Hadoop完全分布式集群安装及配置(基于虚拟机)
写在前面因为之前Hadoop伪分布式的安装(参见:Hadoop安装以及伪分布模式搭建过程)是在VirtualBox上安装了Ubuntu虚拟机,所以这次在开始的时候也是在VirtualBox上安装了3个Ubuntu虚拟机,但是3个虚拟机打开之后发现3者的IP地址是一样的(通过ifconfig命令查看IP地址),我尝试着通过设置静态IP、更改网络模式等方法都没有成功,不能够做到3个虚拟机之间互联。所以
Hadoop入门配置系列博客目录一览
1、Eclipse中使用Hadoop伪分布模式开发配置及简单程序示例(Linux下)
2、使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)
3、Hadoop完全分布式集群安装及配置(基于虚拟机)
4、Eclipse中使用Hadoop集群模式开发配置及简单程序示例(Windows下)
5、Zookeeper3.4.9、Hbase1.3.1、Pig0.16.0安装及配置(基于Hadoop2.7.3集群)
6、mysql5.7.18安装、Hive2.1.1安装和配置(基于Hadoop2.7.3集群)
7、Sqoop-1.4.6安装配置及Mysql->HDFS->Hive数据导入(基于Hadoop2.7.3)
8、Hadoop完全分布式在实际中优化方案
9、Hive:使用beeline连接和在eclispe中连接
10、Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)
11、Win下使用Eclipse开发scala程序配置(基于Hadoop2.7.3集群)
12、win下Eclipse远程连接Hbase的配置及程序示例(create、insert、get、delete)
本篇博客主要介绍“Hadoop完全分布式集群安装及配置(基于虚拟机)”。
写在前面
因为之前Hadoop伪分布式的安装(参见:[Hadoop安装以及伪分布模式搭建过程](http://blog.csdn.net/quiet_girl/article/details/70175831) )是在VirtualBox上安装了Ubuntu虚拟机,所以这次在开始的时候也是在VirtualBox上安装了3个Ubuntu虚拟机,但是3个虚拟机打开之后发现3者的IP地址是一样的(通过ifconfig命令查看IP地址),我尝试着通过设置静态IP、更改网络模式等方法都没有成功,不能够做到3个虚拟机之间互联。所以这里使用的是VMware。VMware版本: VMware-workstation-full-12.5.7.20721.exe,秘钥:5A02H-AU243-TZJ49-GTC7K-3C61N(来自:https://zhidao.baidu.com/question/1240914582586009779.html)
Ubuntu镜像版本: ubuntu-16.04.2-server-amd64.iso
JDK版本: jdk-8u131-linux-x64.tar.gz
Hadoop版本: hadoop-2.8.0.tar.gz
一、ubuntu安装
下载地址: http://releases.ubuntu.com/?_ga=2.148742000.695831999.1499166942-66111771.1499166942
安装教程: http://jingyan.baidu.com/article/c275f6ba07e269e33d756714.html(写的很好),注意,最后有可能需要更改BIOS设置,链接文末都说明。
如果3个都使用桌面版,电脑估计会卡死,所以这里使用了server版本的,在使用上述方法安装完一个ubuntu虚拟机之后,对于其余2个ubuntu不需要像第一个一样一步一步安装,为了节省精力,可以直接使用VMware的克隆技术。
1、克隆具体操作如下:
(1)务必将之前安装的系统完全关闭,可以使用命令行shutdown -P now.
(2)这里以hadoop_s2的克隆为例,hadoop_s2系统名称右击 --> 管理 --> 克隆 --> 下一步 --> 克隆源选择“虚拟机中的当前状态”–> 下一步 --> 克隆类型选择“创建完整克隆”–> 下一步 --> 填写克隆之后的虚拟机名称即位置 --> 完成即可。
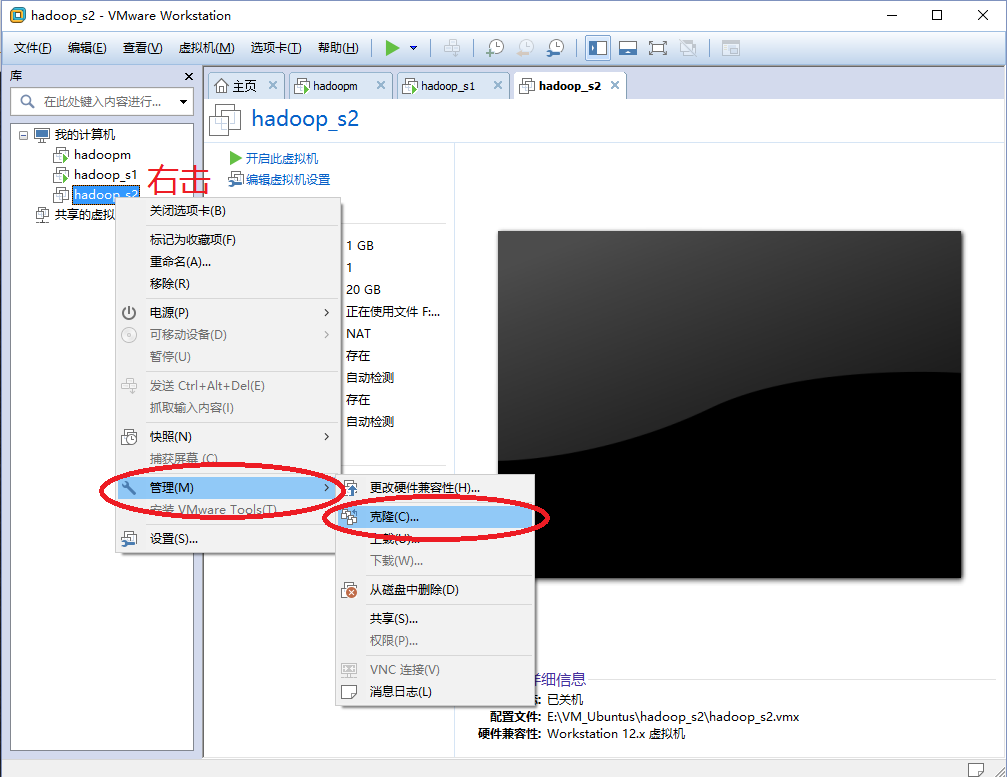
2、ubuntu系统名称:
hadoopm(作为master节点),hadoop_s1和hadoop_s2(作为2个slaver节点)。
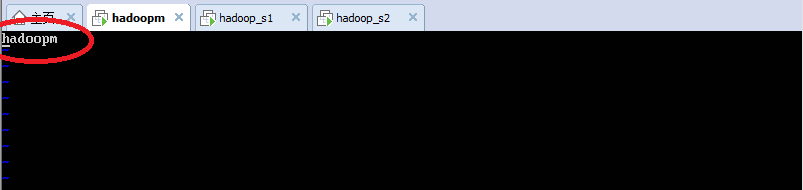
在克隆之后,我们需要将linux的主机重命名,分别修改3个主机的hostname文件,命令:
vi /etc/hostname
以hadoopm为例,hostname文件如图:
二、3个虚拟机之间网络互通配置
我们需要使3个虚拟机之间能够网络互通,正常情况下3个虚拟机的IP在同一个网段上且可以互连。但是通过其hostname不能够互联,所以这一步的配置主要使其通过主机名也能够互联。1、本次hadoopm、hadoop_s1和hadoop_s2的IP如下:
| hostname | IP |
|---|---|
| hadoopm | 192.168.163.128 |
| hadoop_s1 | 192.168.163.129 |
| hadoop_s2 | 192.168.163.130 |
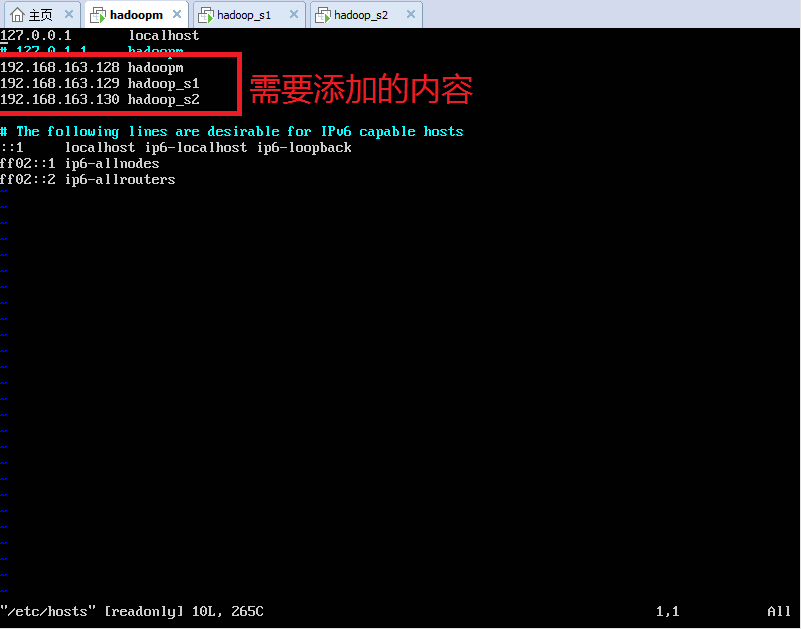
2、配置3个虚拟机的/etc/hosts文件,配置如下:
3、验证3个虚拟机之间是否可以互联
以下命令分别在3个虚拟机上验证:
ping 192.168.163.128 //检测是否可以ping通自己的IP
ping hadoopm //检测是否可以ping通自己的hostname
ping 192.168.163.129 //检测是否可以ping通hadoop_s1的IP
ping hadoop_s1 //检测是否可以ping通hadoop_s1的hostname
ping 192.168.163.130 //检测是否可以ping通hadoop_s2的IP
ping hadoop_s2 //检测是否可以ping通hadoop_s2的hostname
若可以ping通,则进行以下配置。
若使用的是虚拟机,发现network is unreachable的错误,可以尝试将windows中所有VMware的服务都开启,看是否可以解决(网络模式是NAT)
三、ssh免密码登录
1、对3个虚拟机分别使用下列命令产生公私密钥:
sudo apt-get install ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
使用命令ssh localhost进行测试,若无需输入密码,则单机ssh免密码登录成功。
2、让主节点(hadoopm)免密码登陆两个子节点(hadoop_s1和hadoop_s2)
(1)对hadoop_s1使用下面的命令,进入hadoop_s1的~/.ssh目录下:
scp hadoopm:~/.ssh/id_rsa.pub ./hadoopm_rsa.pub //复制hadoopm的公钥
cat hadoopm_rsa.pub >> authorized_keys //将hadoopm的公钥追加到hadoop_s1的authorized_keys文件中
通过在hadoopm的~/.ssh目录下执行ssh hadoop_s1验证是否可以免密码登录,若第一次需要需要yes,但是exit退出hadoop_s1之后再次执行ssh hadoop_s1可以免密码登录,则配置成功。注意观察主机名,当登录进去之后主机名便改变了。
(2)对hadoop_s2使用下面的命令,进入hadoop_s2的~/.ssh目录下:
scp hadoopm:~/.ssh/id_rsa.pub ./hadoopm_rsa.pub //复制hadoopm的公钥
cat hadoopm_rsa.pub >> authorized_keys //将hadoopm的公钥追加到hadoop_s2的authorized_keys文件中
通过在hadoopm的~/.ssh目录下执行ssh hadoop_s2验证是否可以免密码登录,若第一次需要需要yes,但是exit退出hadoop_s2之后再次执行ssh hadoop_s2可以免密码登录,则配置成功。
四、安装JDK
下载地址: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,如图:
安装方法:Linux(Ubuntu)下如何安装JDK
注意:3个虚拟机都需要安装JDK,我这里3个虚拟机上安装的jdk目录都为:/opt/Applications/Java/jdk1.8
五、安装Hadoop
下载及安装、设置JAVA_HOME环境变量、设置Hadoop安装目录(即HADOOP_INSTALL)的环境变量参见:Hadoop安装以及伪分布模式搭建过程 的《三、安装Hadoop》
注意:3个虚拟机都需要安装Hadoop、设置JAVA_HOME、设置Hadoop安装目录,我这里3个虚拟机上安装的jdk目录都为:/opt/Applications/Hadoop/hadoop-2.8.0
六、配置Hadoop
注意:完全分布式的Hadoop配置内容和伪分布式不同!! 利用hadoop搭建伪分布式环境需要配置4个xml文件,这4个xml文件都在/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop文件夹中。 先在hadoopm上配置,再通过scp命令复制到hadoop\_s1和hadoop\_s2中。(1)修改hadoop-env.sh配置文件
| 配置hadoop-env.sh过程 |
|---|
S1:打开hadoop-env.sh文件,将当前位置切换了/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo vi hadoop-env.sh,命令执行后hadoop-env.sh文件被打开。 |
S2:在hadoop-env.sh文件中修改JAVA_HOME环境变量,将export JAVA_HOME=${JAVA_HOME}(虽然之前的代码也能获取到JAVA_HOME的值,但是有时候会失效)修改为export JAVA_HOME=/opt/Applications/Java/jdk1.8 |
(2)修改core-site.xml配置文件
| 配置core-site.xml过程 |
|---|
S1:打开core-site.xml文件,将当前位置切换了/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo vi core-site.xml,命令执行后core-site.xml文件被打开。 |
| S2:在core-site.xml文件末尾添加上如下代码: |
代码如下(<'configuration'>和<'/configuration'>标签原来就有):
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/Applications/Hadoop/hadoop-2.8.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoopm:9000</value>
<final>true</final>
</property>
</configuration>
注意: hadoop.tmp.dir文件不是一个临时文件,是存放所有hadoop中数据的文件,其目录地址为:/opt/Applications/Hadoop/hadoop-2.8.0/tmp。
(3)修改hdfs-site.xml配置文件
| 配置hdfs-site.xml过程 |
|---|
S1:打开hdfs-site.xml文件,将当前位置切换了/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo vi hdfs-site.xml,命令执行后hdfs-site.xml文件被打开。 |
| S2:在hdfs-site.xml文件末尾添加上如下代码: |
代码如下(<'configuration'>和<'/configuration'>标签原来就有):
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
</property>
</configuration>
注意:2是指备份2份(总共2份)。在hadoop中默认有3份文件(含备份),这里总共想要存放2份文件,则改为2。
(4)修改mapred-site.xml配置文件
| 配置mapred-site.xml过程 |
|---|
| S1: (1)打开mapred-site.xml文件(你会发现在/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop没有mapred-site.xml文件,只有一个mapred-site.xml.template文件。这是因为mapreduce比较特殊,它可以配置也可以不配置,而其他例如core-site.xml存在因为其必须配置。 (2)这里只需要将mapred-site.xml.template复制一下,并且将文件名改为mapred-site.xml进行修改即可,直接在/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop下使用 sudo cp mapred-site.xml.template mapred-site.xml即可)。(3)将当前位置切换了/opt/Application/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令 sudo vi mapred-site.xml,命令执行后mapred-site.xml文件被打开。 |
| S2:在mapred-site.xml文件末尾添加上如下代码: |
代码如下(`<'configuration'>`和`<'/configuration'>`标签原来就有):
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.163.128:9001</value>
</property>
</configuration>
这里192.168.163.128是hadoopm的IP地址。
(5)修改yarn-site.xml配置文件
| 配置yarn-site.xml过程 |
|---|
S1:打开yarn-site.xml文件,将当前位置切换了/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo vi yarn-site.xml,命令执行后yarn-site.xml文件被打开。 |
| S2:在yarn-site.xml文件末尾添加上如下代码: |
代码如下(`<'configuration'>`和 `<'/configuration'>` 标签原来就有):
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopm</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)配置masters和slaves文件
切换至/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop,使用ls查看文件,发现只有slaves,这里使用sudo cp slaves masters 命令复制一下。
(1)配置的masters文件如下:


(7)向2个子节点复制hadoop配置
| 操作 | 命令 |
|---|---|
| 向hadoop_s1中复制hadoop配置 | 在hadoopm的/home/lina(根目录)下使用下面的命令:scp -r /opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop hadoop_s1:/opt/Applications/Hadoop/hadoop-2.8.0/etc |
| 向hadoop_s2中复制hadoop配置 | 在hadoopm的/home/lina(根目录)下使用下面的命令:scp -r /opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop hadoop_s2:/opt/Applications/Hadoop/hadoop-2.8.0/etc |
其中,/opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop是hadoopm的配置文件hadoop配置文件目录,相当于复制配置文件夹,/opt/Applications/Hadoop/hadoop-2.8.0/etc是hadoop_s1(hadoop_s2)中需要将hadoopm配置文件复制到的地方,即这里需要用hadoopm的hadoop配置文件夹替换为hadoop_s1(hadoop_s2)的hadoop配置文件夹。
七、格式化HDFS文件
在hadoopm上格式化HDFS文件,使用cd命令将当前位置切换到/opt/Applications/Hadoop/hadoop-2.8.0/bin目录下(bin目录下面有一个hdfs),执行命令:./hdfs namenode -format
出现"Storage directory /opt/Applications/Hadoop/hadoop-2.8.0/etc/hadoop/name has been successfully formatted"说明格式化成功。
八、启动进程检测配置是否正确
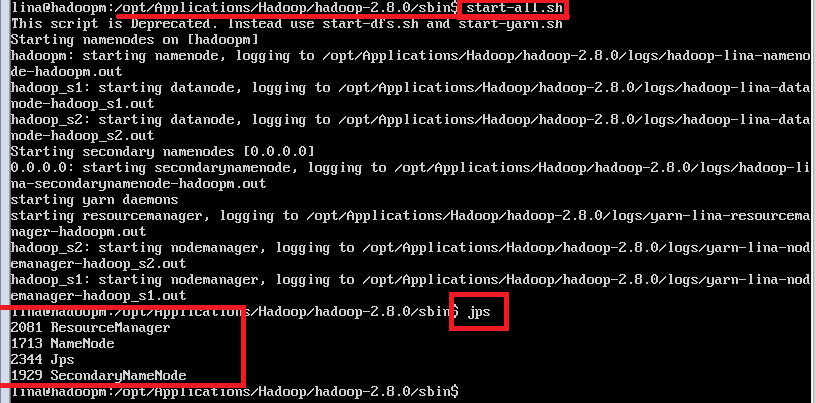
1、在 主节点hadoopm上操作: 进入/opt/Applications/Hadoop/hadoop-2.8.0/sbin目录,执行下列命令:start-all.sh
使用jps命令验证,若启动成功,则会出现下图:


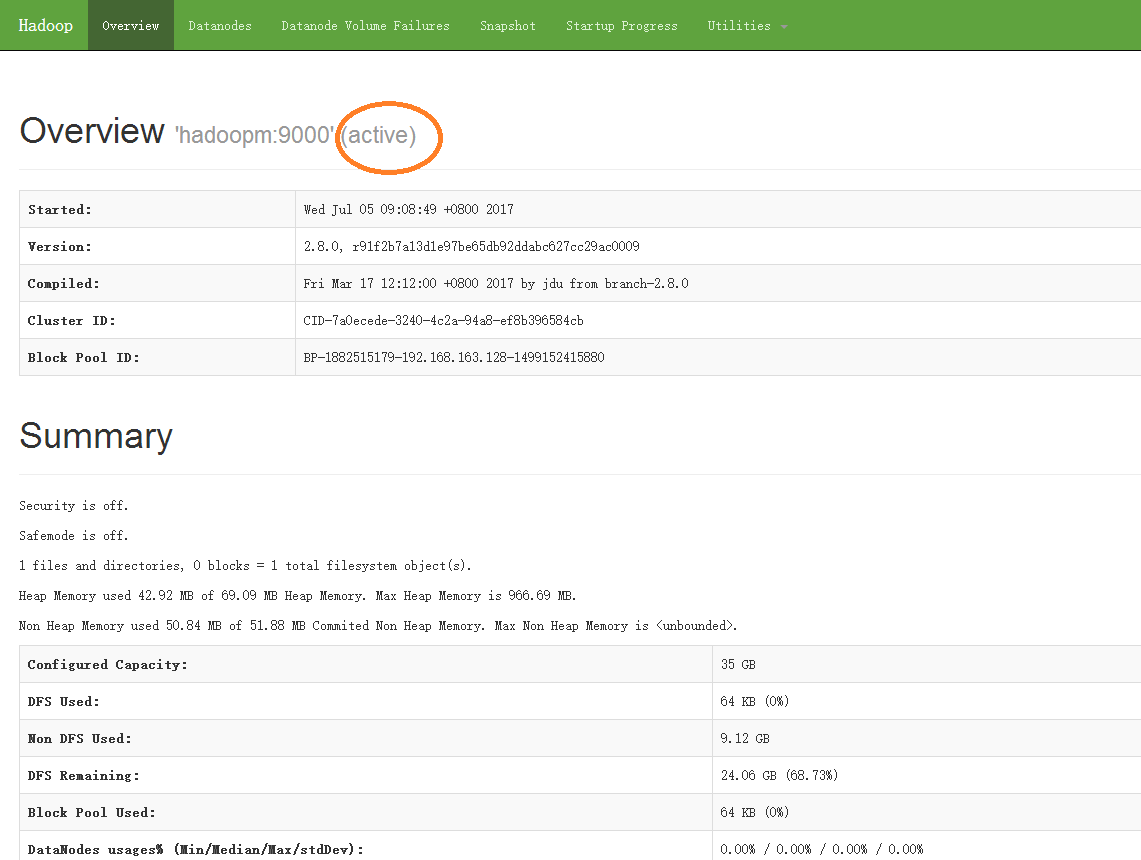
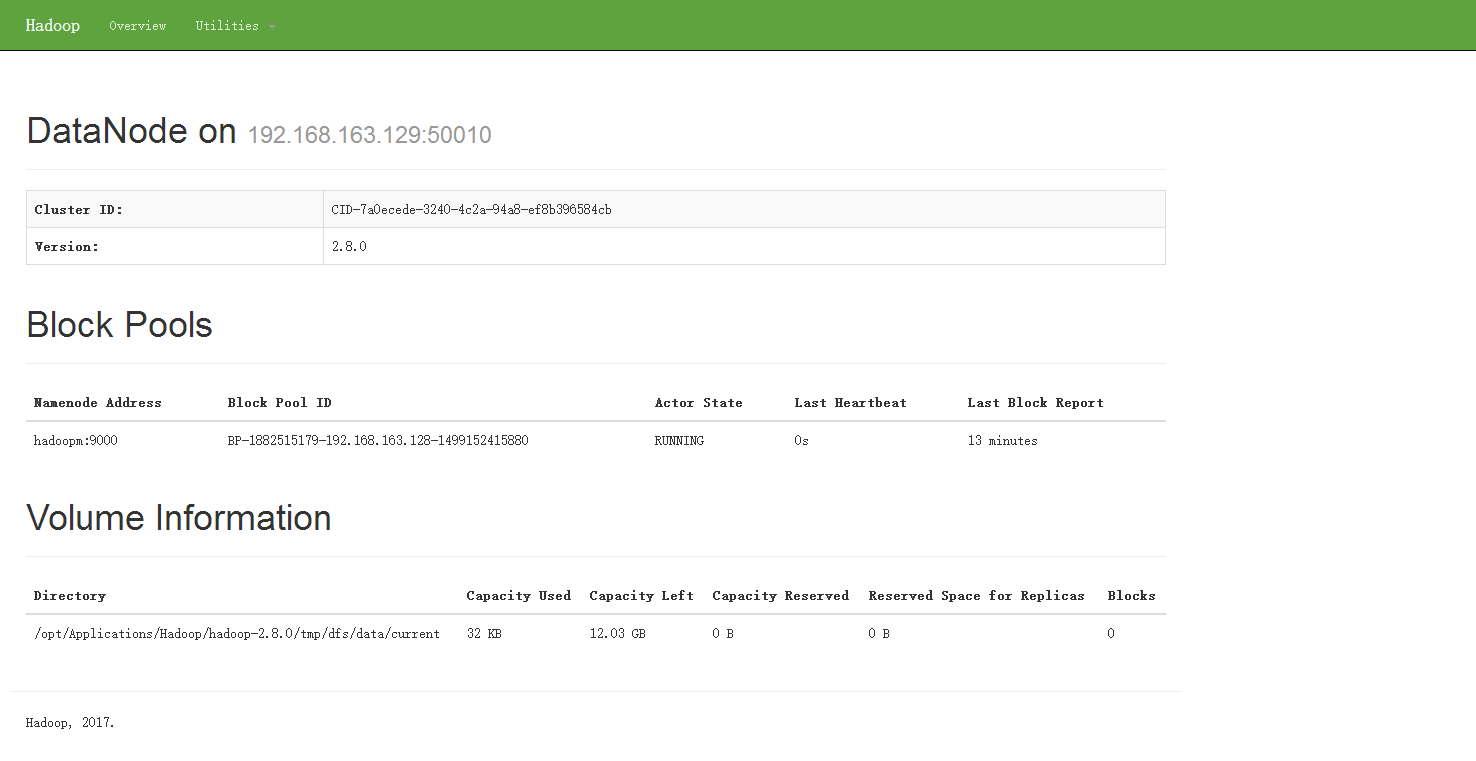
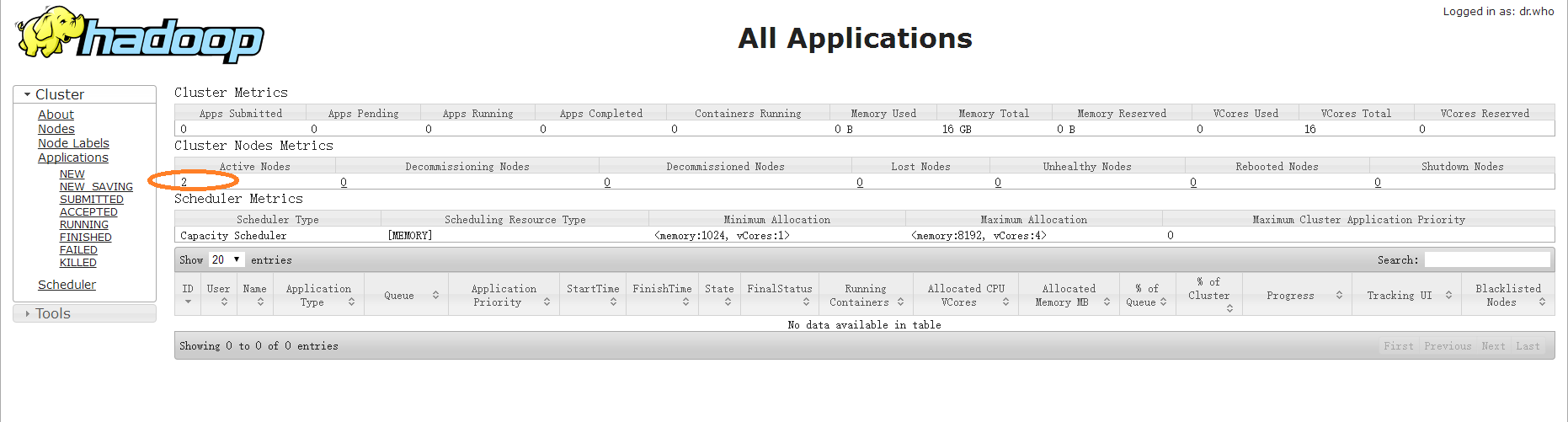

至此,Hadoop基于虚拟机的完全分布式集群配置完毕。
参考文章:[hadoop学习之hadoop完全分布式集群安装](http://blog.csdn.net/ab198604/article/details/8250461)

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)