HPCC论文阅读笔记
利用INT获取精确的链路负载信息,精确控制流量解决了INT信息在拥塞时延迟,对INT信息过度反应的问题,利用空闲队列,维持接近0的网内队列HPCC公平,易部署数据中心网络对高带宽、低延迟的要求较高,但是这面临着挑战。本文列举了两个具有代表性的案例。case1:PFCstormRDMA云存储集群曾因为一次大规模incast,加上厂商交换机持续发送PFC pause帧,而导致全网范围的大规模流量下降。
一、其他的一些概念
INT:in-network telemetry,in-band network telemetry,网内遥测,带内网络遥测,In-band network telemetry via programmable dataplanes
QCN(Quantized Congestion Notification,量化拥塞通知)是一套应用于L2的端到端拥塞通知机制
PFC,priority flow control
Coarse-grained / fine-grained:粗粒度、细粒度
PoD:point-of-delivery
ToR:Top of Rack,一种数据中心的布线方式,个人理解为图中的edge层,在当前的RDMA部署中,每个PoD是一个独立的RDMA域,这意味着只有同一个PoD内的服务器才能用RDMA通信。

NACK:接收端主动通告没有收到的报文,发送方收到后go-back-N,从N开始全部重新发送
Tail latency:尾部延迟, 指客户端很少看到的高延迟
50th 95th percentiles:https://blog.csdn.net/m0_37668842/article/details/105550199
概念:95th percentile百分点指的是所给数集中超过其95%的数。95th百分点是统计时所采用的最高值,超过的5%的数据将被舍弃。这样可以将瞬间的毛刺(尖峰)去掉,使统计平均更具真实意义。
举例:例如数据为60,45,43,21,56,89,76,32,22,10,12,14,23,35,45,43,23,23,43,23 (20 个点),将该序列降序排列,其最大值为89。由于20个点的5%为1,所以舍弃1个最大值89,剩下的最大值76就是95th百分点
二、论文部分
摘要
利用INT获取精确的链路负载信息,精确控制流量
解决了INT信息在拥塞时延迟,对INT信息过度反应的问题,利用空闲队列,维持接近0的网内队列
HPCC公平,易部署
介绍
数据中心网络对高带宽、低延迟的要求较高,但是这面临着挑战。本文列举了两个具有代表性的案例。
case1:PFC storm
RDMA云存储集群曾因为一次大规模incast,加上厂商交换机持续发送PFC pause帧,而导致全网范围的大规模流量下降。在这类集群中,大规模incast和拥塞是常态。因此本文对CC算法的调整包括了保守地提高速率以避免触发PFC暂停。
case2:高延迟
机器学习应用短消息延迟超过100$$\mu s$$,在RDMA网络中,其期望延迟为小于50$$\mu $$,导致高延迟的原因是网络中的队列主要由同一集群中带宽密集型的云存储系统占用,本文将ML应用部署到新的集群来分离这两个应用
现有RDMA网络中的CC机制,DCQCN和TIMELY的局限性:
收敛速度慢:目前的拥塞信号,ECN或RTT,当前的CC机制无法准确地判断应该增加或减少多少速率,因此用启发式方法猜测速率更新,并尝试迭代收敛到稳定的速率分布,这样的方法在处理大规模拥塞事件时速度慢,如case1所示。
包队列延迟:DCQCN使用1bit的ECN标志位来判断拥塞风险,TIMELY发送端利用RTT增加的RTT来探测拥塞,因此,发送方只有在拥塞队列形成之后才开始降低速率,队列会导致网络延迟的增加,即case2中的问题
调参复杂:当前的CC算法用于调整发送速率的启发式算法对于特定的网络环境需要调整过多的参数。DCQCN有15个参数。
HPCC算法
核心思想:利用INT中精确的链路负载信息来计算精确的流量更新
创新点:
-
只需要一个速率更新步骤,无需迭代;
-
利用INT的精确信息能够解决上述三个局限性
实现难点:
-
INT信息会由于链路拥塞而被延迟,从而导致发送端速率减少的推迟,本文的解决办法是控制inflight字节数;
-
发送方为了快速反应有可能盲目地对所有的信息作出反应,从而导致过度反应,本文的解决办法是通过结合per-ACK和per-RTT来选择性的利用INT信息,从而实现快速反应而不过度反应
DCQCN的问题
存在着两对矛盾:吞吐量vs稳定性,带宽vs延迟
在一个DCQCN配置中,很难在不影响网络稳定性的情况下实现高吞吐量。在图(a)中,在30%的网络负载之下,更小的(Ti)和更大的(Td)通过让发送发更加积极地检测利用宽带,减少了每条流的平均完成时间。但这样做也会造成更多PFC PAUSE帧的出现。

目前的理解:30%网络负载是指有100台机器中有30台正在发送数据,纵坐标为FCT Slow down(是指当网络中只有一个流时,该流的实际FCT被其理想FCT归一化的值,其实就是实际完成时间与理论完成时间的比值),横坐标为流的大小,右图是不同参数情况下的由PFC导致的暂停发送的时长和延迟
为了始终保持较低的延迟,网络需要在缓冲区中稳定地维持较小的队列(这意味着ECN标记阈值较低),而如果ECN标记阈值较低,则发送方将过于保守以至于无法提高流量。

HPCC算法
HPCC是一个基于窗口的CC算法。inflight字节表示已经被发送但是还未被发送方确认的数据量。
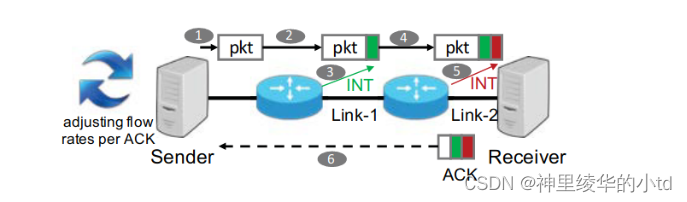
算法框架图

发送端的每一个包都会有ACK,在数据包传输过程中,每一个交换机利用INT特性插入元数据,回报当前出端口负载,包括时间戳ts,队列长度qLen,传输字节数txBytes,链路带宽容量B,接收端受到数据包后将元数据拷贝到ACK中发送回发送端,由发送端决定如何调整流量
算法实现
发送端使用发送窗口限制飞行字节
发送方维护一个发送窗口,用于限制飞行字节,出时大小设置为$$W_{init}=B_{NIC}*$$,其中$$B_{NIC$$为网卡带宽,使用pacing技术防止bursty,pacing速率为$$R=\frac{W}{T}$$,W为窗口大小,T为base RTT
基于飞行字节的拥塞信号和流控规则
对于一条带宽B的链路,其飞行字节为所有通过的流的窗口大小之和,$$I=\sum{W_i}$$,
如果$$I,那么$$\sum{\frac{W_i}{T}},其中$$\frac{W_i}{T$$是第i条流在没有拥塞时的吞吐量,这种情况下,总吞吐量低于链路带宽
如果$$I>=B*$$,那么$$\sum{\frac{W_i}{T}}>=B$$,这种情况下,必然存在拥塞并形成队列。
HPCC的目标是:控制$$I$$略小于$$B*$$
每条链路inflight字节数计算方法:$$I_j=qlen+txRate*$$,qlen从INT中直接获取,$$txRate=\frac{ack_1.txBytes-ack_0.txBytes}{ack_1.ts-ack_0.ts$$,这个公式假设了所有的流有相同已知的RTT(This is possible in data centers, where the RTT between most server pairs are very close due to the regularity of the topology.)
对信号作出反应:
链路$$$$归一化的inflight字节数为$$U_j=\frac{I_j}{B_j*T}=\frac{qlen_j}{B_j*T}+\frac{txRate_j}{B_j$$
对于此条链路,需要调整发送端窗口大小略小于$$B*$$,设置系数$$\eta<1(e.g. 0.95)$$,$$k_j=\frac{I_j}{\eta*B*T}=\frac{U_j}{\eta}$$,即每个窗口除以系数kj即可。
发送端窗口调整公式为$$W_i=\frac{W_i}{max_j(K_j)}+W_{AI}=\frac{W_i}{max_j(U_j)/\eta}+W_{AI}$$,这里的$$W_{AI$$是一个为了确定公平性而存在的一个很小的值,WAI越大,总的吞吐量越大,这个公平性也会越好,但是整体队列长度也会增加
解决过度反应的问题
图解说明:对于S1来说,(a)中P1,(b)中P2分别给发送端报告了qlen=4的ACK,以每次窗口调整为1/2为例,两次ACK过后,S1的W(2)=W(1)/2=W(0)/4,这种情况下P1和P2报告了几乎相同的链路条件,但是进行了两次窗口大小的调整,这种调整方式并不合理。

per-ACK,per-RTT策略:快速反应而不过度反应
引入一个参考窗口大小$$W^c_$$,其值在同一个RTT内保持不变,只有在下一个RTT内,第一个ACK到达时,才会进行更新:$$W^c_i=W_i$$,而窗口更新的规则也变为

算法总结
函数1:飞行字节估计,传入ACK,返回归一化的inflight字节数U
对于每条链路,计算传输速率txRate,计算每一条链路归一化的u',用ACK和发送端记录的较小的队列长度(本质是对链路队列长度的估计,在上一次更新和本次ACK中取较小值,取较大值造成拥塞的概率更高,这样取值可以过滤噪声的影响)进行计算,用u记录u'的最大值,并同时记录时间戳$$\ta$$,$$\ta$$在当前值与RTT中取最小值(为了平滑估计,如果$$\tau>RTT$$,说明链路很拥堵,平滑时U直接用最新值,反映了最新的链路情况,如果$$\tau,说明链路拥塞情况不是很严重,则之前的U具有一定的参考价值,应增加其权重),返回U估计值(EWMA)
函数2:计算窗口大小,传入归一化的飞行字节U,bool型函数是否更新窗口大小,返回更新后的窗口大小
如果发送方发现需要增加窗口大小,则首先尝试使用WAI进行maxStage次调整,如果调整后仍有上升空间,或者归一化的inflight字节大于$$$$,则调用公式,快速提升或降低窗口大小(第12 ~ 13行)。

lastUpdateSeq用于记录新的$$W^c$$发送的第一个数据包的序号,即将收到的ACK的序号应大于lastUpdateSeq,才能触发$$W^c$$与W的同步,
参数设置
$$\eta=0.95,maxStage=5,W_{AI}=\frac{W_{init}*(1-\eta)}{N}$$
HPCC属性:非启发式
硬件实现
在FPGA的商用NIC中实现了HPCC,在具有P4可编程能力的商用交换机ASIC中实现了标准INT,在相同的硬件平台实现了DCQCN以便于公平的比较
NS3相关实验
60:1 incast,随机挑选60个发送端发送500KB
不同的CC方案流完成时间对比

更适合短流,长流消耗更长的时间
HPCC与DCQCN相比,选择不同的流控机制,PFC,go-back-N,IRN(增加了一个固定大小的窗口,用于限制inflight字节数)

HPCC中config.txt部分解释
KMAX_MAP 3 25000000000 400 50000000000 800 100000000000 1600
KMIN_MAP 3 25000000000 100 50000000000 200 100000000000 400
PMAX_MAP 3 25000000000 0.2 50000000000 0.2 100000000000 0.2
这三个作者给的解释是
KMAX_MAP 3 25000000000 400 50000000000 800 100000000000 1600 {a map from link bandwidth to ECN threshold kmax}
KMIN_MAP 3 25000000000 100 50000000000 200 100000000000 400 {a map from link bandwidth to ECN threshold kmin}
PMAX_MAP 3 25000000000 0.2 50000000000 0.2 100000000000 0.2 {a map from link bandwidth to ECN threshold pmax}
这是一个映射,3表示有3个映射关系,当速率为250000000是对应的值为后面的那个,之前出过错是,40Gbps时,这个设置没有写入config.txt,导致报错,需要添加 4000000000 系列的参数,例如修改为
KMAX_MAP 4 25000000000 400 50000000000 800 100000000000 1600 40000000000 600
KMIN_MAP 4 25000000000 100 50000000000 200 100000000000 400 40000000000 180
PMAX_MAP 4 25000000000 0.2 50000000000 0.2 100000000000 0.2 40000000000 0.2
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)