在AWS EC2上编译Caffe,并测试示例程序
在AWS EC2上编译Caffe,并测试示例程序Caffe 1.0.01. 启动Ubuntu 14.04 EC2.选择镜像版本2. 进入虚拟机后,安装编译 Caffe步骤,参考。http://blog.csdn.net/xuyongshi02/article/details/53945635目前的版本是 1.0.0-rc3。h
- 在AWS EC2上编译Caffe,并测试示例程序
Caffe 1.0.0
1. 启动Ubuntu 14.04 EC2.
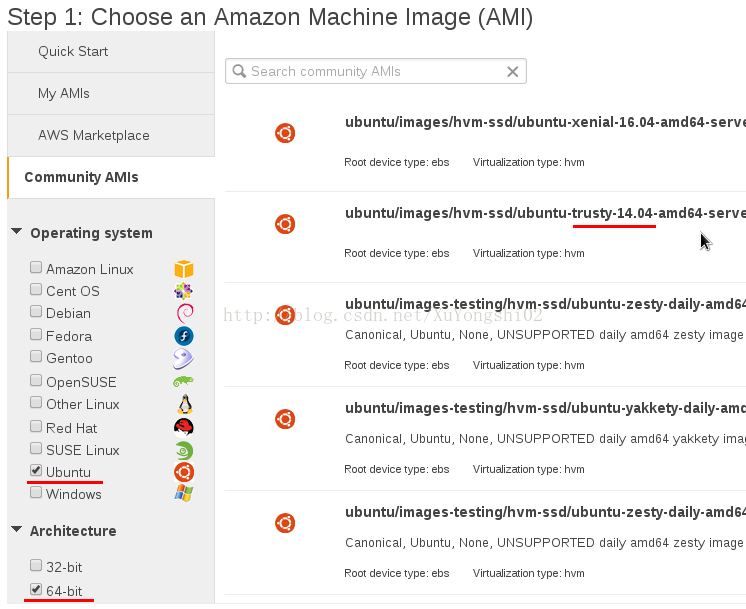
选择镜像版本
2. 进入虚拟机后,安装编译 Caffe
步骤,参考。http://blog.csdn.net/xuyongshi02/article/details/53945635
目前的版本是 1.0.0-rc3。
https://prateekvjoshi.com/2016/01/05/how-to-install-caffe-on-ubuntu/
得到的虚拟机信息如下:
一台是EC2虚拟机,另一台是docker容器。

编译后的主要可执行文件。
3. 准备数据(包括训练,测试,及相应的标签Label)
如 mnist 示例 ( 在源码的相应的目录下)
wget --no-check-certificate http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
4. 下载后的数据需要转成 lmdb 数据库格式
| build/examples/mnist/convert_mnist_data.bin data/mnist/train-images-idx3-ubyte \
data/mnist/train-labels-idx1-ubyte examples/mnist/mnist_train_lmdb --backend=lmdb |
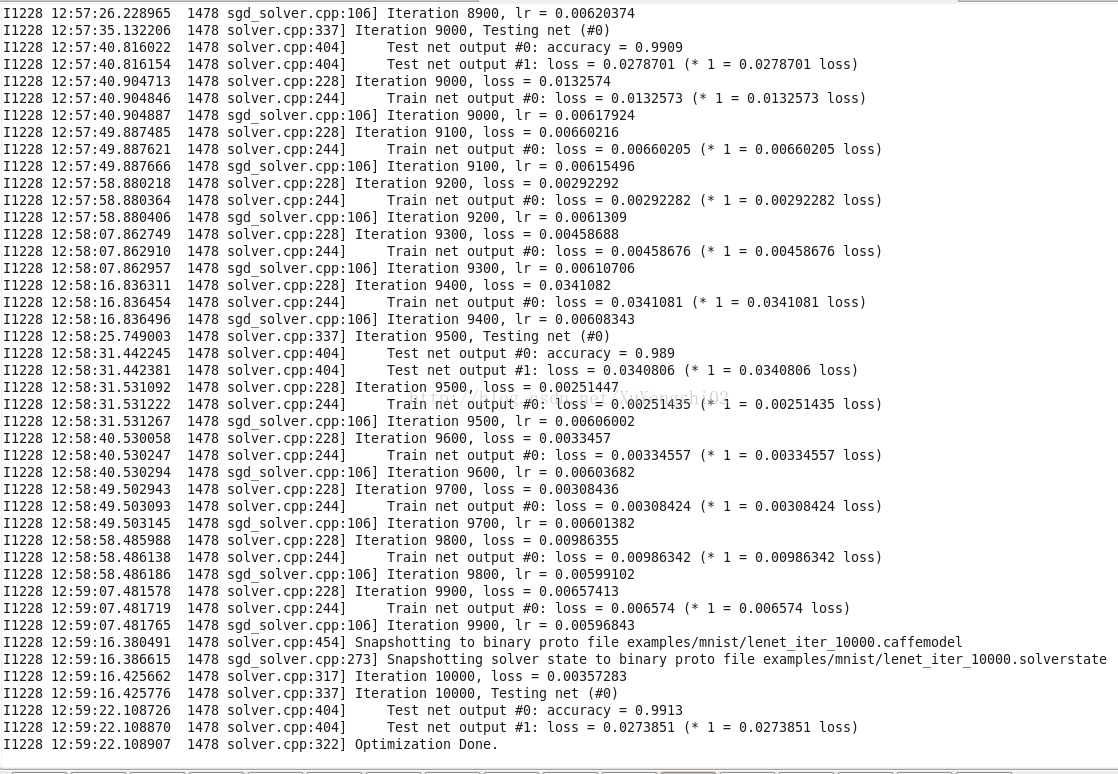
5. 训练
| set -e && build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt |
部分的输出如下:
在EC2 t2.small 上运行时间 大约 20分钟
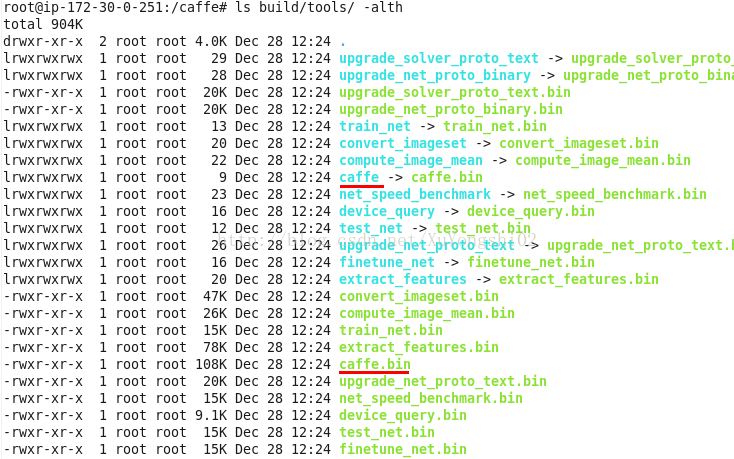
可以看到 目录下,多了几个文件
6. 预测
build/tools/caffe test \
--model=examples/mnist/lenet_train_test.prototxt \
--weights examples/mnist/lenet_iter_10000.caffemodel \
-iterations 100
输出大致如下:
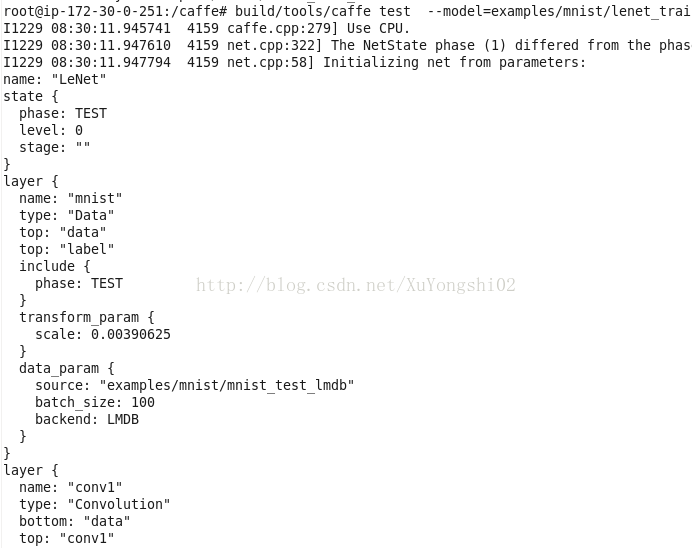
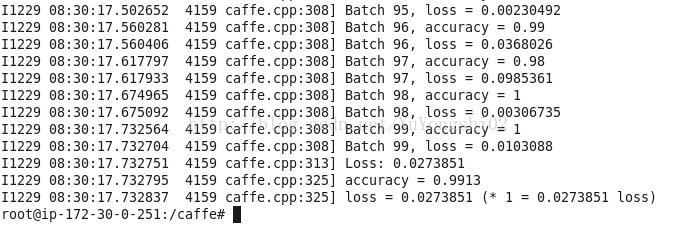
大约运行了1分钟左右, 从结果可以看到, 准确度99%。
日志 输出样例 http://blog.csdn.net/xuyongshi02/article/details/53945467
参考:

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)