Hadoop2.7.4在Windows 7(64位)详细配置(完美版)
hadoop环境搭建相对麻烦,需要安装虚拟机过着cygwin什么的,所以通过查资料和摸索,在window上搭建了一个,不需要虚拟机和cygwin依赖,相对简便很多。官网下载JDK 1.8版本配置好java环境官网下载hadoop-2.7.4.tar.gz解压至无空格目录下即可,下面是目录结构:文件夹访问权限修改(Everyone)下载Hadoop 2.7.4 Windows 64位 编译
hadoop环境搭建相对麻烦,需要安装虚拟机过着cygwin什么的,所以通过查资料和摸索,在window上搭建了一个,不需要虚拟机和cygwin依赖,相对简便很多。
官网下载JDK 1.8版本
配置好java环境

官网下载hadoop-2.7.4.tar.gz
解压至无空格目录下即可,下面是目录结构:
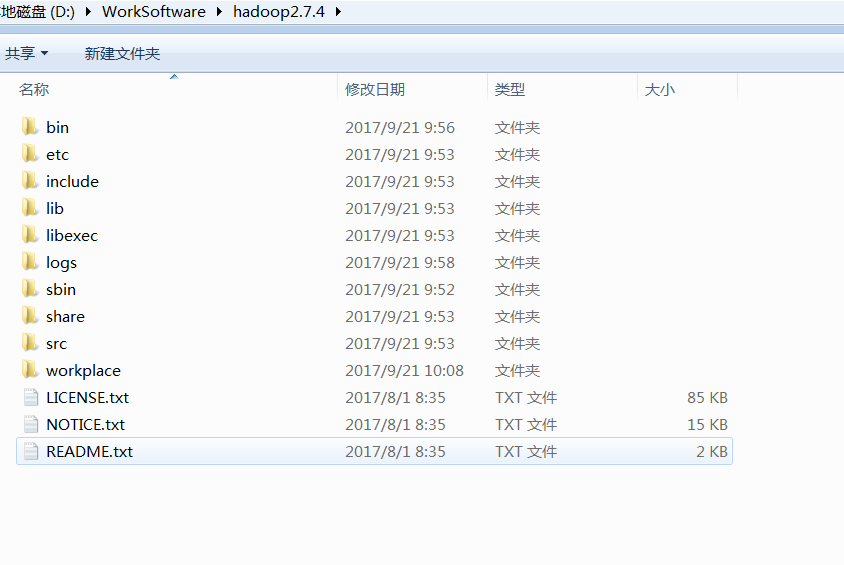
文件夹访问权限修改(Everyone)
下载Hadoop 2.7.4 Windows 64位 编译bin
某网友提供的文件地址
将压缩包里的bin目录(包含以下.dll和.exe文件)文件替换官网hadoop目录下的bin目录;
为Hadoop配置windows环境变量
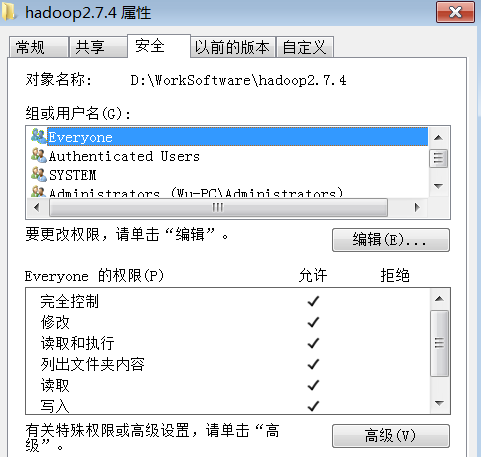
右键单击我的电脑 –>属性 –>高级环境变量配置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME,如下图
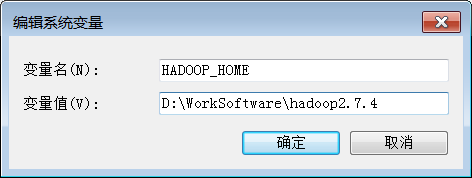
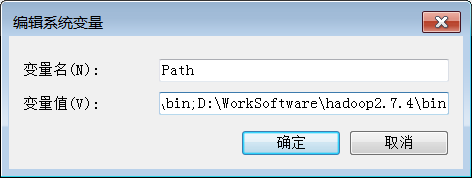
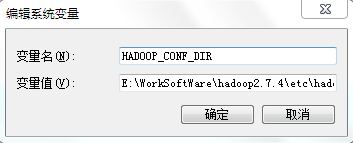
HADOOP_CONF_DIR 指定配置文件的路径为E:\WorkSoftWare\hadoop2.7.4\etc\hadoop
hadoop环境测试:
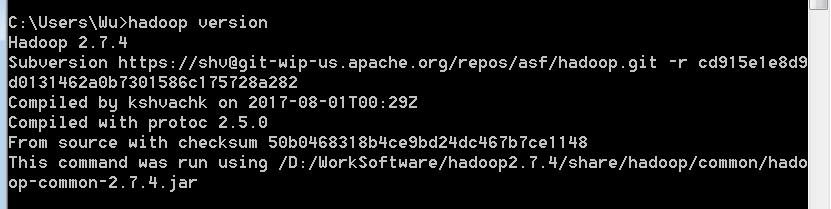
打开一个cmd窗口,hadoop version,显示如下:
修改Hadoop配置文件(namenode,datanode运行读取)
注意:配置文件里windows所有盘符前要加/,比如: /D:/XXXXXXXXXX
编辑“D:\WorkSoftware\hadoop2.7.4\etc\hadoop”下的配置文件,
参考配置
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/WorkSoftware/hadoop2.7.4/workplace/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.name.dir</name>
<value>/D:/WorkSoftware/hadoop2.7.4/workplace/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/WorkSoftware/hadoop2.7.4/workplace/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
</configuration>
mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--告诉hadoop以后MR运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!--nomenodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的老大(ResourceManager)的地址-->
<!--****************-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
启动
格式化系统文件:
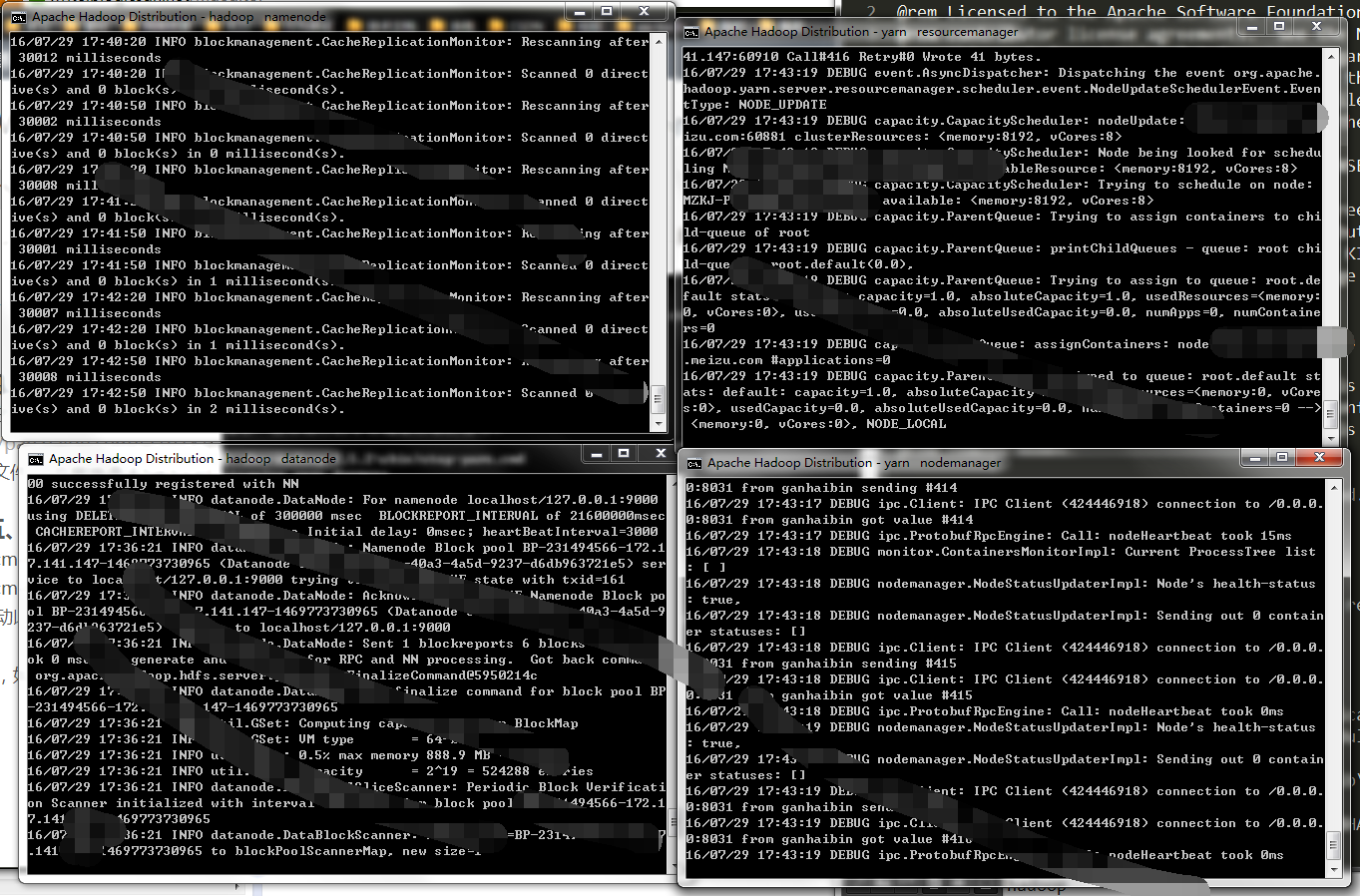
hdfs namenode -format格式化完成后到hadoop/sbin下执行,启动hadoop
start-dfs
也可以执行“start-all”,
start-all它将会启动以下进程
访问:http://localhost:50070,如图:
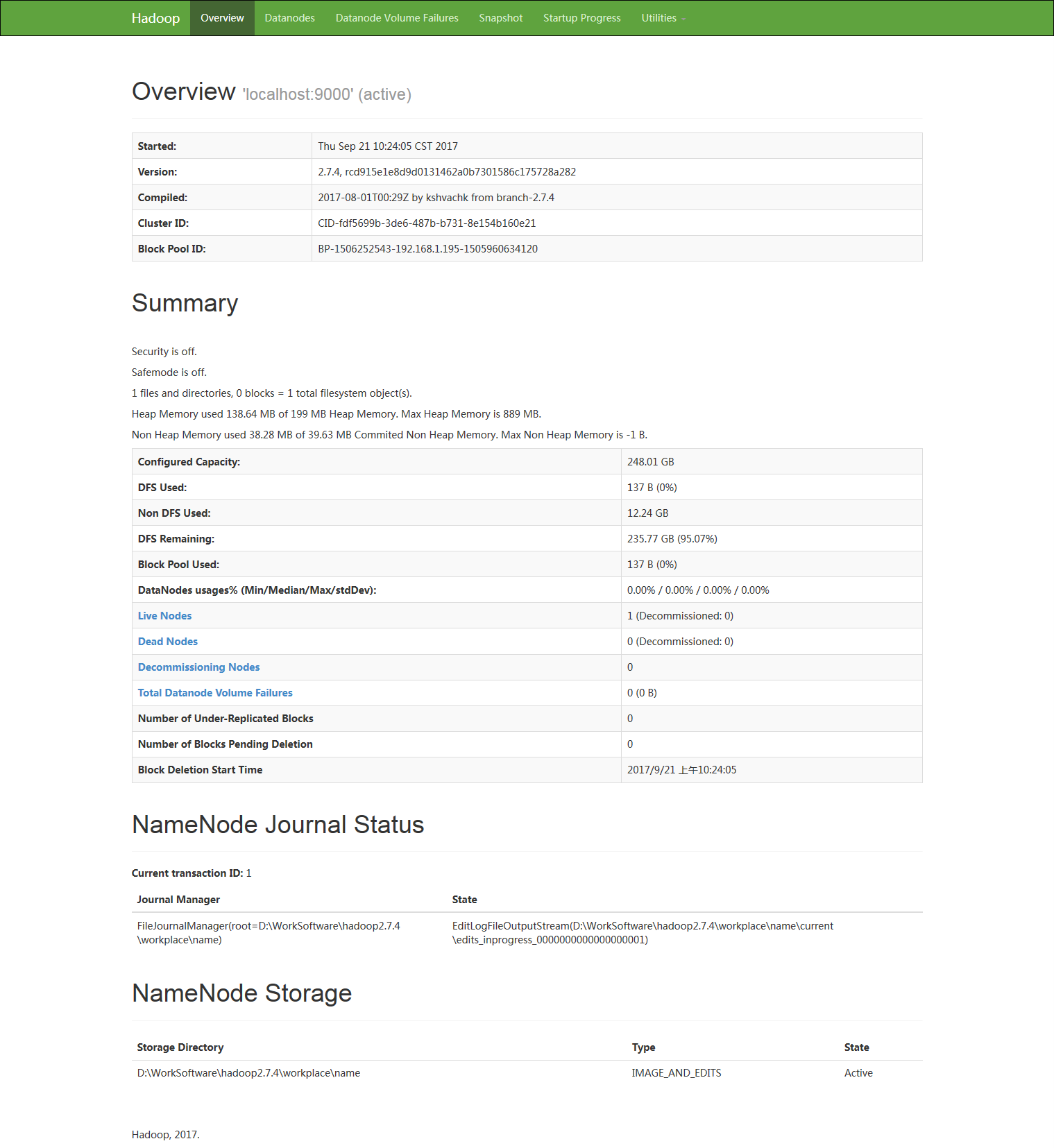
至此,hadoop服务已经搭建完毕。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)