内存计算技术那家强?SPARK vs HANA
最近业界有很多技术和产品都认为属于内存计算的范畴,由于我个人也从事于内存计算产品的研发,所以想借个机会,跟各位聊聊到底什么是内存计算技术,以及比较一些现在两种比较主流的内存计算技术Apache Spark和SAP HANA,它们的特点和区别。什么是内存计算技术?关于内存计算,就像云计算和大数据一样,其实无论在百度百科还是Wikipedia都没有非常精确的描述,但是有几个共通的关键点
最近业界有很多技术和产品都认为属于内存计算的范畴,由于我个人也从事于内存计算产品的研发,所以想借个机会,跟各位聊聊到底什么是内存计算技术,以及比较一些现在两种比较主流的内存计算技术Apache Spark和SAP HANA,它们的特点和区别。
什么是内存计算技术?
关于内存计算,就像云计算和大数据一样,其实无论在百度百科还是Wikipedia都没有非常精确的描述,但是有几个共通的关键点,我在这里给大家总结一下:其一是数据放在内存中,至少和当前查询工作涉及到的数据放在都要放在内存中;其二是多线程和多机并行,也就是尽可能地利用现代x86 Xeon CPU线程数多的优势来加速整个查询;其三是支持多种类型的工作负载,除了常见和基本的SQL查询之后,还通常支持数据挖掘,更有甚者支持Full Stack(全栈),也就是常见编程模型都要支持,比如说SQL查询,流计算和数据挖掘等。
Apache Spark的设计思路
大家都知道,现在Apache Spark可以说是最火的开源大数据项目,就连EMC旗下专门做大数据Pivotal也开始抛弃其自研十几年GreenPlum技术,转而投入到Spark技术开发当中,并且从整个业界而言,Spark火的程度也只有IaaS界的OpenStack能相提并论。那么本文作为一篇技术文章,我们接着就直接切入它的核心机制吧。
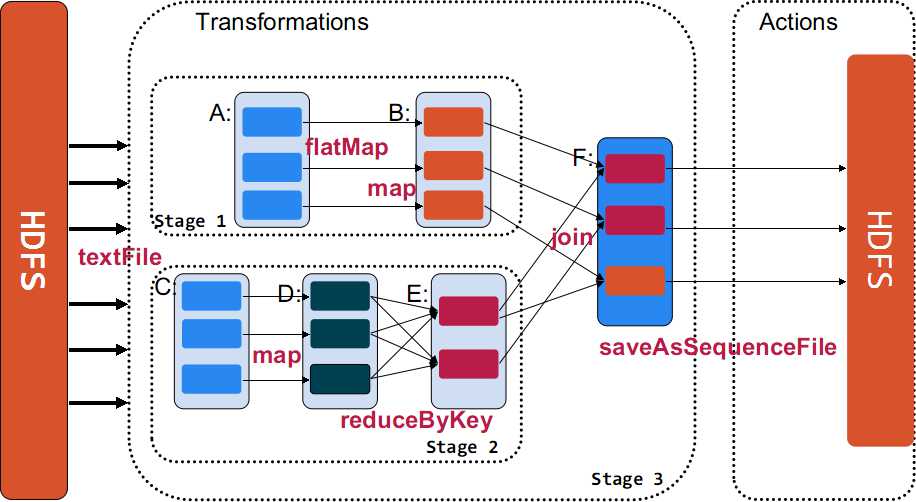
图1. Spark的核心机制图
在Spark的核心机制方面,主要有两个层面:首先是RDD(Resilient Distributed Datasets),RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现,它表示已被分区,不可变的并能够被并行操作的数据集合,并且通常缓存到内存中,并且每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了Map Reduce框架中由于Shuffle操作所引发的大量磁盘IO。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。其次,就是在RDD上面执行的算子(Operator),在Spark的支持算子方面,主要有转换(Transformation)和操作(Action)这两大类。在转换方面支持算子有 map, filter,groupBy和join等,而在操作方面支持算子有count,collect和save等。
Spark常见存储数据的格式是Key-Value,也就是Hadoop标准的Sequence File,但同时也听说支持类似Parquet这样的列存格式。Key-Value格式的优点在于灵活,上至数据挖掘算法,明细数据查询,下至复杂SQL处理都能承载,缺点也很明显就是存储空间比较浪费,和类似Parquet列存格式相比更是如此,key-Value格式数据一般是原始数据大小的2倍左右,而列存一般是原始数据的1/3到1/4。
在效率层面,由于·使用Scala这样基于JVM的高级语言来构建,显而易见会有一定程度的损失,标准Java程序执行时候的速度基本接近C/C++ O0模式的程度,会比C/C++ O2模式的速度慢60%左右。
在技术创新方面,个人觉得Spark还谈不上创新,因为它其实属于比较典型In-Memory Data Grid内存数据网格,无论从7-8年前的IBM WebSphere eXtreme Scale到最近几年新出,并用于12306的Pivotal Gemfire都采用较类似的架构,都主要通过多台机器拼成一个较大内存网格,里面存储的数据都接近Key-Value模式,并且这个内存网格会根据很多机制来确保数据会持久稳定地保存在内存中,并能保持数据的更新和恢复,而在网格上面使用一些常见的算子,来执行灵活的查询,并且用户可以写的程序来直接调用这些算子。
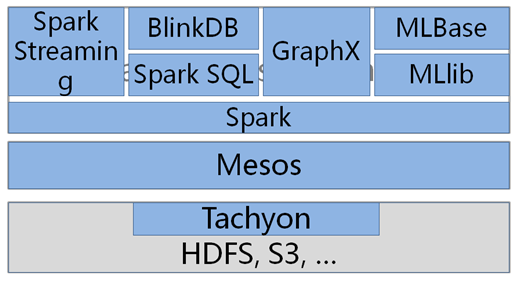
图2. Spark的生态圈
但是在整体架构的展现形式方面的,个人觉得Spark的确是领先同类开源产品两个身位的,因为它已经接近实现其Full Stack的梦想,它包括Spark Streaming,GraphX,MLBase,还有BlinkDB这个绝对的亮点(虽热个人觉得随着计算能力的提高,大数据在今后直接算也是可行的)。还有,个人真心对AMPLab的推广能力深深佩服。个人对Spark的总结是“创新的产品生态,较为传统的技术”。
SAP HANA的设计思路
其实至少10年前就有一波内存计算的风潮,那时代表性的产品主要有用于OLTP事务加速的Timeten和Altibase,而2010年开始的内存计算技术产品,最有代表性的莫过于SAP HANA,由于HANA公开资料比较少,所以在技术方面的描述没办法像Spark那样的详细,那么我这边先根据部分公开的资料和我的一些理解稍微和大家聊聊它使用到的一些核心技术。
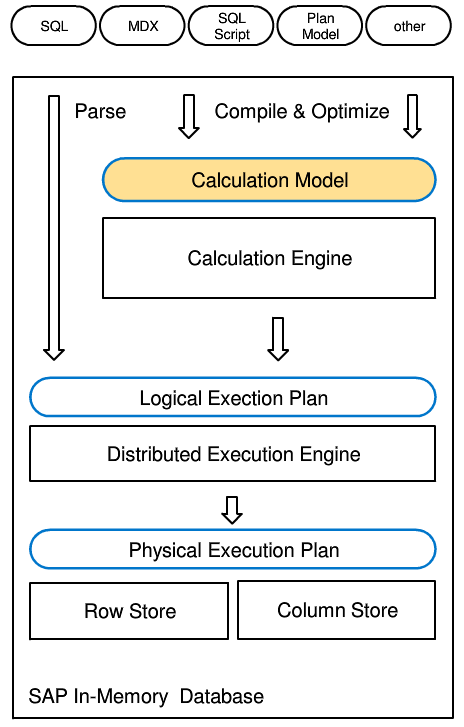
图3. SAP HANA计算引擎
主要有三个方面,首先,在性能优化方面,它尽可能地利用Intel x86 CPU特性,当然这是和他们在HANA设计初期就和德国Intel深度合作有关,主要做了两个设计:其一是全面利用最新的Intel指令集,在处理逻辑上面,全面采用Vector Processing的理念从而尽可能地使用最新的SSE4.1和SSE4.2等指令集,还有就是在NUMA场景下降低消耗,使其多线程性能提升参数尽可能地接近1;其二是在数据结构方面,为了尽可能地利用好Cache,并尽可能少地访问内存,所以推出了缓存敏感的CSB(Cache Sensitive B+)树来代替传统的B树;其次,HANA还支持动态编译,无论是SQL查询还是MDX查询等,在HANA内部都会都被转译一个公共的表示层,名为L语言,并且在执行之前会使用LLVM来进行编译为二进制代码,并执行,这样做的好处主要是避免传统数据库引擎繁琐的Switch-Case逻辑,并且由于这些Switch-Case逻辑很容易导致Context切换,所以如果避免类似的逻辑,这样对整体性能裨益良多;还有就是完全内存化,也就是确保所有数据都在内存中,就算是用来做数据安全性的Snapshot快照也不使用廉价的硬盘,而是使用昂贵的SSD来做保存,这样保存和恢复都更快。
在存储数据结构方面,HANA是行存和列存都支持,但是根据我碰到的一些用户反馈,用户基本上还是以使用列存为主。
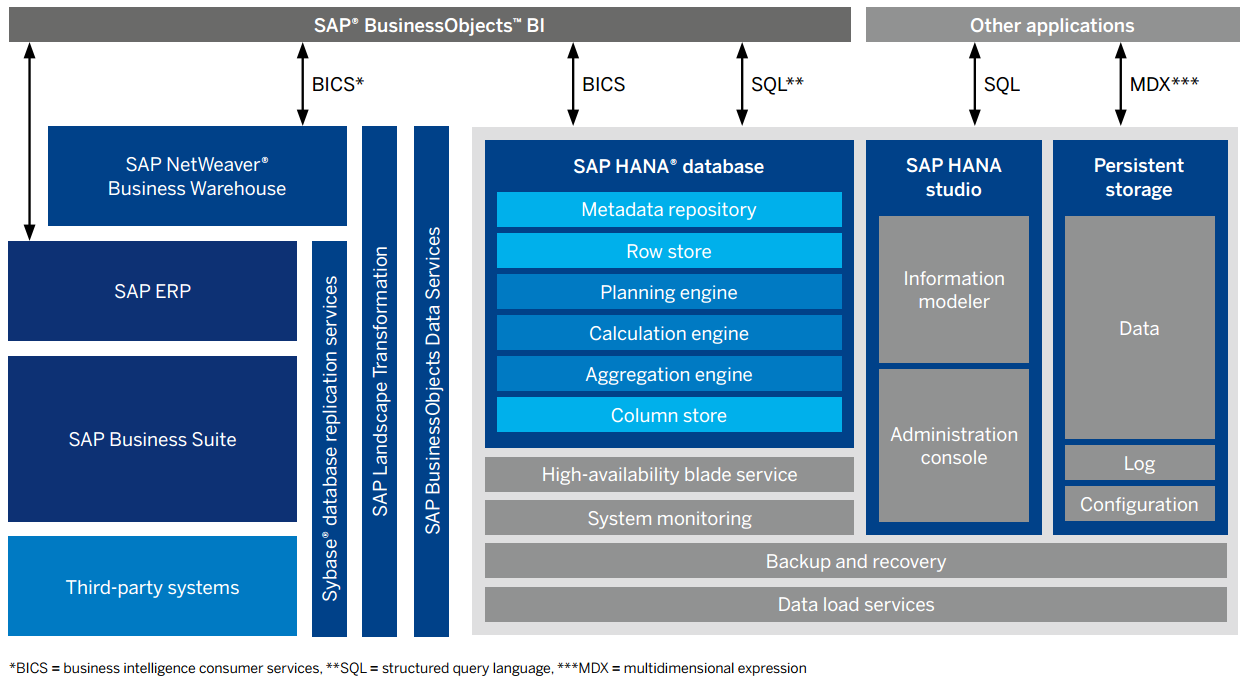
图4. SAP HANA产品全貌
在产品形态方面,它主要还是提供多种工具和产品接入,都主要以分析为主,比如类似SAP NetWeaver或者BO这样BI工具,还有支持文本分析,以及各种预测算法,并且在这些之上,开发出很多针对某些行业的应用,比如,财务方面,物流方面和广告方面的,所以根据部分用户的反馈, HANA如果只是当它内存数据库来用,其实价值不是特别大,但是如果能把它当中开发平台来使用,那么就很物尽其用,因为它上面能利用的库和应用比较多。在销售方式方面,还是传统的License模式。总体而言,个人觉得SAP HANA这样内存计算平台“有特色的技术,较传统的产品形态”。
综述
为什么要聊聊内存计算这个问题,因为我基于个人多年的研发经验,对于常见的SQL分析而言,由于其本身读写形式是连续读,而连续读硬盘本身的读写能力也是挺强的,再加上存储数据本身是压缩的,所以当硬盘个数和CPU个数比较匹配的话(比如1:1),那么在执行数据分析的时候,数据是否在内存并不是极为关键,性能比在1比6左右,也就是数据完全在内存比数据完全在硬盘中快5倍左右,这个性能比在大多数情况下用户不会觉得非常关键,所以个人觉得单纯把全部数据放在内存中的意义不是特别大,因此我特地拿出Apache Spark和SAP HANA这两款产品的出来比较,从而发觉现在其实内存计算没那么简单,还是有非常多的门道的。那么对于用户,该如何在这两种技术之间选择呢?下面是我个人的见解:
对于那些希望有一整套Full Stack的支持初创企业,个人支持你们去使用Spark,因为他们这个群体本身的特色就是喜欢尝试新鲜的东西,数据不会特别大,需求会比较多变,同时也不会使用到特别复杂的功能,所以Spark对他们而言,更适合。
对于HANA的,个人觉得特别适合那些传统企业,因为它的SQL接口更成熟,速度更快,可以做到复杂查询实时出结果,于此同时它提供的文本分析工具和数据挖掘工具,但可惜许可证成本太高,并且也因为这个原因,导致使用HANA的群体比较小,没有一个生态群,所以HANA技术上的创新也很难造福千千万万的程序员。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)