基于Hadoop集群实现数据处理及可视化展示
后续会将文章写出来,我这个项目的主题是疫情(虽然疫情快结束了,主要是分享思路,祝大家身体健康),数据来源于百度疫情(世界和我国各城市相关疫情数据)和一个私人的疫情网站(我国近十天的历史疫情数据),页面比较简陋,因为本人前端的功底比较薄弱。在以上基础上,可设置Linux的定时程序组合命令,实现实时爬取监控。1.部署爬虫到虚拟机(先在虚拟机中配置python环境)6.上传springboot项目到服务
·
在集群搭建完毕之后,后续工作实现逻辑是:
1.部署爬虫到虚拟机(先在虚拟机中配置python环境)
2.flume负载均衡监控爬虫输出路径并将日志上传到hdfs
3.编写mapreduce排序,去空值,规范数据
4.将mapreduce的结果通过sqoop导出到本地MySQL
5.基于springboot+echart可视化展示结果
6.上传springboot项目到服务器,在线展示
7.azkaban调度执行以上内容
后续会将文章写出来,我这个项目的主题是疫情(虽然疫情快结束了,主要是分享思路,祝大家身体健康),数据来源于百度疫情(世界和我国各城市相关疫情数据)和一个私人的疫情网站(我国近十天的历史疫情数据),页面比较简陋,因为本人前端的功底比较薄弱。欢迎留言提供建议!
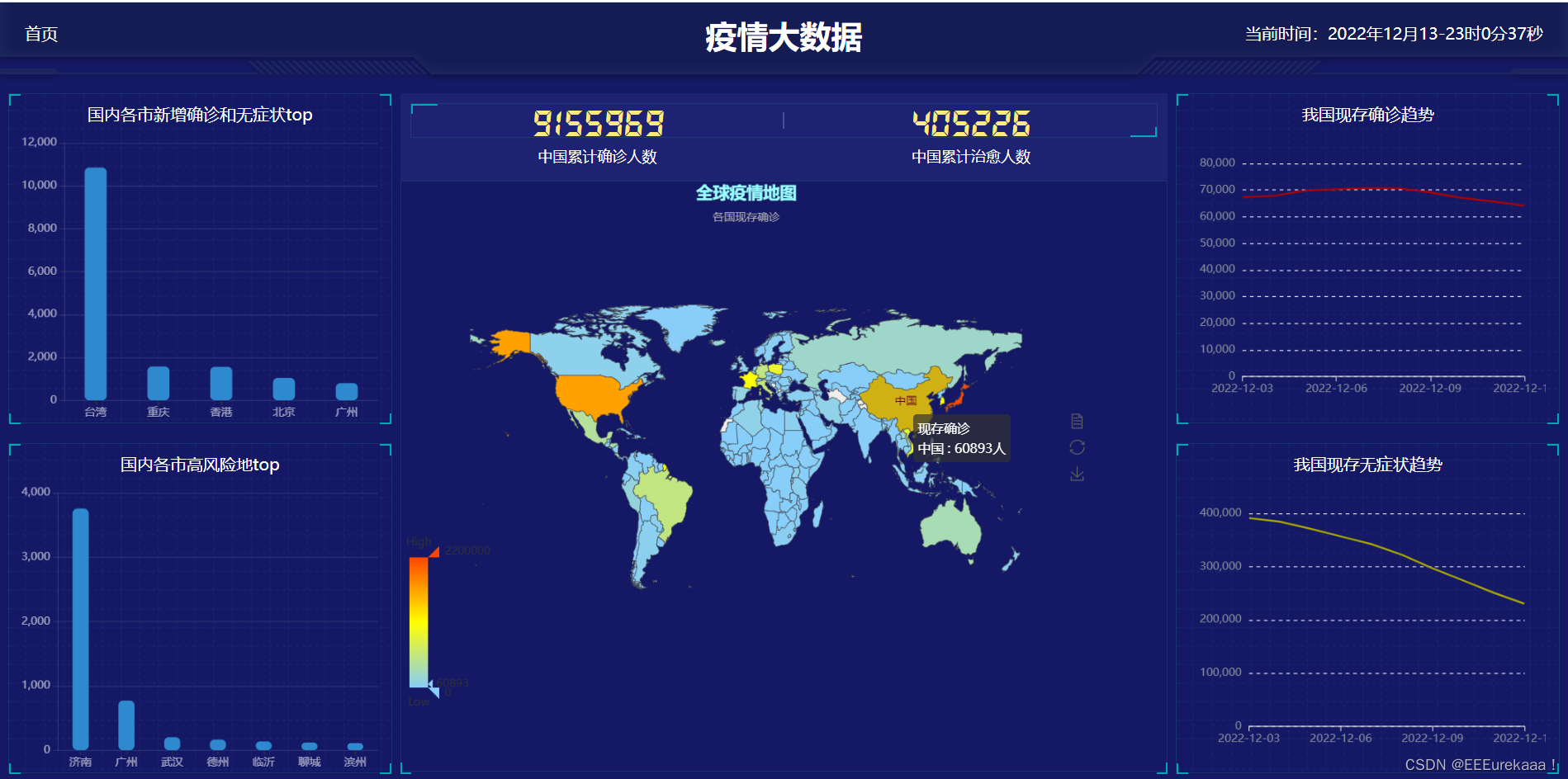
成果展示:


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)