【聚类算法】| Kmeans算法的Python实现(以西瓜数据集为例)
如有错误,恳请指出。任务:无监督聚类西瓜数据集(30样本),数据集如下所示:西瓜书的聚类部分,有一个题目是用30个无标签的西瓜数据集来进行聚类分出3类,这里直接贴上代码。参考代码:"""writing by: Clichongtheme:机器学习聚类算法的实现data:2022/4/27"""import numpy as npimport pandas as pdimport matplotli
·
如有错误,恳请指出。
- 任务:无监督聚类西瓜数据集(30样本),数据集如下所示:
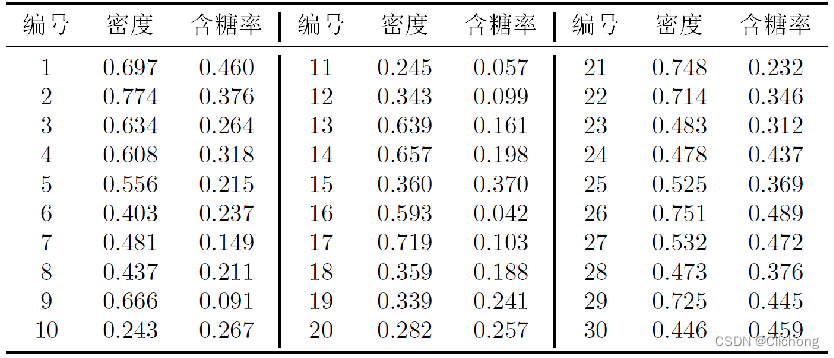
西瓜书的聚类部分,有一个题目是用30个无标签的西瓜数据集来进行聚类分出3类,这里直接贴上代码。
- 参考代码:
"""
writing by: Clichong
theme: 机器学习聚类算法的实现
data: 2022/4/27
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 功能: 设置随机种子, 确保结果可复现
def make_seed(SEED=42):
np.random.seed(SEED)
# 功能: 计算样本与聚类中心的距离, 返回离簇中心最近的类别
# params: sample: 单个数据样本, centers: k个簇中心
# return: 返回的是当前的样本数据属于那一个簇中心的id或者索引
def distance(sample, centers):
# 这里用差的平方来表示距离
d = np.power(sample - centers, 2).sum(axis=1)
cls = d.argmin()
return cls
# 功能: 对当前的分类子集进行可视化展示
def clusters_show(clusters, step):
color = ["red", "blue", "pink"]
marker = ["*", "^", "."]
plt.figure(figsize=(8, 8))
plt.title("step: {}".format(step))
plt.xlabel("Density", loc="center")
plt.ylabel("Sugar Content", loc="center")
# 用颜色区分k个簇的数据样本
for i, cluster in enumerate(clusters):
cluster = np.array(cluster)
plt.scatter(cluster[:, 0], cluster[:, 1], c=color[i], marker=marker[i], s=150)
plt.show()
# 功能: 根据输入的样本集与划分的簇数,分别返回k个簇样本
# params: data:样本集, k:聚类簇数
# return:返回是每个簇的簇类中心
def k_means(samples, k):
data_number = len(samples)
centers_flag = np.zeros((k,))
# 随机在数据中选择k个聚类中心
centers = samples[np.random.choice(data_number, k, replace=False)]
print(centers)
step = 0
while True:
# 计算每个样本距离簇中心的距离, 然后分到距离最短的簇中心中
clusters = [[] for i in range(k)]
for sample in samples:
ci = distance(sample, centers)
clusters[ci].append(sample)
# 可视化当前的聚类结构
clusters_show(clusters, step)
# 分完簇之后更新每个簇的中心点, 得到了簇中心继续进行下一步的聚类
for i, sub_clusters in enumerate(clusters):
new_center = np.array(sub_clusters).mean(axis=0)
# 如果数值有变化则更新, 如果没有变化则设置标志位为1,当所有的标志位为1则退出循环
if (centers[i] != new_center).all():
centers[i] = new_center
else:
centers_flag[i] = 1
step += 1
print("step:{}".format(step), "\n", "centers:{}".format(centers))
if centers_flag.all():
break
return centers
# 功能: 根据簇类中心对簇进行分类,获取最后的分类结果
# params: samples是全部的数据样本,centers是聚类好的簇中心
# return: 返回的是子数组
def split_data(samples, centers):
# 根据中心样本得知簇数
k = len(centers)
clusters = [[] for i in range(k)]
for sample in samples:
ci = distance(sample, centers)
clusters[ci].append(sample)
return clusters
if __name__ == '__main__':
make_seed()
# 导入数据
data = pd.read_excel(r"./dataset/西瓜数据集4.0.xlsx")
samples = data[["密度", "含糖率"]].values
# print(samples)
centers = k_means(samples=samples, k=3)
clusters = split_data(samples=samples, centers=centers)
print(clusters)
- 输出:
[[0.473 0.376]
[0.593 0.042]
[0.478 0.437]]
step:1
centers:[[0.47385714 0.29514286]
[0.5647 0.1347 ]
[0.60483333 0.46033333]]
step:2
centers:[[0.41018182 0.286 ]
[0.571 0.14645455]
[0.639625 0.4355 ]]
step:3
centers:[[0.36775 0.25616667]
[0.63255556 0.16166667]
[0.64488889 0.41244444]]
step:4
centers:[[0.36063636 0.23772727]
[0.63255556 0.16166667]
[0.625 0.4171 ]]
step:5
centers:[[0.36136364 0.21709091]
[0.6515 0.16325 ]
[0.61118182 0.41336364]]
step:6
centers:[[0.36136364 0.21709091]
[0.6515 0.16325 ]
[0.61118182 0.41336364]]
# 以下每个列表表示一类(一共分了3类):
[[array([0.403, 0.237]), array([0.481, 0.149]), array([0.437, 0.211]), array([0.243, 0.267]), array([0.245, 0.057]), array([0.343, 0.099]), array([0.36, 0.37]), array([0.359, 0.188]), array([0.339, 0.241]), array([0.282, 0.257]), array([0.483, 0.312])],
[array([0.634, 0.264]), array([0.556, 0.215]), array([0.666, 0.091]), array([0.639, 0.161]), array([0.657, 0.198]), array([0.593, 0.042]), array([0.719, 0.103]), array([0.748, 0.232])],
[array([0.697, 0.46 ]), array([0.774, 0.376]), array([0.608, 0.318]), array([0.714, 0.346]), array([0.478, 0.437]), array([0.525, 0.369]), array([0.751, 0.489]), array([0.532, 0.472]), array([0.473, 0.376]), array([0.725, 0.445]), array([0.446, 0.459])]]
- 可视化输出:
不同的颜色分别为1类,可以看见每次聚类样本类别的变化:






ps:这个是我的一个课程作业,就直接贴上来啦,原理啥的就不多说了

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)