Windows下IntelliJ IDEA远程连接服务器中Hadoop运行WordCount(详细版)
使用IDEA直接运行Hadoop项目,有两种方式,分别是本地式:本地安装Hadoop+IDEA;远程式:远程部署Hadoop,本地安装IDEA并连接, 本文介绍第二种。文章目录一、安装配置Hadoop(1)虚拟机伪分布式(2)云服务器分布式二、配置IDEA1、安装配置Maven2、新建Maven项目三、设置连接Hadoop1、Linux中操作2、IDEA中操作四、可能出现的问题一、安装配置Hado
使用IDEA直接运行Hadoop项目,有两种方式,分别是本地式:本地安装Hadoop+IDEA;远程式:远程部署Hadoop,本地安装IDEA并连接, 本文介绍第二种。
一、安装配置Hadoop
(1)虚拟机伪分布式
见上才艺!CentOS7从0到1部署Apache Hadoop生态集群
(2)云服务器分布式
如果是云主机,需要注意hosts映射问题和安全组开放问题,见阿里云腾讯云等云服务器搭建hadoop集群服务器,内外网hosts配置文件问题
二、配置IDEA
1、安装配置Maven
IDEA自带了Maven,为了更方便和更好的管理,推荐自己安装Maven
Maven是什么?
Maven 是专门用于构建和管理Java相关项目的工具
使用Maven管理项目的3个好处:
1、使用Maven管理的Java 项目都有着相同的项目结构。 有一个pom.xml 用于维护当前项目都用了哪些jar包。所有的java代码都放在 src/main/java 下面; 所有的测试代码都放在src/test/java 下面 。
2、便于统一维护jar包。把所有的jar包都放在了本地"仓库“ 里,然后哪个项目需要用到这个jar包,只需要给出jar包的名称和版本号就行了,这样就实现了jar包共享,避免每一个项目都有自己的jar包带来的麻烦。
3、帮助开发人员将精力倾注在开发而不是在包的管理当中,开发人员无需关注包的冲突问题和管理问题。
- 下载解压(注意Maven版本需要和IDEA匹配,否则可能会报错)
下载地址:apache-maven-3.6.3-bin.zip百度网盘链接
提取码:hgdh
我的IDEA是201903,运行实测无障碍。如果IDEA版本低,可以百度升级方法 - 配置环境变量
(1)先解压到自己的目录当中(随意)

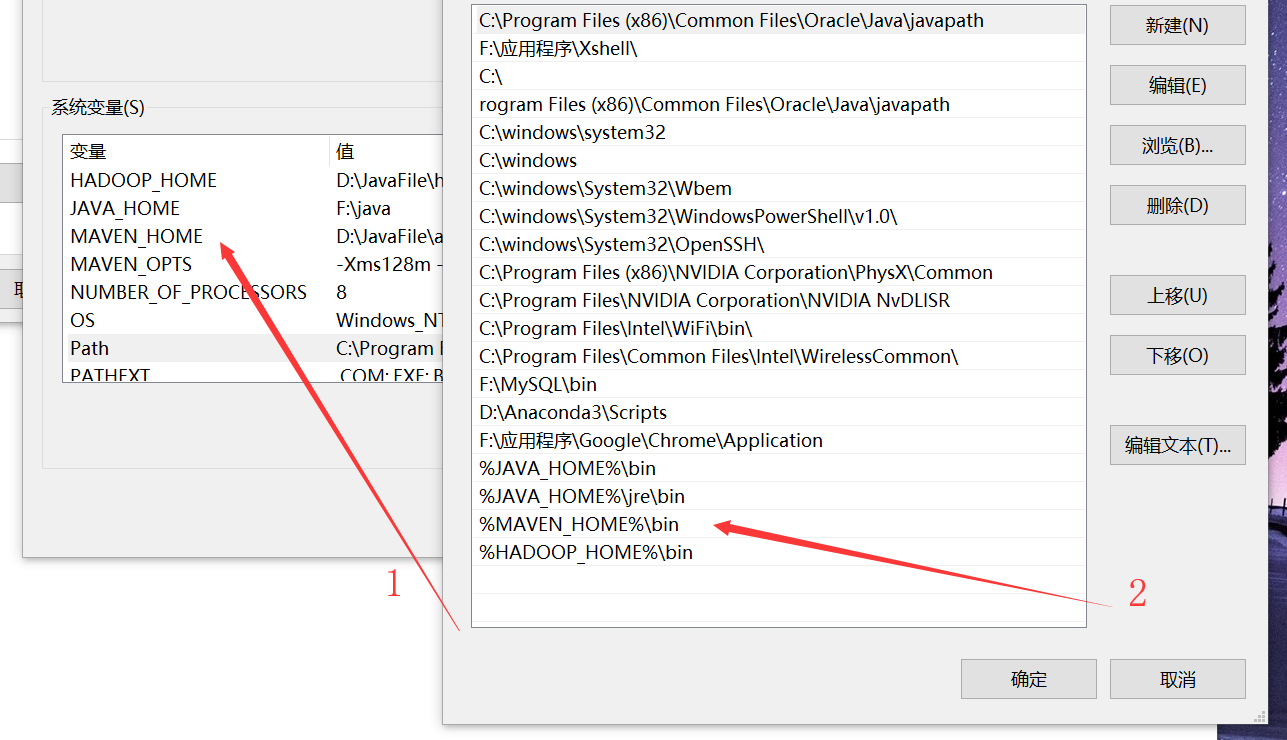
(2)打开电脑环境变量,新建MAVEN_HOME为自己的解压目录,紧接着添加/bib目录到Path_

(3)完成后使用mvn -v查看版本,如果出现如图则环境变量配置完成 - 配置仓库
进入解压目录,备份修改setting.xml
<!-- 自建,maven自动下载的jar包,会存放到该目录下 -->
<localRepository>D:/server/maven/repository</localRepository>
- 配置镜像地址
国内镜像速度更快,推荐修改
<mirrors>
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>
</mirror>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>central</id>
<name>Maven Repository Switchboard</name>
<url>http://repo1.maven.org/maven2/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>repo2</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo2.maven.org/maven2/</url>
</mirror>
<mirror>
<id>ibiblio</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://mirrors.ibiblio.org/pub/mirrors/maven2/</url>
</mirror>
<mirror>
<id>jboss-public-repository-group</id>
<mirrorOf>central</mirrorOf>
<name>JBoss Public Repository Group</name>
<url>http://repository.jboss.org/nexus/content/groups/public</url>
</mirror>
<mirror>
<id>google-maven-central</id>
<name>Google Maven Central</name>
<url>https://maven-central.storage.googleapis.com
</url>
<mirrorOf>central</mirrorOf>
</mirror>
<!-- 中央仓库在中国的镜像 -->
<mirror>
<id>maven.net.cn</id>
<name>oneof the central mirrors in china</name>
<url>http://maven.net.cn/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
- 在IDEA中配置Maven
(1)关闭所有项目,防止配置只生效当前项目!
(2)打开Settings,在输入框输入maven,这里要注意,选择了自定义的maven后, 一定要勾选Override(覆盖)。同时保证 Local repository 项填写的路径和你勾选的配置文件中配置的路径是一致的。

(3)设置镜像源(如果在setting中设置,可跳过!)

(4)配置Intellij IDEA中自动下载jar包 :依次点击File -> Setting ->Maven ->Importing:选中Automatically download中的两个多选框Sources和Documentation

2、新建Maven项目
点击File–>New–>Project,选择Maven


新建后会出现如图所示界面:

1:SRC,项目代码所属目录,放到Java文件中,正式
2:TEST,测试代码
3:POM.xml:包管理文件,需要的包以键值对的方式传入
4:导入包的方式,点击导入
5:也是导入包的方式,点击后本项目的包自动导入
三、设置连接Hadoop
新建完成后需要设置导入包,新建class
1、Linux中操作
(1)拷出hdfs-site.xml和core-site.xml文件
安装lrzsz后可以选择sz保存到Windows中,或者使用软件拷出也可以
(2)启动集群
$HADOOP_HOME/sbin/start-all.sh
(3)创建目录,上传文件到hdfs中
[root@master ~]# hdfs dfs -mkdir /data
[root@master ~]# hdfs dfs -mkdir /out
[root@master ~]# hdfs dfs -put ./word.txt /data/
[root@master ~]# hdfs dfs -ls /data/
Found 1 items
-rw-r--r-- 3 root supergroup 22 2020-08-08 18:14 /data/word.txt
[root@master ~]# hdfs dfs -cat /data/word.txt
hello word
hello Java
[root@master ~]#
2、IDEA中操作
(1)导入hadoop配置文件到resources中

(2)查看一下本项目的Maven是否配置生效了,如果没有则修改

(3)修改pom.xml文件,导入需要的包(无需更改内容)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>JavaHadoopProJectS</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<mainClass>org.hhrz.mapreduce.demo.JobMain</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
修改文件后点击右下角的自动导入包
(4)新建wordcount类(注意编程规范)

package hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
public class WordCount {
public static class Map extends Mapper<Object,Text,Text,IntWritable>{
private static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
StringTokenizer st = new StringTokenizer(value.toString());
while(st.hasMoreTokens()){
word.set(st.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
private static IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{
int sum = 0;
for(IntWritable val:values){
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
static {
try {
System.load("D:/JavaFile/bin/hadoop.dll");//建议采用绝对地址,bin目录下的hadoop.dll文件路径
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
}
public static void main(String[] args) throws Exception{
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境。
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage WordCount <int> <out>");
System.exit(2);
}
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(5)传入参数


第一个路径是输入路径,可以精确到某个文件,也可以模糊到文件夹,但是注意:输入参数是文件夹时,文件夹内不能再包含文件夹;第二个路径是输出路径,输出路径后不能存在,否则会报错。两个文件路径都是HDFS上
(6)运行

四、可能出现的问题
1.org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
原因:缺少hadoop.dll或winutils.exe等驱动,需要下载对应hadoop版本的hadoop.dll(相差较少版本据说也可以,如2.7.3版本Hadoop可以使用2.6的Hadoop.dll)。
解决方案:(1)将文件放置到$Hadoop/bin下;或者 (2)添加到代码当中 (建议放到main的上面)
链接:hadoop-common-2.7.3-bin百度网盘链接
提取码:qf5b
static {
try {
System.load("D:/JavaFile/bin/hadoop.dll");//建议采用绝对地址,bin目录下的hadoop.dll文件路径
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
}
2.log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
原因:log4j缺省问题
解决方法:(1)配置log4j.properties(不推荐,复杂);或者 (2)添加代码
public static void main(String[] args) throws Exception{
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境。建议放到mian当中
以上两个问题的解决代码已经写入到WordCount中,无需额外复制粘贴

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)