
AI驱动TDSQL-C Serverless 数据库技术实战营-融合智能体与TDSQL-C技术,高效实现二手房数据查询与分析应用
TDSQL-C MySQL版(TDSQL-C for MySQL)——腾讯云自主研发的新一代云原生关系型数据库,完美融合了传统数据库的成熟经验、云计算的灵活便捷以及新硬件技术的强大性能。它全面兼容MySQL,致力于为用户提供极致弹性的伸缩能力、卓越的性能表现、高度可用的服务、坚如磐石的数据可靠性以及全方位的安全保障。TDSQL-C能够轻松实现超百万QPS的高并发处理能力,支持PB级数据量的分布式智
文章目录
什么是TDSQL-C
TDSQL-C MySQL版(TDSQL-C for MySQL)——腾讯云自主研发的新一代云原生关系型数据库,完美融合了传统数据库的成熟经验、云计算的灵活便捷以及新硬件技术的强大性能。它全面兼容MySQL,致力于为用户提供极致弹性的伸缩能力、卓越的性能表现、高度可用的服务、坚如磐石的数据可靠性以及全方位的安全保障。TDSQL-C能够轻松实现超百万QPS的高并发处理能力,支持PB级数据量的分布式智能存储,以及Serverless模式的秒级自动伸缩,助力企业快速推进数字化转型,迈向业务发展的新高度。
技术创新
本篇博客 我们基于 TDSQL-C Mysql Serverless 与HAI llama 大模型结合,实现自然语言操作数据库并进行统计分析功能,开启大模型应用时代。
主要实现思路:

算力服务器与数据库服务器申请与部署
购买 TDSQL-C Mysql Serverless 实例
- 访问腾讯云官网申请 TDSQL-C Mysql 服务器, 点击链接 进行访问, 如下图所示,点击立即选购
- 选购
如下图所示,选购我们所需的Serverless
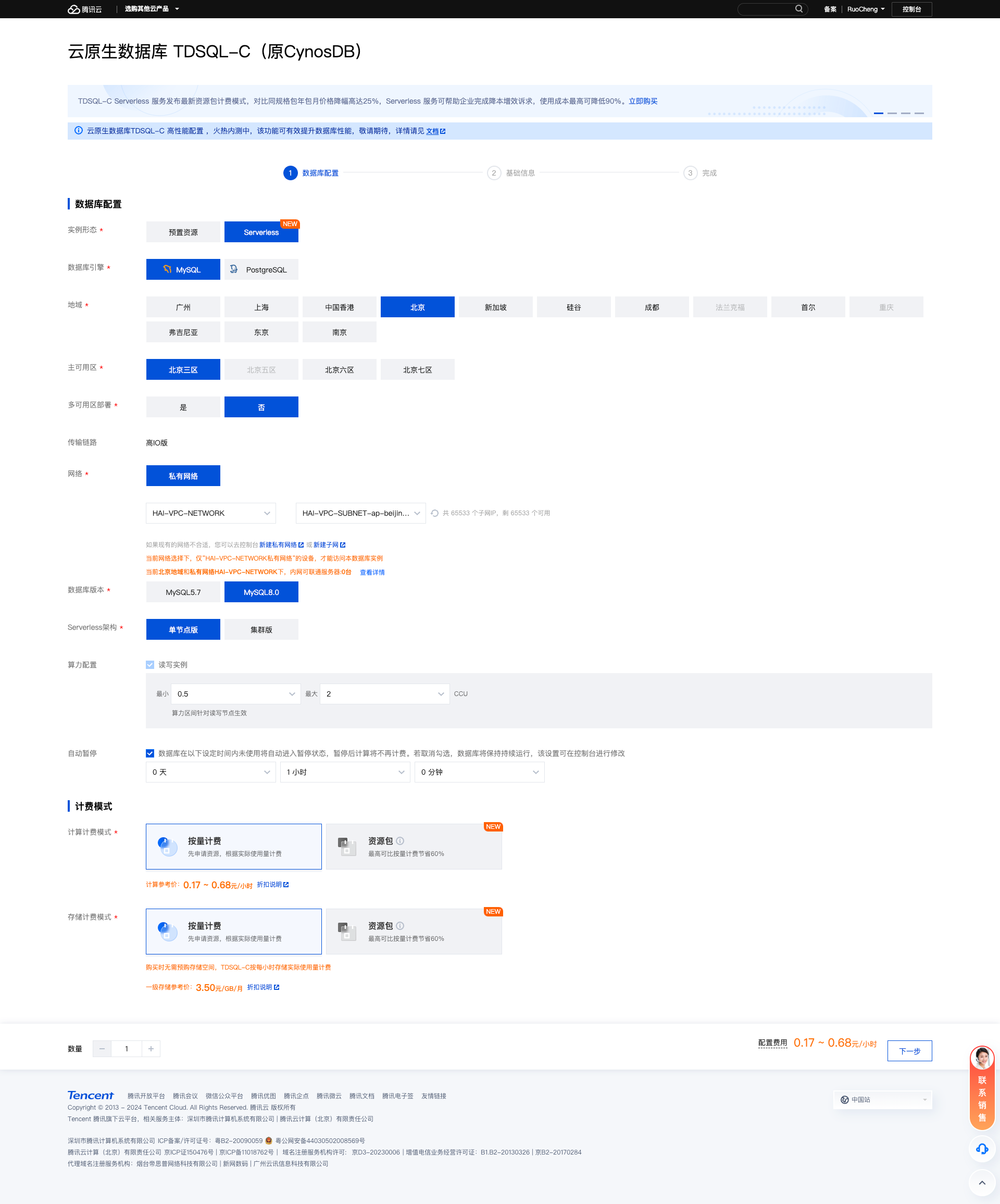
- 设置数据库密码与配置信息
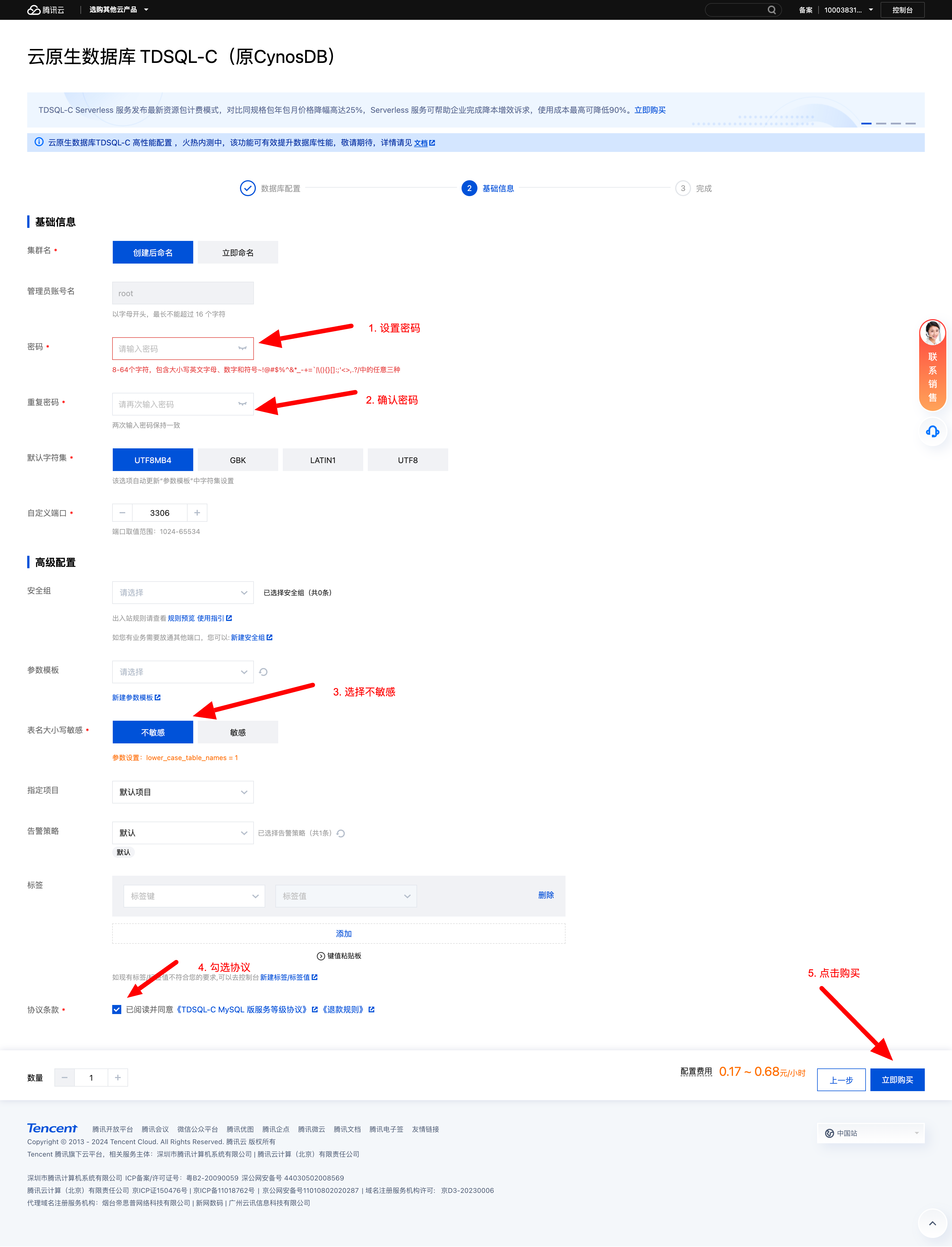
按照上述操作完成之后点击立即购买即可
购买HAI高算力服务器
- 点击链接 访问腾讯云
HAI官网,如下图所示点击立即使用

- 点击新建按钮,新建服务器(费用会在新建服务器并使用后才开始计费)

- 根据配置需求选择算力服务器

- 查看
HAI算力服务器的llama对外端口
检查是否已经默认开放 6399端口,如果没有开放的话需要手动点击端口配置在入站规则中添加协议端口
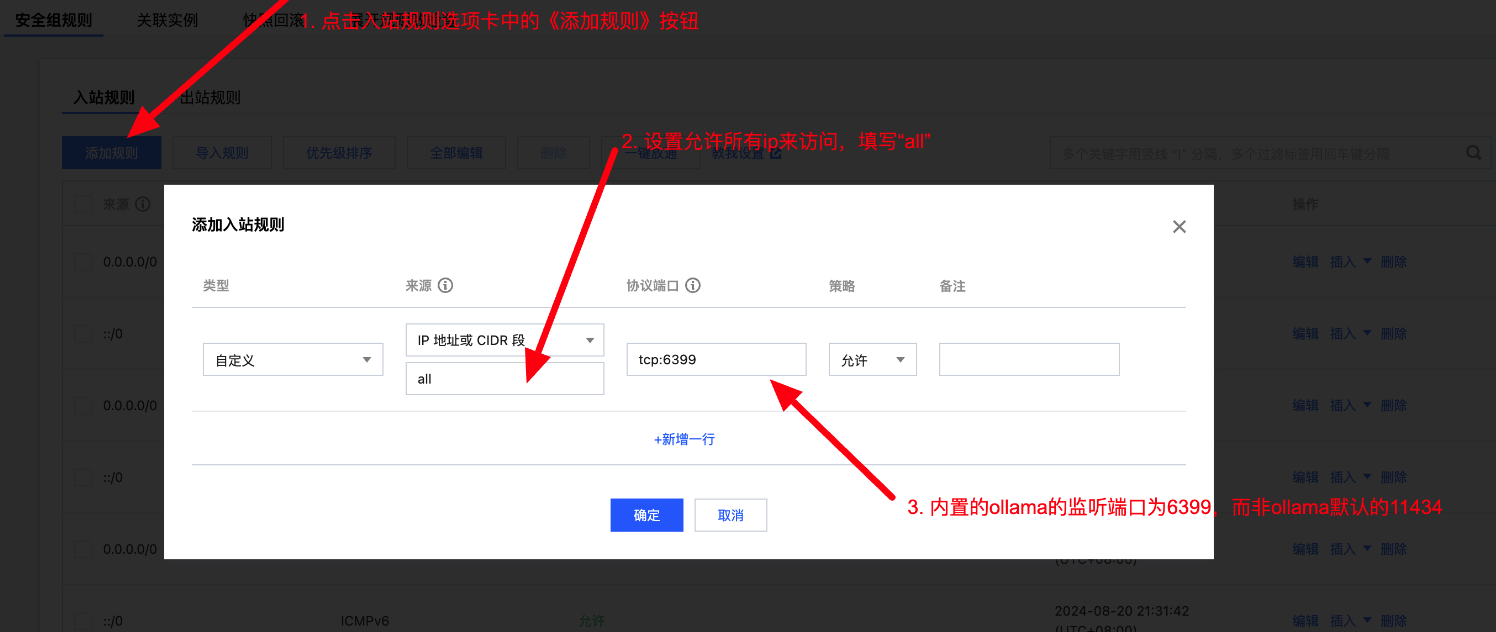
配置完成之后可以在浏览器中输入 ip:6399 进行访问,查看浏览器页面中是否有 ollama is running 的输出, 如果有输出的话,则表示此时的配置没有问题,外部链接是可以访问的。
准备工作
准备数据
如下图所示我们准备的是南京二手房的部分csv数据, 目前准备了1000条数据,用于我们本次的测试使用

下载依赖
如下图所示在终端输入指令,下载所需的依赖
pip install openai
pip install langchain
pip install langchain-core
pip install langchain-community
pip install mysql-connector-python
pip install streamlit
pip install plotly
pip install numpy
pip install pandas
pip install watchdog
pip install matplotlib
pip install kaleido
好啦到目前为止,我们前期的环境准备工作就已经完成了, 接下来我们进入项目开发阶段
案例研发
创建数据库
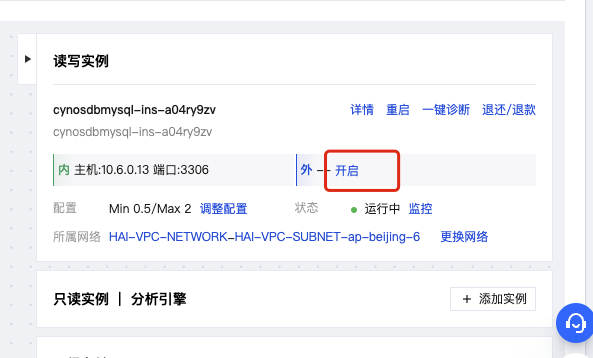
- 如下图所示在我们创建好的TDSQL-C的集群列表页面点击开启外网访问
- 登录tdsql-c 或者通过
Navicat来链接TDSQL-C
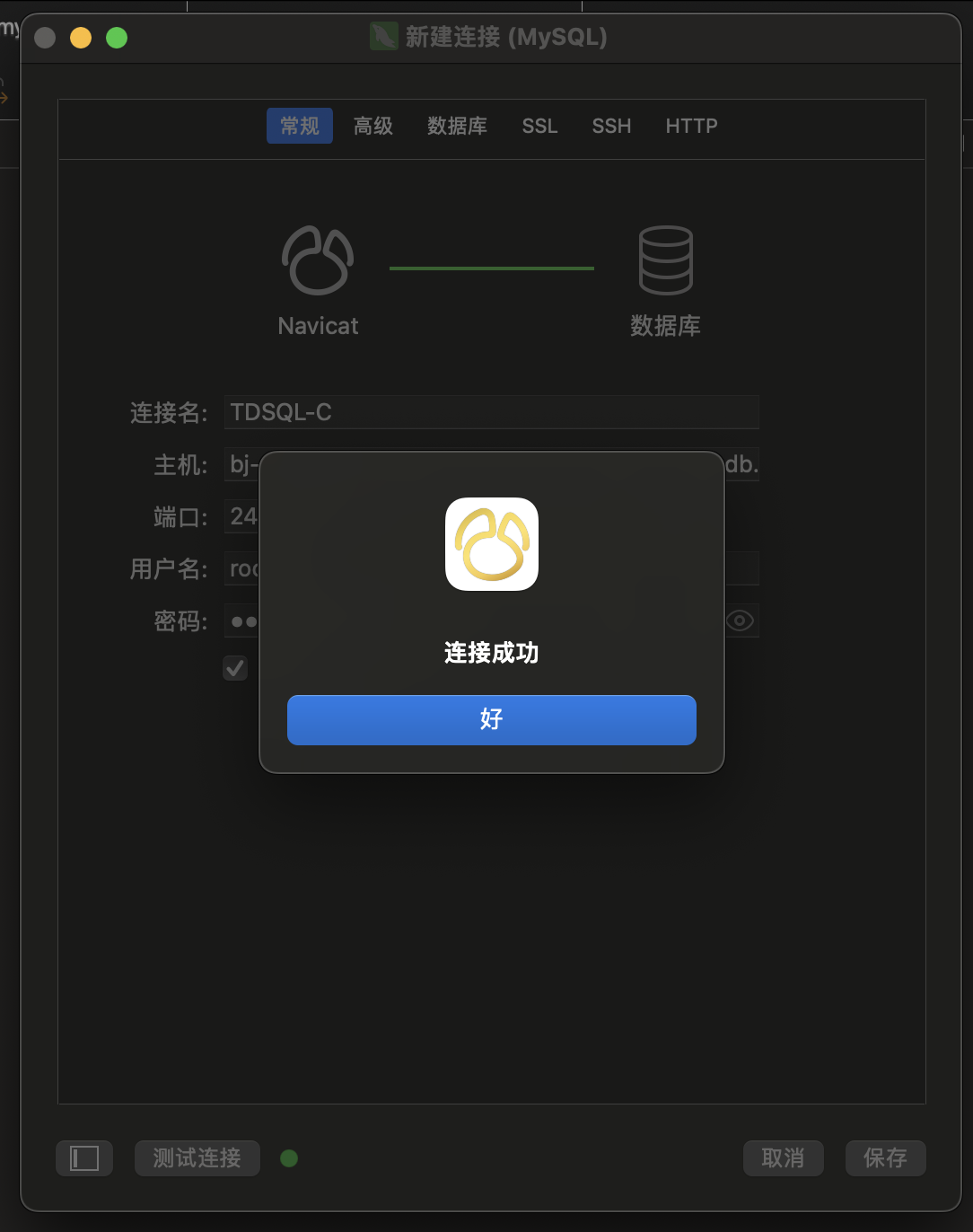
- 创建一个数据库命名
mysqlflex
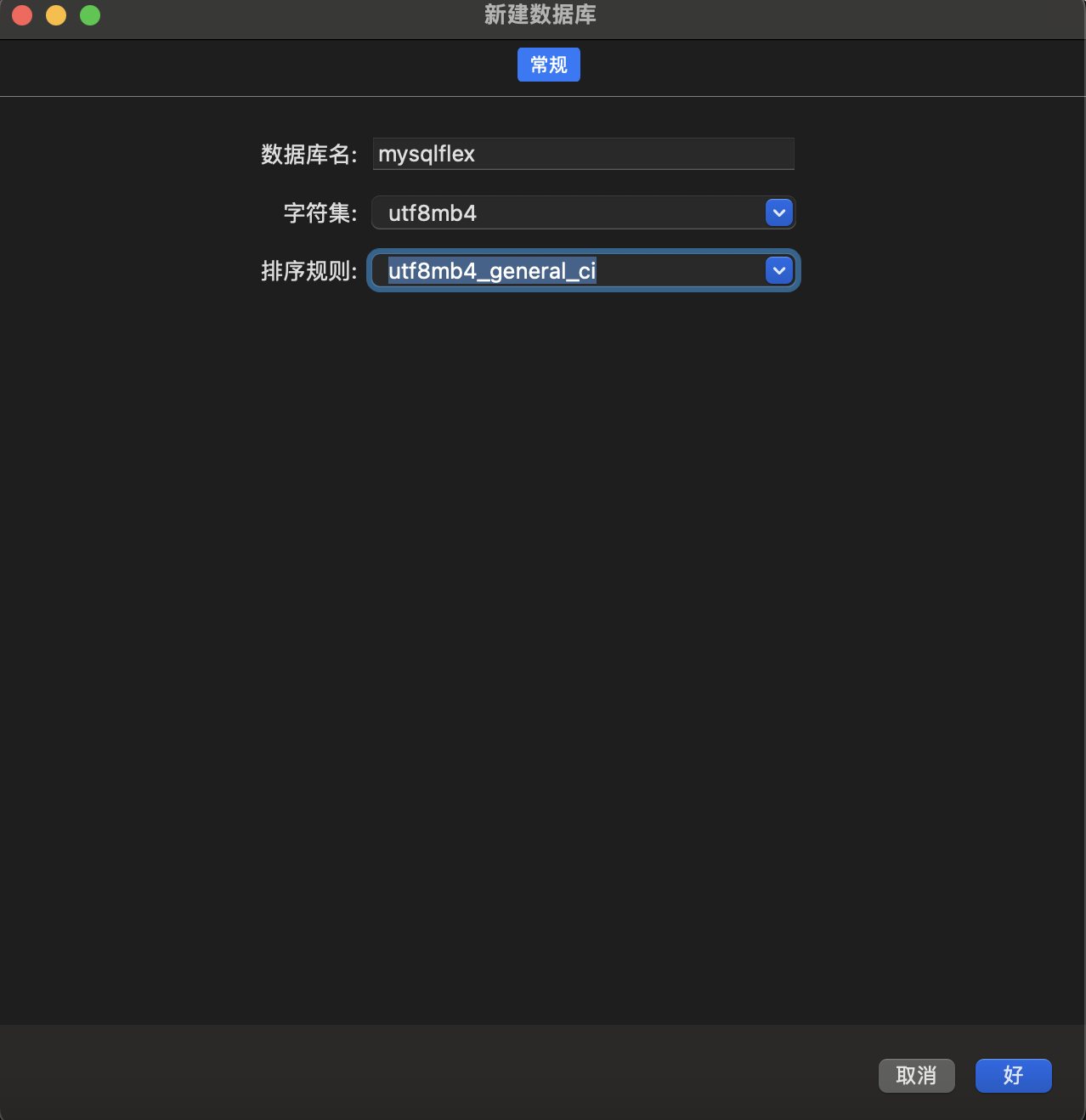
- 执行sql语句创建数据表,代码如下:
CREATE TABLE test_table (
id INT AUTO_INCREMENT PRIMARY KEY,
community_name VARCHAR(255),
location_area VARCHAR(100),
total_price DECIMAL(10, 2),
unit_price DECIMAL(10, 2),
house_type VARCHAR(100),
floor_level VARCHAR(100),
built_area DECIMAL(10, 2),
house_structure VARCHAR(100),
inside_area DECIMAL(10, 2),
building_type VARCHAR(100),
orientation VARCHAR(50),
construction_structure VARCHAR(100),
decoration_status VARCHAR(100),
elevator_ratio VARCHAR(50),
has_elevator VARCHAR(50),
property_years TEXT,
listing_time DATE,
transaction_ownership VARCHAR(100),
last_transaction DATE,
house_usage VARCHAR(100),
house_age VARCHAR(100),
property_ownership VARCHAR(100),
mortgage_info VARCHAR(255),
house_certificate_backup VARCHAR(255)
);
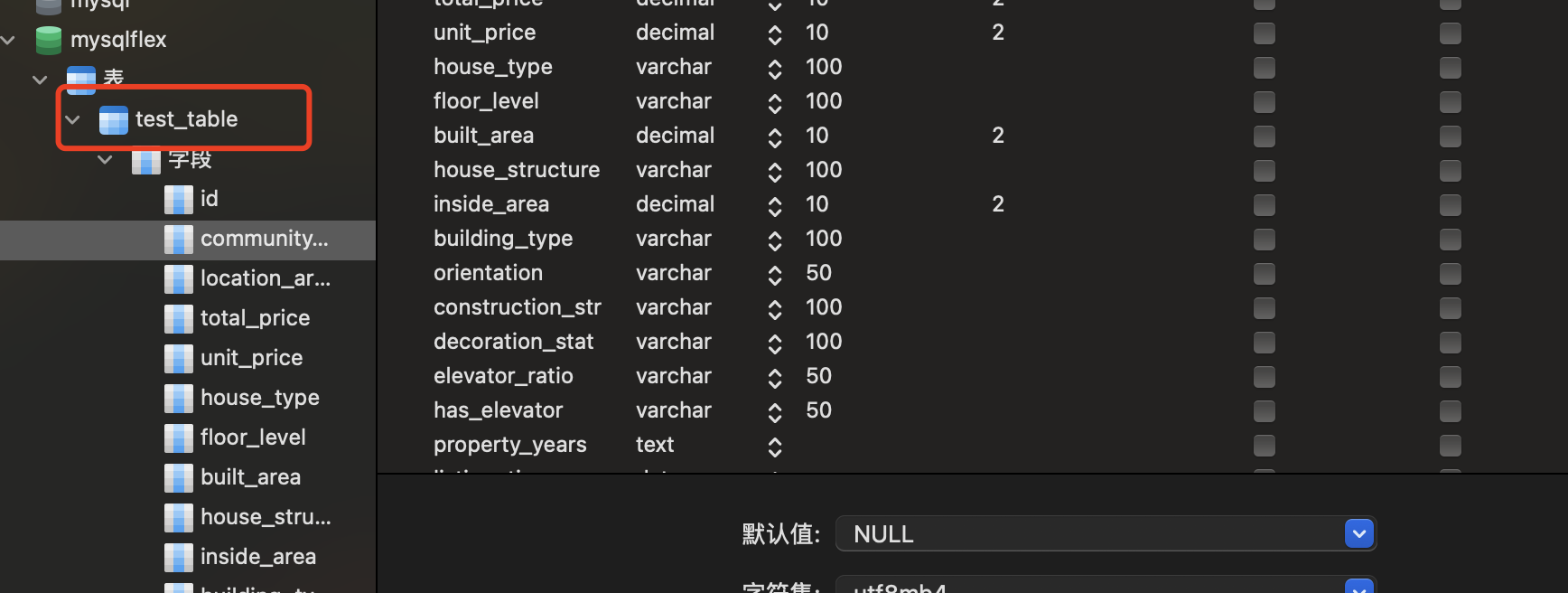
sql 语句执行完成之后创建如下图所示的数据表
写入数据
如下图是我们项目的目录结构:
接下来我们通过读取csv 数据将其写入到TDSQL-C 中,代码如下:
# 数据库连接信息
config = {
'user': 'root',
'password': 'your_password’,
'host': 'bj***************com',
'database': 'mysqlflex',
'port':24863,
'raise_on_warnings': True
}
# CSV文件路径
file_path = '南京二手房数据集.csv'
def insert_csv_data_to_db(config, file_path):
# 创建连接
creatConnector = mysql.connector.connect(**config)
# 获取游标
cursor = creatConnector.cursor()
try:
# 读取csv 数据, 并将数据插入到数据库
with open(file_path, mode='r', encoding='utf-8') as csv_file:
reader = csv.DictReader(csv_file)
rows = list(reader) # 将CSV行转换为列表,以便批量插入
# 定义SQL插入语句模板
query_template = """
INSERT INTO test_table (
id,
community_name,
location_area,
total_price,
unit_price,
house_type,
floor_level,
built_area,
house_structure,
inside_area,
building_type,
orientation,
construction_structure,
decoration_status,
elevator_ratio,
has_elevator,
property_years,
listing_time,
transaction_ownership,
last_transaction,
house_usage,
house_age,
property_ownership,
mortgage_info,
house_certificate_backup
) VALUES (
%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,
)
"""
# 将每行数据转换成元组格式,并处理空字段
values_tuples = []
for row in rows:
# 将空字符串转换为None
values = [None if value == '' or value == '暂无数据' else value for value in row.values()]
values_tuples.append(tuple(values))
# 打印前几个元组进行调试
# print(values_tuples[:5])
cursor.executemany(query_template, values_tuples)
# 提交事务
creatConnector.commit()
except mysql.connector.Error as err:
print(f"Database error: {err}")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 关闭游标
cursor.close()
# 关闭连接
creatConnector.close()
if __name__ == '__main__':
# 调用函数执行插入操作
insert_csv_data_to_db(config, file_path)
执行代码后查看数据是否插入到数据库,如下图所示

登录TD-SQL-C 查看数据
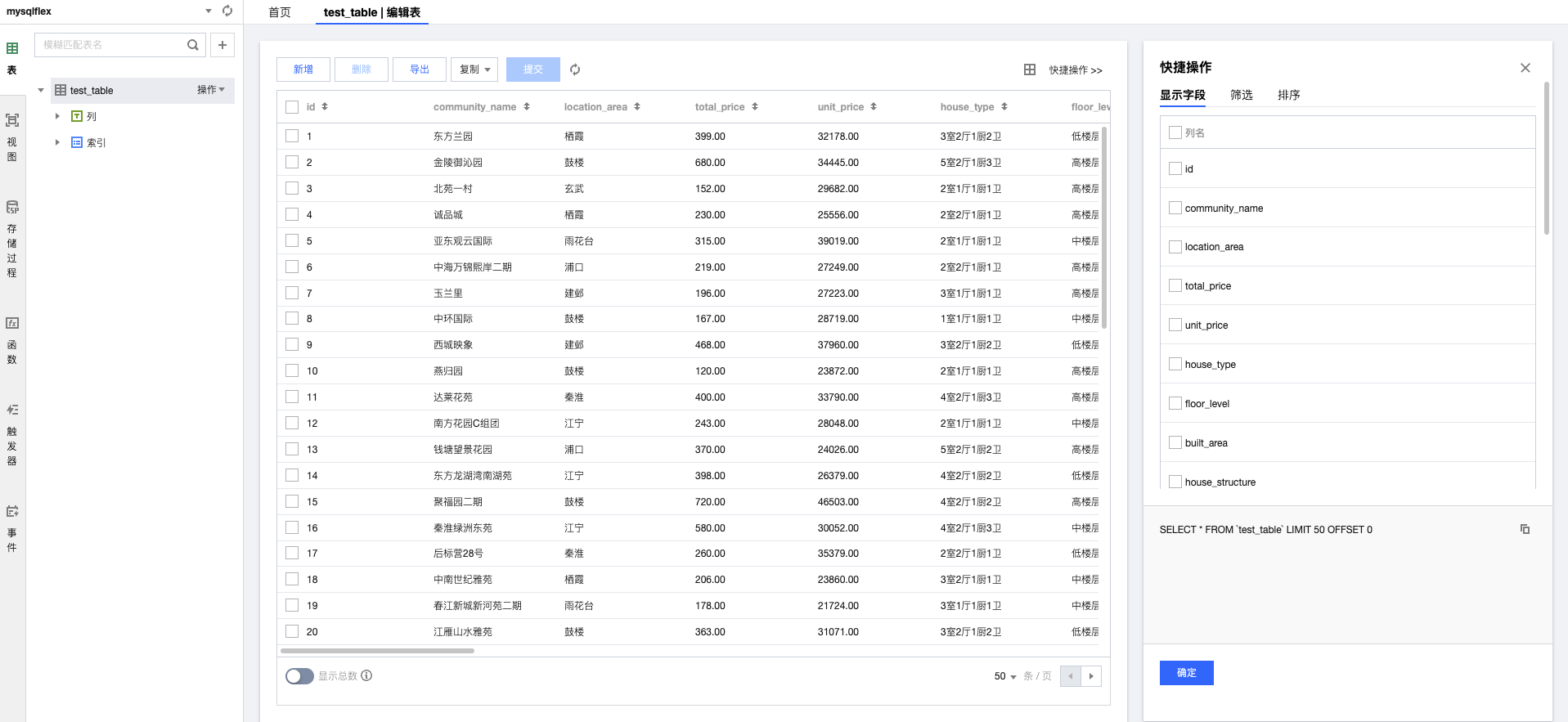
智能体与TDSQL-C 的结合应用
到目前为止我们已经将数据导入到数据库了, 接下来我们将会正式体验基于大语言模型与LangChain的智能应用构建
第一步配置llama3.1
在项目文件下创建config.yaml文件 , 并编写hai 和TDSQL-C 的基本链接信息, 如下图所示

第二步代码开发
代码开发部分完整代码如下, 需要注意的是 , 代码中我已经将读取csv 的数据写入到数据库部分写成函数模式,在构建项目的过程中该部分代码不会执行, 如果需要执行该部分代码则直接调用insert_csv_data_to_db 函数即可
import csv
from langchain_community.utilities import SQLDatabase
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import streamlit as st
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import yaml
import mysql.connector
from decimal import Decimal
import plotly.graph_objects as go
import plotly
import pkg_resources
import matplotlib
# Streamlit app code
import streamlit as st
import mysql.connector
import csv
# 数据库连接信息
config = {
'user': 'root',
'password': 'Ruo*****',
'host': 'bj-************ncentcdb.com',
'database': 'mysqlflex',
'port': 24863,
'raise_on_warnings': True
}
def insert_csv_data_to_db(config, file_path):
# 创建连接
creatConnector = mysql.connector.connect(**config)
# 获取游标
cursor = creatConnector.cursor()
try:
# 读取csv 数据, 并将数据插入到数据库
with open(file_path, mode='r', encoding='utf-8') as csv_file:
reader = csv.DictReader(csv_file)
rows = list(reader) # 将CSV行转换为列表,以便批量插入
# 定义SQL插入语句模板
query_template = """
INSERT INTO test_table (
id,
community_name,
location_area,
total_price,
unit_price,
house_type,
floor_level,
built_area,
house_structure,
inside_area,
building_type,
orientation,
construction_structure,
decoration_status,
elevator_ratio,
has_elevator,
property_years,
listing_time,
transaction_ownership,
last_transaction,
house_usage,
house_age,
property_ownership,
mortgage_info,
house_certificate_backup
) VALUES (
%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s
)
"""
# 将每行数据转换成元组格式,并处理空字段
values_tuples = []
for row in rows:
# 将空字符串转换为None
values = [None if value == '' or value == '暂无数据' else value for value in row.values()]
values_tuples.append(tuple(values))
# 打印前几个元组进行调试
# print(values_tuples[:5])
cursor.executemany(query_template, values_tuples)
# 提交事务
creatConnector.commit()
except mysql.connector.Error as err:
print(f"Database error: {err}")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 关闭游标
cursor.close()
# 关闭连接
creatConnector.close()
yaml_file_path = 'config.yaml'
with open(yaml_file_path, 'r') as file:
config_data = yaml.safe_load(file)
# 获取所有的已安装的pip包
def get_piplist(p):
return [d.project_name for d in pkg_resources.working_set]
# 获取llm用于提供AI交互
ollama = ChatOllama(model=config_data['hai']['model'], base_url=config_data['hai']['base_url'])
db_user = config_data['database']['db_user']
db_password = config_data['database']['db_password']
db_host = config_data['database']['db_host']
db_port = config_data['database']['db_port']
db_name = config_data['database']['db_name']
# 获得schema
def get_schema(db):
schema = mysql_db.get_table_info()
return schema
def getResult(content):
global mysql_db
# 数据库连接
mysql_db = SQLDatabase.from_uri(f"mysql+mysqlconnector://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}")
# 获得 数据库中表的信息
# mysql_db_schema = mysql_db.get_table_info()
# print(mysql_db_schema)
template = """基于下面提供的数据库schema, 根据用户提供的要求编写sql查询语句,要求尽量使用最优sql,每次查询都是独立的问题,不要收到其他查询的干扰:
{schema}
Question: {question}
只返回sql语句,不要任何其他多余的字符,例如markdown的格式字符等:
如果有异常抛出不要显示出来
"""
prompt = ChatPromptTemplate.from_template(template)
text_2_sql_chain = (
RunnablePassthrough.assign(schema=get_schema)
| prompt
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
sql = text_2_sql_chain.invoke({"question": content})
print(sql)
# 连接数据库进行数据的获取
# 配置连接信息
conn = mysql.connector.connect(
host=db_host,
port=db_port,
user=db_user,
password=db_password,
database=db_name
)
# 创建游标对象
cursor = conn.cursor()
# 查询数据
cursor.execute(sql.strip("```").strip("```sql"))
info = cursor.fetchall()
# 打印结果
# for row in info:
# print(row)
# 关闭游标和数据库连接
cursor.close()
conn.close()
# 根据数据生成对应的图表
print(info)
template2 = """
以下提供当前python环境已经安装的pip包集合:
{installed_packages};
请根据data提供的信息,生成是一个适合展示数据的plotly的图表的可执行代码,要求如下:
1.不要导入没有安装的pip包代码
2.如果存在多个数据类别,尽量使用柱状图,循环生成时图表中对不同数据请使用不同颜色区分,
3.图表要生成图片格式,保存在当前文件夹下即可,名称固定为:图表.png,
4.我需要您生成的代码是没有 Markdown 标记的,纯粹的编程语言代码。
5.生成的代码请注意将所有依赖包提前导入,
6.不要使用iplot等需要特定环境的代码
7.请注意数据之间是否可以转换,使用正确的代码
8.不需要生成注释
data:{data}
这是查询的sql语句与文本:
sql:{sql}
question:{question}
返回数据要求:
仅仅返回python代码,不要有额外的字符
"""
prompt2 = ChatPromptTemplate.from_template(template2)
data_2_code_chain = (
RunnablePassthrough.assign(installed_packages=get_piplist)
| prompt2
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
code = data_2_code_chain.invoke({"data": info, "sql": sql, 'question': content})
# 删除数据两端可能存在的markdown格式
print(code.strip("```").strip("```python"))
exec(code.strip("```").strip("```python"))
return {"code": code, "SQL": sql, "Query": info}
# 构建展示页面
import streamlit
# 设置页面标题
streamlit.title('智能体与TDSQL-C 的结合应用之二手房信息查询')
# 设置对话框
content = streamlit.text_area('请输入想查询的信息', value='', max_chars=None)
# 提问按钮 # 设置点击操作
if streamlit.button('提问'):
# 开始ai及langchain操作
if content:
# 进行结果获取
result = getResult(content)
# 显示操作结果
streamlit.write('AI生成的SQL语句:')
streamlit.write(result['SQL'])
streamlit.write('SQL语句的查询结果:')
streamlit.write(result['Query'])
streamlit.write('plotly图表代码:')
streamlit.write(result['code'])
# 显示图表内容(生成在getResult中)
streamlit.image('./图表.png', width=800)
运行应用
如下图所示在终端执行命令 streamlit run tdsqlAitest.py 来启动应用

访问链接在浏览器中效果如下图所示
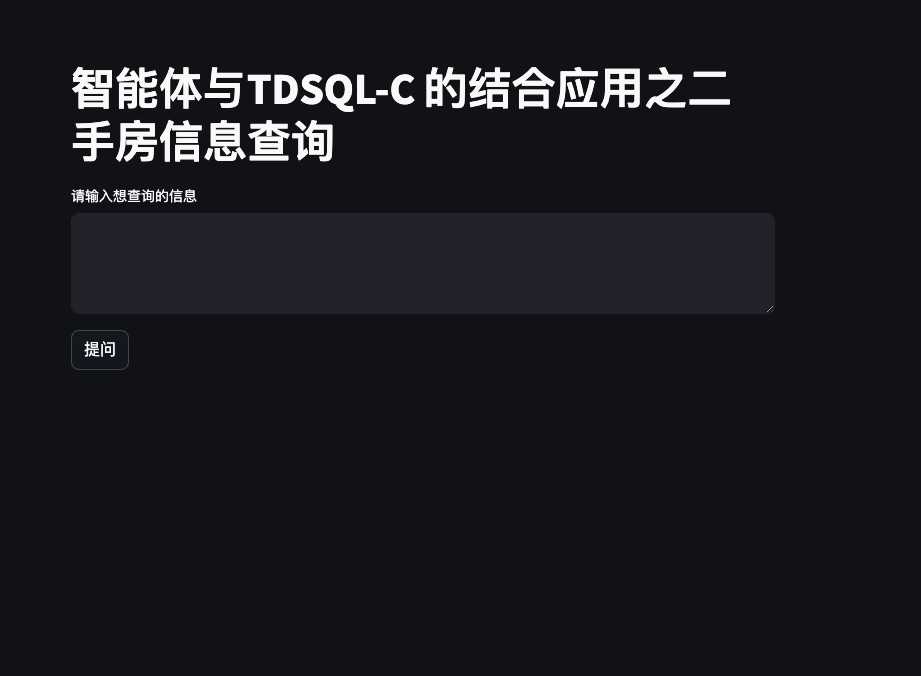
测试应用
接下来我们输入查询一下数据库中每个小区的房屋总价 来测试应用
注意我们点击提问的时候,执行的操作如下:
- 连接SQL并执行SQL操作,获取查询结果
- 基于大语言模型生成PLOTLY图表代码并执行
- 生成Plotly图表并在Web中展示
效果如下图所示

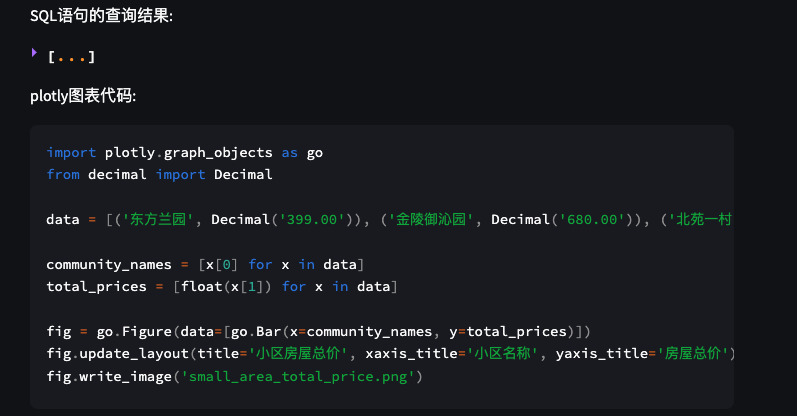

总结
本篇博客中,我们成功从无到有构建了基于LangChain的Text2SQL服务,这一创新性进展的关键步骤包括:
- 成功对接了Llama3.1大型模型;
- 构建了SQL-Chain,将数据库架构信息导入大型语言模型;
- 构建了User-Chain,用于将用户的查询需求传递给模型,并生成相应的SQL查询语句。
我认为,这一成就标志着人工智能与数据库领域的深度融合,实现了划时代的突破。它不仅大幅提升了生产力,也为智能科技在未来的应用打开了新的可能性。展望未来,我们将继续探索智能科技在更多领域的创新应用。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 57
57 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)