caffe︱cifar-10数据集quick模型的官方案例
准备拿几个caffe官方案例用来练习,就看到了caffe中的官方案例有cifar-10数据集。于是练习了一下,在CPU情况下构建quick模型。主要参考博客:liumaolincycle的博客 配置:win10下虚拟机,ubuntu 16.04 虚拟机安装: win10系统搭建虚拟机:VMware Workstation Player 12环境+Ubuntu Kylin 16.
准备拿几个caffe官方案例用来练习,就看到了caffe中的官方案例有cifar-10数据集。于是练习了一下,在CPU情况下构建quick模型。主要参考博客:liumaolincycle的博客
配置:win10下虚拟机,ubuntu 16.04
虚拟机安装:
win10系统搭建虚拟机:VMware Workstation Player 12环境+Ubuntu Kylin 16.04 LTS系统
caffe安装:caffe+CPU︱虚拟机+Ubuntu16.04+CPU+caffe安装笔记
本案例图片是帮你处理过了,尺寸变化、图像像素均值文件都已经给出了。
————————————————————————————————————
一、数据集准备
本实验使用的数据集是CIFAR-10,一共有60000张32*32的彩色图像,其中50000张是训练集,另外10000张是测试集。数据集共有10个类别,分别如下所示

数据通过一个命令会帮你下载,并且帮你计算好。图像均值文件等。
cd /CAFFE
sudo /data/cifar10/get_cifar10.sh #该脚本会下载二进制的cifar,并解压,会在/data/cifar10中出现很多batch文件
sudo /examples/cifar10/create_cifar10.sh #运行后将会在examples中出现数据集./cifar10_xxx_lmdb和数据集图像均值./mean.binaryproto
一定要先定位在caffe文件夹下面,以下代码才可以运行成功。下载数据会比较慢。
————————————————————————————————————
二、设置solver
由于一些虚拟机没有能用的GPU所以需要修改一下solver文件。
linux修改可以用vim 也可以用gedit ,笔者不是特别会用vim,所以对gedit使用的较多。
建模的是quick所以需要修改的文件是:cifar10_quick_solver.prototxt
————————————————————————————————————
三、训练
直接调用.sh文件就可以开始训练了。
cd $CAFFE
./examples/cifar10/train_quick.sh #先以0.001的学习率迭代4000次,再以0.01的学习率接着再迭代1000次,共5000次
还有full模型,full模型比quick模型迭代次数多,一共迭代70000次,前60000次学习率是0.001,中间5000次学习率是0.0001,最后5000次学习率是0.00001。full模型的网络层数也比quick模型多。
测试准确率也比quick模型高,大约有0.82。
可以看到每一层的详细信息、连接关系及输出的形式,方便调试。 
初始化后开始训练: 
在solver的设置中,每100次迭代会输出一次训练损失,测试是500次迭代输出一次: 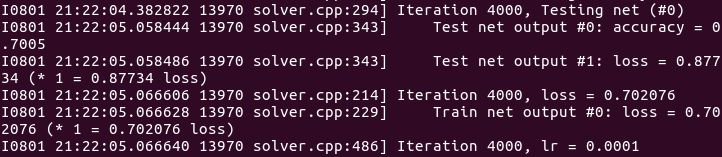
训练阶段,lr是学习率,loss是训练函数。测试阶段,score 0是准确率,score 1是损失函数。最后的结果: 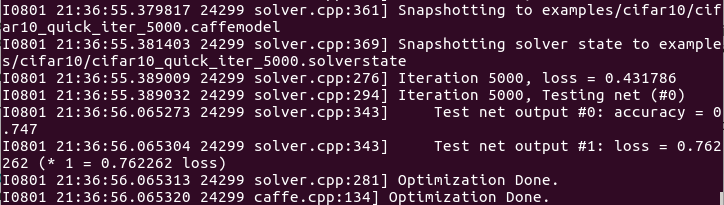
测试准确率大约有0.75,模型参数存储在二进制protobuf格式的文件cifar10_quick_iter_5000中。
————————————————————————————————————
参考文献:
2、官网链接:http://caffe.berkeleyvision.org/gathered/examples/cifar10.html

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)