Flink学习13:Flink外接kafka数据源
borker即是kafka集群的每台机器Topic是一类数据的集合。
 1.flink外部数据源(kafka)简介
1.flink外部数据源(kafka)简介
kafka的broker
borker即是kafka集群的每台机器Topic是一类数据的集合
Partition
是Topic数据的物理分区
Producer
负责生成数据到kafka的broker中
consumer
consumer Group
为consumer指定对应的consumer Group
2.kafka的安装
下载kafka
kafka_2.12-3.2.0kafkakakakakakakakakakakakaka-Java文档类资源-CSDN下载
下载完成后直接解压
tar -zxvf kafka_2.12-3.2.0.tgz
修改kafka配置文件
vi /opt/kafka/config/server.properties
增加3个配置
listeners=PLAINTEXT://10.31.126.100:9092
advertised.listeners=PLAINTEXT://10.31.126.100:9092
zookeeper.connect=10.31.126.100:2181
启动kafka
1.先启动zookeeper服务
cd /opt/kafka
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
开启以后,不要关闭当前窗口,不然的话zookeeper服务会中断
ps: 如果报错:/opt/kafka/bin/kafka-run-class.sh: line 342: /opt/kafka/echo/bin/java: No such file or directory
可以看下 echo $JAVA_HOME 是不是路径打印不出。
解决方案: 执行 source /etc/profile ,再打印下 echo $JAVA_HOME,看下是否正常。
2.开启kafka服务
cd /opt/kafka
./bin/kafka-server-start.sh ./config/server.properties
开启以后,不要关闭当前窗口,不然的话kafka服务会中断
3.测试kafka
bin/kafka-topics.sh --create --bootstrap-server 10.31.126.10:9092 --replication-factor 1 --partitions 1 --topic wordTest
ps:在较新版本(2.2 及更高版本)的 Kafka 不再需要 ZooKeeper 连接字符串,即- -zookeeper localhost:2181。使用 Kafka Broker的 --bootstrap-server localhost:9092来替代- -zookeeper localhost:2181。
2.2一下版本:./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication 1 --partitions 1 --topic wordsendertest
来启动
查看topic列表
bin/kafka-topics.sh --bootstrap-server 10.31.126.10:9092 --list
查看对应Topic描述:
bin/kafka-topics.sh --describe --bootstrap-server 10.31.126.10:9092 --topic wordTest
删除topic
bin/kafka-topics.sh -delete --bootstrap-server 10.31.126.10:9092 --topic wordTest
可以开启多个生产者客户端发送消息,开启多个消费者客户端接收消息,以观察这种订阅-发布模式实现的消息队列。
生产者客户端:
bin/kafka-console-producer.sh --bootstrap-server 10.31.126.10:9092 --topic wordTest
打开消费者客户端:
从当前时间点,开始取数据
bin/kafka-console-consumer.sh --bootstrap-server 10.31.126.10:9092 --topic wordTest
从最开始的时间点,开始取数据,(取该topic所有的数据)
bin/kafka-console-consumer.sh --bootstrap-server 10.31.126.10:9092 --topic wordTest --from-beginning
关闭kafka
bin/kafka-server-stop.sh
开启生产者和消费者
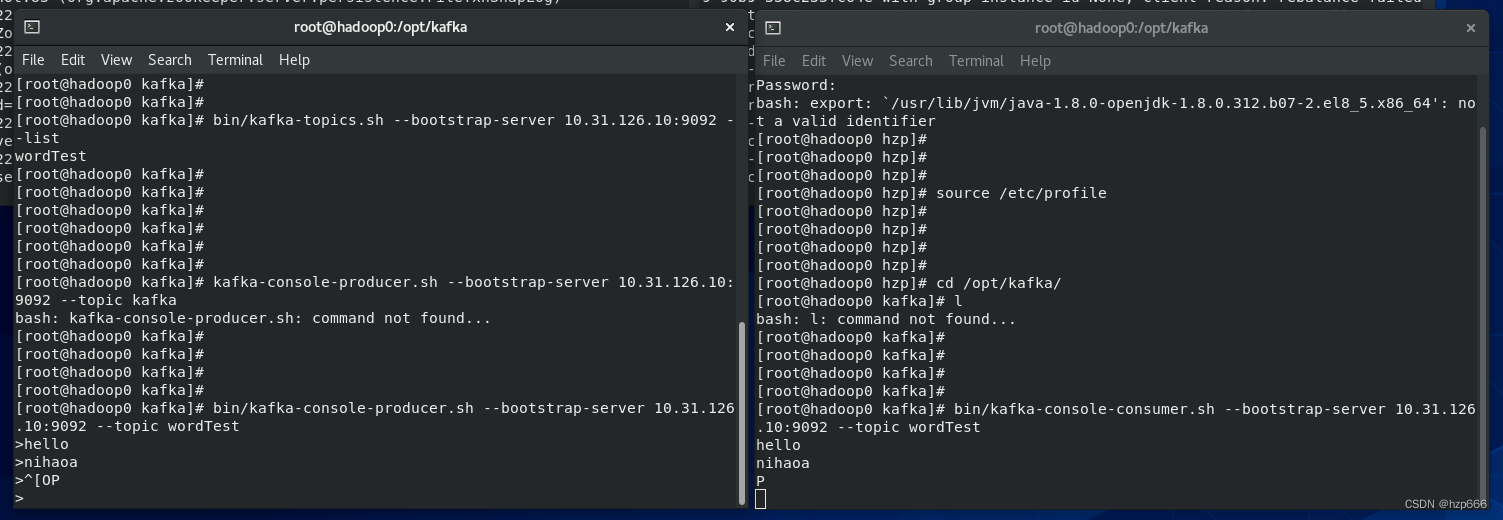
3.kafka数据源,flink程序
编写flink程序,消费kafka数据
核心的生成kafka数据源方法介绍:
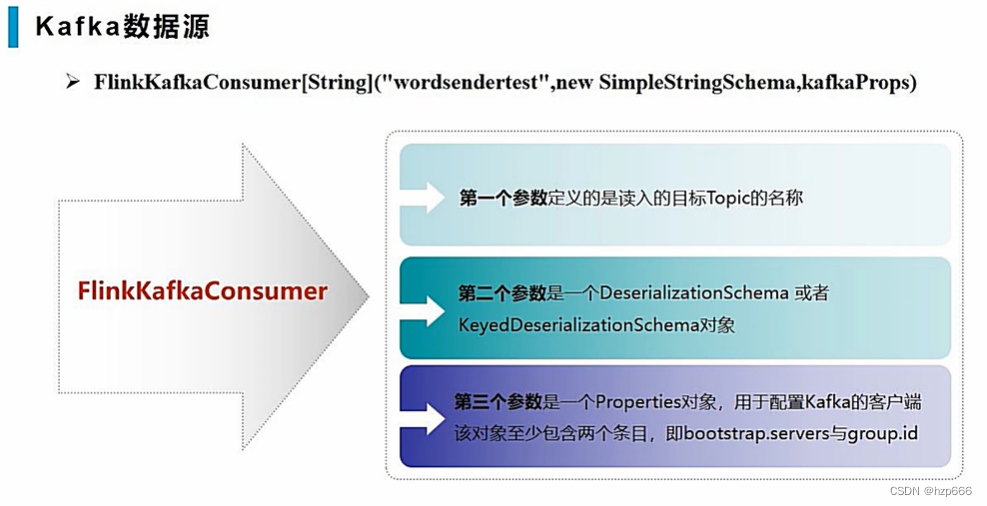
其中SimpleStringSchema,是因为kafka是纯字节存储,所以需要在代码中进行反序列化成对象,让Scala可以解析。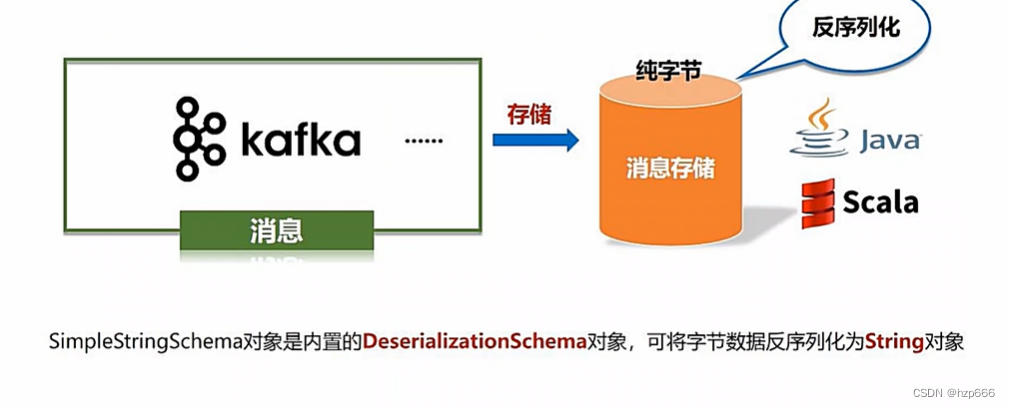
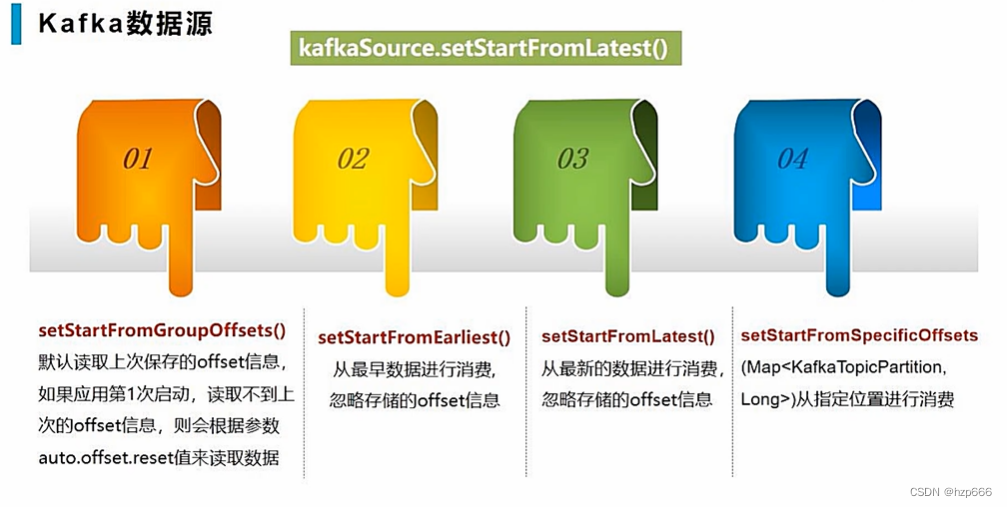
设置offset的几种方式
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaConsumerBase}
import java.util.Properties
object kafkaTest {
def main(args: Array[String]): Unit = {
//create the env
val env = StreamExecutionEnvironment.getExecutionEnvironment
//for kafka connection
val kafkaProps = new Properties()
//kafka's attribute
kafkaProps.setProperty("bootstrap.servers","10.31.126.10:9092")
//set the consumer's group
//kafkaProps.setProperty("group.id","group1")
//create the consumer
val kafkaSource = new FlinkKafkaConsumer[String]("wordTest", new SimpleStringSchema, kafkaProps)
//set offset
kafkaSource.setStartFromEarliest()
//auto commit offset
kafkaSource.setCommitOffsetsOnCheckpoints(true)
//band data source
val stream = env.addSource(kafkaSource)
stream.print()
//execute
env.execute()
}
}
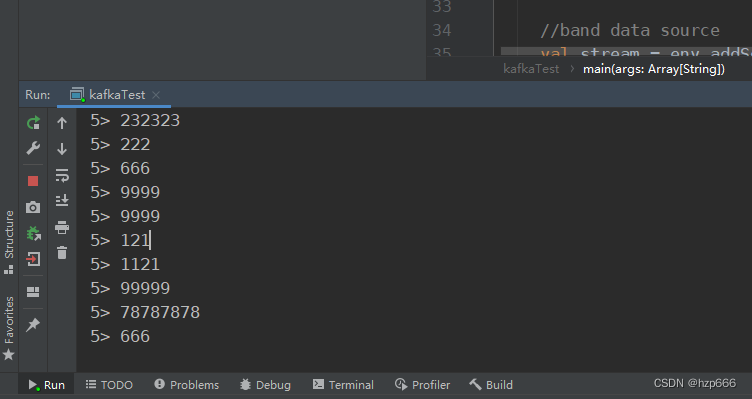
输出效果:


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)