一文快速上手openGauss
本文提供了在CentOS7.6环境下快速安装openGauss企业版的简明指南。主要内容包括:关闭防火墙和SELinux、安装依赖包、下载解压安装包、配置主机名和环境变量、编辑clusterconfig.xml文件、使用root用户初始化环境后切换omm用户完成安装。最后介绍了openGauss的关键内存结构(本地内存区、共享内存区)和线程结构(postmaster、BgWriter等核心进程)。
快速安装openGauss
本文基于centOS7.6环境,目的是简单快速安装openGauss企业版本,官方安装文档有更加详细步骤和说明
官方安装文档地址
https://docs.opengauss.org/zh/docs/6.0.0/docs/InstallationGuide
安装前准备
关闭防火墙 systemctl disable firewalld.service systemctl stop
firewalld.service 关闭SELINUX vim /etc/selinux/config SELINUX=disabled
修改“SELINUX”的值“disabled reboot
(1)安装依赖包
yum install openssl* -y yum install python3* -y yum install
libaio-devel readline-devel expect -y
(2)下载和解压安装包
登录https://opengauss.org/zh/download/ 下载企业版
mkdir -p /opt/software/openguass 上传到此目录 解压 tar -xzvf
openGauss-All-6.0.1-CentOS7-x86_64.tar.gz tar -xzvf openGauss
openGauss-OM-6.0.1-CentOS7-x86_64.tar.gz
(3)修改主机名
hostnamectl set-hostname node1 vi /etc/hosts {ip} node1
(4)配置库环境变量
export LD_LIBRARY_PATH=/opt/software/openGauss/script/gspylib/clib:$LD_LIBRARY_PATH
(5)编辑配置文件
clusterconfig.xml文件包含部署openGauss的服务器信息、安装路径、IP地址以及端口号等。用于告知openGauss如何部署。
用户需根据不同场景配置对应的XML文件。
vi /opt/software/openguass/clusterconfig.xml
<?xml version="1.0" encoding="UTF-8"?>
需要修改的地方只有nodeNames的值,改为第3步的主机名,还有修改为自己的主机IP地址<!-- openGauss整体信息 --> <CLUSTER> <!-- 数据库名称 --> <PARAM name="clusterName" value="dbCluster" /> <!-- 数据库节点名称(hostname) --> <PARAM name="nodeNames" value="node1" /> <!-- 数据库安装目录--> <PARAM name="gaussdbAppPath" value="/opt/huawei/install/app" /> <!-- 日志目录--> <PARAM name="gaussdbLogPath" value="/var/log/omm" /> <!-- 临时文件目录--> <PARAM name="tmpMppdbPath" value="/opt/huawei/tmp" /> <!-- 数据库工具目录--> <PARAM name="gaussdbToolPath" value="/opt/huawei/install/om" /> <!-- 数据库core文件目录--> <PARAM name="corePath" value="/opt/huawei/corefile" /> <!-- 节点IP,与数据库节点名称列表一一对应 --> <!-- 如果用ipv6 替换ipv4地址即可 如:<PARAM name="backIp1s" value="2407:xxxx:xxxx:xxxx:xxxx:xxxx:caa:2335"/> --> <PARAM name="backIp1s" value="10.1.20.8"/> </CLUSTER> <!-- 每台服务器上的节点部署信息 --> <DEVICELIST> <!-- 节点1上的部署信息 --> <DEVICE sn="node1"> <!-- 节点1的主机名称 --> <PARAM name="name" value="node1"/> <!-- 节点1所在的AZ及AZ优先级 --> <PARAM name="azName" value="AZ1"/> <PARAM name="azPriority" value="1"/> <!-- 节点1的IP,如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP --> <!-- 用ipv6安装部署时 换上ipv6地址即可,后面xml文件示例也是同样操作 --> <PARAM name="backIp1" value="10.1.20.8"/> <PARAM name="sshIp1" value="10.1.20.8"/> <!--dbnode--> <PARAM name="dataNum" value="1"/> <PARAM name="dataPortBase" value="26000"/> <PARAM name="dataNode1" value="/opt/huawei/install/data/dn"/> <PARAM name="dataNode1_syncNum" value="0"/> </DEVICE> </DEVICELIST> </ROOT>
(6)初始化安装环境
该步骤用root用户执行
cd /opt/software/openGauss/script ./gs_preinstall -U omm -G dbgrp -X
/opt/software/openGauss/clusterconfig.xml这步会创建omm用户,需要设置omm密码
(7)使用gs_install安装openGauss
chmod -R 755 /opt/software/openGauss/script/ chown -R omm:dbgrp
/opt/software/openGauss/script/ cp …/clusterconfig.xml . gs_install
-X /opt/software/openGauss/script/clusterconfig.xml需要设置密码 aaAA11__
Successfully started cluster. Successfully installed application. end
deploy…
(8)登录
gsql -d postgres -p 26000 -r openGauss=#
openGauss内存结构
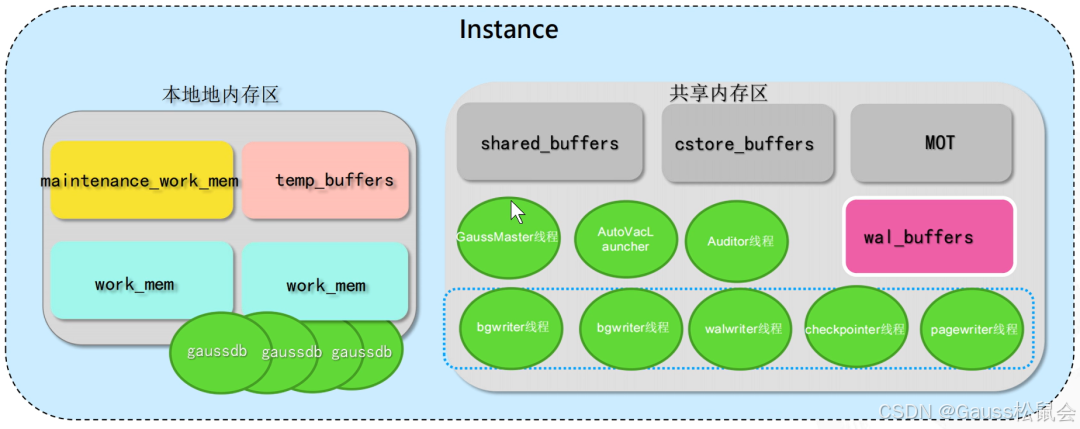
本地内存区
maintenance_work_mem:维护操作 vacuum,reindex使用
temp_buffers:临时表使用
work_mem:order by 和distinct 操作对元组进行排序,通过merge-join 和hash join
操作对表进行连接时使用
共享内存区
shared_buffers:控制行存缓冲区大小 建议设置为内存的25~40%(没有单位以块为单位)
cstore_buffers:控制列存缓冲区大小 建议设置为内存/节点个数0.40.25
wal_buffers:wal log数据的缓冲区 设置为-1 为自动调节大小
MOT buffer:全局内存,是一个长期内存池,包含MOT的数据和索引。平均分布在NUMA节点,由所有CPU核共享。
openGauss线程结构
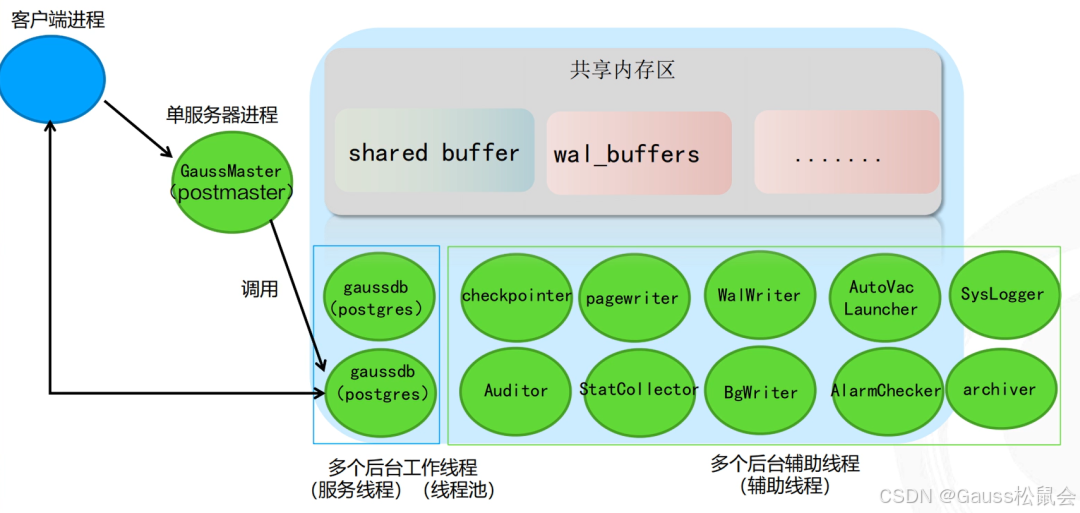
postmaster进程
1.数据库初始化时,为后端线程设置共享内存结构;
2.数据库的启停;
3.监听客户端连接,为每个客户端连接调用单独的服务线程;
4.管理与数据库运行相关的辅助线程;
5.线程垃圾回收,当后端服务线程紧急退出或者内核dump时,清理后端线程;
6.错误报告;
BgWriter
把共享内存中的脏页写到磁盘上的线程。
正常状态下,bgwriter在刷新完缓存后,会等待时长bgwriter_delay(默认10秒)。当连续两次都没有要刷新的缓存,那么就会进入冬眠状态,等待时长变为50*bgwriter_delay。
PageWriter
负责将脏页数据拷贝至双写(double-writer)区域并落盘,然后将脏页转发给bgwriter子线程进行数据落盘操作。
autovacuum launcher 和 autovacuum worker
自动清理回收垃圾进程 autovacuum_vacuum_threshold = 50
autovacuum_vacuum_scale_factor = 0.2• 触发vacuum–> 表上新增变化(update,delete) >= autovacuum_vacuum_scale_factor*
reltuples(表上记录数) + autovacuum_vacuum_threshold• 触发vacuum analyze–> 表上新增(insert,update,delte) >=
autovacuum_analyze_scale_factor* reltuples(表上记录数) +
autovacuum_analyze_threshold• 触发vacuum freeze–>
指定表上事务的最大年龄配置参数autovacuum_freeze_max_age,默认为2亿,达到这个阀值将触发
autovacuum进程,从而避免wraparound
wal writer
定期将wal_buffers缓冲区的日志写入磁盘 延迟写入,最多是wal_writer_delay周期时间的三倍。
checkpointer
数据库采用wal机制,日志落盘,内存数据异步落盘,数据库重启时,内存还没落盘导致数据丢失,所以需要重放wal日志恢复内存中的数据,不过wal日志会累计变大,导致恢复时间很长,用checkpoint机制,定期将缓存刷新到磁盘。数据的恢复只需要从刷新点开始重放wal日志。
触发条件
1.时间触发:距离上次执行时间间隔超过指定值(checkpoint_timeout)
2.wal日志:当最新的wal日志和上次checkpoint的刷新点的距离大于指定值checkpoint_complete_target
3.手动触发
4.数据库关闭
5.基础备份
6.数据库崩溃修复
其他线程
archiver 将wal日志拷贝备份目录
StatCollector 统计信息收集线程
SysLogger 日志线程,将消息或错误信息写入日志
auditor 审计线程
openGauss存储结构
安装后目录
根据配置文件中的内容,主要目录如下
openGauss安装目录 /opt/huawei/install/app
openGauss数据目录 /opt/huawei/install/data/dn
openGauss日志目录 /var/log/omm/用户名
openGauss系统工具目录 /opt/huawei/install/om
openGauss临时文件目录 /opt/huawei/tmp
/opt/huawei/install/data/dn/
global 元数据、数据字典 存放目录
base 默认表空间
pg_tblspc 用户指定表空间
oid和relfilenode
oid不变,relfilenode会变
openGauss=# select oid,relfilenode from pg_class where relname='t1';
oid | relfilenode
-------+-------------
16384 | 16384
(1 row)
oopenGauss=# select pg_relation_filepath('t1'::regclass);
pg_relation_filepath
----------------------
base/15741/16384
(1 row)
create tablespace test_tbs relative location 'tablespace/testtbs01';
select oid,* from pg_tablespace;
16390
create table t2 (id number) tablespace test_tbs;
openGauss=# select oid,relfilenode from pg_class where relname='t2';
oid | relfilenode
-------+-------------
16391 | 16391
(1 row)
openGauss=# select pg_relation_filepath('t2'::regclass);
pg_relation_filepath
------------------------------------------------------
pg_tblspc/16390/PG_9.2_201611171_dn_6001/15741/16391
(1 row)
openGauss=# truncate table t2;
TRUNCATE TABLE
openGauss=# select oid,relfilenode from pg_class where relname='t2';
oid | relfilenode
-------+-------------
16391 | 16397
(1 row)
t1表没有指定表空间,所以创建在base目录下,t2表指定了表空间,所以在pg_tblspc目录下,对表t2进行truncate操作后,relfilenode变化。
oid 类似身份证号,relfilenode 户口本上的户号。地址变了,户号就会变。
truncate,vacuum full ,删除重建表都会导致relfilenode 变化。
日志和文件
告警日志位置(结合配置文件看) /var/log/omm/omm/pg_log/dn_6001
操作系统日志 vim /var/log/messages
日志收集 gs_collector --begin-time=“20250320 01:01” --end-time=“20250320
11:11” 解压 tar -xzvf collector_20250320_111114.tar.gz控制文件 /opt/huawei/install/data/dn/pg_control pg_controldata
/opt/huawei/install/data/dn/访问控制文件 pg_hba.conf
openGauss日常运维
数据库启停
查看服务状态 ps -ef |grep gauss
gs_om -t status --detail
gs_ctl status -D /opt/huawei/install/data/dn
启动 gs_om -t start
gs_ctl start -D /opt/huawei/install/data/dn
停止 gs_om -t stop
gs_ctl stop -D /opt/huawei/install/data/dn -m f 一致性 gs_ctl stop -D
/opt/huawei/install/data/dn -m i 非一致性
vacuum操作
表膨胀
有效数据量不变,表越来越大,扫描的效率变低。是因为opengauss的MVCC机制问题,在写数据时,旧数据不删除,把新数据插入,将旧数据标记为无效,清理之前一直占用空间。执行update的话就是insert+delete的原理,依然会导致表膨胀。
vacuum的作用 磁盘清理dead tuple ;更新统计信息;重组数据;解决事务ID回卷问题。 vacuum :
不要求获得排它锁,找到那些旧的“死”数据,标记为可用状态,不进行空间合并 vacuum full:
就是除了vacuum,进行空间合并,它需要lock table vacuum analyze:
更新统计信息,使得优化器能够选择更好的方案执行sql vacuum freeze: 表记录冻结,可解决事务id回卷的问题vacuum做了什么 1、清除update或delete 操作后留下的死元组 2、跟踪表块中可用空间,更新free space map
3、更新visibility map,index only scan 以及后续vacuum都会利用到 4、冻结表中的行,防止事务ID回卷
5、配合analyze ,定期更新统计信息FSM 简单来说,就是vacuum只是清理死元组,利用FSM可以高效的将空间管理起来,方便查找和重新使用。
visibility map
all_visible为t表示全部可见,不包含死元组,作用是加快vacuum,进行vacuum时,当扫描到all_visible为t时,则直接跳过。
检查openGauss状态
检查实例状态 gs_check -U omm -i CheckClusterState
检查锁信息
锁机制是数据库保证数据一致性的重要手段,检查相关信息可以检查数据库的事务和运行状况。
查询数据库中的锁信息 openGauss=# SELECT * FROM pg_locks;
查询等待锁的线程状态信息 openGauss=# SELECT * FROM pg_thread_wait_status WHERE
wait_status = ‘acquire lock’;
统计事件数据
SQL语句长时间运行会占用大量系统资源,用户可以通过查看事件发生的时间,占用内存大小来了解现在数据库运行状态。
查询事件的线程启动时间、事务启动时间、SQL启动时间以及状态变更时间。 openGauss=# SELECT
backend_start,xact_start,query_start,state_change FROM
pg_stat_activity;查询当前服务器的会话计数信息 openGauss=# SELECT count(*) FROM pg_stat_activity;
查询当前使用内存最多的会话信息。 openGauss=# SELECT * FROM pv_session_memory_detail()
ORDER BY usedsize desc limit 10;
对象检查
表、索引、分区、约束等是数据库的核心存储对象
查看表的详细信息 openGauss=# \d+ table_name
查询表统计信息 openGauss=# SELECT * FROM pg_statistic;
查看索引的详细信息 openGauss=# \d+ index_name
查询分区表信息 openGauss=# SELECT * FROM pg_partition;
查询约束信息 openGauss=# SELECT * FROM pg_constraint;
备份
指定用户导出数据库 gs_dump dbname -p port -f out.sql -U user_name -W password
导出schema gs_dump dbname -p port -n schema_name -f out.sql
导出table gs_dump dbname -p port -t table_name -f out.sql
检查数据库性能
- 以操作系统用户omm登录数据库主节点。
- 执行如下命令对openGauss数据库进行性能检查。
gs_checkperf
[omm@node1 15741]$ gs_checkperf Cluster statistics information:
Host CPU busy time ratio : 2.92 %
MPPDB CPU time % in busy time : 57.95 %
Shared Buffer Hit ratio : 60.06 %
In-memory sort ratio : 0
Physical Reads : 530109
Physical Writes : 16200
DB size : 67 MB
Total Physical writes : 16200
Active SQL count : 4
Session count
kill空闲连接
执行如下SQL语句,查看state字段等于idle,且state_change字段长时间没有更新过的连接信息。
openGauss=# SELECT * FROM pg_stat_activity where state=‘idle’ order by
state_change;释放空闲的连接数。
查看每个连接,并与此连接的使用者确认是否可以断开连接,或执行如下SQL语句释放连接。其中,pid为上一步查询中空闲连接所对应的pid字段值。openGauss=# SELECT pg_terminate_backend(140390132872976);
重建索引
如果数据发生大量删除后,索引页面上的索引键将被删除,但索引页面并不会直接删除,即索引页面数量并不会减少,因此会造成索引膨胀。重建索引可回收浪费的空间。
新建的索引中逻辑结构相邻的页面,通常在物理结构中也是相邻的,所以一个新建的索引比更新了多次的索引访问速度要快。 重建索引有以下两种方式:
先运行DROP INDEX语句删除索引,再运行CREATE INDEX语句创建索引。 在删除索引过程中,会在父表上增加一个短暂的排他锁,阻止相关读写操作。在创建索引过程中,会锁住写操作但是不会锁住读操作,此时读操作只能使用顺序扫描。
使用REINDEX语句重建索引。
- 使用REINDEX TABLE语句重建索引,会在重建过程中增加排他锁,阻止相关读写操作。
- 使用REINDEX INTERNAL TABLE语句重建desc表(包括列存表的cudesc表)的索引,会在重建过程中增加排他锁,阻止相关读写操作。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐
 10
10 0
0- 0



 已为社区贡献446条内容
已为社区贡献446条内容

所有评论(0)