Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)
Hadoop集群环境安装配置详见:Hadoop完全分布式集群安装及配置(基于虚拟机)Ubuntu镜像版本: ubuntu-16.04.2-server-amd64.isoJDK版本: jdk1.8Hadoop版本: hadoop-2.7.3已安装的Hadoop集群中主机名和对应的IP如下:主机名IPhadoop2m(master)192.168.163.13
Hadoop入门配置系列博客目录一览
1、Eclipse中使用Hadoop伪分布模式开发配置及简单程序示例(Linux下)
2、使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)
3、Hadoop完全分布式集群安装及配置(基于虚拟机)
4、Eclipse中使用Hadoop集群模式开发配置及简单程序示例(Windows下)
5、Zookeeper3.4.9、Hbase1.3.1、Pig0.16.0安装及配置(基于Hadoop2.7.3集群)
6、mysql5.7.18安装、Hive2.1.1安装和配置(基于Hadoop2.7.3集群)
7、Sqoop-1.4.6安装配置及Mysql->HDFS->Hive数据导入(基于Hadoop2.7.3)
8、Hadoop完全分布式在实际中优化方案
9、Hive:使用beeline连接和在eclispe中连接
10、Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)
11、Win下使用Eclipse开发scala程序配置(基于Hadoop2.7.3集群)
12、win下Eclipse远程连接Hbase的配置及程序示例(create、insert、get、delete)
Hadoop入门的一些简单实例详见本人github:https://github.com/Nana0606/hadoop_example
本篇博客主要介绍“Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)”。
Hadoop集群环境
安装配置详见: Hadoop完全分布式集群安装及配置(基于虚拟机)
Ubuntu镜像版本: ubuntu-16.04.2-server-amd64.iso
JDK版本: jdk1.8
Hadoop版本: hadoop-2.7.3
已安装的Hadoop集群中主机名和对应的IP如下:
| 主机名 | IP |
|---|---|
| hadoop2m(master) | 192.168.163.131 |
| hadoop2_s1(slave) | 192.168.163.132 |
| hadoop2_s2(slave) | 192.168.163.133 |
注意: 1、在安装scala和spark之前,hadoop集群环境可以开启也可以关闭(我安装的时候是把集群环境关闭的),但是在spark测试之前一定要开启hadoop,因为spark的运行需要用到Hive环境。 2、scala和spark在所有节点上都需要安装,这里先在主节点上安装,然后使用scp命令复制到其他人节点。即:下述所有配置都在主节点上操作(scala检测在所有节点上都要操作)
Scala-2.12.2
1、下载
下载地址: http://www.scala-lang.org/download/2.12.2.html(页面最下方有下载版本)
下载版本: scala-2.12.2.tgz
压缩包存放目录: /home/lina/Software/Hadoop/scala-2.12.2.tgz
2、解压
将目录切换到压缩包存放的目录,我们这里将其解压到(安装到)/opt/Hadoop/文件夹下,命令如下:cd /home/lina/Software/Hadoop
tar -zxf scala-2.12.2.tgz -C /opt/Hadoop
解压之后的目录文件为/opt/Hadoop/scala-2.12.2
3、配置环境变量
使用`sudo vi ~/.bashrc`打开环境配置文件,增加如下内容:export SCALA_HOME=/opt/Hadoop/scala-2.12.2
export PATH=$SCALA_HOME/bin:$PATH
使用source ~/.bashrc使之立即生效。
4、使用scp命令将文件拷到slaves
命令如下:cd /opt/Hadoop
scp -r scala-2.12.2 hadoop2_s1:/opt/Hadoop //将scala-2.12.2文件夹复制到hadoop2_s1的/opt/Hadoop/文件夹下
scp -r scala-2.12.2 hadoop2_s2:/opt/Hadoop //将scala-2.12.2文件夹复制到hadoop2_s2的/opt/Hadoop/文件夹下
5、测试环境是否安装成功
使用scala -version检测scala是否安装成功(所有节点都需要安装),若安装成功,则会出现下图内容: Spark-2.1.0
1、下载
下载地址: http://spark.apache.org/downloads.html
选择下图所示版本:
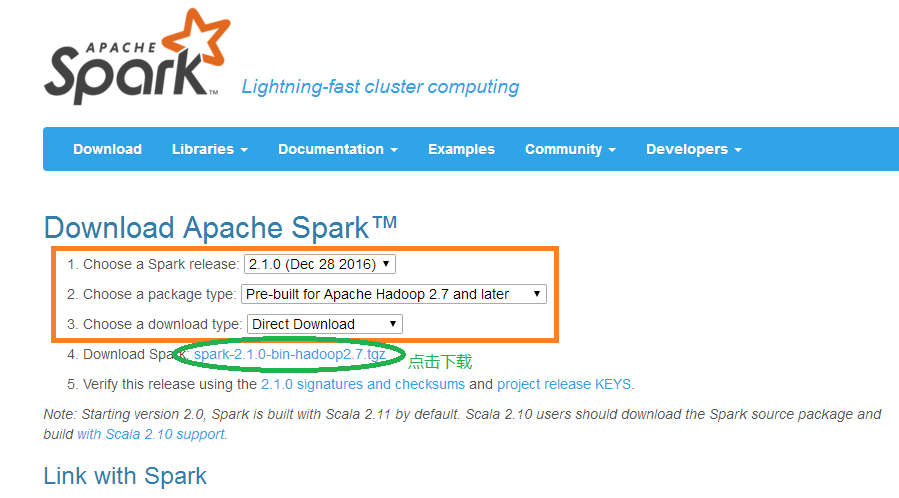
下载版本: spark-2.1.0-bin-hadoop2.7.tgz
压缩包存放目录: /home/lina/Software/Hadoop/spark-2.1.0-bin-hadoop2.7.tgz
2、解压
将目录切换到压缩包存放的目录,我们这里将其解压到(安装到)/opt/Hadoop/文件夹下,命令如下:cd /home/lina/Software/Hadoop
tar -zxf spark-2.1.0-bin-hadoop2.7.tgz -C /opt/Hadoop
解压之后的目录文件为/opt/Hadoop/spark-2.1.0-bin-hadoop2.7,使用下面的命令对文件夹重命名:
cd /opt/Hadoop
mv spark-2.1.0-bin-hadoop2.7 spark-2.1.0-hadoop2.7 //将文件夹重命名为spark-2.1.0-hadoop2.7
3、配置环境变量
使用`sudo vi ~/.bashrc`打开环境配置文件,增加如下内容:export SPARK_HOME=/opt/Hadoop/spark-2.1.0-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
使用source ~/.bashrc使之立即生效。
4、修改配置文件
以下操作在$SPARK_HOME/conf/文件夹下操作,因为文件夹中只有默认配置文件,所以使用下面的命令,复制一份并重命名:cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
(1)修改spark-env.sh
使用`sudo vi slaves`打开文件,配置如下内容:export SCALA_HOME=/opt/Hadoop/scala-2.12.2
export JAVA_HOME=/opt/Java/jdk1.8
export SPARK_MASTER_IP=hadoop2m
export SPARK_WORKER_MEMORY=800m #注意:这个大小根据自己的情况可以改动
export HADOOP_CONF_DIR=/opt/Hadoop/hadoop-2.7.3/etc/hadoop
(2)修改slaves
使用`sudo vi slaves`打开文件,配置如下内容:hadoop2m
hadoop2_s1
hadoop2_s3
5、使用scp命令将文件拷到slaves
命令如下:cd /opt/Hadoop
scp -r spark-2.1.0-hadoop2.7 hadoop2_s1:/opt/Hadoop //将spark-2.1.0-hadoop2.7文件夹复制到hadoop2_s1的/opt/Hadoop/文件夹下
scp -r spark-2.1.0-hadoop2.7 hadoop2_s2:/opt/Hadoop //将spark-2.1.0-hadoop2.7文件夹复制到hadoop2_s2的/opt/Hadoop/文件夹下
6、测试是否安装成功
启动hadoop集群,使用`spark-shell`测试(根目录下即可),结果如下图: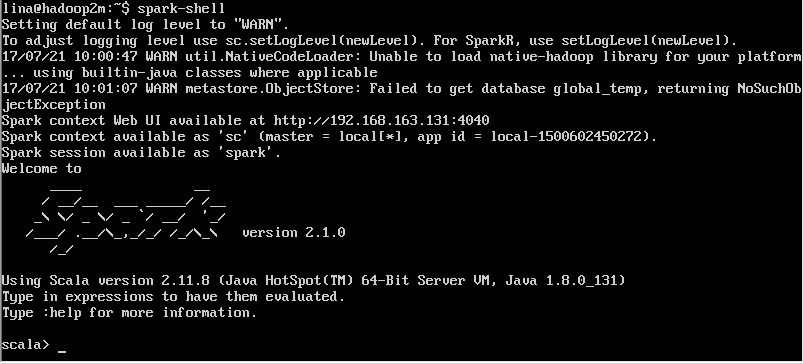

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)