Python的字符编码
之前一直以为unicode和utf8是对等的,现在才发现utf8算是unicode的中间状态。在学习网页爬虫时,理解网页数据传输的编码机制是一个基础,不然搞不懂报错
编码的发展
ASCII字符集
最早的编码机制,由8bit(8位二进制)作为一个字节(byte),一共规定了128个字符和8位二进制数字的对应编码。
GB2312字符集
为兼容庞大的中国汉字开发的字符集,由16bit(16位二进制)即二个字节组成一个数字表示一个特定字符,足够表示256x256=65536个字符。
Unicode字符集
足够兼容所有的字符,属于全世界通用的字符集,是32bit,四个字节表示一个特定字符,我们看到的str类型就是Unicode字符集
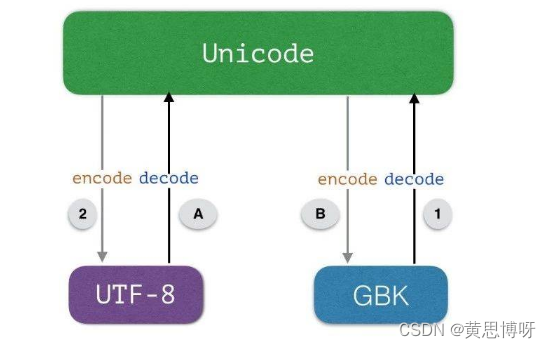
UTF-8字符集或GBK字符集

是对Unicode字符集的再次编码,目的是减小Unicode带来的空间浪费问题,实现表示字符的特定二进制数字长度可变。进行数据传送的就是UTF-8字符集或是GBK字符集
Python中的字符串的编码类型和转换
1.类型为str字符串,属于Unicode编码
一般状况下,python默认的编码类型是Unicode,查看字符类型为“str” :
>>> word="世界和平"
>>> print(type(word))
<class 'str'>2.类型为byte字符串,是对Unicode编码的二进制数据进行再次编码,常见的是UTF-8、GBK
利用encode()将Unicode编码的str类型编码为用UTF-8表示的byte类型:
>>> word_=word.encode("utf-8")
>>> print(word_)
b'\xe4\xb8\x96\xe7\x95\x8c\xe5\x92\x8c\xe5\xb9\xb3'
>>> print(type(word_))
<class 'bytes'>
#\xe4是一个两位的16进制字节,\x是算一个标准吧,在utf8里一个中文字符由3个字节表示利用encode()将Unicode编码的str类型编码为用GBK字符集表示的byte类型:
>>> word_=word.encode("GBK")
>>> print(word)
世界和平
>>> print(word_)
b'\xca\xc0\xbd\xe7\xba\xcd\xc6\xbd'
#在GBK的编码中,2个字节表示一个中文字符常见的一个报错:用GBK对unicode字符进行编码传输后,却用UTF8进行解码为unicode字符:
>>> word_=word.encode("GBK")
>>> word_.decode("utf8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 0: invalid continuation byte
>>>不能对str类型进行解码,但是可以查看其对应的Unicode字符集的2进制数字:
#ord()函数转换为对应的十进制的字符集编码:
>>> print(ord("世"))
19990
#bin()函数转为二进制:
>>> bin(19990)
'0b100111000010110' #前面的0b是二进制数字的标记将UTF-8编码的byte类型字符“\xe4\xb8\x96”转化为2进制:
str_=""
list_=["e4","b8","96"]
for i in list_:
i_=bin(int(i,16))
i__=i_.replace("0b","")
str_+=i__
print(str_)
"111001001011100010010110"比较字符“世”的UTF-8编码和Unicode编码二进制数值的区别:
#Unicode:
" 0100 111000 010110"
#utf-8:
"11100100 10111000 10010110""世"是由三个字符组成,在UTF8的编码规则中,n个字节(n>1)组成的二进制,第1个字节的前n个数字规定为1,第n+1个数字规定为0,其他的字节前两位数是10(......)
和爬虫有关的字符问题
解码方式和响应体编码方式不同出现的报错:
在爬虫过程中,查看响应体自身头部要求的编码格式:
print(response.encoding)
'ISO-8859-1'在默认下,爬虫用UTF8作为响应体字符的编码格式,而传输过来的byte类型响应体是根据头部编码信息(可由response.encoding返回)要求进行编码,如上,要是返回“ISO-8859-1”就会出现冲突,就会报错。
解决:告诉python响应体的编码格式:
response=requests.get(link)
response.encoding="GB2312"报错:illegal multibyte sequence,在一些字符串中混入了非法字符,会直接导致爬虫报错:
解决,用decode()进行解码,添加“ignore”参数忽略非法字符:
#直接获取响应体未解码的字节数据:
byte_datas=response.content
#添加ignore忽略非法字符:
str_datas=byte_datas.decode("GBK","ignore")
网页用gzip进行压缩出现中文乱码的解决
一些网页会对发送的响应体进行压缩,提高发送速度,比如新浪,常见的压缩方式是gzip、deflate
import requests
r=requests.get("https:\\www.sina.com.cn\")
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4533.400"}
print(r.text)若是用get()获取响应体r后,print(r.text)得到的会是一些中文乱码

幸运的是r.content可以直接解开gzip或deflate的压缩,得到其byte类型数据:
print(r.content)用chardet根据byte类型数据查看编码方式:
1.安装
pip install chardet --target=C://xx/xx/site-packages2.查看编码格式
import chardet
print(chardet.detect(r.content))
利用decode()进行解码:
bytes=r.content
strings=bytes.decode("utf8")
print(strings)
参考书籍:python网络爬虫从入门到实践 编者 唐松

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)