ios架构与开发第五课 BFF、MVVM和响应式编程
15跨平台架构:如何设计 BFF 架构系统?上一模块,我和你介绍了iOS 工程化实践中的基础组件设计, 接下来这部分,我们将进入核心内容:移动端系统架构的设计与实现。首先请你想一想:如果没有一套灵活的可扩展的系统架构,结果会怎样?这方面我深有感触,在我们的 App 没有良好的系统架构之前,每一个微小的改动都需要“大动干戈”。具体来说,由于强耦合性,每次改动我们都需要和各个业务部门商讨详细的技术方案
15 跨平台架构:如何设计 BFF 架构系统?
上一模块,我和你介绍了iOS 工程化实践中的基础组件设计, 接下来这部分,我们将进入核心内容:移动端系统架构的设计与实现。
首先请你想一想:如果没有一套灵活的可扩展的系统架构,结果会怎样?
这方面我深有感触,在我们的 App 没有良好的系统架构之前,每一个微小的改动都需要“大动干戈”。具体来说,由于强耦合性,每次改动我们都需要和各个业务部门商讨详细的技术方案;功能开发完毕后,又要协调各个部门进行功能回归测试。整个过程下来,不仅耗费太多精力和时间,还容易在跨部门、跨团队沟通之间生出许多事来。
而一套良好的系统架构,不仅仅是一款 App 的基石,也是整套代码库的规范。有了良好的系统架构,业务功能开发者就能做到有据可依,团队之间的沟通变成十分顺畅;各个功能团队之间也能并行开发,保证彼此快速迭代,提高效率。
因此,我们在推动工程化实践的同时也需要不断优化系统架构。在2017 年,我和公司同事就设计与实现了一套基于原生技术的跨平台系统架构,能让所有开发者同时在 iOS 和 Android 平台上工作。
如今这套架构经过不断改进,依然在使用。我们现在开发的 Moments App ,它所用的跨平台系统架构,正是我吸取了当初的经验与教训,使用 BFF 和 MVVM 重新架构与实现的。
这一讲,我们主要先聊聊如何使用 BFF(backend for frontend,服务于前端的后端)来设计跨平台的系统架构,以提高可重用性,进而提升开发效率。MVVM 的设计与实现,我会在后面几讲详细介绍。
为什么使用 BFF ?
我们的 Moments App 是一款类朋友圈的 App,随着功能的不断完善,目前几乎所有 App 的数据源都由多个微服务所支持。在 Moments App 中,后台微服务包括:用于用户管理与鉴权的用户服务,用于记录朋友关系的朋友关系服务,用于拉黑管理的黑名单服务,用于记录每条朋友圈信息的信息服务,用于头像管理的头像服务,用于点赞管理的点赞服务等等。
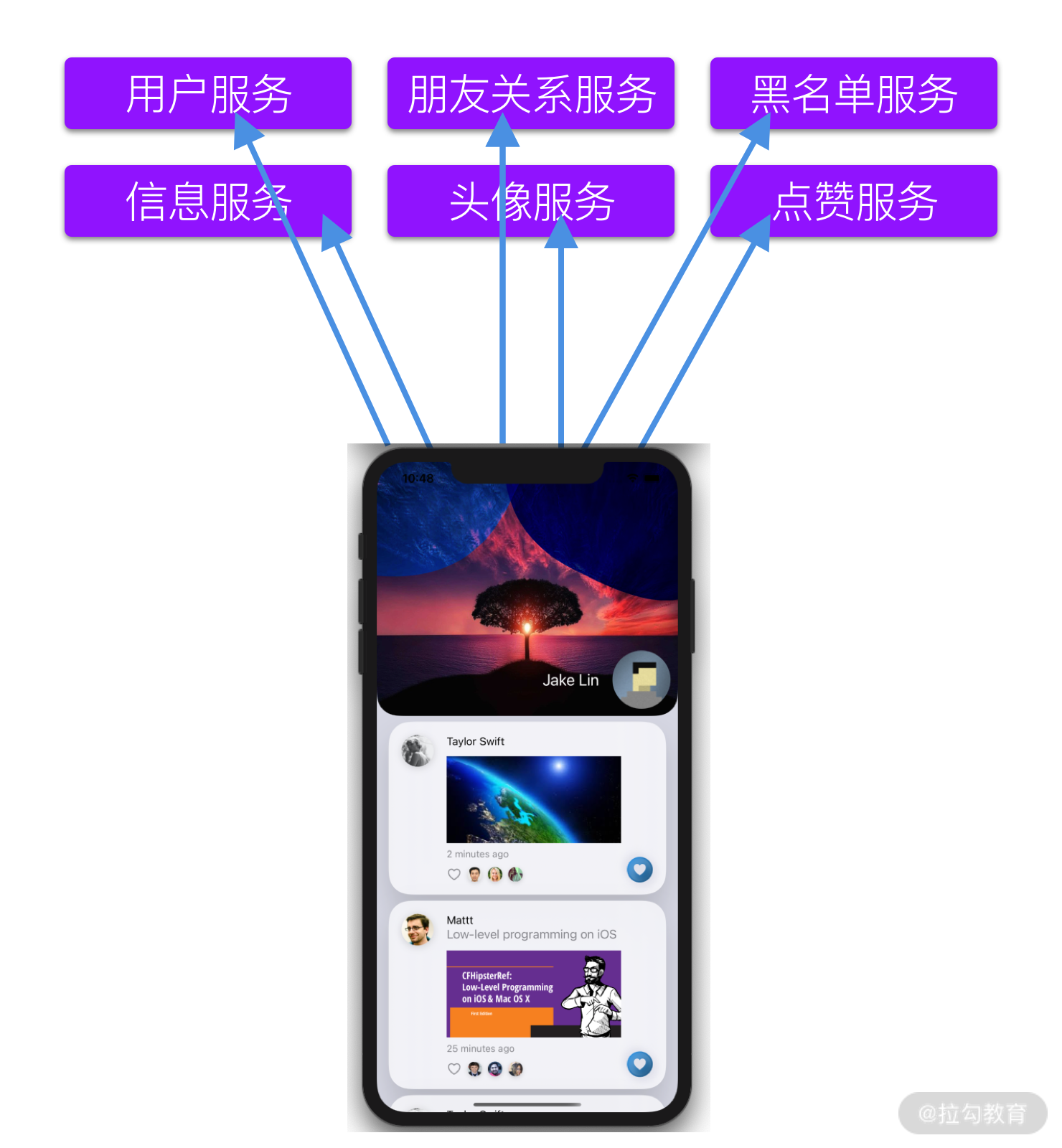
当我们需要呈现朋友圈界面时,App 需要给各个微服务发送请求,然后把返回的信息整理,合并和转换成我们所需要的信息进行呈现。
这些网络请求的顺序和逻辑非常复杂。有些请求需要串行处理,例如只有完成了用户服务的请求以后,才能继续其他请求;而有些请求却可以并行发送,比如在得到信息服务的返回结果以后,可以同时向头像服务和点赞服务发送请求。
接着,在得到了所有结果以后,App 需要整理和合并数据的逻辑也非常复杂,如果请求返回结果的顺序不一致,往往会导致程序出错。于是,为了解决这一系列的问题,我们引入了 BFF 服务。
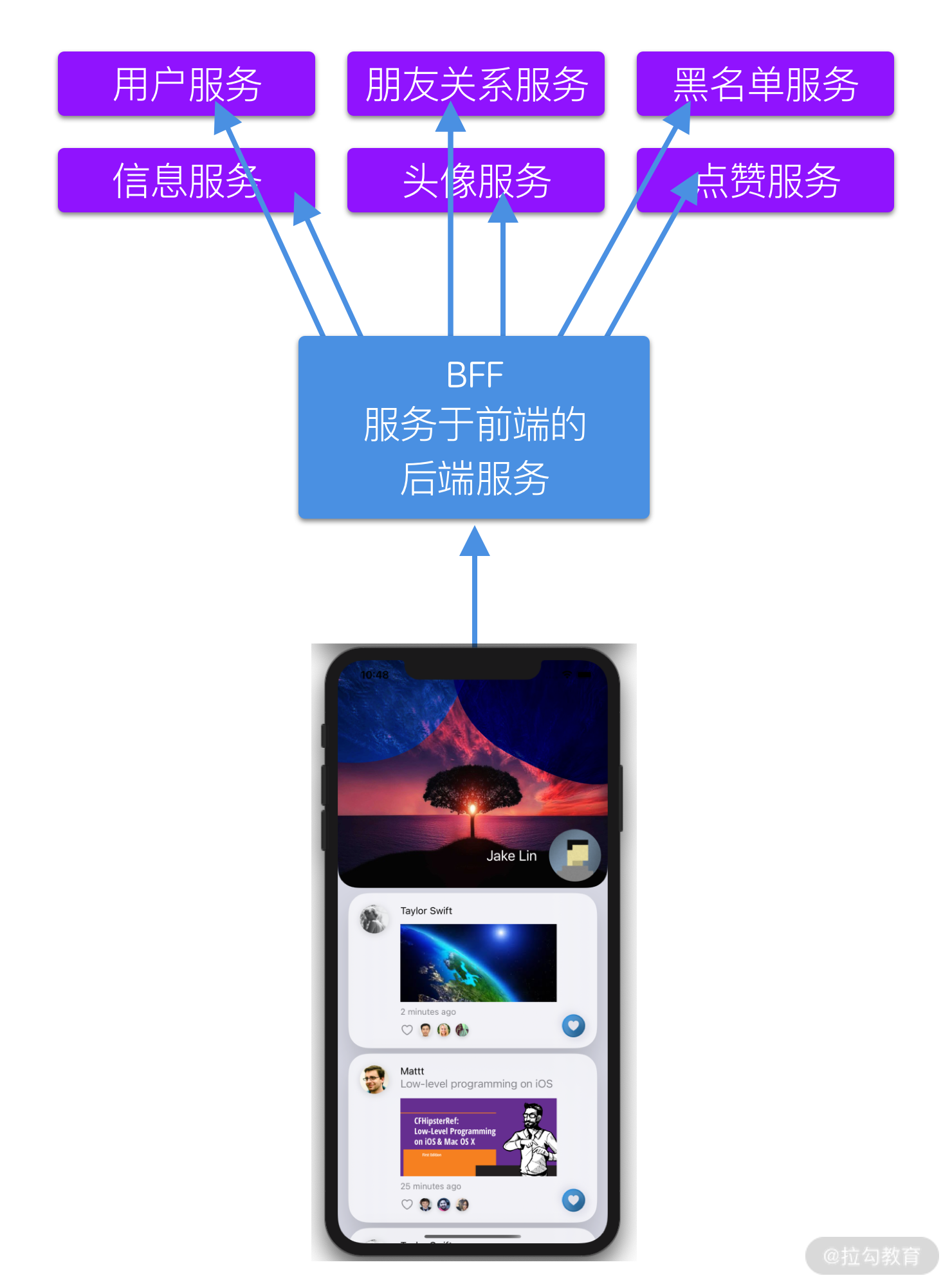
BFF 是一个服务于不同前端的后台服务,所有的前端(比如 iOS, Android 和 Web) 都依赖它。而且 BFF 是一个整合服务,它负责把前端的请求统一分发到各个具体的微服务上,然后把返回数据整合在一起统一返回给前端。
可以说,有了 BFF,我们的 App 就不再需要往多个微服务发送请求,也不再需要处理复杂的并发请求,这样就有效减低了复杂度,避免竞态条件等非预期情况发生。除此以外, 使用BFF 还有以下好处。
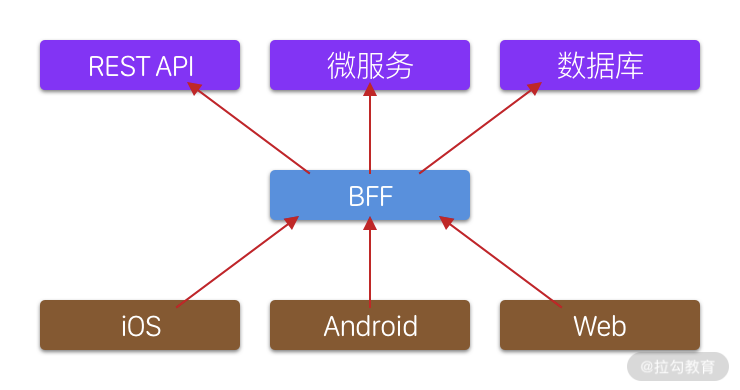
首先,App 仅需依赖一个 BFF微服务,就能有效地管理 App 对微服务的依赖。众所周知,当 App 版本发布以后,我们没有办法强迫用户更新他们设备上的 App,如果我们需要变动某个微服务的地址,原有的 App 将无法访问新的微服务地址,但是有了 BFF 以后,我们可以通过 BFF 统一路由到新的微服务去。
第二,不同的微服务可能提供不一样的数据传输方式,例如有的提供 RESI API,有的提供 gRPC,而有的提供 GraphQL。在没有 BFF 的情况下,App 端必须实现各个技术栈来访问各个微服务。一旦有了 BFF 以后,App 只需要支持一种传输方式,极大减轻移动端开发和维护成本。
第三,由于 BFF 统一处理所有的数据,iOS 和 Android 两端都可以得到由 BFF 清理并转换好的数据,无须在各端重复开发一样的数据处理代码。这极大减少了工作量,让我们可以把重心放在提高用户体验上。
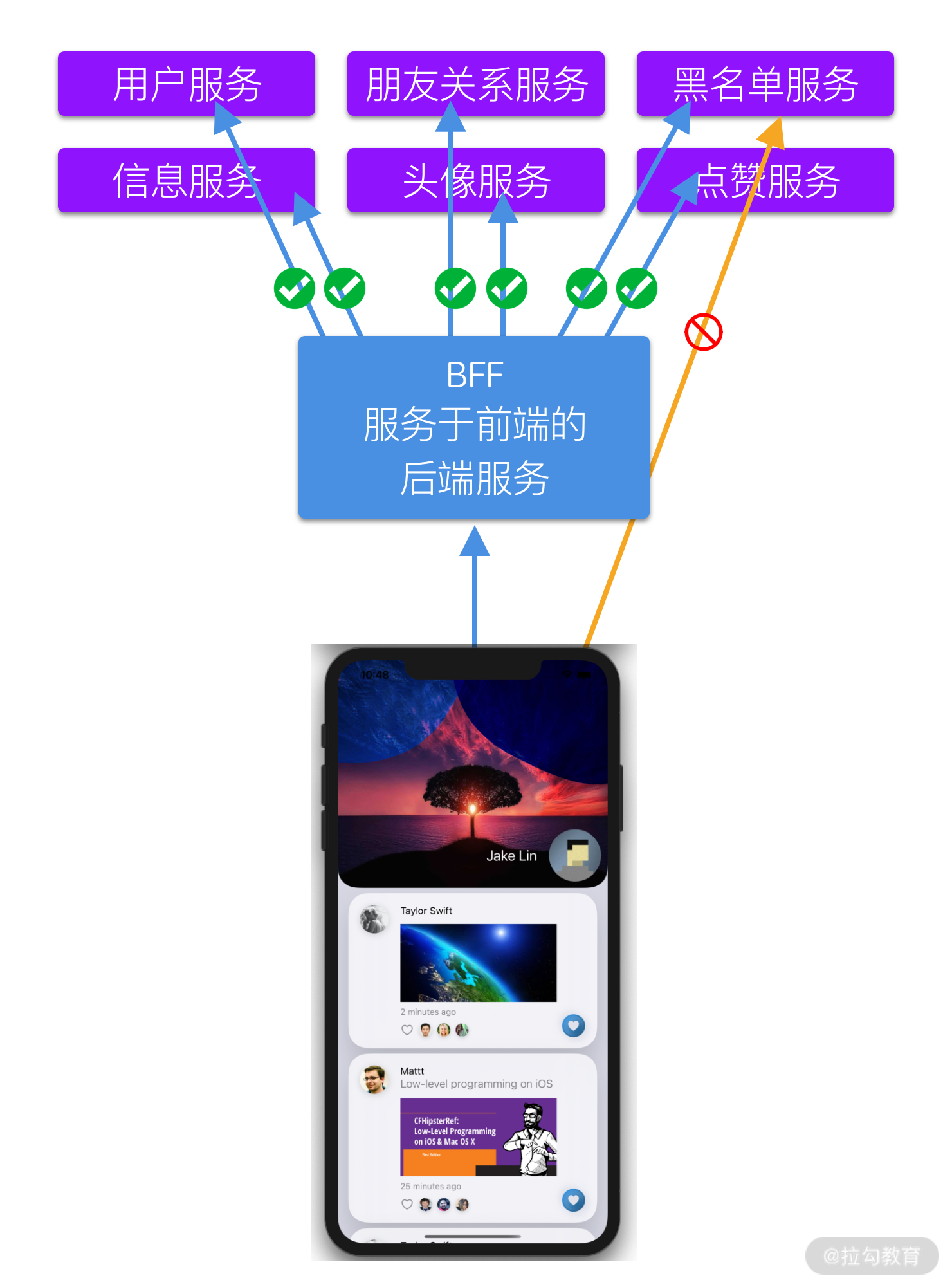
第四,BFF 在提升整套系统安全性的同时,提高整体性能。
具体来说,因为我们的 App 是通过公网连接到后台微服务的,所有微服务都需要公开给所有外部系统进行访问。这就会面临隐私信息暴露等安全问题,比如用户会通过 App 获得本来不应该公开的黑名单信息。
但我们引入 BFF 以后,可以为微服务配置安全规则(如 AWS 上的 Security Group)只允许 BFF 能访问,例如上述的黑名单管理服务,就可以设置除了 BFF 以外不允许任何其他外部系统(包括我们的 App)直接访问,从而有效保证了隐私信息与公网的隔离。
与此同时, BFF 还可以同步访问多个不同的数据源,统一管理数据缓存,这无疑能有效提升整套系统的性能。
BFF 的技术选型——GraphQL
既然 BFF 那么好用,那应该怎样实现一个 BFF 服务呢?我经过多个项目的实践总结发现,GraphQL 是目前实现 BFF 架构的最优方案。
具体来说,和 REST API,gRPC 以及 SOAP 相比, GraphQL 架构有以下几大优点。
-
GraphQL 允许客户端按自身的需要通过 Query 来请求不同数据集,而不像 REST API 和gRPC 那样每次都是返回全部数据,这样能有效减轻网络负载。
-
GraphQL能减轻为各客户端开发单独 Endpoint 的工作量。比如当我们开发 App Clip 的时候,App Clip 可以在 Query 中以指定子数据集的方式来使用和主 App 相同的 Query,而无须重新开发新 Endpoint。
-
GraphQL 服务能根据客户端的 Query 来按需请求数据源,避免无必要的数据请求,减轻服务端的负载。
下面我们以一个例子来看看GraphQL 是怎样处理不同的 Query 的。
假设我们要开发一个显示某大 V 朋友圈的 App Clip,当用户使用 App Clip 时不需要鉴权,不必查看黑名单,就直接可以看到该大 V 的朋友圈信息,那么我们在访问 GraphQL 的流程会就简化了(如下图所示)。
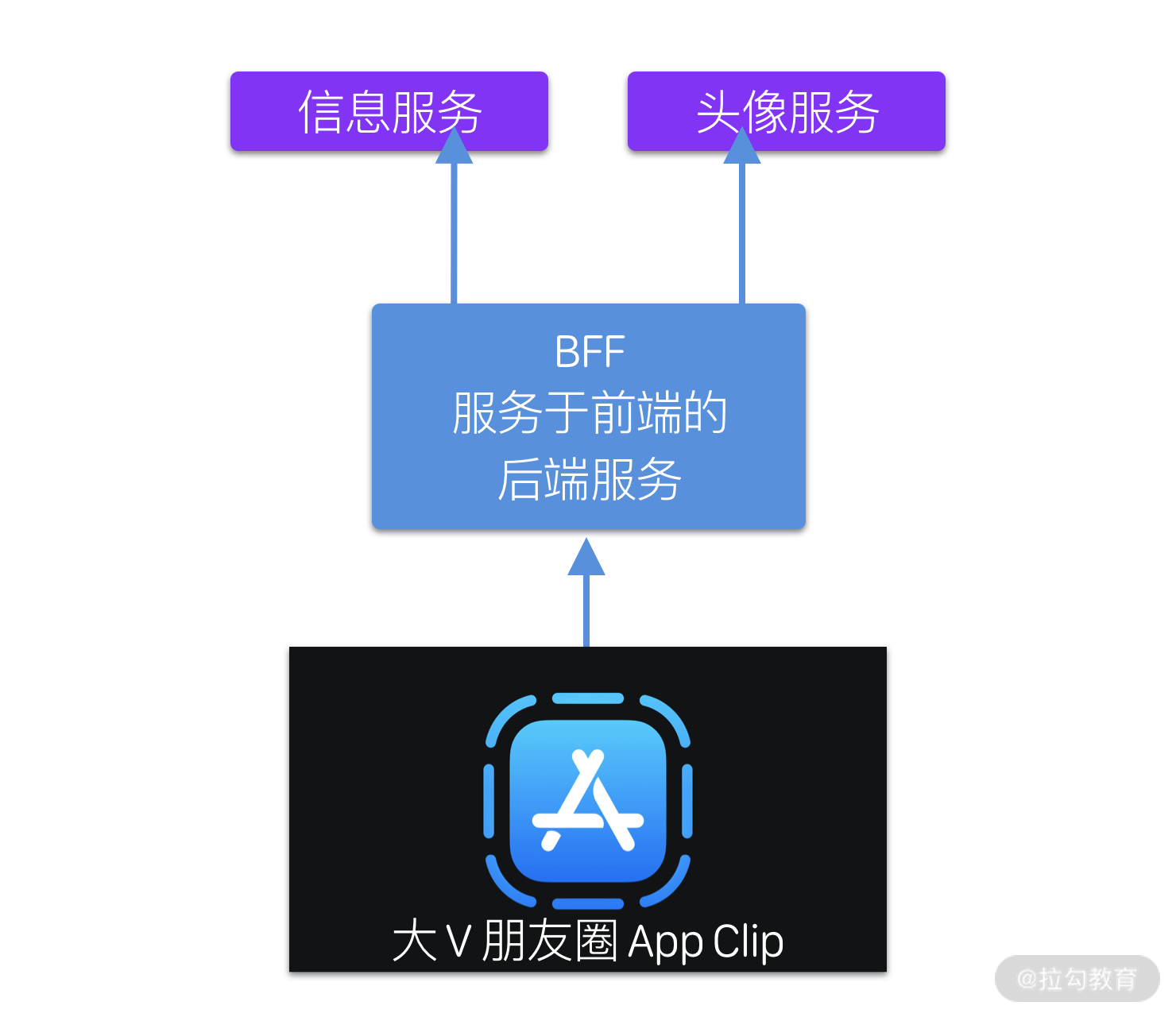
和我们的主 App 请求相比,App Clip 不需要显示点赞信息,返回的结果就可以精简了。而且由于不需要进行鉴权,也不需要查询朋友关系、黑名单和点赞等信息,BFF 也无须向这些微服务发起请求,从而有效减轻了 BFF 服务的负载。
另外一方面,和 REST API 相比,GraphQL 的数据交换都由 Schema 统一管理,能有效减少由于数据类型和可空类型不匹配所导致的问题。
除此之外,GraphQL 还能减轻版本管理的工作量。因为 GraphQL 能支持返回不同数据集,从而无须像 REST API 那样为每个新功能不断地更新 Endpoint 的版本号。
如何使用 GraphQL 实现 BFF
既然我们确定了 GraphQL,那需要选择一个服务框架来帮我们实现。具体怎么实现呢?为了方便演示,我选择了 Apollo Serve。
Apollo Serve 是基于 Node.js 的 GraphQL 服务器,目前非常流行。使用它,可以很方便地结合 Express 等 Web 服务,而且还可以部署到亚马逊 Lambda,微软 Azure Functions 等 Serverless 服务上。
再加上 Apollo Serve 在我们公司的生产环境上使用多年,一直稳定地支撑着 App 正常运行,因为比较熟悉,所以我就选了它。
下面一起看看具体怎么做。
第一步,使用 GraphQL,我们先要为前后端传递的数据定义 schema。 在这里我写了 Moment 类型的部分 Schema 定义。比如在 Moment 类型里,我定义了 id,type,title 和 user details 等属性,其中 user details 属性的类型是 User Details,它定义了 name 和 avatar 等属性。其的代码示例如下所示。
enum MomentType {
URL
PHOTOS
}
type Moment {
id: ID!
userDetails: UserDetails!
type: MomentType!
title: String # nullable
photos: [String!]! # non-nullable but can be empty
}
type UserDetails {
id: ID!
name: String!
avatar: String!
backgroundImage: String!
}
如果你想要查看完整定义,可以点击拉勾教育的仓库中查看。
GraphQL 支持枚举类型,比如上面的MomentType就是一个枚举类型,它只有两个值URL和PHOTOS,在数据传输过程中,它们是通过字符串传送给前端的。
Moment是一个类型定义,在 Swift 中可以对应成struct,而在 Kotlin 中则对应为data class。这个类型有id、userDetails等属性。这些属性可以是基础数据类型,如String、ID、Int等;也可以是自定义类型,如自定义的UserDetails。
当数据类型后面有!时,表示该属性不能为null。这其中需要注意一点,那就是!在数组定义里面的使用。比如photos: [String!]!,表示该数组不能为null,而且不能存放值为null的数据。而photos: [String!]则表示photos数组自身可能为null,但还是不能存放值为null的数据 。再来看photos: [String]!,这表示photos数组自己不可以为null, 但是可以放值为null的数据。
第二步,有了 Schema 的定义以后,接下来我们可以定义 Query 和 Mutation,以便为 App 提供查询和更新的接口。
type Query {
getMomentsDetailsByUserID(userID: ID!): MomentsDetails!
}
这表示该 GraphQL 服务提供一个名叫getMomentsDetailsByUserID的 Query,该 Query 接受userID作为入口参数,并返回MomentsDetails。
一般 Query 只能用于查询,如果要更新,则需要使用 Mutation,下面是一个 Mutation 的定义。
type Mutation {
updateMomentLike(momentID: ID!, userID: ID!, isLiked: Boolean!): MomentsDetails!
}
其实 Mutation 是一个会更新状态的 Query,因为在更新后还是可以返回数据的。例如上例中updateMomentLike接受了momentID、userID和isLiked作为入口参数,在更新状态后也可以返回MomentsDetails。
第三步,有了以上的定义以后,我们可以借助 resolver 来查询或者更新数据。
const resolvers = {
Query: {
getMomentsDetailsByUserID: (_, {userID}) => momentsDetails,
},
Mutation: {
updateMomentLike: (_, {momentID, userID, isLiked}) => {
for (const i in momentsDetails.moments) {
if (momentsDetails.moments[i].id === momentID) {
if (momentsDetails.moments[i].isLiked === isLiked) {
break
}
momentsDetails.moments[i].isLiked = isLiked;
if (isLiked) {
const likedUserDetails = getUserDetailsByID(userID)
momentsDetails.moments[i].likes.push(likedUserDetails);
} else {
// remove the item for that user
momentsDetails.moments[i].likes = momentsDetails.moments[i].likes.filter((item) => item.id !== userID);
}
break;
}
}
return momentsDetails;
}
}
};
resolvers的大致逻辑是,在 get Moments Details By User ID 查询里面,直接把 momentsDetails 的数据返回。在 update moment like 更新里面,我们更新了 momentsDetails 的 is Liked 属性来表示用户是否点赞。在 Moments App 的 BFF 中,我们维护了一个内存数据库,而在真实生产环境中,可以访问 MySQL、MongoDB 来直接存储数据,或者通过其他微服务来桥接数据库的访问。
到此为止,我们就通过 GraphQL 实现了一个 BFF。 注意,这只是一个例子,并不是每个 BFF 都必须通过 Apollo Server 以及 Node.js 来实现。你可以根据所做团队成员的技能来挑选适合你们的技术栈。
比如,Kotlin 是一个不错的选择,因为大部分 Android 开发者都熟悉 Kotlin 语言,而且 Kotlin 还可以完美兼容 JVM。特别 JVM 生态非常发达,我们可以利用 Kotlin 和基于 JVM 的开源库构建稳定的 BFF 方案。
总结
这一讲我介绍了如何使用 BFF 来设计跨平台的系统架构,以及如何使用 GraphQL 实现 BFF。虽然 GraphQL 有众多优点,但并非十全十美,甚至可以说,世界上并没有完美的技术。所以,在使用 GraphQL 过程中,我们需要注意以下两点。
-
在定义 Schema 的过程中,需要前后台开发者共同协商沟通,特别要注意
nullable类型的处理,如果前端定义有误,很容易引起 App 的崩溃。 -
GraphQL 通常使用 HTTP POST 请求,但有些 CDN (content delivery network,内容分发网络)对 POST 缓存支持不好,当我们把 GraphQL 的请求换成 GET 时,整个 Query 会变成 JSON-encoded 字符串并放在 Query String 里面进行发送。此时,要特别注意该 Query String 的长度不要超过 CDN 所支持的长度限制(比如 Akamai 支持最长的 URL 是 8892 字节),否则请求将会失败。
思考题:
在这里,我们使用 BFF 和 MVVM 来架构跨平台方案,请问你在跨平台方面,使用的是那种方案,原因是什么?
可以把回答写到下面的留言区哦。这一讲我们介绍了 BFF 服务端,从下一讲开始,我将开始介绍跨平台系统架构的另一个核心 MVVM 模式。这其中,我会先聊聊如何在iOS 移动端使用 MVVM 模式进行架构设计。
16 架构模式:为什么要选择 MVVM 模式?
作为 iOS 开发者,我们都很熟悉 MVC 模式。根据苹果官方的解释, MVC 表示 Model-View-Controller, 也就是模型、视图和控制器。但是业界一直把 MVC 戏称为 Massive ViewController(臃肿的视图控制器)。因为当我们使用 MVC 的时候,随着功能越来越丰富, ViewController 往往变得臃肿和繁杂,而且模块之间相互耦合,难以维护。下图显示了苹果的 MVC 模式。
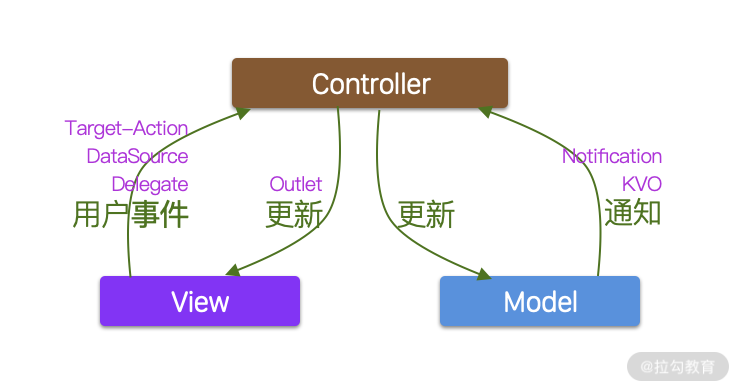
其中,Controller 通常指 ViewController ,是 MVC 的核心,ViewController 通过Target-Action、DataSource 和 Delegate 来接收来自 View 的用户事件,并通过 Outlet 来更新 View。同时 ViewController 还通过 Notification 和 KVO 来接收来自 Model 的通知,并通过变量来更新 Model。
除了与 View 和 Model 进行交互以外,ViewController 还负责导航、网络访问、数据缓存、错误处理以及 Model 对象的 Encode 和 Decode。由于 ViewController 承担多项责任,往往导致代码量极大,且由于强耦合,对 ViewController 的一点点改动都需要进行手工回归测试,费时费力。那么,有没有什么好的办法来解决这些问题呢?
MVVM 及其优点
经过多年实践证明,MVVM 模式是目前解决臃肿 ViewController 问题的有效方法。MVVM 全称 Model-View-ViewModel (模型-视图-视图模型)。与 MVC 相比,它引入了一个名叫 ViewModel 的新概念。如下图所示。
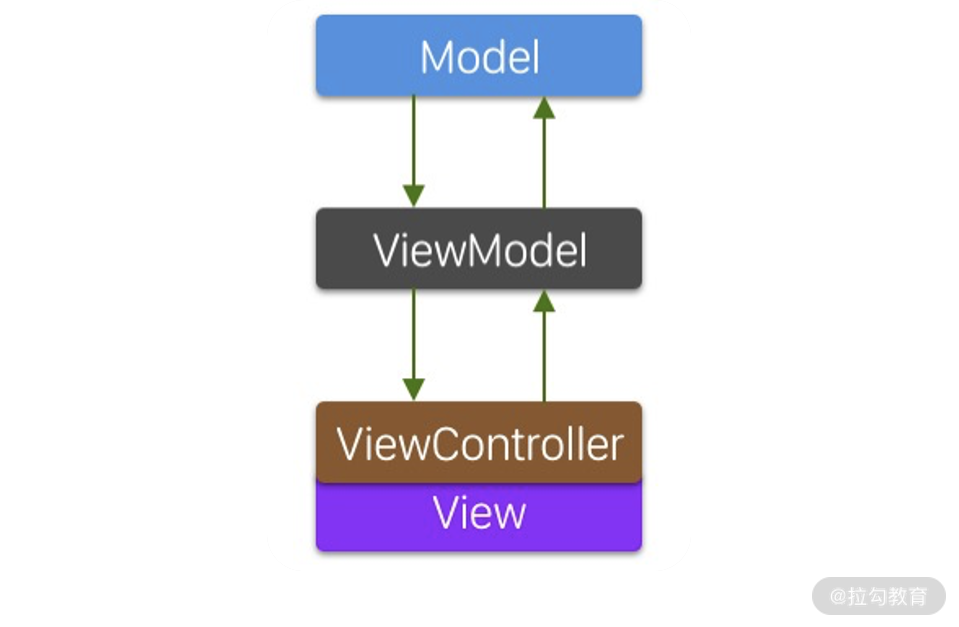
MVVM 由三层组成:
-
Model,用于保存数据的模型对象,通常定义为只有数据并没有方法的结构体(Struct);
-
View,用于呈现 UI(用户界面)并响应用户的事件,通常是 ViewController 和 View;
-
ViewModel,用于桥接 Model 和 View 两层,把 Model 转换成 View 呈现 UI 所需的数据,并把 View 层的用户输入数据更新到 Model 中。
那么,和 MVC 相比,MVVM 模式具有什么优点呢?具体有以下几个。
-
能效减低代码的复杂性,即 MVVM 模式能有效简化 ViewController 的逻辑,使得 ViewController 的代码只处理 UI 相关的逻辑。
-
能提高代码的可测试性,由于 ViewModel 明确负责 Modle 与 View 之间的数据转换,而且不负责 View 的生命周期管理,我们可以很方便地测试 ViewModel 的代码逻辑,提高代码的健壮性。
-
能够减低代码耦合性。在 MVVM 模式下,每一层都明确分工,这样可以减少代码耦合性,提高代码的可维护性和可重用性。
-
减轻移动团队的开发门槛,方便知识的共享。前两年谷歌公司为 Android 引入了一个基于 MVVM 模式的新框架 Architecture Components,使用 MVVM 模式能方便开发者同时在 iOS 和 Android 两个平台开发功能。
基于 MVVM 的架构设计
如今,经过多年的实践,我们已经能够成功地使用 MVVM 模式在 iOS 和 Android 上实现了一套风格一致的架构设计。 比如,在 Moments App 里面,我就进行了优化并重新实现了一套基于 MVVM 模式的架构,具体如下图所示:
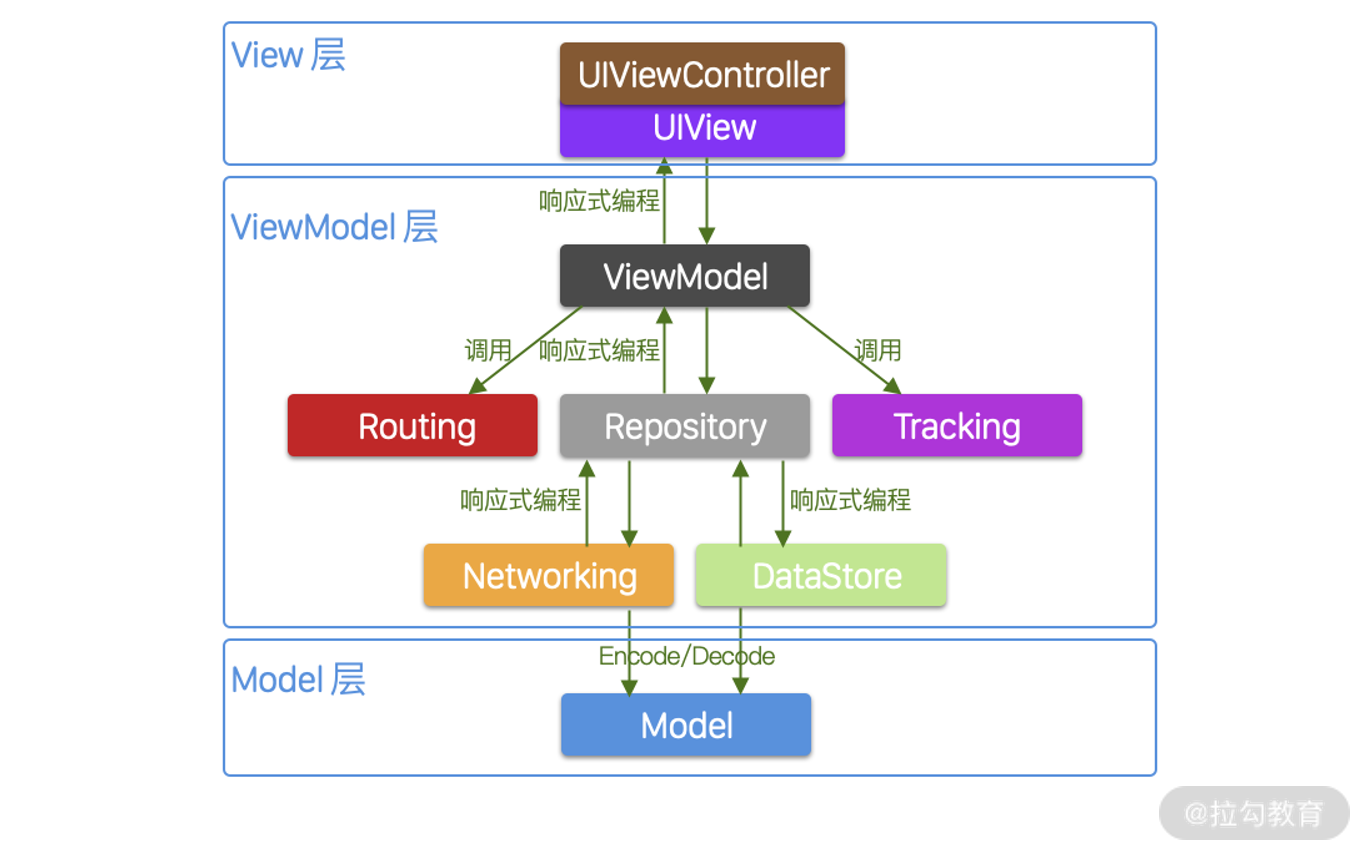
Moments App 的架构图
Moments App 的架构详解
以上是我们 Moments App 的架构图,下面我把每一层进行分解和介绍下。
View 层
View 层由UIViewController以及UIView所组成,负责呈现 UI 和响应用户事件。由于 MVVM 模式相当灵活,我们在后面第 32 讲会介绍如何在保持其他模块完全不变的情况下把 View 层换成 SwiftUI 来实现。
ViewModel 层
它是 MVVM 模式的核心,主要任务是连接 View 和 Model 层,为 View 层准备呈现 UI 所需的数据,并且响应 View 层所提供的用户事件。同时它还负责处理路由和发送用户行为数据。由于 ViewModel 层的责任还是很重,因此我们把它进一步细分为各个模块,大致包括ViewModel、Routing、Tracking、Repository、Networking、DataStore。
其中,ViewModel扮演一个协助者的角色,负责准备 View 层所需的数据,并响应 View 层的用户事件。ViewModel 与上层的UIViewController和UIView之间通过响应式编程的方式来通知对方,而上层 UI 组件通过数据绑定的方式,来监听 ViewModel 的数据变化,并及时更新 UI。
Routing是负责路由和导航的模块,ViewModel 在响应 View 的请求时(如打开新页面),会调用 Routing 模块进行导航。
Tracking则负责统计分析数据的模块,ViewModel 在响应 View 的请求时(如用户点击了点赞按钮),会调用 Tracking 模块来发送用户行为的数据。
Repository是数据层,作为唯一信息来源(Single source of truth)维护着 App 所使用的 Model 数据。当 ViewModel 需要访问数据的时候,会调用 Repository 模块,然后 Repository 会根据需要通过 Networking 来访问网络的后台数据,或者调用 DataStore 来获取本地缓存的数据。ViewModel 和 Repository 的接口也是响应式编程的方式,主要由 ViewModel 给 Repository 发起请求,然后监听 Repository 来获取数据所发生的变化。
Networking是网络层,负责访问 BFF,然后把 BFF 返回的 JSON 数据 Decode 成 Model 数据。Repository 与 Networking 的接口也是响应式编程的方式。Repository 会给 Networking 发起请求,并监听 Networking 的返回。
DataStore为数据存储层,用于把数据缓存到 App 里面使得用户在不需等待网络请求的情况下可以快速看到 UI。Repository 与 DataStore 的接口也是响应式编程的方式。Repository 监听 DataStore 的数据变化。
Model 层
最后一层是 Model 层,它比较简单,都是一些用于存放数据的模型对象,这些对象能用于存放网络请求使用的数据,也可用于存放本地缓存的数据。
朋友圈模块的架构设计
有了上述的架构设计,我就可以把 MVVM 模式应用到各个业务模块里面。比如,在这里我以 Moments App 的朋友圈模块作为例,和你介绍下它的具体的架构。下面是我为该模块所绘制的类型关系图。
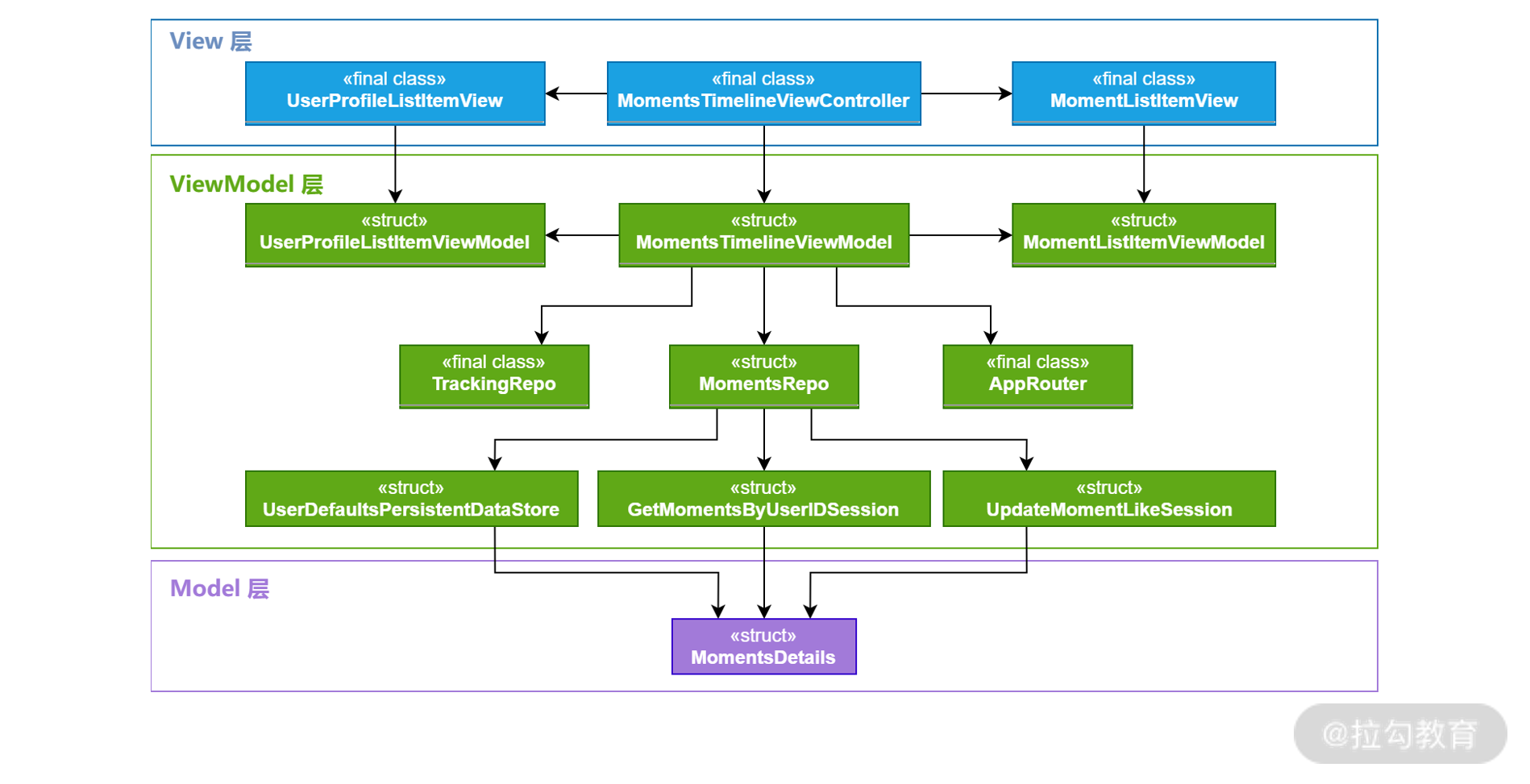
Moments App 朋友圈模块的类型关系图
View 层用于显示 UI,MomentsViewTimelineViewController用于显示朋友圈界面,这个页面里面使用了一个 TableView 来显示各种不同的 Cell。这些 Cell 都通过 UIView 来显示,其中UserProfileListItemView用于显示用户个人的信息,而MomentListItemView显示一条朋友圈的信息。
ViewModel 层由多个组件所组成。其核心是MomentsTimelineViewModel,它为MomentsViewTimelineViewController准备呈现 UI 的数据,并处理用户的事件。各个 UI 子组件也对应着各个子 ViewModel。例如UserProfileListItemView对应了UserProfileListItemViewModel。
当MomentsTimelineViewModel要发送统计分析数据的时候会调用TrackingRepo,进而把用户行为数据发送到分析数据的后台。当MomentsTimelineViewModel要导航到其他页面的时候会调用AppRouter,而AppRouter会调用路由模块来导航到相应的页面去。
当MomentsTimelineViewModel需要读取或者更新数据的时候,会给MomentsRepoo发起请求。该 Repo 负责发送网络请求并把朋友圈数据缓存到本地文件系统中。这个 Repo 还是所有朋友圈信息的数据中心,App 里面任何页面需要朋友圈信息的数据,都可以从该 Repo 中进行读取。
为了进一步解耦,我们把数据缓存和网络请求模块从 Repo 中独立出来,分成 DataStore 和 Networking 两个模块。例如当MomentsRepoo需要读写缓存的时候,会调用UserDefaultsPersistentDataStore,DataStore 模块负责把模型数据保存到UserDefaults里面。
而当MomentsRepoo需要从网络上取出朋友圈信息时会调用GetMomentsByUserIDSession。GetMomentsByUserIDSession会从 BFF 里读取当前用户所有的朋友圈信息。当MomentsRepoo需要更新朋友圈信息时(如更新点赞的状态),会调用UpdateMomentLikeSession来对 BFF 发起更新的请求。
Model 层相对比较简单,只有一个用于保存朋友圈信息的模型数据:MomentsDetails。其中UserDefaultsPersistentDataStore使用它来进行本地缓存的读取,而GetMomentsByUserIDSession和UpdateMomentLikeSession会使用它来存放网络请求的 JSON 数据。
上面就是 Moments App 基于 MVVM 模式的架构设计,我们会在后面几讲中详细介绍各个层的架构与具体实现方式。
总结
这一讲我们结合 Moments App 介绍了一套可行的 MVVM 架构模式。通过它,我们可以有效降低各个模块之间的耦合度,提高可重用性,再加上由于每个模块有了明确的责任与分工,我们在实现新功能时,也能降低沟通成本,提高开发效率。所以有关这个架构模式,你一定要重视起来哦。
另外,结合 BFF 的后端服务,我们还可以在 iOS 和 Android 两端同样使用 MVVM 模式来进行架构设计,并保持一致的代码风格,以便于开发者能同时在两个平台进行开发。
思考题
请问你们的 App 使用了怎样的架构模式?你觉得有什么优缺点可以分享给大家?
你可以把自己的思考写到下面的留言区哦,这一讲就介绍到这里,下一讲我将介绍如何使用 RxSwift 来实现响应式编程。
17 响应式编程:如何保证程序状态自动更新?
在 iOS 开发中,随着 App 功能不断增强,处理各种异步事件,保持程序状态实时更新,也变得越来越困难。
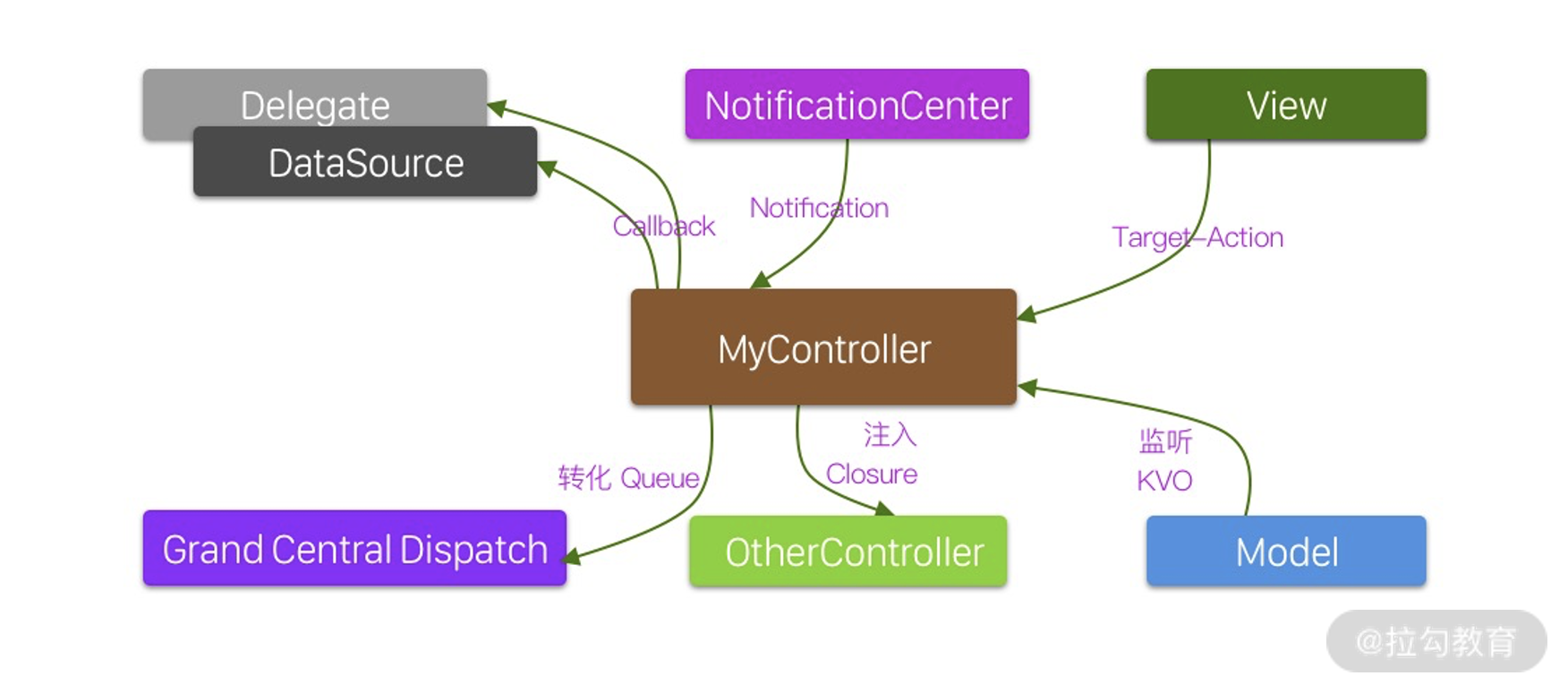
以 ViewController 来为例,我们需要处理许多异步事件,比如来自 Delegate 和 DataSource 的回调,来自 NotificationCenter 的通知消息,来自 View 的 Target-Action 事件,等等。
由于它们随机发生且可能来自不同的线程,本身就会比较复杂,再加上其他新事件的引入,代码处理的逻辑会呈指数式增长。那么,怎样才能从根本上解决这些问题呢?这一讲我们所介绍的响应式编程就可以解决。
响应式编程与 RxSwift
所谓响应式编程,就是使用异步数据流(Asynchronous data streams)进行编程。在传统的指令式编程语言里,代码不仅要告诉程序做什么,还要告诉程序什么时候做。而在响应式编程里,我们只需要处理各个事件,程序会自动响应状态的更新。而且,这些事件可以单独封装,能有效提高代码复用性并简化错误处理的逻辑。
现在,响应式编程已慢慢成为主流的编程范式,比如 Android 平台的 Architecture Components 提供了支持响应式编程的 LiveData, SwiftUI 也配套了 Combine 框架。在 Moments App 中,我采用的也是响应式编程模式。
目前比较流行的响应式编程框架有 ReactiveKit、ReactiveSwift 和 Combine。在这里,我们推荐使用RxSwift。因为 RxSwift 遵循了 ReactiveX 的 API 标准,由于 ReactiveX 提供了多种语言的实现,学会 RxSwift 能有效把知识迁移到其他平台。还有 RxSwift 项目非常活跃,也比较成熟。更重要的是,RxSwift 提供的 RxCocoa 能帮助我们为 UIKit 扩展响应式编程的能力,而 Combine 所对应的 CombineCocoa 还不成熟。
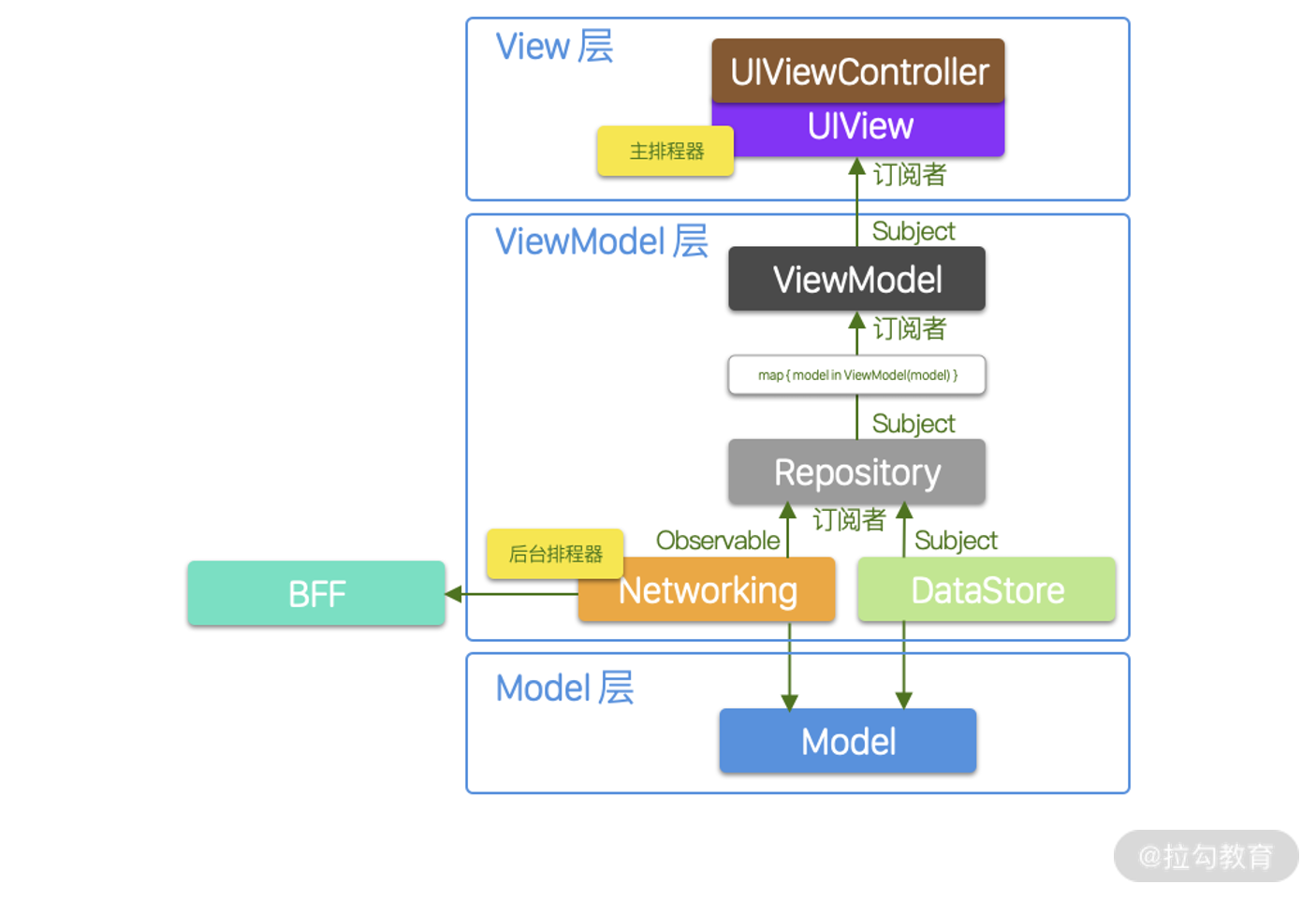
为了让 App 可以自动更新状态,我们在 Moments App 里面使用 RxSwift 把 MVVM 各层连接起来。
从上图可以看出,当用户打开朋友圈页面,App 会使用后台排程器向 BFF 发起一个网络请求,Networking 模块把返回结果通过Observable 序列发送给 Repository 模块。Repository 模块订阅接收后,把数据发送到Subject里面,然后经过map 操作符转换,原先的 Model 类型转换成了 ViewModel 类型。 ViewModel 模块订阅经过操作符转换的数据,发送给下一个Subject,之后,这个数据被 ViewController 订阅,并通过主排程器更新了 UI。
整个过程中,Repository 模块、 ViewModel模块、ViewController 都是订阅者,分别接收来自前一层的信息。就这样,当 App 得到网络返回数据时,就能自动更新每一层的状态信息,也能实时更新 UI 显示。
这其中的 Observable 序列、订阅者、Subject 、操作符、排程器属于 RxSwift 中的关键概念,它们该如何理解,如何使用呢?接下来我就一一介绍下。
异步数据序列 Observable
为了保证程序状态的同步,我们需要把各种异步事件都发送到异步数据流里,供响应式编程发挥作用。在 RxSwfit 中,异步数据流称为 Observable 序列,它表示可观察的异步数据序列,也可以理解为消息发送序列。
在实际应用中,我们通常使用 Observable 序列作为入口,把外部事件连接到响应式编程框架里面。比如在 Moments App ,我通过 Observable 把网络请求的结果连接进 MVVM 架构中。
那么怎样创建 Observable 序列呢?为方便我们生成 Observable 序列, RxSwfit 的Observable类型提供了如下几个工厂方法:
-
just方法,用于生成只有一个事件的 Observable 序列; -
of方法,生成包含多个事件的 Observable 序列; -
from方法,和of方法一样,from方法也能生成包含多个事件的 Observable 序列,但它只接受数组为入口参数。
以下是相关代码示例。
let observable1: Observable<Int> = Observable.just(1) // 序列包含 1
let observable2: Observable<Int> = Observable.of(1, 2, 3) // 序列包含 1, 2, 3
let observable3: Observable<Int> = Observable.from([1, 2, 3]) // 序列包含 1, 2, 3
let observable4: Observable<[Int]> = Observable.of([1, 2, 3]) // 序列包含 [1, 2, 3]
当你需要生成只有一个事件的 Observable 序列时,可以使用just方法,如observable1只包含了1。
当需要生成包含多个事件的 Observable 序列时,可以使用of或者from方法。它们的区别是,of接收多个参数而from只接收一个数组。如上所示,我们分别使用了of和from方法来生成observable2和observable3,它们都包含了 1、2 和 3 三个事件。
这里需要注意,of方法也能接收数组作为参数的。与from方法会拆分数组为独立元素的做法不同,of方法只是把这个数组当成唯一的事件,例如observable4只包含值为[1, 2, 3]的一个事件。
在开发当中,Observable 序列不仅仅存放数值,比如 Moments App 的异步数据流就需要存放朋友圈信息来更新 UI,Observable也支持存放任意类型的数据。像在下面的例子中,peopleObservable就存放了两条类型为Person的数据,其中 Jake 的收入是 10 而 Ken 的收入是 20。
struct Person {
let name: String
let income: Int
}
let peopleObservable = Observable.of(Person(name: "Jake", income: 10), Person(name: "Ken", income: 20))
订阅者
在响应式编程模式里,订阅者是一个重要的角色。在 Moments App 里面,上层模块都担任订阅者角色,主要订阅下层模块的 Observable 序列。那订阅者怎样才能订阅和接收数据呢?
在 RxSwift 中,订阅者可以调用Observable对象的subscribe方法来订阅。如下所示。
let observable = Observable.of(1, 2, 3)
observable.subscribe { event in
print(event)
}
订阅者调用subscribe方法订阅observable,并接收事件,当程序执行时会打印以下信息:
next(1)
next(2)
next(3)
completed
你可能会问上面的next和completed是什么呢?其实它们都是事件,用来表示异步数据流上的一条信息。RxSwift 使用了Event枚举来表示事件,定义如下。
public enum Event<Element> {
/// Next element is produced.
case next(Element)
/// Sequence terminated with an error.
case error(Swift.Error)
/// Sequence completed successfully.
case completed
}
-
.next(value: T):用于装载数据的事件。当 Observable 序列发送数据时,订阅者会收到next事件,我们可以从该事件中取出实际的数据。 -
.error(error: Error):用于装载错误事件。当发生错误的时候,Observable 序列会发出error事件并关闭该序列,订阅者一旦收到error事件后就无法接收其他事件了。 -
.completed:用于正常关闭序列的事件。当 Observable 序列发出completed事件时就会关闭自己,订阅者在收到completed事件以后就无法收到任何其他事件了。
怎么理解呢?下面我通过两个例子来介绍下。由于之前讲过的of和from等方法都不能发出error和completed事件 ,在这里我就使用了create方法来创建 Observable 序列。
首先我们看一下发送error事件的例子。
Observable<Int>.create { observer in
observer.onNext(1)
observer.onNext(2)
observer.onError(MyError.anError)
observer.onNext(3)
return Disposables.create()
}.subscribe { event in
print(event)
}
在这个例子中,我们调用了create方法来生成一个 Observable 序列,该 Observable 发出next(1)、next(2)、error和next(3)事件。由于next(3)事件在错误事件之后,因此订阅者无法接收到next(3)事件。程序执行时会打印下面的日志。
next(1)
next(2)
error(anError)
接着我们看一下发送completed事件的例子。
Observable<Int>.create { observer in
observer.onNext(1)
observer.onCompleted()
observer.onNext(2)
observer.onNext(3)
return Disposables.create()
}.subscribe { event in
print(event)
}
在这里,我调用create方法来生成一个 Observable 序列,该 Observable 发出了next(1)、completed、next(2)和next(3)事件。因为next(2)和next(3)都在完成事件之后发出的,所以订阅者也无法接收它们,程序执行时会打印如下的日志。
next(1)
completed
在现实生活中,当我们订阅了报刊时可以自己选择退订,却无法让发行方停刊。在 RxSwift 里面也一样,订阅者无法强行让 Observable 序列发出completed事件来关闭数据流。那订阅者该怎样取消订阅呢?
如果你仔细观察就会发现,subscribe方法返回的类型为Disposable的对象,我们可以通过调用该对象的dispose方法来取消订阅。
为了更好地理解dispose方法的作用和触发时机,我通过subscribe()方法来打印出各个事件,如下所示。
let disposable = Observable.of(1, 2).subscribe { element in
print(element) // next event
} onError: { error in
print(error)
} onCompleted: {
print("Completed")
} onDisposed: {
print("Disposed")
}
disposable.dispose()
我们在onNext闭包里面处理next事件;在onError闭包里处理error事件;在onCompleted闭包里处理completed事件;而在onDisposed闭包里处理退订事件。
在这里,我们调用subscribe方法后,它又马上调用了dispose方法,因此程序会在调用onCompleted之后立刻调用onDisposed。其执行效果如下:
1
2
Completed
Disposed
假如我在订阅前调用delay方法,那么所有的事件都会延时两秒钟后才通知订阅者,代码如下:
let disposableWithDelay = Observable.of(1, 2).delay(.seconds(2), scheduler: MainScheduler.instance).subscribe { element in
print(element) // next event
} onError: { error in
print(error)
} onCompleted: {
print("Completed")
} onDisposed: {
print("Disposed")
}
disposableWithDelay.dispose()
和上面没有延时的例子一样,我们在调用subscribe方法以后马上调用了dispose方法,由于 Observable 序列上所有事件还在延时等待中,程序会直接调用onDisposed并退订了disposableWithDelay序列,因此没办法再收到两秒钟后所发出的next(1)、next(2)和completed事件了。 其执行效果如下:
Disposed
在很多时候,订阅后马上退订并不是我们想要的结果,我们希望订阅者一直监听事件直到自身消亡的时候才取消订阅。那有什么好的办法能做到这一点呢?
RxSwift 为我们提供了DisposeBag类型,方便存放和管理各个Disposable对象。其用法也非常简单,只需调用Disposable的disposed(by:)方法即可。代码如下:
let disposeBag: DisposeBag = .init()
Observable.just(1).subscribe { event in
print(event)
}.disposed(by: disposeBag)
Observable.of("a", "b").subscribe { event in
print(event)
}.disposed(by: disposeBag)
代码中的disposeBag存放了两个Disposable对象。当订阅者调用其deinit方法时,同时也会调用disposeBag的deinit方法。在这时候,disposeBag会取出存放的所有Disposable对象,并调用它们的dispose方法来取消所有订阅。
在实际情况下,我建议只需为一个订阅者定义一个disposeBag即可。例如 Repository 模块同时订阅了 Networking 模块和 DataStore 模块,但它只定义了一个disposeBag来管理所有的订阅。
事件中转 Subject
以上是如何生成、订阅和退订 Observable 序列。使用Observable的工厂方法所生成的对象都是“只读”,一旦生成,就无法添加新的事件。但很多时候,我们需要往 Observable 序列增加事件,比如要把用户点击 UI 的事件添加到 Observable 中,或者把底层模块的事件加工并添加到上层模块的序列中。
那么,有什么好办法能为异步数据序列添加新的事件呢?RxSwift 为我们提供的 Subject 及其onNext方法可以完成这项操作。
具体来说,Subject作为一种特殊的 Observable 序列,它既能接收又能发送,我们一般用它来做事件的中转。在 Moments App 的 MVVM 架构里面,我们就大量使用 Subject 发挥这一作用。 比如,当 Repository 模块从 Networking 模块中接收到事件时,会把该事件转送到自身的 Subject 来通知 ViewModel,从而保证 ViewModel 的状态同步。
那么,都有哪些常见的 Subject 呢?一般有 PublishSubject、BehaviorSubject 和 ReplaySubject。它们的区别在于订阅者能否收到订阅前的事件。
-
PublishSubject:如果你想订阅者只收到订阅后的事件,可以使用 PublishSubject。
-
BehaviorSubject:如果你想订阅者在订阅时能收到订阅前最后一条事件,可以使用 BehaviorSubject。
-
ReplaySubject:如果你想订阅者在订阅
的时候能收到订阅前的 N 条事件,那么可以使用 ReplaySubject。
在订阅以后,它们的行为都是一致的,当 Subject 发出error或者completed事件以后,订阅者将无法接收到新的事件。与之相关的详细的内容,我会在第 19 讲数据层架构里展开介绍。
操作符
操作符(Operator)是 RxSwift 另外一个重要的概念,它能帮助订阅者在接收事件之前把 Observable 序列中的事件进行过滤、转换或者合并。
例如在 Moments App 里面,我们使用 map 操作符把 Model 数据转换成 ViewModel 类型来更新 UI。这里的 map 操作符就属于转换操作符,能帮助我们从一种数据类型转变成另外一种类型。除了map ,compactMap 和 flapMap 也属于转换操作符。
此外还有 filter 和 distinctUntilChanged等过滤操作符,我们可以使用过滤操作符把订阅者不关心的事件给过滤掉。还有合并操作符如 startWith,concat,merge,combineLatest 和 zip,可用于组装与合并多个 Observable 序列。
除了上面提到过的常用操作符,RxSwift 还为我们提供了 50 多个操作符,那怎样才能学会它们呢?我推荐你到 rxmarbles.com 或者到 App Store 下载 RxMarbles App,然后打开各个操作符并修改里面的参数,通过输入的事件和执行的结果来理解这些操作的作用。在之后的第 20 讲,我也会详细介绍一些常用的操作符的用法,到时候可以留意哦。
排程器
保持程序状态自动更新之所以困难,很大原因在于处理并发的异步事件是一件烦琐的事情。为了方便处理来自不同线程的并发异步事件,RxSwift 为我们提供了排程器。它可以帮我们把繁重的任务调度到后台排程器完成,并能指定其运行方式(如是串行还是并发),也能保证 UI 的任务都在主线程上执行。
比如在 Moments App 里面,Networking 和 DataStore 模块都在后台排程器上执行,而 View 模块都在主排程器上执行。
根据串行或者并发来归类,我们可以把排程器分成两大类串行的排程器和并发的排程器。
串行的排程器包括 CurrentThreadScheduler、MainScheduler、SerialDispatchQueueScheduler。
其中,CurrentThreadScheduler可以把任务安排在当前的线程上执行,这是默认的排程器。当我们不指定排程器的时候,RxSwift 都会使用 CurrentThreadScheduler 把任务放在当前线程里串行执行;MainScheduler是把任务调度到主线程MainThread里并马上执行,它主要用于执行 UI 相关的任务;而SerialDispatchQueueScheduler则会把任务放在dispatch_queue_t里面并串行执行。
并发的排程器包括 ConcurrentDispatchQueueScheduler 和 OperationQueueScheduler。
其中,ConcurrentDispatchQueueScheduler把任务安排到dispatch_queue_t里面,且以并发的方式执行。该排程器一般用于执行后台任务,例如网络访问和数据缓存等等。在创建的时候,我们可以指定DispatchQueue的类型,例如使用ConcurrentDispatchQueueScheduler(qos: .background)来指定使用后台线程执行任务。
OperationQueueScheduler是把任务放在NSOperationQueue里面,以并发的方式执行。这个排程器一般用于执行繁重的后台任务,并通过设置maxConcurrentOperationCount来控制所执行并发任务的最大数量。它可以用于下载大文件。
那么,如何用排程器进行调度,处理好不同线程的并发异步事件呢?请看下面的代码实现。
Observable.of(1, 2, 3, 4)
.subscribeOn(ConcurrentDispatchQueueScheduler(qos: .background))
.dumpObservable()
.map { "\(getThreadName()): \($0)" }
.observeOn(MainScheduler.instance)
.dumpObserver()
.disposed(by: disposeBag)
首先我们传入ConcurrentDispatchQueueScheduler(qos: .background)来调用subscribeOn方法,把 Observable 序列发出事件的执行代码都调度到后台排程器去执行。然后通过传入MainScheduler.instance来调用observeOn,把订阅者执行的逻辑都调度主排程器去执行。
这是一种常用的模式,我们通常使用后台排程器来进行网络访问并处理返回数据,然后通过主排程器把数据呈现到 UI 中去。
由于后台线程不能保证执行的顺序,其执行效果如下,当你执行的时候可能会有点变化。
[Observable] 1 emitted on Unnamed Thread
[Observable] 2 emitted on Unnamed Thread
[Observer] Unnamed Thread: 1 received on Main Thread
[Observable] 3 emitted on Unnamed Thread
[Observer] Unnamed Thread: 2 received on Main Thread
[Observable] 4 emitted on Unnamed Thread
[Observer] Unnamed Thread: 3 received on Main Thread
[Observer] Unnamed Thread: 4 received on Main Thread
总结
在这一讲中我们介绍了 RxSwift 的五个关键概念:Observable 序列、订阅者、Subject、操作符以及排程器。我把本讲的代码都放在 Moments App 项目中的RxSwift Playground 文件里面,希望你能多练习,把五个概念融会贯通。
以下是我在实际工作中使用 RxSwift 的一些经验总结,希望能帮助到你。
-
当我们拿到需求的时候,先把任务进行分解,找出哪个部分是事件发布者,哪部分是事件订阅者,例如一个新功能页面,网络请求部分一般是事件发布者,当得到网络请求的返回结果时会发出事件,而 UI 部分一般为事件订阅者,通过订阅事件来保持 UI 的自动更新。
-
找到事件发布者以后,要分析事件发布的频率与间隔。如果只是发布一次,可以使用Obervable;如果需要多次发布,可以使用Subject;如果需要缓存之前多个事件,可以使用 ReplaySubject。
-
当我们有了事件发布者和订阅者以后,接着可以分析发送和订阅事件的类型差异,选择合适的操作符来进行转换。我们可以先使用本讲中提到的常用操作符,如果它们还不能解决你的问题,可以查看 RxMarbles 来寻找合适的操作符。
-
最后,我们可以根据事件发布者和订阅者所执行的任务性质,通过排程器进行调度。例如把网络请求和数据缓存任务都安排在后台排程器,而 UI 更新任务放在主排程器。
我在后面几讲中会详细介绍如何把 RxSwift 应用到在 MVVM 架构来保证程序状态信息的自动更新。希望能帮助你把今天所学知识灵活应用到真实场景中。
思考题
据我所知,很多 iOS 开发者都想学习响应式编程和 RxSwift,但也不少人最终放弃了,如何你也曾经学习过并放弃了,请分享一下你的经验,哪一部分使你放弃学习和使用 RxSwift 呢?
可以把你的想法写得留言区哦,下一讲我将介绍如何设计网络访问与 JSON 数据解析。
源码地址:
RxSwift Playground 文件地址:https://github.com/lagoueduCol/iOS-linyongjian/blob/main/Playgrounds/RxSwiftPlayground.playground/Contents.swift

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)