Spring Cloud —— 链路追踪技术
导航一、什么是链路追踪二、Spring Cloud Sleuth2.1 相关概念三、Sleuth 入门案例四、Zipkin 的集成4.1 Zipkin 介绍4.2 Zipkin 服务端安装4.3 Zipkin 客户端安装五、Zipkin 数据持久化5.1 MySQL 数据持久化5.2 Elasticsearch 数据持久化一、什么是链路追踪在大型系统的微服务化构建中,一个系统被拆分成了许多模块。这
导航
一、什么是链路追踪
在大型系统的微服务化构建中,一个系统被拆分成了许多模块。这些模块负责不同的功能,组合成系统,最终可以提供丰富的功能。
在这种架构中,一次请求往往需要涉及到多个服务。这些服务模块,可能由不同的团队开发、不同的编程语言实现、部署在了几千台服务器横跨多个不同的数据中心。这样的系统会存在一些问题:
1、如何快速发现问题?
2、如何判断故障影响范围?
3、如何梳理服务依赖以及依赖的合理性?
4、如何分析链路性能以及实时容量规划?
有些系统通过打日志来进行埋点,然后再通过elk进行定位及分析问题,更有甚者直接远程服务器,使用各种linux命令单手操作查看日志,随着业务越来越复杂,这种方式低效且吃力,不能更好的管控整体系统。
全链路性能监控从整体维度到局部维度展示各项指标,将跨应用的所有调用链性能信息集中展现,可方便度量整体和局部性能,并且方便找到故障产生的源头,生产上可极大缩短故障排除时间。同时,一个优秀的链路追踪技术组件还具有更丰富好用的特性,如:
1、请求链路追踪,故障快速定位(基本特性)。
2、可视化,各个阶段的耗时,方便性能分析。
3、依赖优化。
4、数据分析,优化链路。可以得到用户的行为路径,汇总分析应用在很多业务场景。
二、Spring Cloud Sleuth
Spring Cloud Sleuth 是 Spring 团队提供的链路追踪技术,大量借用了 Google Dapper 的设计。
官方文档(英文):Spring Cloud Sleuth Reference Documentation
2.1 相关概念
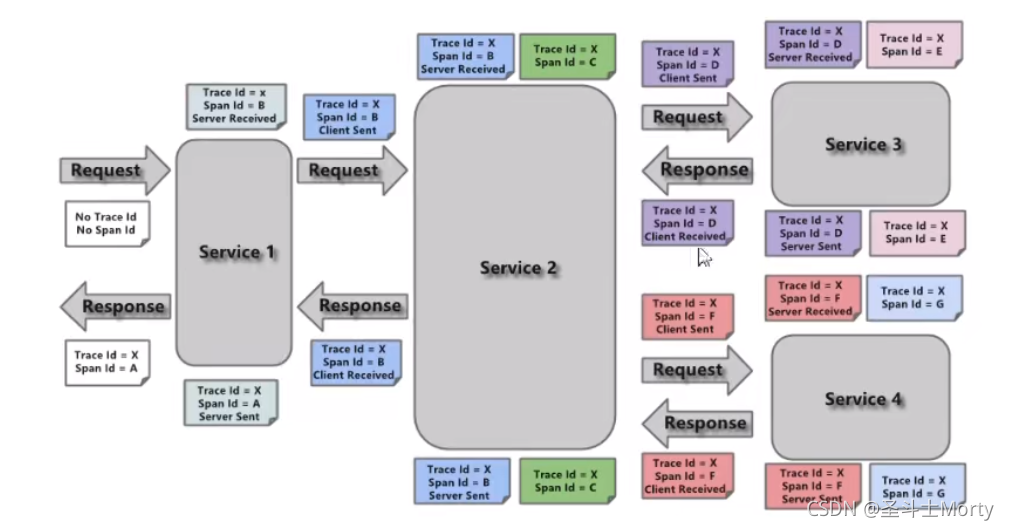
- Trace
由一组 Trace Id 相同的 Span 串连形成的树状结构。当请求到达分布式系统的入口时,链路追踪框架会为其创建一个唯一的标识,即 Trace Id。当请求在分布式系统内部流转时,框架始终传递 Trace Id,直到整个请求返回。我们可以使用使用 Trace Id 将请求串联起来,形成一条完整的请求链路。 - Span
代表一组基本的工作单元。用于统计各处理单元的延迟,当请求到达各个服务的时候,也会生成一个 Span Id,来标记开始、过程、结束。通过 Span Id 的开始、结束时间戳,就能统计 Span 的调用时间。另外,还可以获取如事件名称、请求信息等元数据。 - Annotation
用于记录一段时间内的事件。内部使用的重要注释:
cs(Client Send):客户端发出请求,开始一个请求的声明
sr(Server Received):服务端接收到请求开始进行处理,sr - cs = 网络延迟(服务调用的时间)
ss(Server Send):服务端处理完毕准备发送到客户端,ss - sr = 请求处理的时间
cr(Client Received):客户端接收到服务端的响应,请求结束。cr - sr = 请求的总时间
三、Sleuth 入门案例
只需在父 pom 中加入 sleuth 依赖就可以完成对 sleuth 的集成:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
</dependencies>
注意,这里的版本已经跟随 Spring Cloud 的大版本,因此不需要显式指定,Spring Cloud 的版本是:
<!-- 版本锁定-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.SR5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.1.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
我们通过 api gateway --> order --> product 的链路来检验 sleuth 的效果:
启动 shop-api-gateway、shop-order、shop-product 三个微服务,并将它们都注册到 Nacos 上: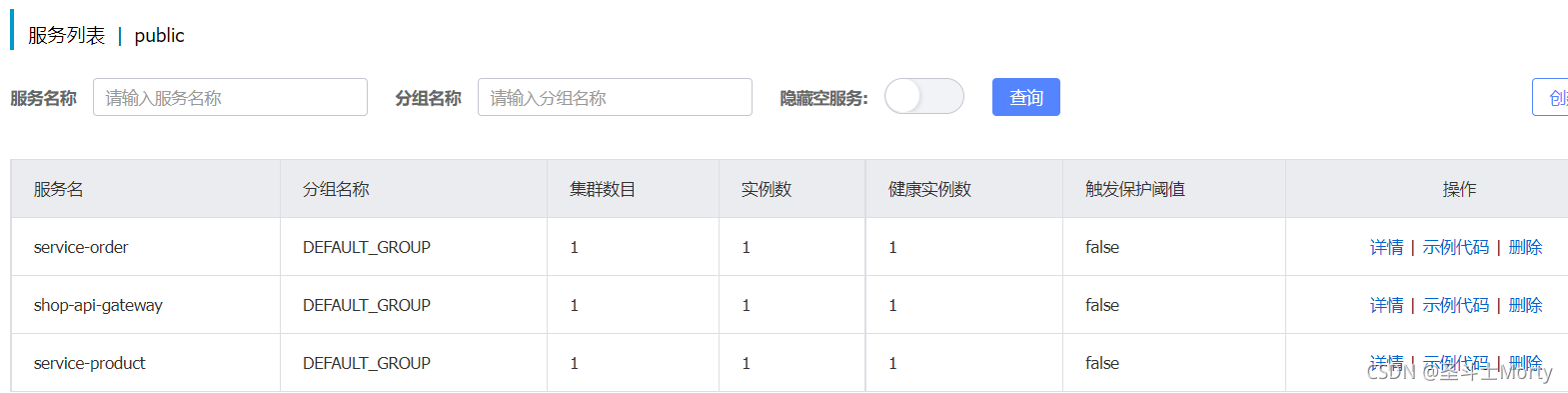
请求网关入口的订单接口,观察三个微服务的后台日志:
可以看到日志中多出了一些类似 hash 码的字符串:
[shop-api-gateway,b6c94df98edb6d99,b6c94df98edb6d99,false]
[service-order,b6c94df98edb6d99,98da32ed6abd6192,false]
[service-product,b6c94df98edb6d99,81d51b3d2b42423f,false]
这就是 sleuth 在未进行任何配置的情况下生成的链路追踪信息。它的格式是:
服务名称,traceId,spanId,是否接入外部可视化工具
四、Zipkin 的集成
4.1 Zipkin 介绍
Zipkin 是 Twitter 的一个开源项目,是一个分布式跟踪系统,基于 Google Dapper 实现。它有助于收集故障诊断服务体系结构中的延迟问题所需的时间数据。特性包括收集和查找这些数据。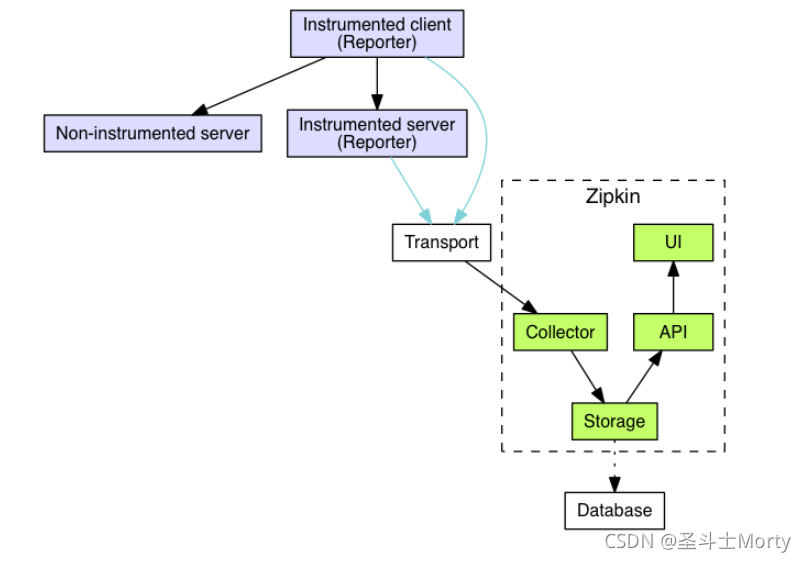
Zipkin 分为两端,一个是服务端(有单独的启动程序),一个是客户端,客户端以maven依赖的形式集成在各个微服务中。
4.2 Zipkin 服务端安装
1、下载Zipkin jar包
在 maven 仓库就可以找到,直接搜索 zipkin server :https://mvnrepository.com/artifact/io.zipkin.java/zipkin-server
2、启动 jar 程序
将下载好的 zipkin-server-2.12.9-exec.jar 包启动,java -jar zipkin-server-2.12.9-exec.jar,并访问 9411 端口。
4.3 Zipkin 客户端安装
1、在父 pom 中加入以下依赖即可:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2、在各个微服务中加入以下配置信息
因为需要各个微服务向 Zipkin 服务端推送数据,因此需要配置 zipkin 服务端地址:
spring:
zipkin:
base-url: http://localhost:9411/ # zipkin server 的请求地址
discovery-client-enabled: false # 让 Nacos 把它当成一个 url ,而不要当成服务名
sleuth:
sampler:
probability: 1.0 # 采样百分比
3、测试
正常访问下单接口,并观察 Zipkin server 的页面展示。
五、Zipkin 数据持久化
zipkin server 默认会将追踪数据保存在内存中,如果想进行持久化,zipkin 支持 mysql 或 Elasticsearch 等多种持久化方式。
5.1 MySQL 数据持久化
5.2 Elasticsearch 数据持久化

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)