手把手教你Swin-Transformer-Semantic-Segmentation(语义分割)训练自己的数据集
一步步教你从搭建环境,到环境测试,到数据集制作,到代码调试,最终到运行并测试结果。跑通Swin-Transformer-Semantic-Segmentation保姆级教程!
显卡不太行的同学一般跑不动哦,我用的工作站显卡2080ti勉强才跑通4batch_size
代码地址:https://github.com/SwinTransformer/Swin-Transformer-Semantic-Segmentation
搭建环境
第一步,建立conda环境,下载pycharm,这就不再赘述了
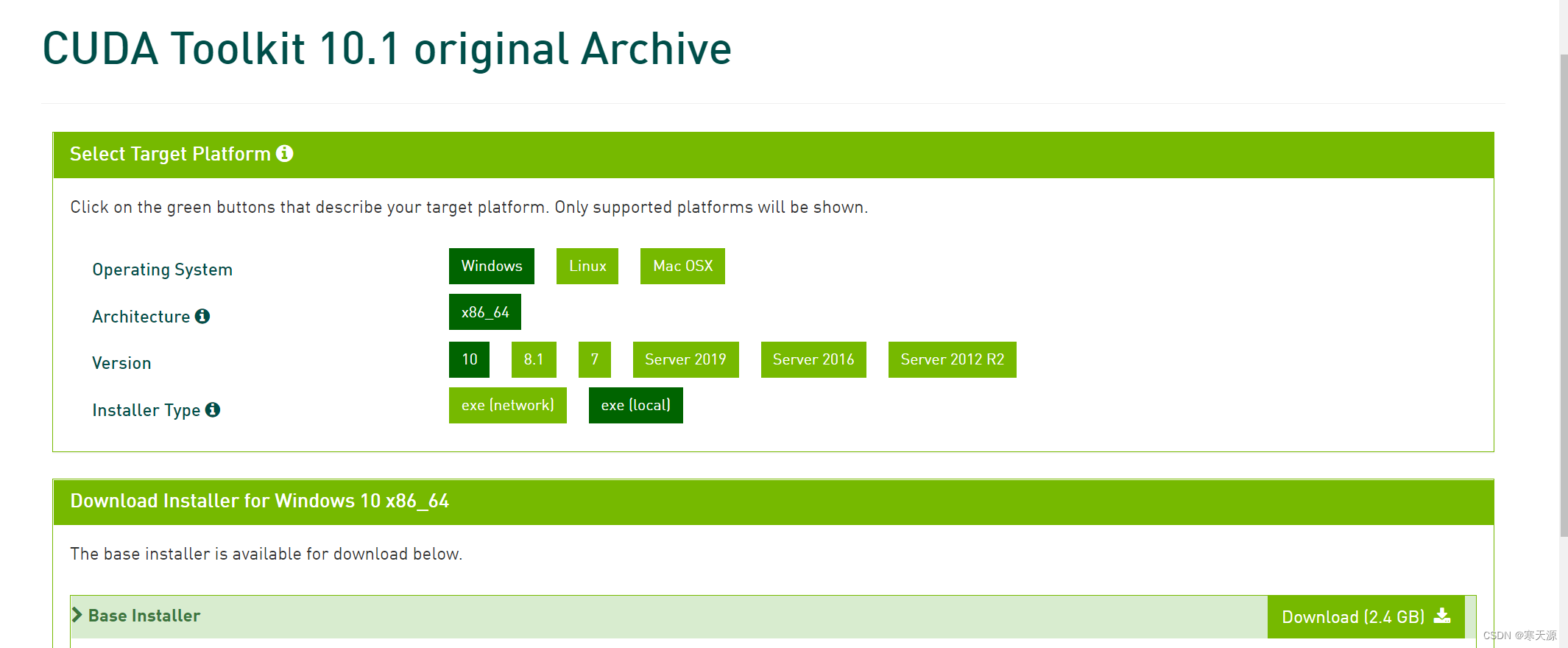
下载cuda10.1(如果你是win系统最好按此步骤来)
地址:CUDA Toolkit 10.1 original Archive | NVIDIA Developer
第二步,安装cudnn7.6.4
地址:cuDNN Archive | NVIDIA Developer
将解压后的cudnn文件逐步对照文件夹名放入cuda中
win+r打开cmd,输入nvcc -V,出现下图情况,就代表cuda已被激活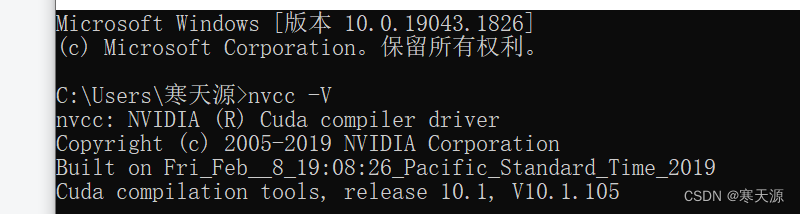
也可以在pycharm中使用命令建立新的虚拟环境,详情可参照下博客
第三步:安装pytorch1.6.0+cu101和torchvision0.7.0+cu101
命令:pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html第四步:安装mmcv-full
安装mmcv请参考官方文档,对照下图这个表来,表中没有的好像就没有了
按步骤来的兄弟吗直接复制以下代码,安装1.1.5版本
pip install mmcv-full==1.1.5 -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html兄弟们这里注意一点,mmcv在win系统的更新最多到1.1.5,1.1.5之后至1.3.0之间的版本是没有的,而代码中的需求版本号是在1.1.4到1.3.0之间,如果有同学是win系统且安装了别的版本号,且可以试一下在mmseg\__init__.py中修改一下MMCV_MAX='1.3.0',改为自己下载的版本号尝试一下,看看能不能跑通,我也不清楚hhh。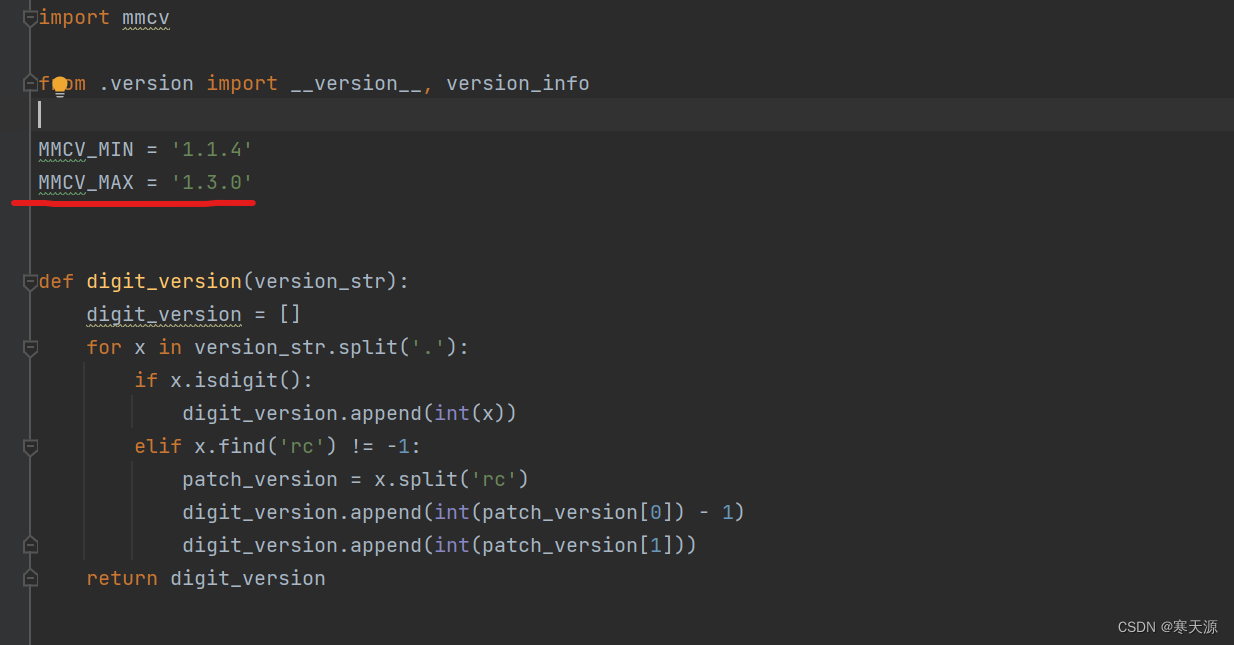
第五步,安装mmseg
pip install mmsegmentation
第六步,安装代码包中给出的requirements,下图的五个txt
注:readthedocs.txt不要运行,pip会主动安装最新版本,避免覆盖掉已下载的版本。
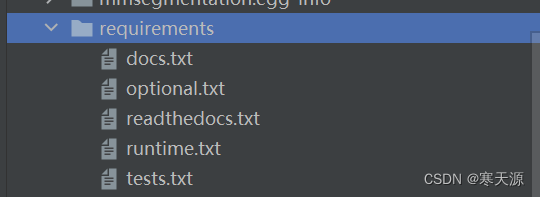
pip install -r requirements\docs.txt剩下的四个txt,各位改改名就好了,依次在终端中安一下
最后再在终端中运行一下以下命令,确认一下所安装的包。
python setup.py develop以上就是关于环境的搭建了
验证环境是否可行
第一步,下载预训练模型
在代码的地址下方有预训练模型的下载链接
下载swin-T的model(github的链接可以直接下载,baidu的提取码是swin)
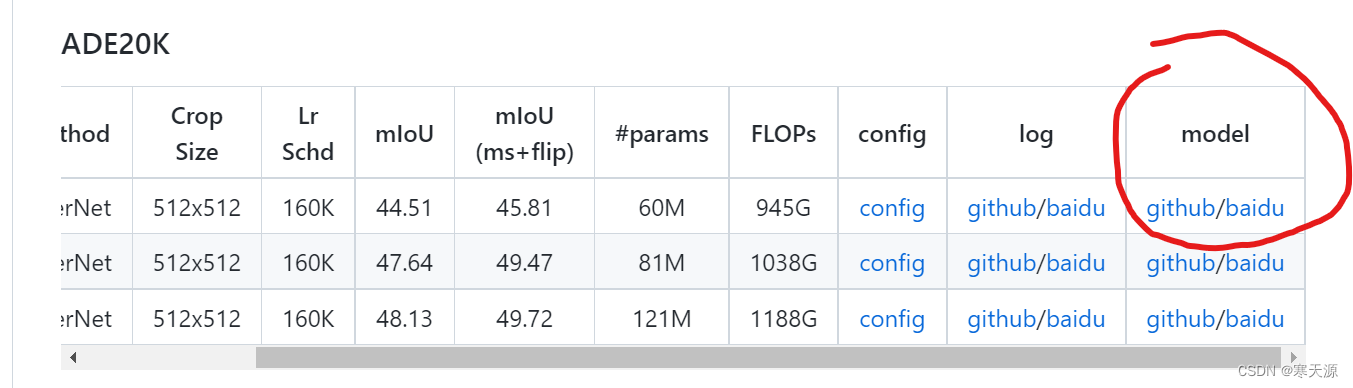
下载之后放入dome文件夹下,如下图
将demo\image_demo.py修改如图所示
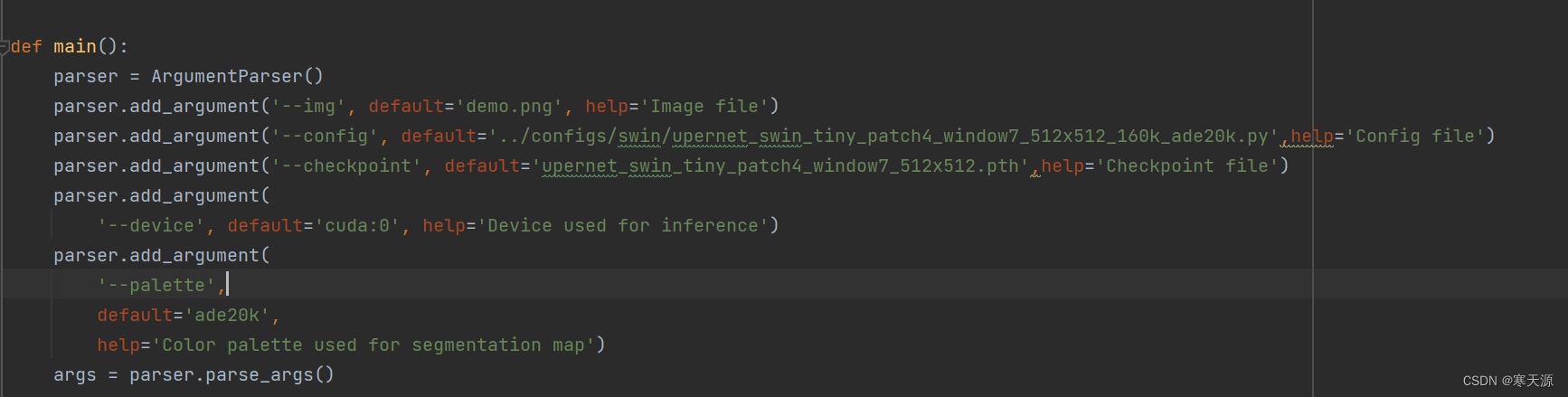
注意:不要小看img,config,checkpoint之前的杠杠(--img)非常重要!
想偷懒的小伙伴可以直接ctrl+cv大法,用这一块替换原来的部分
def main():
parser = ArgumentParser()
parser.add_argument('--img', default='demo.png', help='Image file')
parser.add_argument('--config', default='../configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k.py',help='Config file')
parser.add_argument('--checkpoint', default='upernet_swin_tiny_patch4_window7_512x512.pth',help='Checkpoint file')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
'--palette',
default='ade20k',
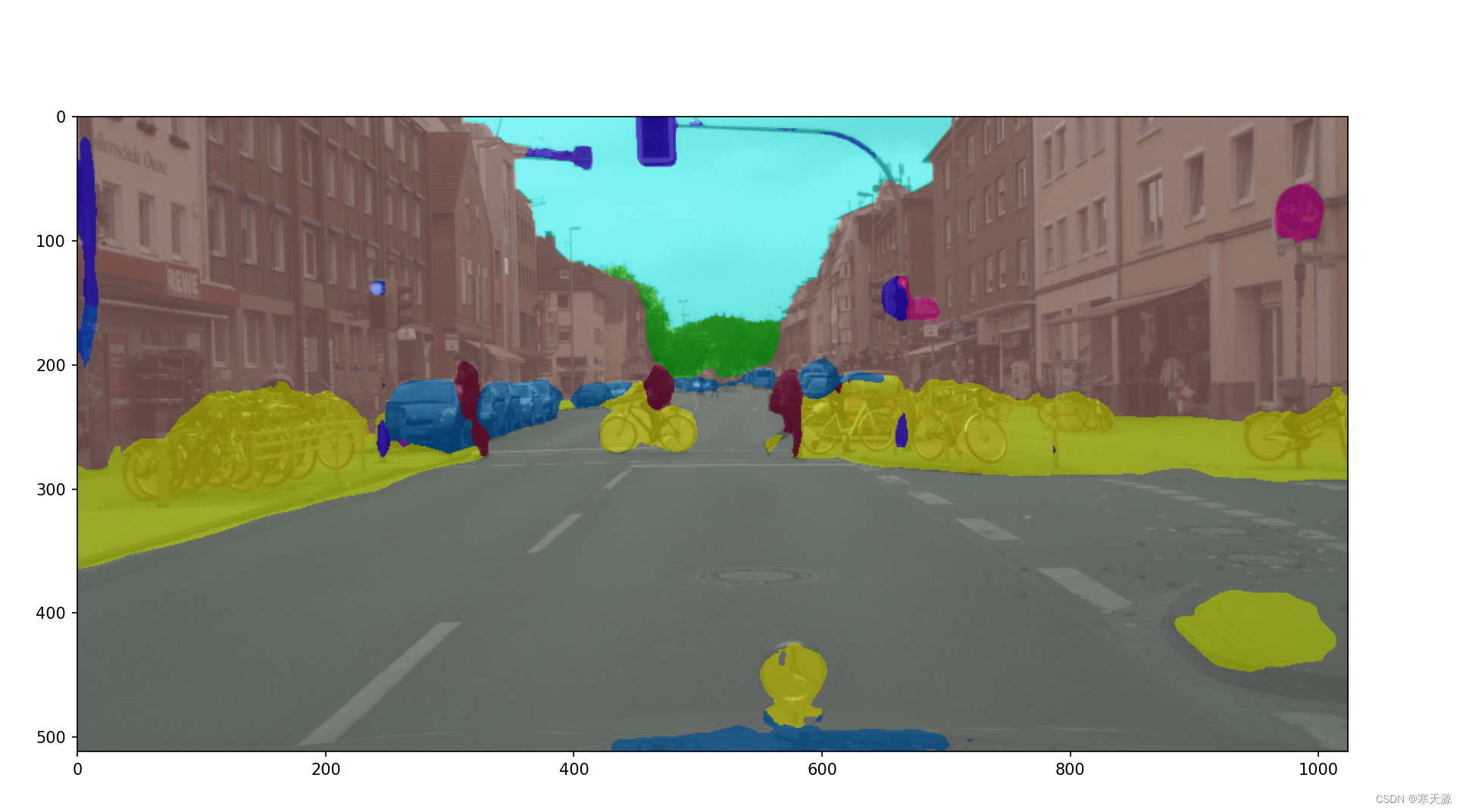
help='Color palette used for segmentation map')出现这张图代表一切关于环境的工作准备已经就绪了
数据集制作
在制作并训练自己的数据集时,我们先在tools文件夹下创建一个data文件夹,再在data文件夹下创建一个VOCdevkit的文件夹,再在此文件夹下创建一个VOC2012的文件夹,在此文件夹下分别建立ImageSets,JPEGImages,SegmentationClass对应分别存放,训练和验证的图片名的txt文件,要训练的所有图片,要训练的所有标签(ImageSets文件夹下再建立一个Segmentation的文件夹来存放train和val)
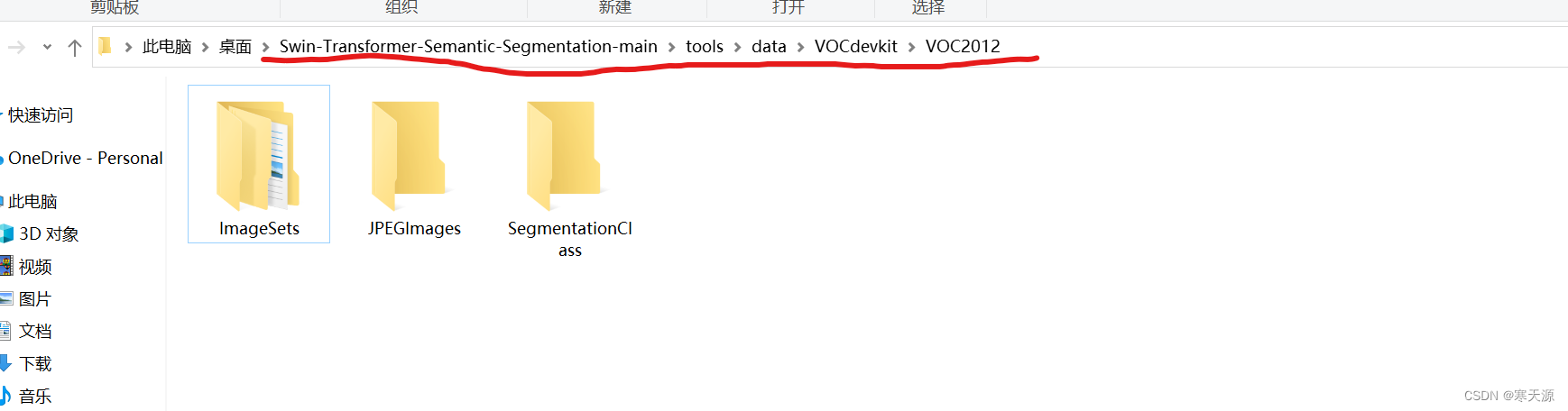
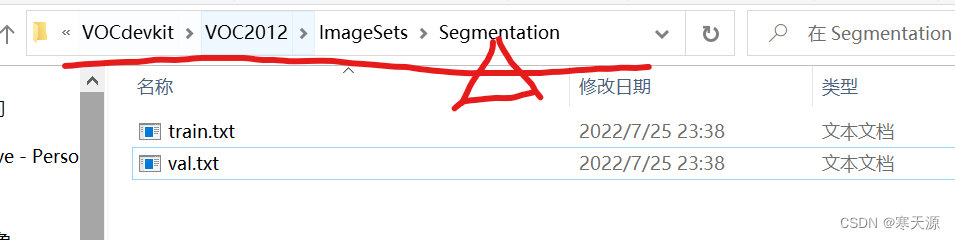
数据标签我们在使用的时候需要制作voc标签,如果不确定自己的数据集标签是否是voc格式,就在tools目录下建立一个py文件,复制下面代码并直接运行
import os
import cv2
from PIL import Image
# Make sure the format of your dataset is VOC format
def convert(mask_path):
cv_img = cv2.imread(mask_path)
cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGRA2BGR)
cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2BGRA)
cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGRA2RGBA)
image = Image.fromarray(cv_img).convert(mode="P")
image.save(mask_path)
mask_folder = "data/VOCdevkit/VOC2012/SegmentationClass"
for mask in os.listdir(mask_folder):
mask_path = os.path.join(mask_folder, mask)
convert(mask_path)代码调试
第一步,在mmseg\datasets\voc.py中修改自己的要训练的图片类别
原图是这样的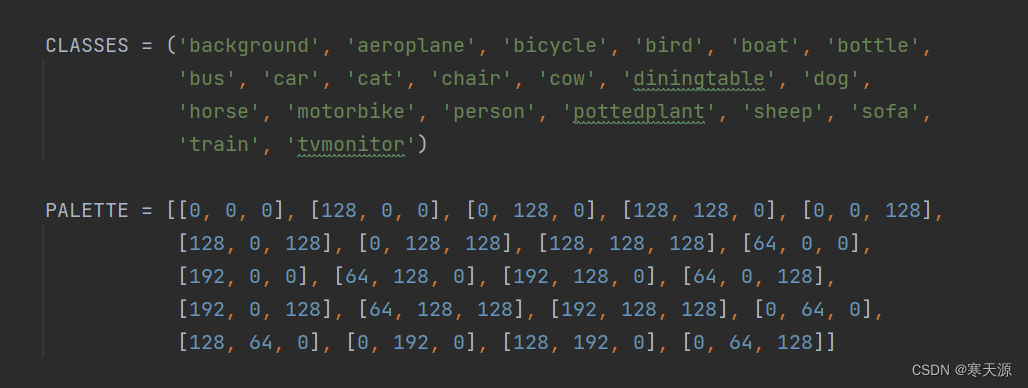
拿我自己的数据集举例,我是训练视杯视盘的分割,用的label样式如下图就建立一个三分类的classes和palette
我的label图
我修改的voc.py(几个颜色就是几分类吧,我也不是很清楚,反正我跑出来效果也并不是很好,希望有大佬能指正。下面的palette不知道数据的可以拿ps的吸管工具吸取颜色之后查看此颜色的RGB三通道的数据,哈哈哈因为我是这么干的)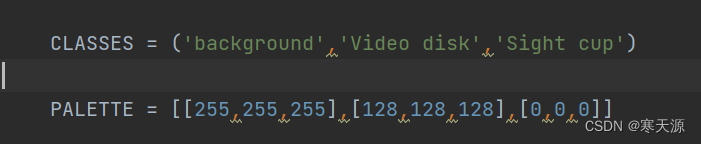
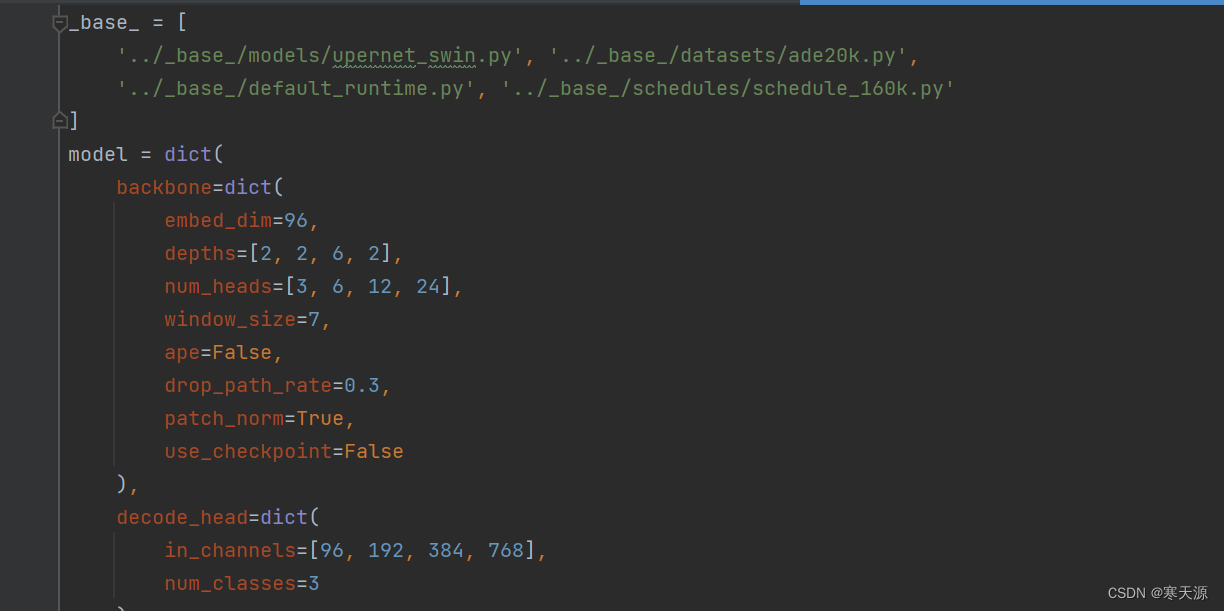
第二步,在configs\swin\upernet_swin_tiny_patch4_window7_512x512_160k_ade20k.py中
找到两个num_classes,修改成你的classes数。我这里就将其修改为3
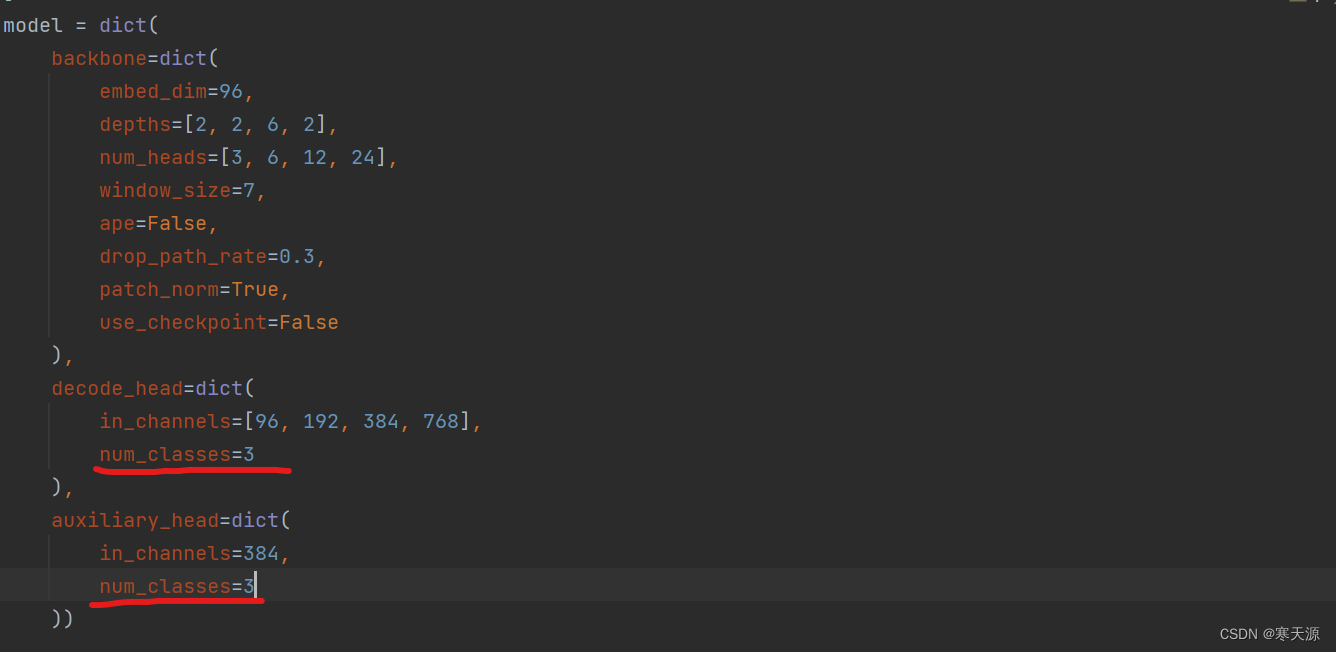
代码末尾这里其实就是batch_size的大小(好像不能小于2)
还有这里的_base_,第一个代表我们使用的模型,第二个代表我们使用的数据集加载方式,第三个应该是记录训练时间用的,第四个是训练的轮次。
因为我们要使用的是voc方式,我们应将ade20k.py修改成pascal_voc12.py。
要修改跑的轮次的话可以修改第四个文件名,其他文件都在schdules的文件夹中
修改如图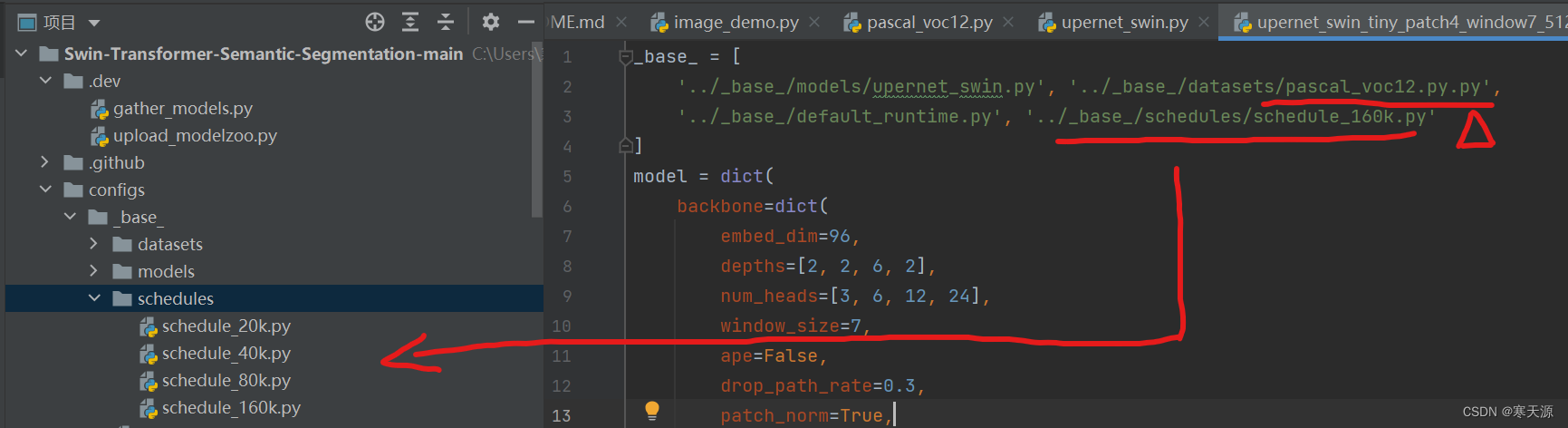
第三步, 在configs\_base_\datasets\pascal_voc12.py中,crop_size修改输入图片的大小,这里最好使用给出的大小,图片的大小可以调整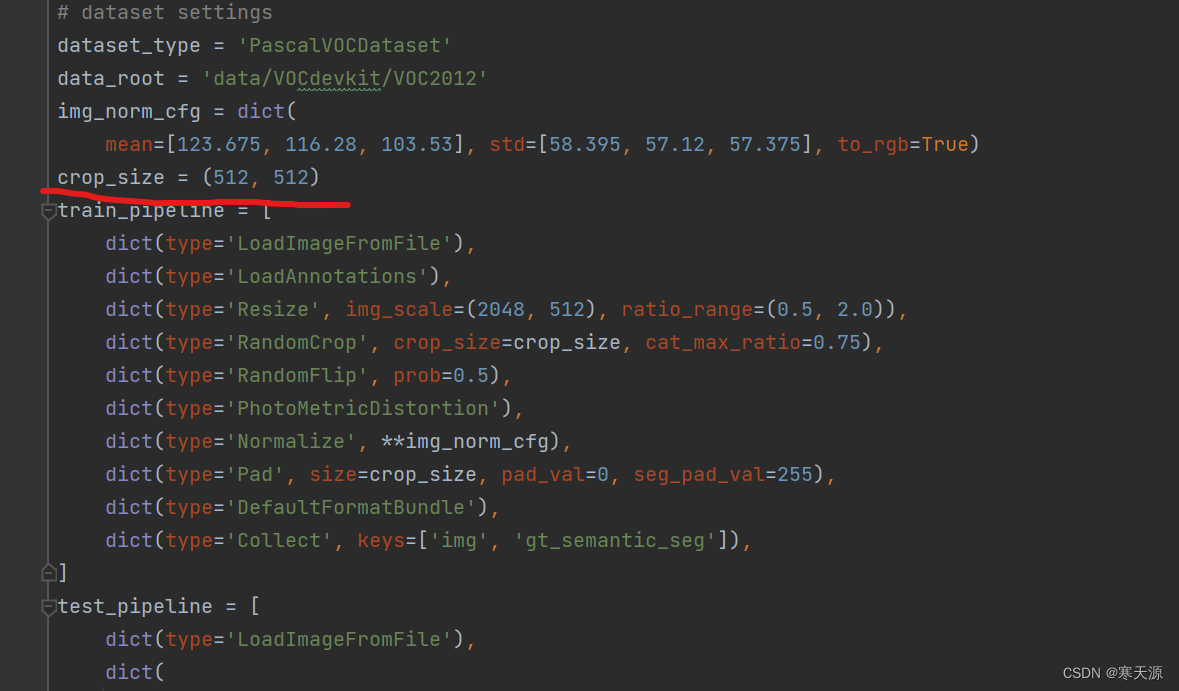
第四步,在configs\_base_\models\upernet_swin.py中
如果你是单GPU训练,请将type='SyncBN'修改为type='BN'
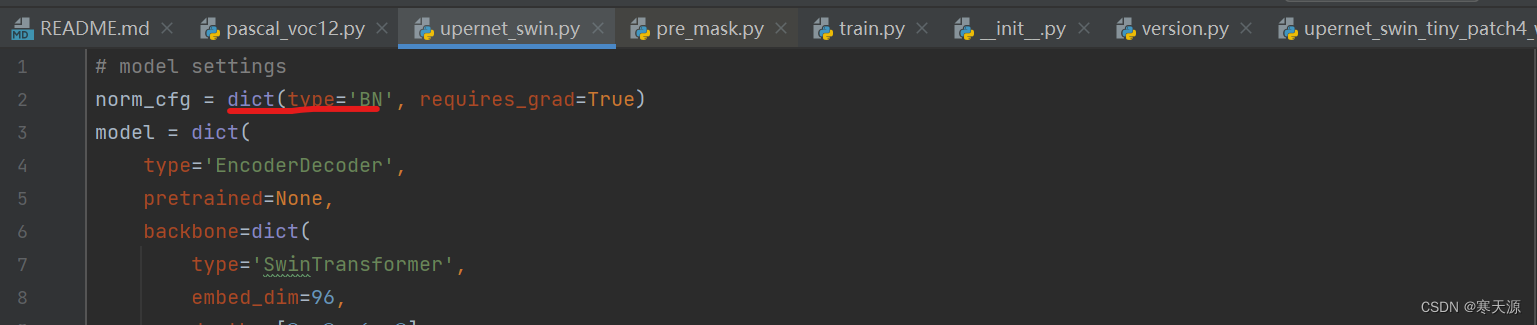
修改此文件的两处num_classes大小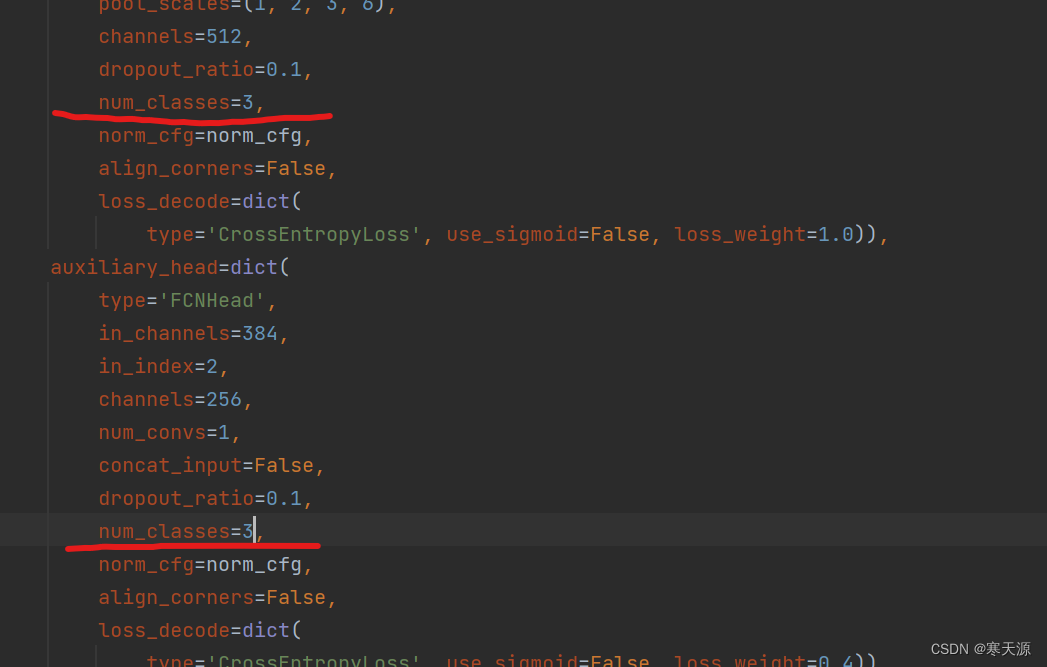
第五步,修改tools\train.py
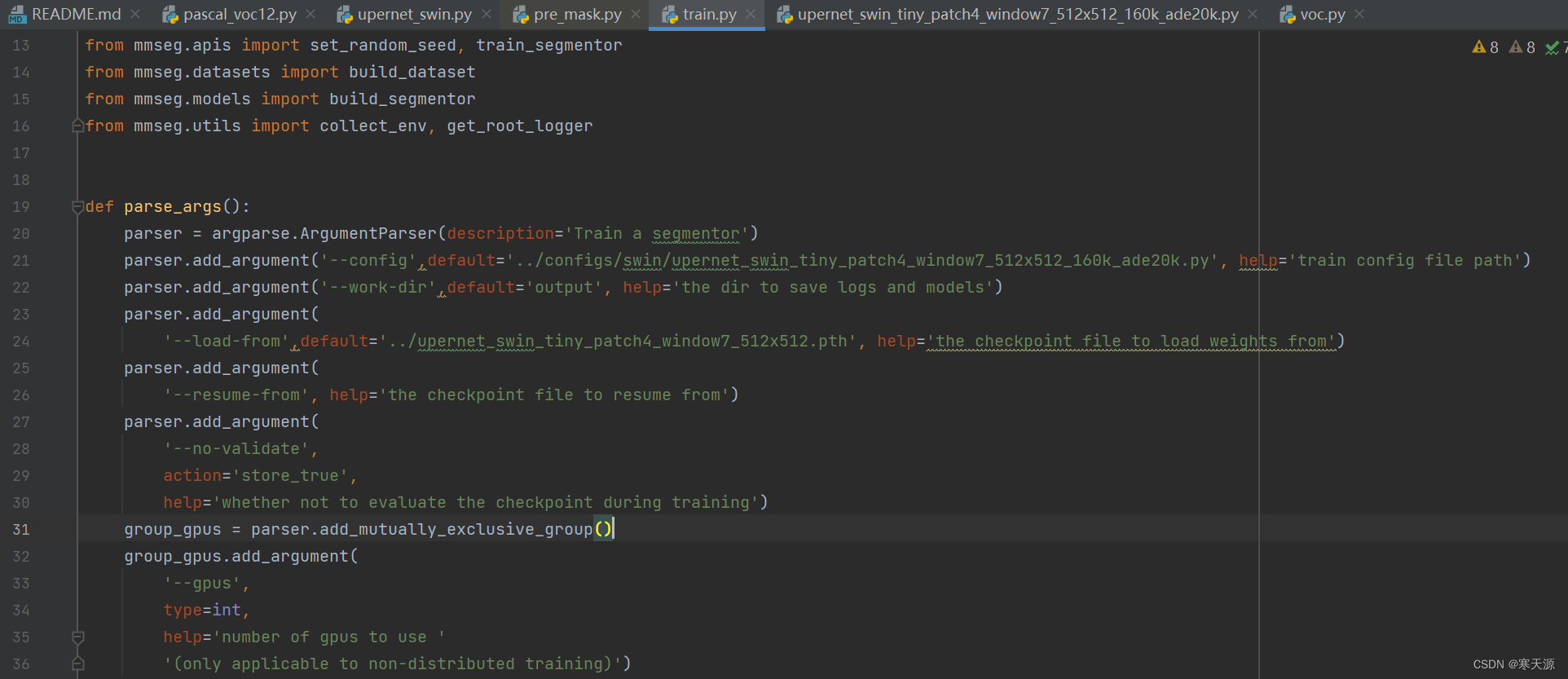
与修改 demo\image_demo.py方式相同,所修改的部分代码如下
def parse_args():
parser = argparse.ArgumentParser(description='Train a segmentor')
parser.add_argument('--config',default='../configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k.py', help='train config file path')
parser.add_argument('--work-dir',default='output', help='the dir to save logs and models')
parser.add_argument(
'--load-from',default='../upernet_swin_tiny_patch4_window7_512x512.pth', help='the checkpoint file to load weights from')
parser.add_argument(
'--resume-from', help='the checkpoint file to resume from')
parser.add_argument(
'--no-validate',
action='store_true',
help='whether not to evaluate the checkpoint during training')万事具备,运行tools\train.py就可以run了
测试
在tools文件下可以创建一个prediction.py文件,填充完文件就可以愉快的玩耍了
import os
from mmseg.apis import init_segmentor, inference_segmentor, show_result_pyplot
from mmseg.core.evaluation import get_palette
from matplotlib import pyplot as plt
import mmcv
from collections import Counter
from PIL import Image
import numpy as np
from tqdm import tqdm
config_file = r"configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k.py"
checkpoint_file = r"tools\output\*****"#修改此处权重名,即.pth文件
model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
img_root = r"tools\data\VOCdevkit\VOC2012\*****/"#修改要预测的图片名或文件夹名
save_mask_root = r"tools\data\*****"#预测结果存放处
if not os.path.exists(save_mask_root):
os.mkdir(save_mask_root)
img_names = os.listdir(img_root)
for img_name in tqdm(img_names):
# test a single image
img = img_root + img_name
result = inference_segmentor(model, img)[0]
img = Image.fromarray(np.uint8(result*55))
img.save(save_mask_root + img_name)感谢大佬的视频指导
视频地址:Win10配置Swin-Transformer-Semantic-Segmentation并训练自己数据集_哔哩哔哩_bilibili
萌新刚上手swin transformer,欢迎大佬们来指正错误,鞠躬!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐

 28
28 2
2- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)