴趣可以自己查看资料。Google云计算的三大法器谷歌发表
Hadoop主要由HDFS、MapReduce和Hbase组成。 它是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下开发分布式程序。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
本文将主要从Hadoop的MapReduce并行框架出发,HDFS和HBase不会涉及,有兴趣可以自己查看资料。
Google云计算的三大法器
谷歌发表的三篇论文奠定了大数据计算的基础,它们分别提出了GFS、MapReduce、BigTable。下面引用 [ 那些年Google公开的大数据领域论文]中的介绍
按时间算第一篇的论文应该2003年公布的 Google File System,这是一个分布式文件系统。从根本上说:
文件被分割成很多块,使用冗余的方式储存于商用机器集群上;这里不得不说基本上Google每篇论文都是关于“商用机型”。
紧随其后的就是2004年被公布的 MapReduce,而今MapReuce基本上已经代表了大数据。传说中,Google使用
它计算他们的搜索索引。而Mikio L. Braun认为其工作模式应该是:Google把所有抓取的页面都放置于他们
的集群上,并且每天都使用MapReduce来重算。
Bigtable发布于2006年,启发了无数的NoSQL数据库,比如:Cassandra、HBase等等。Cassandra架构中有一半
是模仿Bigtable,包括了数据模型、SSTables以及提前写日志(另一半是模仿Amazon的Dynamo数据库,
使用点对点集群模式)。
MapReduce基本原理
MapReduce是Google提出的计算模式,并已经有多个实现系统。通过它,可以方便地进行大规模分布式计算,硬件上的容错性也能够有效保障。MapReduce技术已经有了多个版本的开源实现,如开源框架Hadoop的MapReduce,还有近年来的开源框架Spark也采用了MapReduce的技术。
MapReduce的流行是有理由的。它非常简单,易于扩展。基于它实现的应用程序能够运行在大量服务器组成的集群中,并可以以一种可靠方式处理T级以上的的数据集,实现数据和任务并行和分布地计算与处理。
MapReduce作业(job)会先把数据集切切割成若干个小数据块,再由多个map任务(map task)以并行的方式来处理它们。框架会对map输出的中间结果进行shuffle(洗牌)等操作,然后把结果输出到reduce任务(reduce task)。reduce任务合并数据,并形成最终的结果,保存到分布式文件系统(Hadoop对应的是HDFS文件系统)中。
MapReduce框架很好地把并行任务调度、任务容错、空间局部性优化,以及节点间的负载均衡等,实现在模型内部,从而把复杂的并行化处理过程抽象为只要实现map和reduce两个接口函数即可。我们只要编写实现map函数和reduce函数,框架会自动管理map task和reduce task并行任务的执行和任务之间的协调,并提供高可靠的容错机制。
MapReduce中的map过程和reduce过程,借鉴了Lisp等函数式编程语言中的map和reduce的思想。map过程把一组数据集合的每个元素通过map函数把它映射到另一个数据集合中,reduce过程把一组数据进行合并,如进行统计或求合操作等。如求解一个问题,“求小于4的自然数的平方和”。它的map和reduce过程如下
input=range(1,4) # 枚举
inter_data=map(lambda x:x**2, input) # 每个数映射出它的平方数
output=reduce(lambda x,y: x+y, inter_data) # 平方数相加上面的例子中,原始输入数据[1, 2, 3],经过map函数,求平方的操作,映射到数据[1, 4, 9],再经过reduce函数,求两个数的和的操作,两两合并,形成最终的结果14。
MapReduce框架中的map和reduce过程与此类似,不同的是,每个数据变成key和value对。MapReduce框架把输入文件,处理成一些key,value对,map过程处理这些key,value对产生新的key,value对,reduce过程在根据key把所有的value进行合并,得到最终结果。MapReduce处理相同的问题,过程如下
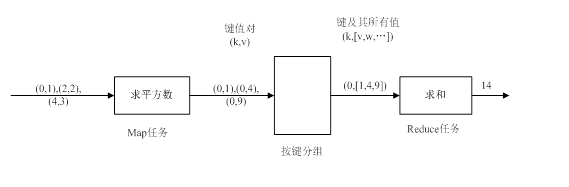
输入文件被处理成key,value对,其中key默认为数据在文件中的偏移,value为实际的值,经过map过程,这里输出相同的key和各个平方数的键值对,reduce归并具有相同的key值,进行求和,并最终产生结果。
map任务可能根据实际情况可能有多个,比如默认处理时,一个输入文件会有一个对应的map任务,当输入数据块超过一定大小时,也会被会为多个map任务。reduce任务根据key值和分组的不同,也有可能有多个reduce任务,如进行单词统计时,一般产生单词和统计个数的键值对,这时每个单词就有一个key,就有很多个reduce过程了。一个单词词频统计的例子如下:
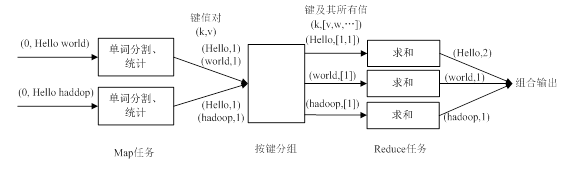
MapReduce作业执行过程
介绍完MapReduce的map和reduce等基本原理之后,我们来看更具体的MapReduce框架。这里介绍Hadoop开源框架的MapReduce作业执行过程。
在Hadoop实现的MapReduce模型中,主要有以下角色,客户端、JobTracker、TaskTracker和HDFS。HDFS是Hadoop的分布式文件系统,它包含NameNode和DataNode。NameNode和JobTracker分布在计算集群的master上,DataNode和TaskTracker分布在各个计算节点上,分布策略如下:
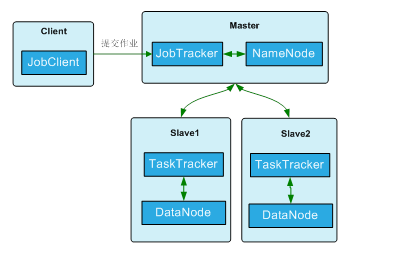
每个作业的执行过程(假设输入数据已经保存到HDFS里面了)又可以分为如下过程:
作业提交过程
MapReduce应用程序调用MapReduce框架的JobClient的runJob方法创建一个作业实例。并调用submitJob函数向TaskTracker发送作业。作业提交完成后,JobTracker返回一个作业号,并将作业运行所需要的资源文件拷到HDFS中,包括MapReduce应用程序的jar包、配置文件和输入数据的分片信息。
提交任务后,客户端会每隔1秒检测一次job的进度,并在客户端显示运行了百分之几,直到任务结束。
任务初始化过程
JobTracker接收到客户端提交的job后,把它放在一个作业队列中,等待作业调度器的调度。当某个作业得到调度时,会根据输入划分信息,创建若干个map任务,并为每个map任务分配唯一的task id。
作业分配过程
当JobTracker创建完task任务之后,就会将map任务分配给TaskTracker执行。TaskTracker的分配,还要考虑到TaskTracker节点上是否有对应的map数据,因为map计算有数据本地化的概念,因为TaskTracker与DataNode总是成对地在一个计算节点上的,所以分配map task时,要考虑到DataNode上已有的map数据块。而分配reduce task则没有这种限制。
任务的运行过程
TaskTracker通过保活心跳和JobTracker进行交互,使得JobTracker知道它在正常运行。另外,心跳中还带有一些其他的信息,如任务完成的进度等。当JobTracker收到某个作业所有任务的完成信息时,才把该作业标记为完成状态。如果此时JobClient进行查询操作,它将返回作业已完成的状态,并在用户界面上显示出来。
Map和Reduce过程
TaskTracker开始执行map过程。它从输入分片中读取一条条记录,并调用重载过的Mapper中的map函数体。将其他输出写入内存缓存中,经过shuffle过程,形成中间结果,并以中间文件的形式存于本地磁盘上。中间文件的位置会通知JobTracker。当所有的map过程结束,JobTracker会通知reduce任务从中间文件的位置拷贝数据。拷贝数据完成后,reduce任务会对结果进行排序,并合并,最后,调用重载的reducer的reduce过程,它处理排好序列的键值对,并将结果最终写HDFS。
至此,MapReduce的作业运行过程结束。
MapReduce数据流
Map过程输出的键值在进入Reduce过程中,经过了MapReduce系统的内部的处理,这些过程称为shuffle过程。熟悉了这些过程,才能更加优化MapReduce系统,来为我们更好地工作。下面是Hadoop官方提供的MapReduce高层数据流程图:
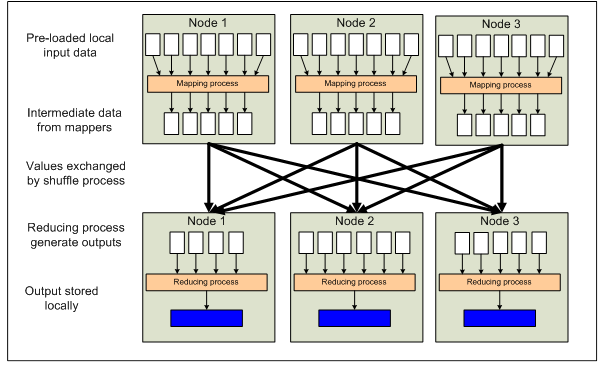
图中,Map函数和Reduce函数之间的数据变换的核心过程,即Shuffle和sort过程。下面是更加详细的数据产生流程,如下图:
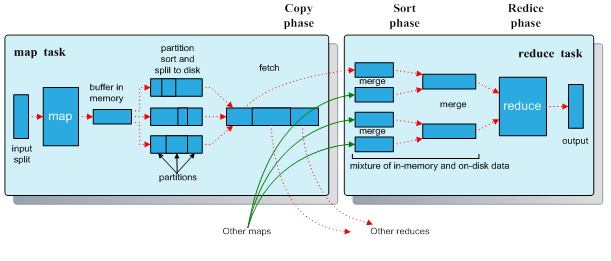
Map任务中有一个内存缓冲区,它用来缓存用户的输入数据。当缓冲区中填满到一定阈值时,框架将会启动一个后台线程把缓冲区中的内容spill到磁盘中。执行spill的后台线程在把缓冲区的数据写到磁盘前,会先对它进行一次排序,然后被进行partition分区,接着每个partition也会按Key进行排序。用户可以自己设计分区Partitioner,来控制Key的数据进入指定的Reduce任务。用户也可以在这里设计Combiner,它能把中间输出文件进行本地合并,从而能把大大减少从Map任务传输到Reduce任务的数据量。此外,中间数据还可以进行压缩。
Map任务的输出包括索引文件和数据文件。进入Reduce任务后,它主要有三个阶段,shuffle、sort和reduce。在shuffle阶段,框架通过Http从所有Map任务的特定分区中获取数据。在sort阶段,Reduce任务对Key进行分组排序。Shuffle和sort是同步运行的,数据可以在fetch获取的过程,同时进行数据merge合并操作。如果,用户设置了sortComparatorClass,那么这里还可以对Key进行二次排序。最后,Reduce任务执行reduce过程,产生最后的数据到HDFS系统中。
MapReduce 序列化操作
序列化是指将对象转化为字节流的过程,或者是说用字节流描述对象的方法。与序列化相反的是反序列化,它将字节流解析成对象。编写MapReduce应用,除了设计Map函数和Reduce过程,还要考虑序列化的设计。
在MapReduce中序列化处于比较关键的地位。因为数据持久化和中间数据传递都需要执行序列化的过程。序列化与反序列化的速度、序列化后的数据大小等都会影响数据传输的速度,和计算的效率。
Hadoop中定义了Writable等接口类,用于封装数据类型,同时用它来实现数据序列化和反序列化。用户基于Writable和它相关的类,可以实现自定义数据类型,避免了频繁地使用字符串分割、解析字符串等操作,极大地提高性能。
同时Hadoop中还提供了SequenceFile文件类,用于产生或解析序列化文件。而且,map过程产生的中间文件就是经过排序的SequenceFile。SequenceFile还支持一些压缩选项,可以有效减小产生数据大小,极大地加大网络传输和硬盘读写性能。
Writable类
Wirtable类是Hadoop的基本类型,MapReduce程序中无此无刻不在使用Wirtable类,甚至很少使用Java中的相应类了。常见的Writable类如下图:
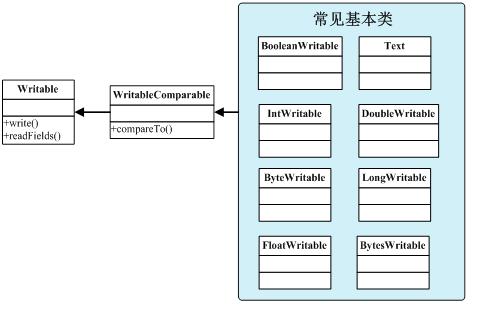
其中WritableComparable是Hadoop中非常重要的接口类,基本常见的数据类型都继承于它。它这里加了一个compareTo的接口。在MapReduce中的Reducer实现按键值排序的功能,就是比较的WritableComparable类型。我们后面如果要定制自己的数据类型,也基本是继承于它。
SequenceFile文件类
我们上面介绍了使用Writable类可以把数据序列化。Hadoop还提供了一个SequenceFile类,封装序列化文件的操作。SequenceFile描述的是键值对的列表,是对数据进行序列化之后产生的二进制文件。
SequenceFile在多个Job之间数据传递时非常好用。默认Job的输入格式一般是TextInputFormat,表示输入文件是文本,此时key是文件中每行的偏移量,value是每行的值,输入到map过程。如果把输入文件格式设置为SequenceFileInputFormat,则表示输入文件是SequenceFile格式,此时的key和value是SequenceFile中写入时的格式,也就是我们可以自己定义key和value格式,这在有多个字段联合作key,或者有多个value的情况下比较实用,可以避免了使用文本保存多个字段时解析字符串、拼凑字符串等操作。
我们可以在上一个Job中,定义输出键类型,输出值类型,和输出文件格式为SequenceFileOutputFormat,则上一个Job就会产生SequenceFile类型的文件,下一个Job紧接着,把输入文件格式也定义为SequenceFileInputFormat,则下一个Job的map过程输入的过程就和上一个Job的reduce输出的键类型、值类型一致。
封装自己的数据类型
上面介绍了使用Wirtable类型和SequenceFile可以方便地在MapReduce各个过程中实现序列化、反序化、排序、传递数据等功能。下面举个例子,看如何封装一个自定义的Writable类型。比如,我们要封装一个自动定义的类,它包含两个int型的成员,这种类型通常在有需要以两个int类型作为key的情况下使用。定义类如下:
public static class IndexPair implements WritableComparable {
public int index1;
public int index2;
public void write (DataOutput out)
throws IOException
{
out.writeInt(index1);
out.writeInt(index2);
}
public void readFields (DataInput in)
throws IOException
{
index1 = in.readInt();
index2 = in.readInt();
}
public int compareTo (Object other) {
IndexPair o = (IndexPair)other;
if (this.index1 < o.index1) {
return -1;
} else if (this.index1 > o.index1) {
return +1;
}
if (this.index2 < o.index2) {
return -1;
} else if (this.index2 > o.index2) {
return +1;
}
return 0;
}
}通过以上的定义,就可以实现一个IndexPair类的序列化、反序列化、排序等功能。可以看到自己定义一个数据类型,是非常容易实现,而且系统会提供序列化时的优化,比使用字符串方式来保存和解析信息,来得高效和便捷得多了。
Hadoop学习资源
CSDN Hadoop技术专题:
http://subject.csdn.net/hadoop/
粉丝日志:Hadoop家族系列文章:
http://blog.fens.me/hadoop-family-roadmap/
炼数成金大数据论坛:
http://www.dataguru.cn/

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)