Apache Hadoop集群设置示例(带虚拟机)
Apache Hadoop是为多机器集群设置而设计的。虽然可能在单机上运行也用于测试目的,但实际实现是针对多机群集。 即使我们想要尝试多机器设置,我们将需要通过网络彼此连接的多个系统,这是不可能的;如果你没有多个系统来尝试Hadoop集群呢?
This Article Is From:https://examples.javacodegeeks.com/enterprise-java/apache-hadoop/apache-hadoop-cluster-setup-example-virtual-machines/
About Raman Jhajj
建议先看英文再看翻译:翻译使用的是Google翻译。
1.介绍
Apache Hadoop是为多机器集群设置而设计的。虽然可能在单机上运行也用于测试目的,但实际实现是针对多机群集。 即使我们想要尝试多机器设置,我们将需要通过网络彼此连接的多个系统,这是不可能的;如果你没有多个系统来尝试Hadoop集群呢?
虚拟机来这里救援。 使用多个虚拟机,我们可以使用单个系统设置Hadoop集群。 因此,在本例中,我们将讨论如何使用虚拟机设置Apache Hadoop集群。
2.要求
- VirtualBox (or any other VM environment)
- Lubuntu 15.04 (or any other linux flavor of your preference)
- VBox Guest Additions image file (VBoxGuestAdditions.iso)
3.准备虚拟机
在本节中,我们将通过步骤准备虚拟机,我们将在后面的示例中使用它们。
3.1创建虚拟机和安装客户操作系统
1.在VirtualBox中创建虚拟机(VM),并为虚拟机分配最少2GB的内存和15GB的存储空间。将第一个虚拟机命名为Hadoop1。
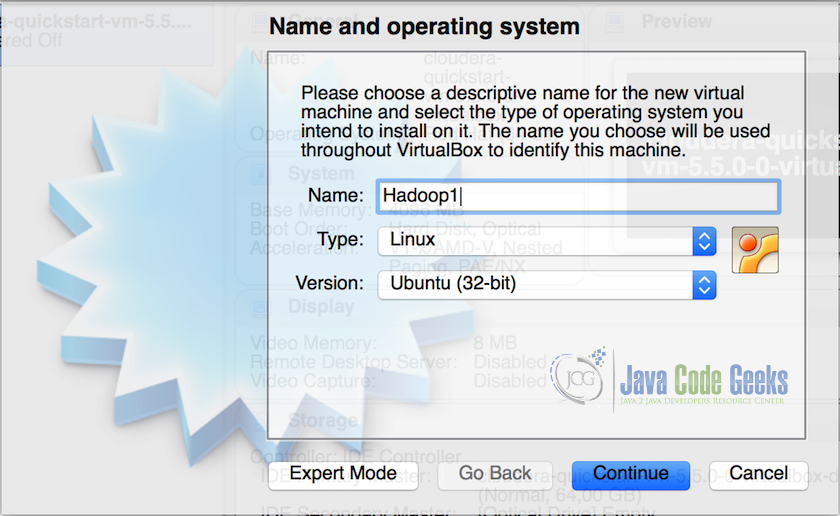
2.一旦创建虚拟机,在虚拟机中安装Lubuntu并完成设置,此后我们将获得一个有效的虚拟机。

3.安装操作系统可能需要一些时间。
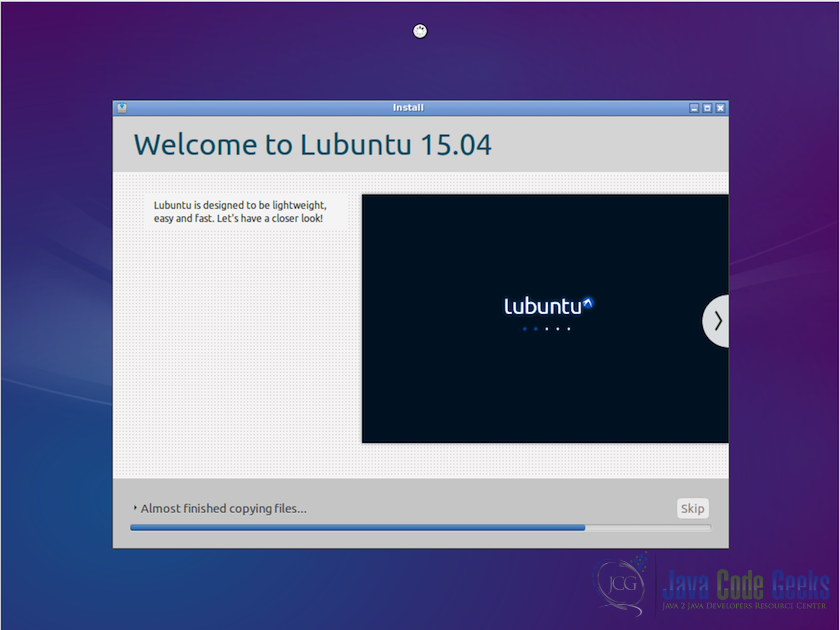
3.2安装额外的Guest
下一步是在VM中安装额外的Guest。 访客添加是VM执行良好所需的附加设置。它包括优化客户操作系统的设备驱动程序和系统应用程序,以提高性能和可用性。 这是每当创建虚拟机时重要和需要的步骤之一,它允许客户操作系统检测屏幕的大小(这有助于在全屏幕上运行VM),并且还使客户操作系统具有共享文件夹与主机操作系统(如果需要)。 以下是在客户机操作系统中安装客户机添加件所需执行的步骤:
1.首先,准备用于构建外部内核模块的系统,可以通过在终端中运行以下命令并安装DKMS(DKMS提供对安装内核模块的补充版本的支持)来完成:
sudo apt-get install dkms2. 将VBoxGuestAdditions.iso CD文件插入Linux客户虚拟CD-ROM驱动器。
3.现在打开终端,将目录更改为CD-ROM驱动器,然后执行以下命令:
sh ./VBoxLinuxAdditions.run注意:此时重新引导系统,并进入下一步,我们将为虚拟机配置网络设置。
4.创建虚拟机群集
在本节中,我们将看到如何配置网络以使虚拟机充当单个群集机器,如何将第一台机器克隆到其他机器上,这将节省所有时间,因为我们不需要在所有机器上单独执行上述步骤。
4.1VM网络设置
1.转到Virtualbox首选项菜单,并从下拉菜单中选择“首选项”(‘Preferences’)。
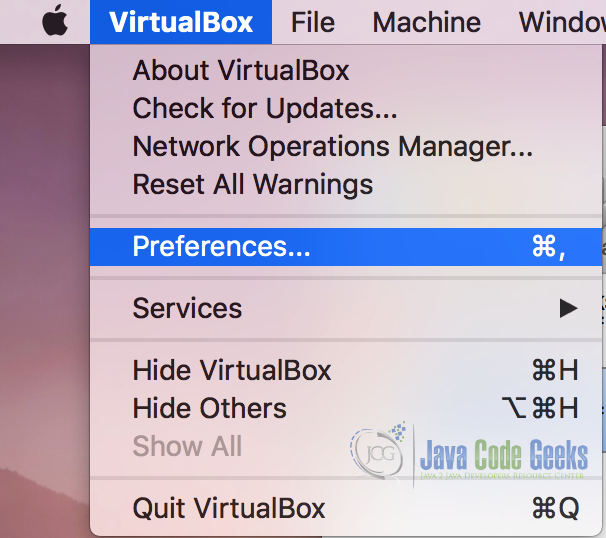
2.在“首选项(Preferences)”菜单中,选择“网络(NetWork)”。在网络首选项中,选择“仅主机网络(Host-only Networks)”,然后单击“添加驱动程序(Add Driver)”。驱动程序将添加到列表中。 双击驱动程序,它将打开一个弹出的DHCP服务器设置,插入DHCP服务器设置,如下面的屏幕截图所示。
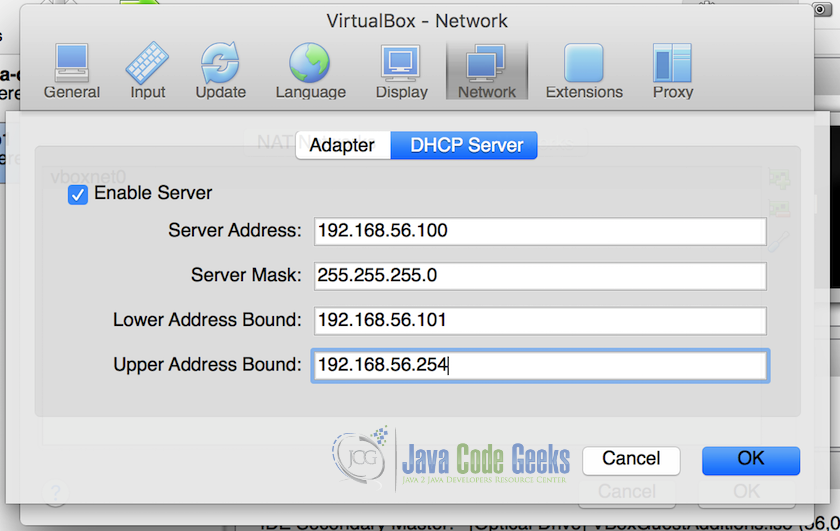
我们将网络的下限和上限设置为“192.168.56.101”和“192.168.56.254”,所有机器将只具有从此范围分配的IP。不要忘记检查“启用服务器(Enable Server)”
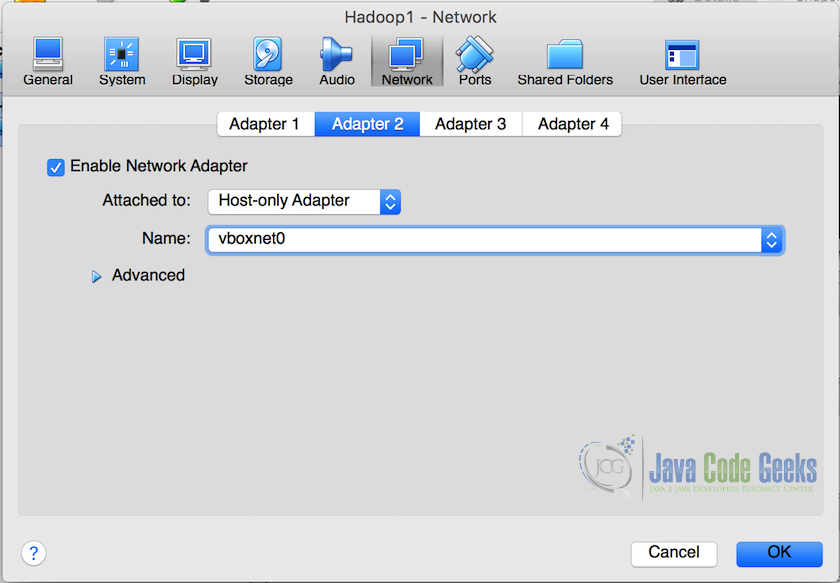
3.完成网络设置和DHCP服务器就绪后,在VirtualBox Manager中,右键单击虚拟机,然后从列表中选择“设置”。从设置弹出窗口中,选择“网络(NetWork)”,然后选择“Adapter2”选中“启用网络适配器(Enable Network Adapter)”,然后在“附加到(Attached to)”下拉菜单中选择“仅主机适配器(Host-only adapter)”。在第二个下拉列表中,所有适配器的名称将可用,包括我们在上一步中创建的名称。 从下拉列表中选择它,在我们的示例中它的名称为“vboxnet0”。这将将虚拟机附加到此particualr网络。
4.2克隆虚拟机
现在我们有一个虚拟机准备好了,我们克隆这个虚拟机创建相同的机器,这使我们免于所有以前的步骤的麻烦,我们可以轻松地有多个虚拟机与克隆它们的配置相同。
1.右键单击虚拟机,然后从下拉列表中选择“克隆(Clone)”。
2.在克隆弹出窗口中,将虚拟机重命名为“Hadoop2”并选择“重新初始化所有网卡的MAC地址(Reinitialize the MAC address of all the network cards)”,然后单击继续。
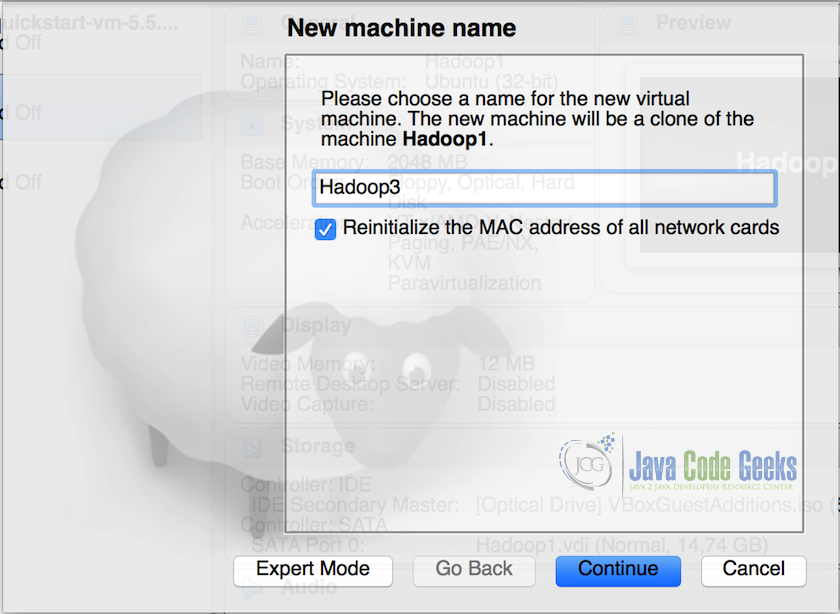
注意:重新初始化MAC地址,确保新虚拟机具有不同的网卡MAC地址。
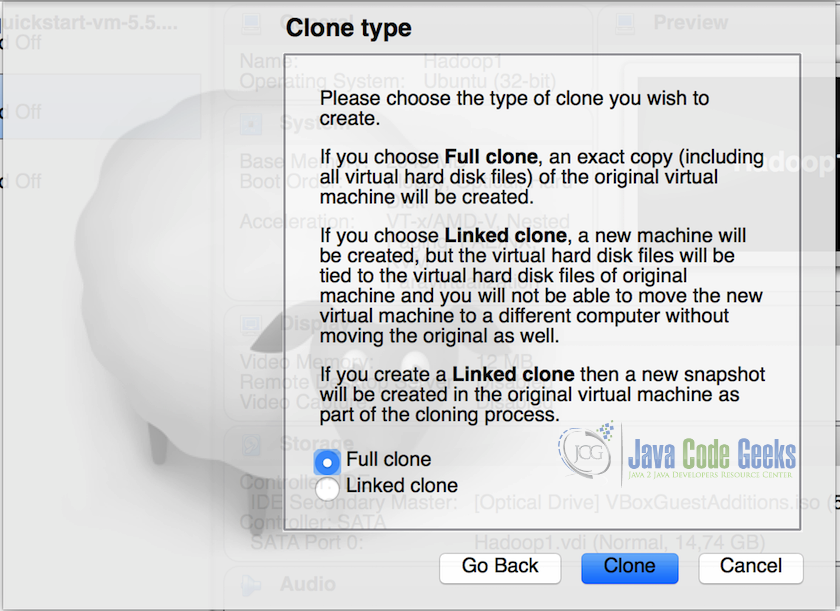
3.在下一个屏幕中,选择“完全克隆(Full Clone)”选项,然后单击“克隆(Clone)”。
4.3测试分配给VM的网络IP
所以现在我们在同一个网络上有两台机器。 我们必须测试这两台机器是否都连接到我们为集群设置的网络适配器。以下是执行此操作的步骤:
1.启动两个虚拟机,并在终端中使用以下命令:
ifconfig这将显示机器的网络配置。 我们将注意到,所分配的IP在192.168.56.101和192.168.56.254的范围内(即,在分配给DHCP网络的较低地址限制和较高地址限制之间)
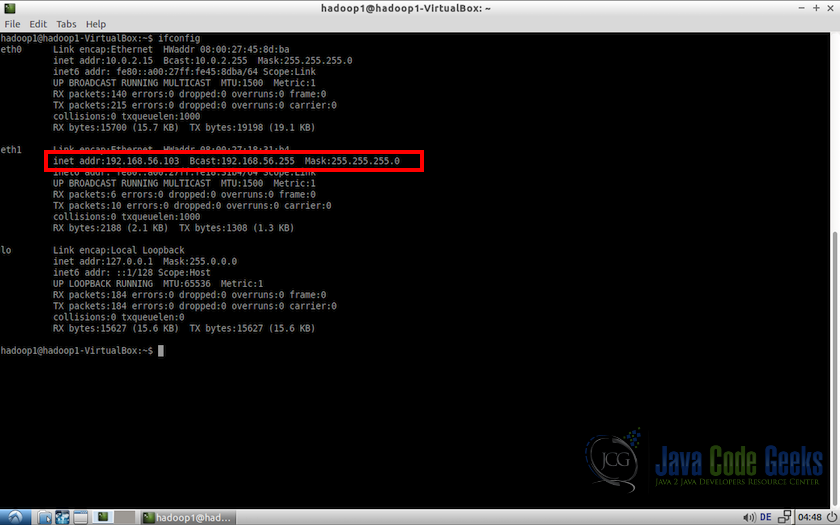
注意:对这两台机器执行相同的任务,并确认一切正常。
4.4转换为静态IP的虚拟机
这个配置会有一个问题。 IP随机分配给系统,并且可能在将来的重新启动中改变。Hadoop需要静态IP来访问集群中的计算机,因此我们需要将计算机的IP始终固定为静态,并为这两台计算机分配特定的IP。 需要在两台机器上执行以下步骤。
1.转到终端中的/ etc / networks,并以root身份编辑文件接口。
#Go to networks directory
cd /etc/networks
#Edit the file 'interfaces'
sudo nano interfacesauto eth1
iface eth1 inet static
#Assign a static ip to the virtual machine
address 192.168.56.101
netmast 255.255.255.0
network 192.168.56.0
#Mention the broadcast address, get this address using ifconfig commmand
#in this case, is it 192.168.56.255
broadcast 192.168.56.255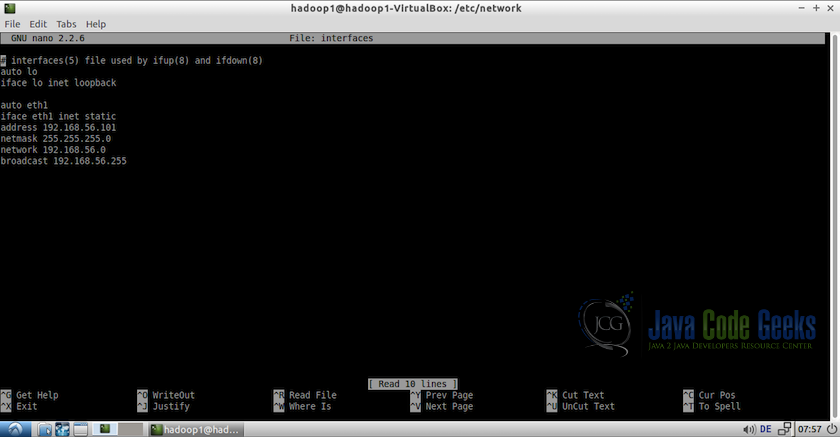
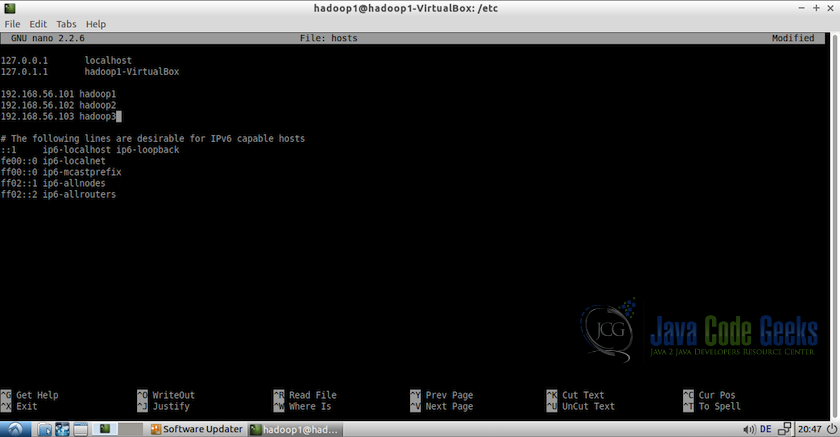
3.在每台计算机上,以root身份编辑文件/ etc / hosts,并添加主机。例如:
#Edit file using nano editor
sudo nano /etc/hosts添加以下主机:
192.168.56.101 hadoop1
192.168.56.102 hadoop2注意:IP应与上一步中分配的IP相同。
4.重新启动(reboot)所有机器。
5.Hadoop先决条件设置
以下是hadoop设置的先决条件设置。 记住所有需要在所有要添加到集群中的机器上完成的设置(本例中为2台机器)
5.1创建用户
在所有机器上创建hadoop用户。 为此打开终端并输入以下命令:
#create a user group for hadoop
sudo addgroup hadoop
#create user hduser and add it to the hadoop usergroup
sudo adduser --ingroup hadoop hduser5.2禁用IPV6
下一步是在所有机器上禁用ipv6。 Hadoop设置为使用ipv4,这就是为什么我们需要在创建hadoop集群之前禁用ipv6。 使用nano打开/etc/sysctl.conf作为root
sudo nano /etc/sysctl.conf并在文件末尾添加以下行。
#commands to disable ipv6
net.ipv6.conf.all.disable-ipv6=1
net.ipv6.conf.default.disable-ipv6=1
net.ipv6.conf.lo.disable-ipv6=1此后,要检查ipv6是否正确禁用,请使用以下命令
cat /proc/sys/net/ipv6/conf/all/disable-ipv6它将返回0或1作为输出,我们希望它为1,因为它表示ipv6被禁用。
5.3连接机器(SSH访问)
现在,我们必须确保机器能够通过网络使用静态IP地址和SSH访问。 对于这个例子,我们将hadoop1机器作为主节点,hadoop1和hadoop2都作为从节点。 所以我们必须确保:
- hadoop1(主)应该能够连接到自己使用
ssh hadoop1- 它应该能够连接到使用的其他VM
ssh hduser@hadoop2为了实现这一点,我们必须在每台机器上生成SSH密钥。 所以登录到hadoop1并按照下面提到的步骤在终端:
1.切换到用户hduser并生成SSH公用密钥:
#change to user hduser
su - hduser
#generate ssh key
ssh-keygen -t rsa -P ""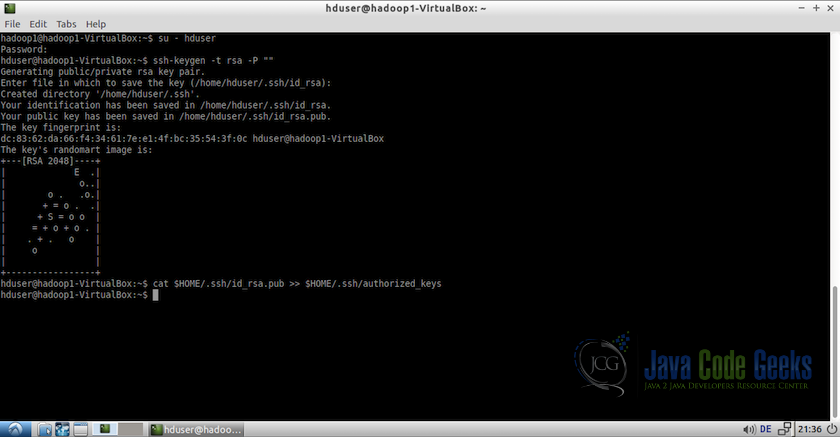
第二个命令将为机器创建一个RSA密钥对。 此键的密码将为空,如命令中所述。 它将要求存储密钥的路径,默认路径为$ HOME / .ssh / id-rsa.pub,当提示保持同一路径时,按Enter键。 如果您计划更改路径,请记住它,因为它将在下一步中需要。
2.使用上一步中创建的密钥启用对机器的SSH访问。 为此,我们必须将密钥添加到机器的授权密钥列表。
cat $HOME/.ssh/id-rsa.pub >> $HOME/.ssh/authorized_keys3. 现在我们必须将hduser @ hadoop1的公共SSH密钥(主节点)添加到hduser @ hadoop2机器的授权密钥文件。 这可以在hadoop1的终端上使用以下命令来完成:
ssh-copy-id -i $HOME/.ssh/id-ras.pub hduser@hadoop2这将提示输入用户hduser @ hadoop2的密码
4.测试从hadoop1到自身的SSH连接,以及hadoop2,以确保一切正常使用:
ssh hadoop1这将连接hadoop1到自己,如果连接成功,退出连接,并尝试连接到hadoop2机器
ssh hduser@hadoop2这也应该成功连接。
6.Hadoop设置
所以,我们在完成所有初始设置的步骤,现在我们准备在集群上设置hadoop。
6.1下载Hadoop
1.从Apache Mirrors下载Hadoop,网址为www.apache.org/dyn/closer.cgi/hadoop/core
2.下载完成后,解压hadoop文件夹并将其移动到/ usr / local / hadoop,最后更改文件夹的所有者为hduser和hadoop组。
#Change to the directory
cd /usr/local
#move hadoop files to the directory
sudo mv /home/hadoop1/Downloads/hadoop-2.7.1 hadoop
#change the permissions to the hduser user.
sudo chown -R hduser:hadoop hadoop我们可以检查文件夹设置中的权限,以确认它们是否正常。

6.2更新bashrc
1.更新用户hduser的bashrc文件。
su - hduser
nano $HOME/.bashrc2. 在文件末尾,添加以下行。
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-i386
#Some convenient aliases
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
export PATH=$PATH:$HADOOP_HOME/bin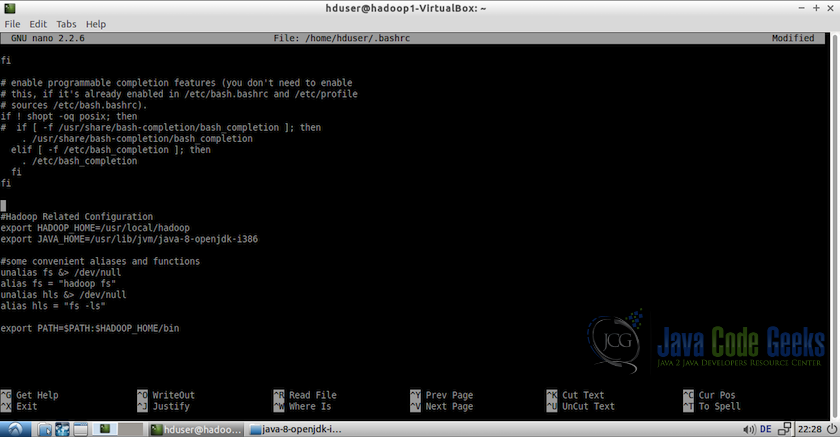
6.3配置Hadoop
现在,是时候配置hadoop设置。 以下是需要遵循的步骤:
1.这需要在所有机器上执行。 在/ usr / local / hadoop / etc / hadoop中打开hadoop-env.sh并设置JAVA_HOME变量,如下所示:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-i3862. 接下来,我们将在/ usr / local / hadoop / etc / hadoop /文件夹中配置core-site.xml,并添加以下属性
<configuration>
<property>
<name>fs.default.FS</name>
<value>hdfs://hadoop1:54310</value>
</property>
</configuration> 这也需要在所有机器中编辑,但所有值字段应指向主节点,在此示例中仅为hadoop1。 因此,对于这两台机器,需要添加具有相同名称和值的相同属性。
3.接下来,我们需要在所有主节点和从属节点上更新hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration> 4. 现在,我们将更新mapred-site.xml文件。 它只需要在主节点上编辑
<configuration>
<property>
<name>mapreduce.jobtracker.address</name>
<value>hadoop1:54311</value>
</property>
</configuration>5.最后一个配置将在文件夹/ usr / local / hadoop / etc / hadoop中的文件slaves中。 添加从节点的主机名或IP地址
hadoop1
hadoop26.4格式化Namenode
我们现在完成所有的配置,所以在启动集群之前,我们需要格式化namenode。 为此,请在hadoop1(主)节点终端上使用以下命令:
hdfs namenode -format6.5启动分布式格式系统
现在是开始分布式格式系统并开始运行集群的时候了。 以下是这样做的命令:
/usr/local/hadoop/sbin/start-dfs.sh一旦dfs启动没有任何错误,我们可以浏览主节点上http:// localhost:50070上的Namenode的Web界面
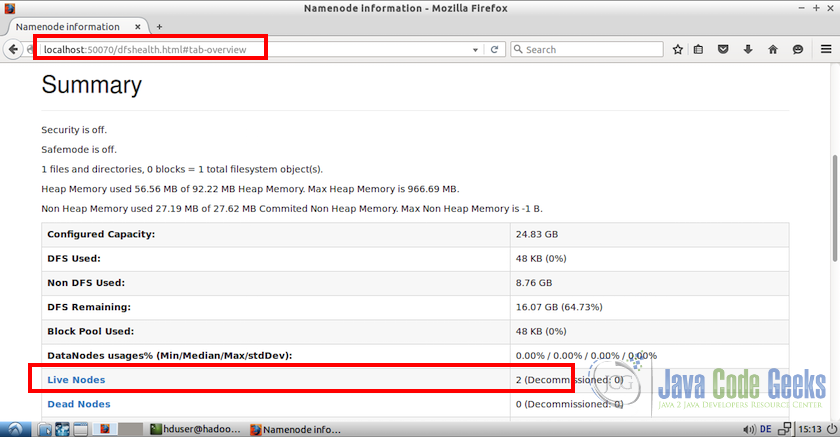
如果你注意到在屏幕截图的底部,有两个活节点,当时确认我们的集群有两个正常工作的节点。
我们还可以从任何从节点访问Web界面,但对于那些我们必须使用主主机名或IP地址。 例如,从hadoop2(从节点),我们可以使用地址http:// hadoop1:50070访问Web界面。
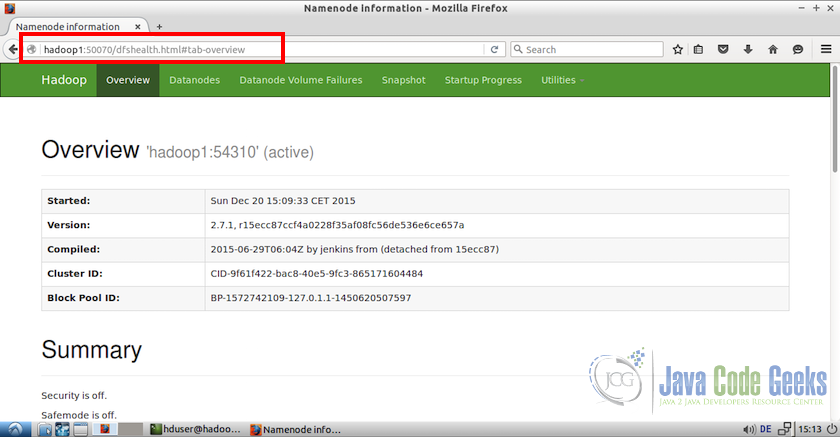
6.6测试MapReduce作业
1.首先,让我们做出所需的HDFS目录并复制一些输入数据用于测试目的
#Make the required directories
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hduser这些目录也可以从Web界面访问。 为此,请转到Web界面,从菜单中选择“实用程序(Utilities)”,然后从下拉列表中选择“浏览文件系统(Browse the file system)”
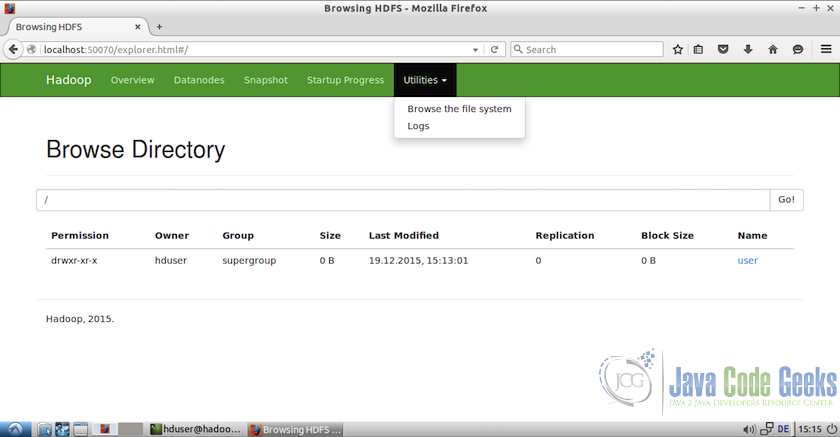
2.现在,我们可以添加一些虚拟文件到我们将用于测试目的的目录。 让所有的文件从etc / hadoop文件夹
#Copy the input files into the distributed file system
/usr/local/hadoop/bin/hdfs dfs -put /usr/local/hadoop/etc/hadoop input下面的屏幕截图显示了添加到目录/ user / hduser / input的文件

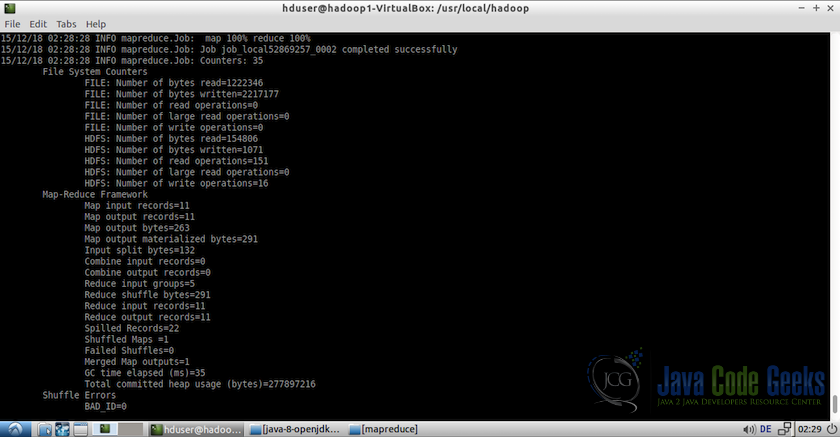
3.使用以下命令运行hadoop软件包中包含的MapReduce
/usr/local/hadoop/bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-example-2.7.1.jar grep input output 'dfs[a-z.]+'注意:有关MapReduce示例如何工作的详细信息,请参阅文章“Hadoop Hello World示例”
下面的截图显示了测试示例的输出日志:
4.我们现在可以使用查看输出文件
/usr/local/hadoop/bin/hdfs dfs -cat output/*6.停止分布式格式系统
现在我们可以使用以下命令停止dfs(分布式格式系统):
/usr/local/hadoop/sbin/stop-dfs.sh这使我们的设置和初始测试的结束。
7.总结
这使我们得出这个例子的结论。 希望这使它更清楚地说明如何在多台机器上设置Hadoop集群。 如果需要在多个物理机器而不是虚拟机上设置集群,则除了包含4.1 VM网络设置和4.2克隆虚拟机的步骤之外,说明相似。 对于物理机集群,我们可以在机器上执行所有其他步骤,一切都应该工作顺利。
8.下载配置文件
为此示例修改和使用的配置文件可以从这里下载。 请记住,在这些配置文件中进行的修改可能因用户网络和其他设置而异,可能需要相应更改。 包装包含:
- hosts file
- sysctl.conf file
- Hadoop 1 folder (contains master node files)
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- slaves
- Hadoop 2 folder (contains slave note files)
- core-site.xml
- hdfs-site.xml
注:为以防万一现已将下载文件备份至百度网盘:http://pan.baidu.com/s/1c2sZNwO

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)