
最全python爬虫库安装详解
一、请求库的安装1、requests 的安装2、Selenium的安装3、ChromeDrive 的安装4.GeckoDriver 的安装5.PhantomJS 的安装6.aiohttp 的安装二、解析库的安装1.lxml 的安装2.Beautiful Soup 的安装3.pyquery 的安装4.tesserocr 的安装
目录
一、请求库的安装
1、requests 的安装
1. 相关链接
2 . pip 安装
pip install requests2、Selenium的安装
1.相关链接
- 官方网站:https://www.seleniumhq.org
- GitHub: selenium/py at trunk · SeleniumHQ/selenium · GitHub
- PyPI: https://pypi.python.org/pypi/selenium
- 官方文梢:https://selenium-python.readthedocs.io
- 中文文档:Selenium with Python中文翻译文档 — Selenium-Python中文文档 2 documentation
2.pip 安装
pip install selenium3、ChromeDrive 的安装
前面我们成功安装好了Selenium库,但是他是一个自动化测试工具,需要浏览器来配合使用。
首先,下载 hrome 浏览器。
随后安装 ChromeDriver 因为只有安装 ChromeDriver ,才能驱动 Chrome 浏览器完成相应的操作 下面我们来介绍下怎样安装 ChromeDriver。
2.准备工作


4. 下载 ChromeDriver
打开 ChromeDriver 的官方网站,可以看到最新版本为 96.04664.18 ,其支持的 Chrome 浏览器版本为 96.04664

5.环境变量配置

6. 验证安装
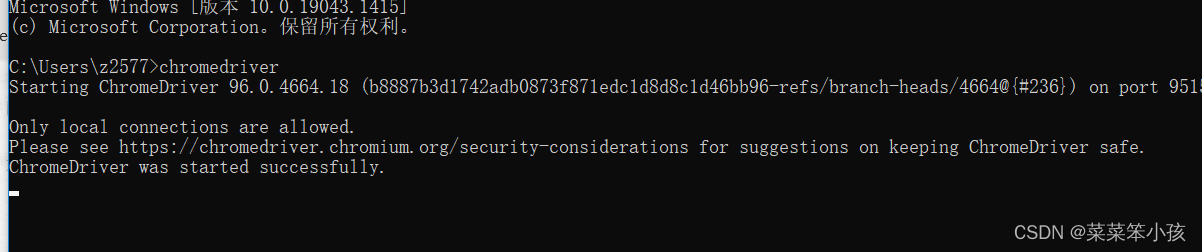
随后再在程序中测 Python 代码:
from selenium import webdriver
browser = webdriver.Chrome()返回:

运行之后 如果弹出一个空Chrome 浏览器,则证明所有的配置都没有问题。如果没有弹出,
4.GeckoDriver 的安装
上面,我们了解了ChromeDriver的配置方法,配置完成后可以用Selenium驱动Chrome浏览器做对应的网页抓取。
那么对应Firefox来说,也可以用同样的方式完成Selenium的对接,这时需要安装另一个驱动GeckoDriver,接下来我们接受一下它的安装过程。
2. 准备工作
确保已经正确安装了Firefox浏览器并且能正常运行。

3.下载 GeckoDriver
在GitHub 上找 GeckoDriver 的发行版,并找到最新版的,如下是0.30

因我的电脑是win10,64位的所以下载如图的

4. 环境变量配置
geckodriver返回如下,则证明安装成功且配置正确

from selenium import webdriver
browser = webdriver.Firefox()返回,不知为啥这次pycharm里运行会报错,于是我用了Anaconda运行

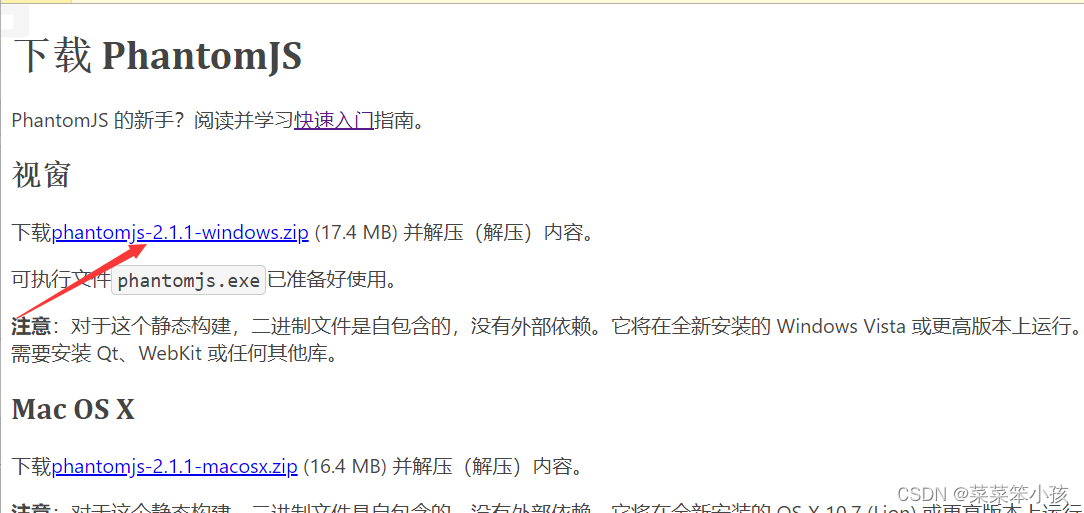
5.PhantomJS 的安装
- 官方网站: PhantomJS - Scriptable Headless Browser
- 官方文梢:Quick Start with PhantomJS
- 下载地址1: Download PhantomJS
- 下载地址2:
- API 接门说明:Command Line Interface | PhantomJS



from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get('https://www.baidu.com')
print(browser.current_url) 如果返回如下,则说明selenium版本过高,需要安装低版本的,因为最新版已经放弃了phantomjs
1.先把selenium卸载,代码如下:
pip uninstall selenium
2.安装selenium==2.48.0版本的,代码如下:
pip install selenium==2.48.0
完美运行成功!!!!!
返回:

6.aiohttp 的安装
2. pip 安装
pip install aiohttppip install cchardet aiodns二、解析库的安装
1、lxml 的安装
- 官方网站:lxml - Processing XML and HTML with Python
- GitHub: https://github.com/lxml/lxml
- PyPI: https://pypi.org/pyp/lxml
pip install lxml
#或
pip3 install lxmlpip install lxml 3.8.0-cp36-cp36m-win_amd64 .whl
#或
pip3 install lxml 3.8.0-cp36-cp36m-win_amd64 .whl
如果没有错误报出,则证明库已经安装好了
2.Beautiful Soup 的安装
pip install beautifulsoup4
#或
pip3 install beautifulsoup4from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>','lxml')
print(soup.p.string)运行结果如下:
![]()
运行一致,则证明安装成功。
3.pyquery 的安装
pip install pyquery
#或
pip3 install pyquerypip install pyquery-1.2.17-py2.py3-none-any.whl
#或
pip3 install pyquery-1.2.17-py2.py3-none-any.whl import pyquery运行结果如下:

运行没有报错,则证明安装成功。
4.tesserocr 的安装
1.OCR
- tesserocr GitHub: GitHub - sirfz/tesserocr: A Python wrapper for the tesseract-ocr API
- tesserocr Py PI: tesserocr · PyPI
- tesserac 下载地址:Index of /tesseract
- tesserac GitHub :https://github.com/tesseract-ocr/tesseract
- tesserac 语言包 :https://github.com/tesseract-ocr/tessdata
- tesseract 文档: Manual Pages | tessdoc
下载完成后双击, 好像没有中文版的

然后一直点 next 和 i agree 就行,直到

pip install tesserocr pillow
#或
pip3 install tesserocr pillow4.验证安装

打开照片所在文件夹,按住 shift 击右键 打开 powershell窗口 输入下面命令:
tesseract image.png stdout -l eng得到结果:

然后,我们看一下在python中如何演示:
首先,现安装库
pip install pytesseract如何想要在python中使用 pytesseract 库,则需要先添加 tesseract 的环境变量
1.将tesseract.exe添加到环境变量PATH中
我的电脑——右键——属性——高级系统设置——环境变量——将 tesseract.exe 所在的文件夹的路径添加到 path 中

2. 修改pytesseract.py文件,指定tesseract.exe安装路径

然后打开它

import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd=r'D:\Tesseract-OCR\tesseract.exe'
image=Image.open('D:\桌面\python\jupyter\image.png')#所要识别的图片的位置
#默认是英文,如果是英文就不需更改
text=pytesseract.image_to_string(image)
#默认是英文,如果是中文,要将语言改成中文。
# text=pytesseract.image_to_string(image,lang='chi_sim')
print(text)返回:

库,先安装到这里,后面还有很多很多,等我慢慢补充,嘿嘿!!!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)