
OpenStack虚拟机管理实例
Nova是OpenStack中的计算服务项目计算虚拟机实例生命周期的所有活动都由Nova管理。Nova提供统一的计算资源服务。Nova需要下列OpenStack服务的支持。Keystone:为所有的OpenStack服务提供身份管理和认证。Glance:提供计算用的镜像库。Neutron:负责配置管理计算实例启动时的虚拟或物理网络连接。Placement:负责跟踪云中可用的资源库存。
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除

目录
一、OpenStack计算服务
1、什么是Nova
- Nova是OpenStack中的计算服务项目,计算虚拟机实例生命周期的所有活动都由Nova管理。
- Nova提供统一的计算资源服务。
- Nova需要下列OpenStack服务的支持。
- Keystone:为所有的OpenStack服务提供身份管理和认证。
- Glance:提供计算用的镜像库。
- Neutron:负责配置管理计算实例启动时的虚拟或物理网络连接。
- Placement:负责跟踪云中可用的资源库存。
2、Nova所用的虚拟技术
- KVM——通用的开放虚拟化技术。
- Xen——部署最快速、最安全、开源的虚拟化软件技术。
- Linux容器——在单一Linux主机上提供多个隔离的Linux环境的操作系统级虚拟化技术。
- Hyper-vare——Microsoft公司推出的企业级虚拟化解决方案。
- VMware ESXi——VMware用于创建和运行虚拟机和虚拟设备的产品。
- Baremetal与Ironic——传统的物理机服务。
3、Nova的系统架构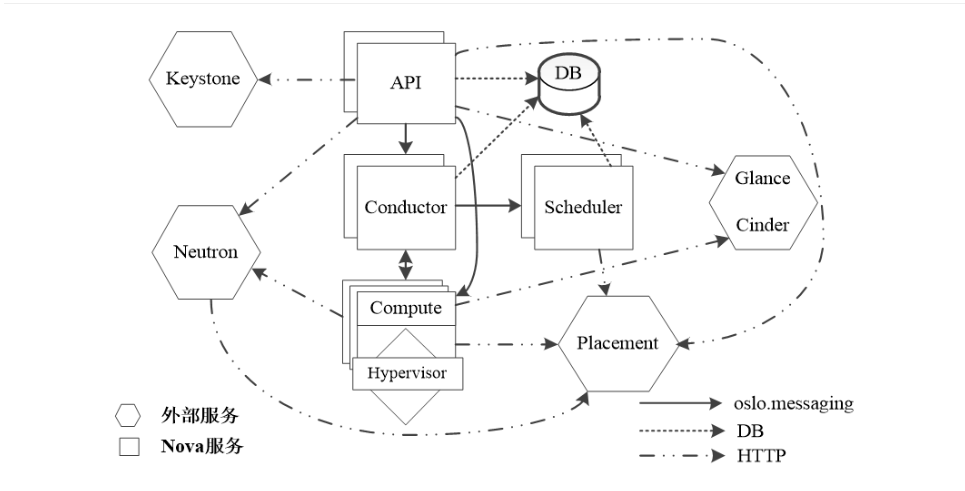
组件说明如下:
- DB:用于数据存储的SQL数据库
- API:用于接收HTTP请求和转换命令,并通过oslo.messaging队列或HTTP与其他组件通信
- Scheduler:用于决定哪台主机承载计算实例的Nova调度器
- Compute:管理Hypervisor与虚拟机实例之间通信的Nova计算组件
- Conductor:中心管理器,用于处理需要协调的请求,作为数据库代理,或者处理对象转换
- Placement:跟踪资源提供者库存和使用的放置服务
4、虚拟机实例化流程
- 用户执行Nova客户端提供的用于创建虚拟机实例的命令
- API组件将请求转换为AMQP消息之后加入消息队列,通过消息队列调用Conductor组件
- Conductor组件从消息队列中接收到虚拟机实例化请求消息后,进行一些准备工作
- Conductor组件通过消息队列通知Scheduler组件选择一个合适的计算节点来创建虚拟机实例
- Conductor组件从Scheduler组件处得到合适的计算节点信息后,通过消息队列通知Compute组件实现虚拟机实例的创建
一、示例
1、验证Nova服务
在ROD一体化OpenStack云平台上查看:
[root@node-a ~]# systemctl status *nova*.service
● openstack-nova-conductor.service - OpenStack Nova Conductor Server
Loaded: loaded (/usr/lib/systemd/system/openstack-nova-conductor.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-04-09 14:26:57 CST; 2 weeks 6 ...
● openstack-nova-compute.service - OpenStack Nova Compute Server
Loaded: loaded (/usr/lib/systemd/system/openstack-nova-compute.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-04-09 14:28:31 CST; 2 weeks 6 ...
● openstack-nova-scheduler.service - OpenStack Nova Scheduler Server
Loaded: loaded (/usr/lib/systemd/system/openstack-nova-scheduler.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-04-09 14:27:03 CST; 2 weeks 6 ...
● openstack-nova-novncproxy.service - OpenStack Nova NoVNC Proxy Server
Loaded: loaded (/usr/lib/systemd/system/openstack-nova-novncproxy.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-04-09 14:21:30 CST; 2 weeks 6 ...共有四个子服务:
- openstack-nova-scheduler.service是计算调度子服务
- openstack-nova-compute.service是计算子服务
- openstack-nova-conductor.service是处理需要请求的子服务
- openstack-nova-novncproxy.service子服务为通过VNC连接访问正在运行的虚拟机提供一个代理
2、试用计算服务的API
列出所有可用的主版本列表
[root@node-a ~]# curl -s -Hcurl -s -H "X-Auth-Token: $OS_TOKEN" http://localhost:8774/ | python -mjson.tool
{
"versions": [
{
"id": "v2.0",
"links": [
{
"href": "http://localhost:8774/v2/",
"rel": "self"
}
],
"min_version": "",
"status": "SUPPORTED",
"updated": "2011-01-21T11:33:21Z",
"version": ""
},
{
"id": "v2.1",
"links": [
{
"href": "http://localhost:8774/v2.1/",
"rel": "self"
}
],
"min_version": "2.1",
"status": "CURRENT",
"updated": "2013-07-23T11:33:21Z",
"version": "2.79"
}
]
}发现有两个可用的API版本v2.0和v2.1。
# 请求一个demo项目作用域的令牌
[root@node-a ~]# curl -i -H "Content-Type: application/json" -d '
{ "auth": {
"identity": {
"methods": ["password"],
"password": {
"user": {
"name": "demo",
"domain": { "id": "default" },
"password": "760ada28891648eb"
}
}
},
"scope": {
"project": {
"name": "demo",
"domain": { "id": "default" }
}
}
}
}' "http://localhost:5000/v3/auth/tokens" ;
# 返回结果提供了令牌ID,还有可访问的端点列表,有关计算服务的端点信息如下:
{"endpoints": [{"region_id": "RegionOne", "url": "http://10.0.0.2:9292", "region": "RegionOne", "interface": "public", "id": "53d6f1fbb2be4ab4bb353d9e24b4c05a"},
...
"type": "compute", "id": "9bc78cabb0a2421e83500e23d31f9c4f", "name": "nova"}执行命令导出环境变量OS_TOKEN:
[root@node-a ~]# export OS_TOKEN="gAAAAA...."尝试通过Nova API v2.1获取当前实例列表
[root@node-a ~]# curl -s -H "X-Auth-Token: $OS_TOKEN" http://localhost:8774/v2.1/servers | python -mjson.tool
{
"servers": []
}本机暂无实例。将URL路径中的v2.1替换为v2,也会得到同样的结果。
二、创建和管理虚拟机实例
1、nova-api服务
- nova-api服务接收和响应来自最终用户的计算API请求。
- 最终用户不会直接发送RESTful API请求,而是通过OpenStack命令行、仪表板和其他需要跟Nova交换的组件使用API。
- nova-api是外部访问并使用Nova提供的各种服务的唯一途径,也是客户端和Nova之间的中间层
2、nova-scheduler服务
-
解决选择启动虚拟机实例的计算节点的问题
-
按照实例类型去选择合适的计算节点
2.1、Nova调度器类型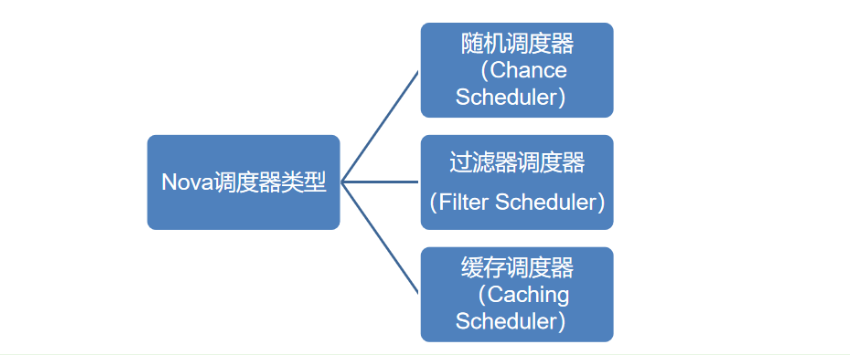
- 随机调度器:从所有nova-compute服务正常运行的节点中随机选择
- 过滤器调度器:根据指定的过滤条件以及权重算法选择最佳的计算节点,又称筛选器
-
缓存调度器:随机调度器的一种特殊类型,在其基础上将主机资源信息缓存在本地内存中,然后通过后台的定时任务从数据库中获取最新的主机资源信息
调度器需要在/etc/nova/nova.conf配置文件中通过scheduler_driver选项指定,默认使用过滤器器调度器
scheduler_driver=nova.scheduler.filter_scheduler.FilterScheduler2.2、过滤器调度器的调度过程
- 第一阶段通过指定的过滤器选择满足条件的计算机节点(运行nova-compute服务的主机)
-
第二阶段对过滤之后的主机类别进行权重计算并排序,选择最优的计算节点来创建虚拟机实例
2.3、过滤器
/etc/nova/nova.conf配置文件中的scheduler_available_filters选项用于配置可用的过滤器,默认所欲的Nova内置的过滤器都可用于执行过滤操作
sheduler_available_filters=nova.scheduler.filters.all_filters另外scheduler_default_filters选项用于执行nova-scheduler服务要使用的过滤器,其默认值:
scheduler_default_filters=RetryFilter, AvailablilityZoneFilter, RamFilter ,DiskFilter, ComputerFilter, ComputerCapabilitiesFilter, ImagePropetiesFilter, ServerGroupAntiAffinityFilterNova内置的过滤器:
| 过滤器 | 说明 |
|---|---|
| RetryFilter(再审过滤器) | 用于过滤掉之前已经调度过的节点 |
| AvailabilityZoneFilter(可用区域过滤器) | 用于将不属于指定可用区域的计算节点过滤掉。为提高容灾性和提供隔离服务,可以将计算节点划分到不同的可用区域中 |
| RamFilter(内存过滤器) | 根据可用内存来调度,将不能满足实例类型内存需求的计算节点过滤掉 |
| DiskFilter(磁盘过滤器) | 根据可用磁盘空间来调度,将不能满足实例类型磁盘需求的计算节点过滤掉 |
| CoreFilter(核心过滤器) | 根据可用CPU核心来调度,将不能满足实例类型vCPU需求的计算节点过滤掉 |
| ComputeFilter(计算过滤器) | 只有nova-compute服务正常工作的计算节点才能够被nova-scheduler服务调度,这是必选的过滤器 |
| ComputeCapabilitiesFilter(计算能力过滤器) | 根据计算节点的特性来过滤 |
| ImagePropertiesFilter(镜像属性过滤器) | 根据所选镜像的属性来过滤 |
| ServerGroupAntiAffinityFilter(服务器组反亲和性过滤器) | 要求尽量将虚拟机实例分散部署到不同的计算节点上 |
| ServerGroupAffinityFilter(服务器组亲和性过滤器) | 要求尽量将虚拟机实例部署到同一个计算节点上 |
2.4、权重计算
所有的权重实现模块位于nova/scheduler/weights目录下。目前nova-scheduler的默认权重实现模块是RAMWeighter,根据计算节点空闲的内存量来计算权重值
3、nova-compute服务
- 在计算节点上运行,负责管理节点上的虚拟机实例
- 创建虚拟机实例最终需要与Hypervisor打交道。Hypervisor以驱动形式在OpenStack系统中实现即插即用。
- nova-compute与Hypervisor一起实现OpenStack对虚拟机实例生命周期的管理
nova-compute的功能:
- 定期向OpenStack报告计算节点的状态
- 实现对虚拟机实例生命周期的管理
nova-compute的处理过程:
- 为实例准备资源
- 创建实例的镜像文件
- 创建实例的XML定义文件
- 创建虚拟网络并启动虚拟机实例
4、nova-conductor服务
- 对数据库进行操作
- 作为nova-compute服务与数据库之间交互的中介,避免了直接访问由nova-compute服务创建的云数据库
- 将nova-compute与数据库分离之后提高了Nova的可伸缩性
-
方便升级
5、Nova计算服务与Placement放置服务
- 从Stein版本开始将Placement API作为一个独立的项目,提供的是放置服务,用于满足计算服务和其他任何服务的资源选择和使用的管理需求
- nova-compute中的Nova资源跟踪器负责创建对应于运行资源跟踪器的计算主机资源提供者记录
- nova-scheduler负责为工作负载选择合适的目标主机
6、镜像和实例的关系
- 实例是在云中的计算节点上运行的虚拟机个体
- 虚拟机镜像为虚拟机文件系统提供模板
- 对实例所做的任何改变都不会影响基础镜像
- 计算服务控制实例、镜像的存储和管理
- 未运行虚拟机实例的基础镜像状态

-
基于一个镜像创建的实例

-
删除实例后镜像和卷的状态

7、命令行的实例创建用法
在使用命令行之前需要导出用户的环境变量,在创建实例之前,查看所需的前提条件:
openstack flavor list #列出可用的实例类型
openstack image list #列出可用的镜像
openstack network list #列出可用的网络
openstack security group list #列出可用的安全组
openstack keypair list #列出可用的密钥对创建实例命令openstack server create的详细语法:
openstack server create
(--image <镜像> | --volume <卷>)
--flavor <实例类型>
[--security-group <安全组>]
[--key-name <密钥对>]
[--property <服务器属性>]
[--file <目的文件名=源文件名>]
[--user-data <实例注入文件信息>]
[--availability-zone <域名>]
[--block-device-mapping <块设备映射>]
[--nic <net-id=网络ID,v4-fixed-ip=IP地址,v6-fixed-ip=IPv6地址,port-id=端口UUID,auto,none>]
[--network <网络>]
[--port <端口>]
[--hint <键=值>]
[--config-drive <配置驱动器卷>|True]
[--min <创建实例最小数量>]
[--max <创建实例最大数量>]
[--wait]
<实例名>命令行的实例管理用法:
# 获取列表
openstack server list
# 查看实例详情
openstack server show [--diagnostics] <实例名或ID >
# 启动实例
openstack server start <实例名或ID> [<实例名或ID > ...]
# 暂停实例及恢复
openstack server [pause | unpause] <实例名或ID> [<实例名或ID > ...]
# 挂起实例及恢复
openstack server [suspend | resume] <实例名或ID> [<实例名或ID > ...]
# 废弃实例及恢复
openstack server [shelve | unshelve]<实例名或ID> [<实例名或ID > ...]
# 关闭实例
openstack server stop <实例名或ID> [<实例名或ID > ...]
# 重启实例
openstack server reboot [--hard | --soft] [--wait] <实例名或ID>
# 调整实例大小
openstack server resize [--flavor <flavor> | --confirm | --revert] [--wait] <实例名或ID>
# 删除实例
openstack server delete <实例名或ID> [<实例名或ID > ...]
# 修改实例
openstack server set [--name <新名称>] [--root-password] [--property <键=值>]
[--state <状态>] <实例名或ID>二、示例:
1、生成密钥对
# 加载demo用户环境脚本
[root@node-a ~]# source keystonerc_demo
# 创建一个名为“demo-pub”的公钥
[root@node-a ~(keystone_demo)]# openstack keypair create --public-key ~/.ssh/id_rsa.pub demo-pub
+-------------+-------------------------------------------------+
| Field | Value |
+-------------+-------------------------------------------------+
| fingerprint | 91:17:86:06:70:0c:8d:f0:4a:d5:9a:61:75:1a:f5:3d |
| name | demo-pub |
| user_id | 0335a26accd149c595e1215fa8d199cf |
+-------------+-------------------------------------------------+使用openstack keypair list查看当前密钥对列表,列表显示每个密钥对的名称和对应的指纹
[root@node-a ~(keystone_demo)]# openstack keypair list
+----------+-------------------------------------------------+
| Name | Fingerprint |
+----------+-------------------------------------------------+
| demo-key | 74:65:07:cf:20:45:32:f4:53:51:89:74:c3:43:72:92 |
| demo-pub | 91:17:86:06:70:0c:8d:f0:4a:d5:9a:61:75:1a:f5:3d |
+----------+-------------------------------------------------+使用openstack keypair show命令查看指定密钥对的详细信息:
[root@node-a ~(keystone_demo)]# openstack keypair show demo-key
+-------------+-------------------------------------------------+
| Field | Value |
+-------------+-------------------------------------------------+
| created_at | 2024-04-23T00:44:39.000000 |
| deleted | False |
| deleted_at | None |
| fingerprint | 74:65:07:cf:20:45:32:f4:53:51:89:74:c3:43:72:92 |
| id | 2 |
| name | demo-key |
| updated_at | None |
| user_id | 0335a26accd149c595e1215fa8d199cf |
+-------------+-------------------------------------------------+该命令加上--public-key选项则仅显示指定密钥对的公钥
[root@node-a ~(keystone_demo)]# openstack keypair show --public-key demo-key
ssh-rsa AAAAB3N...使用openstack keypair delete命令可删除指定密钥对
2、添加安全组规则
添加允许ICMP(ping)和安全shell(SSH)规则:
openstack security group rule create --proto icmp default
openstack security group rule create --proto tcp --dst-port 22 default3、管理实例类型
(1)通过Web界面管理实例类型
略...
(2)通过命令行管理实例类型
# 显示实例类型列表
openstack flavor list
# 查看实例类型详细的语法格式
openstack flavor list 实例类型ID
# 创建实例的简单方法
openstack flavor create 实例类型名称 --id 实例类型ID --ram 内存 --disk 根磁盘 --vcpus VCPU数
# 可使用--public选项觉得实例类型是所有用户可访问,默认为True
openstack flavor create --public m1.extra_tiny --id auto --ram 256 --disk 0 --vcpus 1 --rxtx-factor 1对于现有本地实例类型,使用openstack flavor set命令来修改其参数设置
删除实例类型命令:
openstack flavor delete 实例类型ID4、创建实例
-
基于cirros镜像创建一个实例(实例类型为"m1.tiny"、密钥对为"demo-key"、名为“cirros-VM2")
[root@node-a ~(keystone_demo)]# openstack server create --image cirros --flavor m1.test --key-name demo-key cirros-VM2-
创建一个基于cirros镜像的大小为1GB的卷
[root@node-a ~(keystone_demo)]# openstack volume create --image cirros --size 1 --availability-zone nova mybootvol-
基于该卷创建实例
[root@node-a ~(keystone_demo)]# openstack server create --flavor m1.tiny --volume mybootvol --key-name demo-key cirros-VM35、创建实例排错
-
查看创建实例所有相关的日志
grep 'ERROR' /var/log/nova/*
grep 'ERROR' /var/log/neutron/*
grep 'ERROR' /var/log/glance/*
grep 'ERROR' /var/log/cinder/*
grep 'ERROR' /var/log/keystone/*典型错误:
(1)"No valid host was found. There are not enough hosts available."
- 计算节点的内存不足,CPU资源不够,硬盘空间资源不足。
- 网络配置不正确,造成创建实例时获取IP失败。可能使网络不通或防火墙引起的。
-
openstack-nova-compute服务状态问题。
执行以下命令查看指定计算节点的资源使用情况
[root@node-a ~(keystone_demo)]# openstack htpervisor show node-a(2)“Volume xxx did not finish being created even after we waited x seconds or 61 attempts. And its status is downloading.”
-
创建卷需要的时间比较久,在卷创建成功之前,Nova组件等待超时了。/etc/nova/nova.conf配置文件中有一个控制设备重试的选项block_device_allocate_retires,通过修改此项的值来延长等待时间。
6、管理虚拟机实例
7、访问虚拟机实例列表
# 通常先将证书私钥文件(.SSH)存放到用户主目录下的.ssh子目录中:
[root@node-a Downloads(keystone_demo)]# rz
[root@node-a Downloads(keystone_demo)]# ls
demo-key.pem
[root@node-a Downloads(keystone_demo)]# cd ..
# 修改该密钥文件的访问权限
[root@node-a ~(keystone_demo)]# cp Downloads/demo-key.pem ~/.ssh
[root@node-a ~(keystone_demo)]# chmod 700 ~/.ssh/demo-key.pem
[root@node-a ~(keystone_demo)]# ssh -i ~/.ssh/demo-key.pem cirros@10.0.0.2另一种方式是获取正在运行的虚拟机实例的VNC会话URL并从Web浏览器直接访问它:

三、注入元数据实现虚拟机实例个性化配置
1、元数据注入
通过向虚拟机实例注入元数据信息完成个性化配置工作
元数据信息分成两大类:
- 元数据——结构化数据,以键值对形式注入虚拟机实例
- 用户数据——非结构化数据,通过文件或脚本的方式进行注入,支持多种文件格式
注入机制分为两种:
- 元数据服务机制
-
配置驱动器机制
SSH密钥注入的实现过程:
- OpenStack创建一个SSH密钥对
- 创建虚拟机实例时选择该SSH密钥对
-
用户可以用该SSH密钥对的私钥直接登录实例
2、元数据服务机制
元数据服务的架构:
虚拟机实例通过元数据服务获取元数据的大致流程:
- 虚拟机实例通过项目网络将元数据请求发送到neutron-ns-metadata-proxy
- neutron-ns-metadata-proxy通过unix domain socket将请求发送给neutron- metadata-agent
- neutron-metadata-agent通过内部管理网络将请求转发给nova-api-metadata
-
获取的元数据被原路返回给发出请求的虚拟机实例
3、配置驱动器机制
- 配置驱动器主要用于配置虚拟机实例的网络信息
- 配置驱动器是一个特殊的文件系统
- 配置驱动器的具体实现会根据Hypervisor和具体配置有所不同
- 使用配置驱动器对计算主机和镜像都有一定的要求
-
启用配置驱动器,可在执行openstack server create命令创建虚拟机实例时使用--config-drive true选项,也在/etc/nova/nova.conf配置文件中设置force_config_drive=true
4、进一步了解cloud-init
cloud-init在虚拟机实例启动时的运行过程:
三、示例
1、向虚拟机实例注入用户数据
在脚本中使用cloud-config指令,利用cloud-init的cc_set_passwords.py模块为用户设置密码并启用密码登录方式:示例:
#cloud-config #cloud-init会读取它开头的数据,这一行一定要写上
chpasswd:
list: |
root:abc123 #设置root密码
fedora:abc123 #设置默认用户fedora的密码
expire: false #密码不过期
ssh_pwauth: true #启用SSH密码登录(默认只能通过SSH密钥登录)注释只是说明,使用时将注释删除。
通过SSH登录该实例进行测试:
[root@node-a ]# ssh curl fedora@10.0.0.2
...
fedora@10.0.0.2'password: # 输入用户数据中设置的fedora密码
[fedora@fedora-NEWVM ~]# # 成功登录2、设置虚拟机实例的元数据: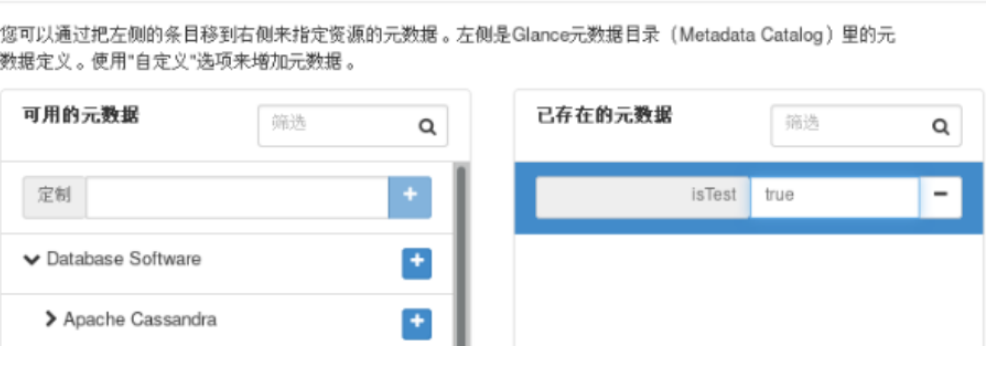
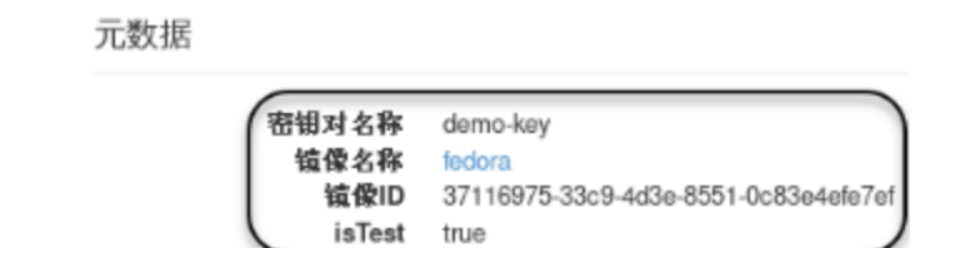
3、验证元数据服务机制
实例可通过http://169.254.169.254访问元数据服务。
元数据服务支持两套API
- OpenStack元数据API
-
EC2兼容的API
获取元数据API所支持的版本列表。
curl http://169.254.169.254/openstack进一步获取其中最新版本(latest)的元数据文件目录。
curl http://169.254.169.254/openstack/latest查看meta_data.json文件的内容并以JSON格式显示。
curl http://169.254.169.254/openstack/latest/meta_data.json | python -m json.tool访问用户数据。
curl http://169.254.169.254/openstack/latest/user_data4、验证配置驱动器机制
通过SSH登录该实例,将配置驱动器挂载到/mnt/config目录
[fedora@fedora-newvm ~]$ su root #切换到root身份操作
Password:
[root@fedora-newvm fedora]# mkdir -p /mnt/config #创建挂载目录
[root@fedora-newvm fedora]# mount /dev/disk/by-label/config-2 /mnt/config #挂载配置驱动器
mount: /mnt/config: WARNING: device write-protected, mounted read-only.
[root@fedora-newvm fedora]# exit #退出root身份操作
exit执行mount命令查看当前挂载的文件系统,发现以下信息:
/dev/sr0 on /mnt/config type iso9660 (ro,relatime,nojoliet,check=s,map=n,blocksize=2048)查看该挂载目录下的内容,可以发现其中有两个目录:
[root@fedora-newvm fedora]# ls /mnt/config
ec2 openstack查看最新版本(latest)的元数据文件目录:
[root@fedora-newvm fedora]# ls /mnt/config/openstack/latest
meta_data.json network_data.json user_data vendor_data2.json vendor_data.json四、增加一个计算节点
1、计算服务的物理部署
1.1、Nova的物理部署
- Nova多个组件和服务部署在计算节点和控制节点节点上
- 计算节点上安装Hypervisor以运行虚拟机实例,只需要运行nova-compute服务
- 其他Nova组件和服务则一起部署在控制节点上
-
通过增加控制节点和计算节点,可以实现简单、方便的系统扩容
1.2、Nova的部署模式
-
Nova经典部署模式

-
Nova负载均衡部部署署模式

2、增加一个计算节点并进行验证
2.1、准备双节点OpenStack云平台安装环境
- 参照之前node-a的方式,添加一个计算节点node-b(192.168.199.31/24),为第2个节点准备环境
-
更改其主机名为“node-b”,将新的主机名追加到/etc/hosts配置文件中,并将第1个节点的主机名的解析添加进来,本例配置如下:
192.168.199.31 node-a node-a.localdomain
192.168.199.32 node-b node-b.localdomain- 将第2个节点主机名的解析也添加到第1个节点主机的/etc/hosts配置文件中
-
设置时间同步。第2个节点也与第1个节点一样配置Chrony
2.2、编辑应答文件
编辑packstack-answers-addnode.txt:
CONFIG_COMPUTE_HOSTS=192.168.199.31,192.168.199.32
CONFIG_PROVISION_DEMO_FLOATRANGE=192.168.199.0/24
CONFIG_KEYSTONE_ADMIN_PW=ABC123456
CONFIG_KEYSTONE_DEMO_PW=ABC1234562.3、使用修改过的应答文件运行Packstack安装器
[root@node-a ~]# packstack --answer-file=packstack-answers-addnode.txt
…
Installing:
Clean Up [ DONE ]
Discovering ip protocol version [ DONE ]
root@192.168.199.32's password: #提供第2个节点root账户密码
Setting up ssh keys [ DONE ]
Preparing servers [ DONE ]
…
Copying Puppet modules and manifests [ DONE ]
Applying 192.168.199.31_controller.pp
192.168.199.31_controller.pp: [ DONE ]
Applying 192.168.199.31_network.pp
192.168.199.31_network.pp: [ DONE ]
Applying 192.168.199.31_compute.pp
Applying 192.168.199.32_compute.pp #应用第2个计算节点
192.168.199.31_compute.pp: [ DONE ]
192.168.199.32_compute.pp: [ DONE ]
Applying Puppet manifests [ DONE ]
Finalizing [ DONE ]2.4、验证双节点部署
-
虚拟机管理器列表

-
计算主机列表

-
计算服务列表

-
网络代理列表

-
新创建测试用的虚拟机实例

-
新创建的虚拟机实例在node-b主机上运行

五、迁移虚拟机实例
1、实例冷迁移
- 冷迁移是一种非在线的迁移方式
- 冷迁移主要用于重新分配节点的计算资源,或者主机节点停机维护等场合
- 实例冷迁移的功能与调整实例大小类似,只是冷迁移不改变实例的实例类型
- 冷迁移不要求源和目的主机必须共享存储,但要求两者必须满足在计算节点间配置nova用户的无密码SSH访问
- 默认只有云管理员角色能够执行实例迁移操作
2、实例热迁移
- 热迁移是一种在线的迁移方式,又称实时迁移
- 在迁移过程中实例不会关闭,始终保持运行状态
- 有以下类型:
- 基于共享存储的实时迁移
- 块实时迁移(简单块迁移)
- 基于卷的实时迁移
3、热迁移命令行用法
openstack server migrate
[--live <目的主机>] # 用于指定目的主机
[--shared-migration | --block-migration] # 执行基于共享存储的实时迁移,包括基于共享存储和基于卷的实时迁移,这是默认设置 | 块实时迁移
[--disk-overcommit | --no-disk-overcommit] # 是否允许磁盘超量
[--wait]
<实例名或ID>4、示例
4.1、在计算节点之间配置SSH无密码访问
(1)在两个节点上准备SSH密钥对及其配置文件
使SSH可以进行非交互式登录:
[root@node-a ~]# echo -e 'StrictHostKeyChecking no' > /var/lib/nova/.ssh/config将/var/lib/nova/.ssh/config文件复制到node-b节点对应的目录中:
[root@node-a ~]# scp -r /var/lib/nova/.ssh/config node-b:/var/lib/nova/.ssh(2)在两个节点上分别执行命令使nova用户可以登录
usermod -s /bin/bash nova(3)在两个节点上检查确认nova用户可以不用密码登录到对方节点 (4)以root用户身份在两个节点上重新启动libvirt和计算服务
systemctl restart libvirtd.service openstack-nova-compute.service4.2、执行实例的冷迁移操作
-
从“动作”下拉菜单中选择“迁移实例”命令

-
确认迁移实例

-
确认或放弃调整大小/迁移

-
实例迁移成功

-
查看实例列表

-
执行命令迁移虚拟机实例
[root@node-a ~(keystone_admin)]# openstack server migrate c76418b1-24ca- 43b0-8d49-70114d8e41e6 -
查看实例当前状态

-
执行命令确认调整:
[root@node-a ~(keystone_admin)]# openstack server resize confirm c76418b1-24ca-43b0- 8d49-70114d8e41e6 -
查看实例列表:

4.3、实现热迁移的通用配置
(1)在每个计算节点上的/etc/nova/nova.conf配置文件中设置server_listen和instances_path参数。
(2)确认每个计算节点具有相同的名称解析配置,以便它们能通过主机名互相访问。
(3)启用root用户免密码SSH功能。
- 在第1个节点上将root用户的SSH公钥加入authorized_keys文件。
- 在第1个节点上将authorized_keys文件复制到第2个节点上。
- 在第2个节点上将root用户的SSH公钥追加到authorized_keys文件中。
- 在第2个节点上将authorized_keys文件复制回第一个节点上。
(4)如果启用防火墙,则应允许计算节点之间的libvirt通信
-
查看虚拟机实例概况(位于可启动的卷):

-
从动作菜单中选择“实例热迁移”命令:

-
实例热迁移设置:

-
成功迁移之后的实例

-
执行实例的热迁移操作
-
查看虚拟机实例概况(未连接卷)
致谢
在此,我要对所有为知识共享做出贡献的个人和机构表示最深切的感谢。同时也感谢每一位花时间阅读这篇文章的读者,如果文章中有任何错误,欢迎留言指正。
学习永无止境,让我们共同进步!!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 32
32 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)