mediapipe实现实时动作检测【python版本】
mediapipe【BlazePose】实现动作检测
mediapipe实现实时动作检测
前言
MediaPipe为直播和流媒体提供跨平台、可定制的机器学习(MachineLearning) 解决方案。利用mediapipe和python可以实现以下功能:
- MediaPipe Face Detection 人脸检测
- MediaPipe Face Mesh 人脸三维关键点(468个)检测
- MediaPipe Hands 手部关键点检测
- MediaPipe Holistic 人体识别
- MediaPipe Objectron 物体识别
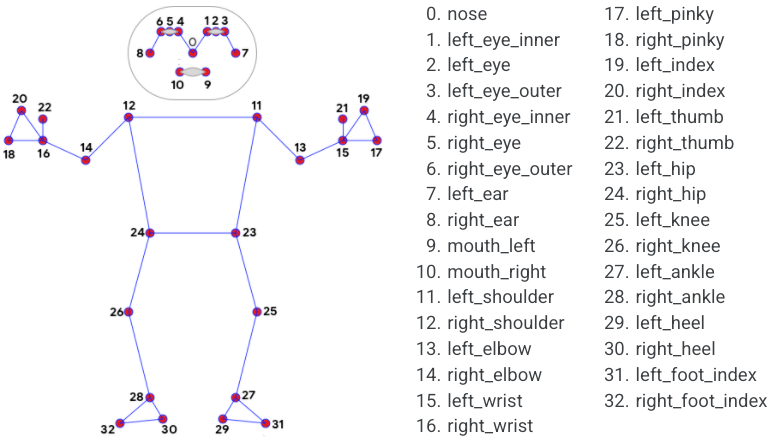
- MediaPipe Pose 人体动作姿态识别
- MediaPipe Selfie Segmentation 自拍分割
本文代码运行环境:win10,python3.7,pycharm,mediapipe 0.8.10,
涉及到的Python库为:opencv-python,mediapipe,matplotlib
安装opencv-python
在python中使用pip install指令安装库很简单,由于包比较大所以使用豆瓣源安装
pip install opencv-python -i https://pypi.douban.com/simple/
调用opencv相关函数时导入的包为:
import cv2 as cv
对于使用pycharm导入cv2之后没有代码提示的问题,可以参考此文章
解决Opencv / cv2没有代码提示的问题
安装mediapipe
pip install mediapipe -i https://pypi.douban.com/simple/
可能遇到的错误
- 包的版本问题

报错是因为protobuf这个包的版本太高了导致不兼容,卸载重装低版本的就行
pip uninstall protobuf
pip install protobuf==3.19.0
- 第一次运行mediapipe代码可能需要下载模型
第一次运行mediapipe 代码的时候 有时候会下载模型,但是有时候因为网络问题,可能下载不下来,报错:
Downloading model to D:\anaconda\envs\virtual_mediapipe\lib\site-packages\mediapipe/modules/pose_landmark/pose_landmark_heavy.tflite
TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连 接尝试失败。
[ WARN:0] global C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-_xlv4eex\opencv\modules\videoio\src\cap_msmf.cpp (438) `anonymous-namespace'::SourceReaderCB::~SourceReaderCB terminating async callback
可以去github或gitee上下载对应的包
https://github.com/google/mediapipe/tree/master/mediapipe/modules/pose_landmark
https://gitee.com/mirrors/mediapipe/tree/master/mediapipe/modules/pose_landmark
输出信息中写了 他会把需要的包下载到什么文件夹:
Downloading model to D:\anaconda\envs\virtual_mediapipe \lib\sitepackages\mediapipe/modules/pose_landmark/pose_landmark_heavy.tflite
比如这个模型:pose_landmark_heavy.tflite

把对应文件下载下来后复制粘贴到这个文件夹就解决了

接下来就可以愉快的使用mediapipe了
补充(2022-9-19):

由于开发者说他们在0.8.11版本以后已经不在把.tflite这样的比较大的二进制文件放在github上存储了,而是让程序从Google Cloud Storage上下载,所以国内一般会报错。考虑到找这这个文件比较麻烦,如果需要这两个文件的同志可以到这里下载:https://wwp.lanzoup.com/iDEQ70byj22j

如果是运行上述七种功能中的其他几种(比如MediaPipe Face Detection、MediaPipe Face Mesh、MediaPipe Hands等)也遇到类似缺少模型但又因网络问题无法下载的情况,可以前往github上找到开发者之前发布(releases)的mediapipe(比如0.8.10.12及其之前)的版本下载下来,这里面也仍然还保留有所有需要的.tflite文件。链接:https://github.com/google/mediapipe/releases

0.8.10.12及其之前的版本达到了266MB,如果github下载慢的话,这里也提供一个123网盘的下载链接:https://www.123pan.com/s/XuubVv-jFmvd.html
先来实现单张图片的人体关键点检测检测
import cv2 as cv
import mediapipe as mp
import matplotlib.pyplot as plt
# 定义可视化图像函数
def look_img(img):
# opencv读入图像格式为BGR,matplotlib可视化格式为RGB,因此需要将BGR转为RGB
img_rgb = cv.cvtColor(img, cv.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plt.show()
# 导入solution
mp_pose = mp.solutions.pose
# 导入绘图函数
mp_drawing = mp.solutions.drawing_utils
# 导入模型
pose = mp_pose.Pose(static_image_mode=True, # 是静态图片还是连续视频帧
model_complexity=2, # 选择人体姿态关键点检测模型,0性能差但快,2性能好但慢,1介于两者之间
smooth_landmarks=True, # 是否平滑关键点
enable_segmentation=True, # 是否人体抠图
min_detection_confidence=0.5, # 置信度阈值
min_tracking_confidence=0.5 # 追踪阈值
)
# 读入图像
img = cv.imread('2.png')
# BGR转RGB
img_RGB = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# 将图像输入模型,获取预测结果
results = pose.process(img_RGB)
# 可视化结果
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
look_img(img)
# 在三维真实物理坐标系中以米为单位可视化人体关键点
mp_drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
原图是这样的

经过关键点识别之后是这样的

三维人体图像是这样的,由于第三个维度是预测出来的,所以有时候不是很准确。

实现视频实时动作检测
会了单张图像检测后,视频检测就非常简单了。
视频就是由连续的一帧一帧图像组成的,摄像头实时获取的视频也不例外,只需要调用cv2(opencv)里的视频捕捉函数一帧一帧读取图像就可以了。
import cv2 as cv
import mediapipe as mp
# 导入solution
mp_pose = mp.solutions.pose
# 导入绘图函数
mp_drawing = mp.solutions.drawing_utils
# 导入模型
pose = mp_pose.Pose(static_image_mode=True, # 是静态图片还是连续视频帧
model_complexity=2, # 选择人体姿态关键点检测模型,0性能差但快,2性能好但慢,1介于两者之间
smooth_landmarks=True, # 是否平滑关键点
enable_segmentation=True, # 是否人体抠图
min_detection_confidence=0.5, # 置信度阈值
min_tracking_confidence=0.5 # 追踪阈值
)
# 处理单帧的函数
def process_frame(img):
img_rgb = cv.cvtColor(img, cv.COLOR_BGR2RGB)
results = pose.process(img_rgb)
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
return img
# 读取视频帧的函数
def process_cap(cap, gap):
while cap.isOpened():
# 读视频帧
ret, frame = cap.read()
if ret: # 判断是否读取成功
# 如果读取成功则处理该帧
frame = process_frame(frame)
# 展示处理后的三通道图像
cv.imshow('video', frame)
# 按键盘的esc或者q退出
if cv.waitKey(gap) in [ord('q'), 27]:
break
else:
# print('error!')
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv.destroyAllWindows()
# 从摄像头实时检测
def detect_camera():
# 创建窗口
cv.namedWindow('video', cv.WINDOW_NORMAL)
# 调用摄像头获取画面 0是windows系统下默认的摄像头,1是Mac系统
cap = cv.VideoCapture(0)
process_cap(cap, 1)
# 从本地导入视频检测
def detect_video(path):
# 创建窗口
cv.namedWindow('video', cv.WINDOW_NORMAL)
# 从本地读取视频
cap = cv.VideoCapture(path)
# 获取原视频帧率
fps = cap.get(cv.CAP_PROP_FPS)
# 获取原视频窗口大小
width = int(cap.get(cv.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv.CAP_PROP_FRAME_HEIGHT))
# print(fps)
# 视频两帧之间的播放间隔,单位为毫秒
gap = int(1000 / fps)
cv.resizeWindow('video',width,height)
process_cap(cap, gap)
if __name__ == '__main__':
while True:
menu = int(input('请选择检测模式:1. 打开摄像头检测\t2. 从本地导入视频检测\t3. 退出\n'))
if menu == 1:
detect_camera()
break
elif menu == 2:
path = input('请输入视频路径(例如:D:\\download\\abc.mp4):\n')
detect_video(path)
break
elif menu == 3:
break
else:
print("输入错误,请重新输入!")
continue

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)