【论文阅读】The Design of a Practical System for Fault-Tolerant Virtual Machines
"The Design of a Practical System for Fault-Tolerant Virtual Machines"是MIT6.824推荐阅读的论文之一,它介绍了一种通过主备机制来进行单核虚拟机级别的容错方法。
为了更有效的做论文阅读笔记,之后都打算将每篇论文笔记的内容控制在较少的字数范围内,毕竟原论文摆在那里,将其翻译照抄过来也没什么意思,将论文读薄才是最重要的。( •̀ ω •́ )✧
"The Design of a Practical System for Fault-Tolerant Virtual Machines"是MIT6.824推荐阅读的论文之一,它介绍了一种通过主备机制来进行单核虚拟机级别的容错方法。
相关背景
本文考虑的主要是fail-stop故障,例如电源线拔掉了,爆炸了,网络离线了等情况,而这也才能用复制的方法容错,普通的程序错误导致的故障也无法通过复制来解决。
容错一般有两种方法:
- **状态转移:**拷贝主虚拟机的所有状态到另一个虚拟机上
- **复制状态机:**将虚拟机认为是一个状态机,只拷贝具体的操作
明显复杂状态机对宽带要求更低,但是其设计更为复杂,本文采用的是复制状态机的方法。但是后面VMWare团队有推出多核虚拟机级别的容错,该方法采用的是类似状态转移的方法。
容错一般还可以分为应用层容错和主机层容错,本文是主机层,在这有容错的虚拟机上可以运行任何应用。
设计概述

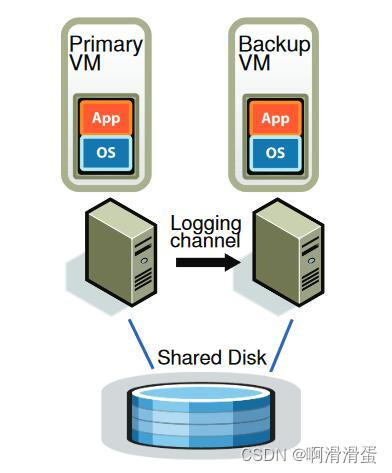
设计主要解决的问题是如何保证两个VM的状态一直保持一致。两个主副VM之间会通过Logging channel进行连接,主VM会将其任何会导致两者状态不一致的命令或者非确定性事件命令都通过Logging channel发送给副VM,副VM会读取该channel来执行相同的操作,但是该执行的输出会被忽略掉。
传递指令需要特别注意的是一些非确定性事件,该事件主要有两类分别是随时到达的客户端输入和在不同时刻不同的VM上会产生不同的结果的怪异指令,例如生成随机数、获取当前时间、获取主机id等。
非确定性事件还包括CPU并发,因为指令交织的顺序难以保证,例如两个并发的线程同时向一块数据加锁,那么主副VM上哪个线程能拿到锁其实是不确定的,但是本文是针对单CPU的,没有提及这个问题
可以猜测传递的日志中主要有三样东西:
- 事件发生时的指令序号,即自机器启动以来指令的相对序号
- 日志类型
- 数据,如果是网络数据包日志,那么就包含对应的数据,如果是怪异指令,那么就是其在主虚拟机上执行的结果
需要注意的是为了保证副VM的执行不会超过主VM,副VM只有的channel里面有指令的时候才会继续运行,即副VM永远会落后主VM一个指令,不然就会一直停止等待,或者检测到主VM挂了,自己上台当主VM
输出控制
系统通过网络数据包来与用户进行交互,文章的目标是让用户接收到返回信息时该指令一定是在两个VM上都能执行了的,它避免的是如下的场景:
- 主虚拟机给了用户返回,但是由于其马上crash了,没有将指令及时传给副VM,那么后面通过副VM上台时,该命令其实是没执行的,但是用户会以为其已经执行了

解决方法是:主VM输出返回必须要在发送了日志且副VM返回了确认接收之后
当然这也有可能会导致重复输出,因为主VM输出后马上奔溃,而副VM上台后还没有执行这个命令,那么后面再执行时就会导致重复输出,而文中提到由于有TCP的规则在,由于输出的是完全一致的数据包,该重复输出会被TCP的协议解决掉。
容错
主副VM之间需要知道对方有没有存活,文中使用了UDP心跳来检测服务器是否奔溃,此外也通过监控日志流量(因为定时器中断的存在,日志流量应该是有规律的)来探查,如果超过特点时间,就可能发生故障了,但是这依然会存在脑裂的问题,如果只是两个VM之间的网络出问题了,那么副VM如果这时上台就会出现两个主VM。文中采用的解决方案是通过Test-and-Set方案,它会在共享存储中执行一个原子性的测试设置操作。如果操作成功,VM就会被允许上线,如果不成功就说明另外一个还在运行。如果采用的不是共享存储,那么也会引入一个第三方的决策者来进行判断。
如果是副VM奔溃了,则会重新起一个副VM,该VM来自对主VM的完全拷贝。
同时为了保证容错的副VM上台后,不会需要太长时间才能把剩余的命令消费掉,已经为了防止channel的缓冲区被填满,副VM会和主VM保持一定的指令数间隔,文中提到执行延迟应不小于100ms,如果副VM跟不上主VM的处理速度,系统会分配给主VM更少的Cpu周期数来平衡两者的速度。
参考资料

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)