Hadoop环境配置(Linux虚拟机)
Hadoop环境配置(Linux虚拟机)本学期选了大数据管理与分析这门课,主要使用Hadoop框架下进行数据分析与应用开发,在此先进行环境配置注意最好把JDK以及Hadoop 放在/usr/local下添加环境变量的时候 可以加到/etc/profile或者 按照该链接 w3cshcool的教材进行配置(强烈推荐)环境要求单机Hadoop的安装安装JDK链接https://www.oracle.c
Hadoop环境配置(Linux虚拟机)
本学期选了大数据管理与分析这门课,主要使用Hadoop框架下进行数据分析与应用开发,在此先进行环境配置
注意
-
最好把JDK以及Hadoop 放在/usr/local下
-
添加环境变量的时候 可以加到/etc/profile
或者 按照该链接 w3cshcool的教材进行配置(强烈推荐)
环境要求

单机Hadoop的安装
安装JDK
链接
https://www.oracle.com/java/technologies/javase-java-archive-javase6-downloads.html
然后
sudo nautilus
会打开一个有权限的文件夹
推荐下载 .bin文件 而非 rpm.bin
然后安装
./jdk-6u23-linux-x64.bin
配置JDK
用vim或vi 打开/etc/profile 文件
vim /etc/profile
点击键盘 i 进行编辑;
将下面内容粘贴到末尾;
export JAVA_HOME=/home/java/jdk1.6.0_23
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
然后esc
然后输入
:w
:q
保存退出 然后输入
source /etc/profile
最后验证
java -version

下载安装Hadoop
网址:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz

下载并解压

然后测试是否可用
./bin/hadoop version # 查看hadoop版本信息

经过俩小时的DeBug 终于可以了
-
换了JDK版本 为jdk1.8.0_171
-
然后 记住改完 /etc/profile 之后 一定要 source /etc/profile
两种角色下都要source 然后就行了~
-
别忘了修改这个.sh文件


然后就能够Hadoop 正常显示版本号了
配置SSH
为了保证远程管理Hadoop节点以及Hadoop 节点之间用户共享访问时的安全性,需要配置SSH(安全外壳协议)。
在单机模式下无需守护进程,因此不需要进行SSH设置。但是在单机伪分布或者集群分布下需要进行SSH设置
所以暂时先跳
配置Hadoop环境
-
就是改java_home那个 上文已经说了
-
Hadoop的配置文件时conf/core-site.xml cof/hdfs-site.xml 以及 conf/mapred-site.xml
其中core-site.xml时全局配置文件,后面分别是HDFS的配置文件以及MapReduce的配置文件。
-
需要修改core-site.xml 以及 hdfs-site.xml
core-site代码如下
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/root/hadoop-2.10.0/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>hdfs-site 如下
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/root/hadoop-2.10.0/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/root/hadoop-2.10.0/tmp/dfs/data</value> </property> </configuration>效果如下 自行修改 file 即 hadoop-2.10.0的文件地址 其他不需要改

Hadoop的运行
-
初始化节点
./bin/hdfs namenode -format -
如果出现,即说明成功,否则可能原因见地址

-
继续输入 ./sbin/start-dfs.sh
-
发现要你输入密码(貌似不行,但是不知道为啥)

-
所以需要进行SSH配置
sudo apt-get update #第一步 sudo apt-get install ssh #第二步 sudo apt-get install pdsh #第三 -
生成密钥对
ssh-keygen -t rsa # 然后一路enter # 就会按照默认保存在.ssh/id_rsa文件中

-
# 先进入.ssh 目录 然后 cp id_rsa.pub authorized_keys # 再继续 ssh localhost结果

最后
分别
start-dfs.sh
start-yarn.sh
即可完成验证、登录
然后
# 访问Hadoop的默认端口号为50070.使用以下URL在浏览器上获取Hadoop服务。
http://localhost:50070/
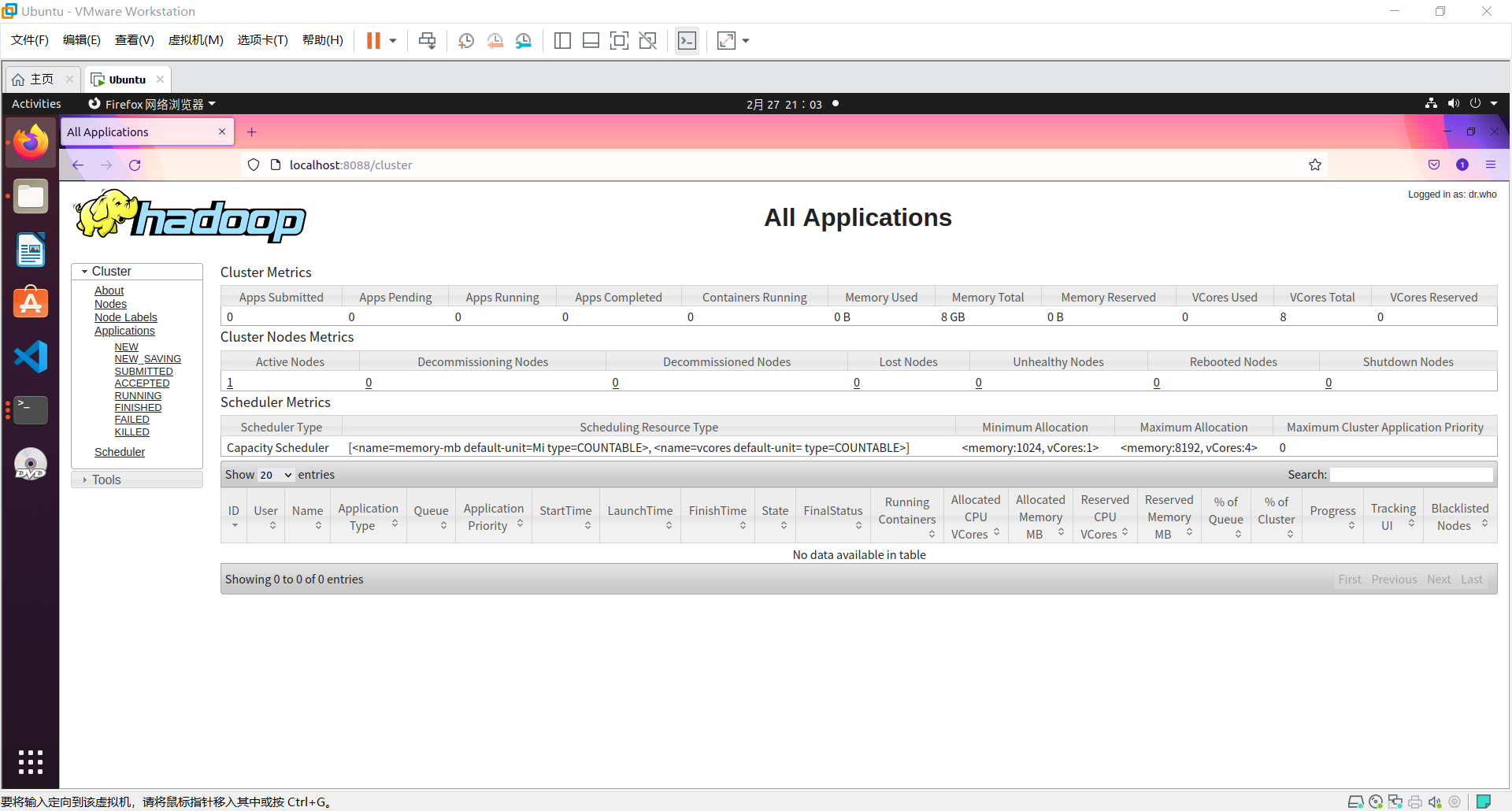
# 访问群集的所有应用程序的默认端口号为8088.使用以下URL访问此服务。
http://localhost:8088/

部分问题
-

这种是说明启动Hadoop的时候已有Hadoop节点在运行,所以在启动之前你需要 在重新启动hadoop之前要先stop掉所有的hadoop服务。 然后恢复正常启动。
启动Hadoop的时候已有Hadoop节点在运行,所以在启动之前你需要 在重新启动hadoop之前要先stop掉所有的hadoop服务。 然后恢复正常启动。
解决
stop-all.sh

然后重启
注意这里输入
./sbin/start-all.sh -
https://www.w3cschool.cn/hadoop/hadoop_enviornment_setup.html
最后这个链接是w3school的hadoop教程,感觉比较好,可以完全按照这个来配置。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)