机器学习--聚类算法之mean shift
聚类算法之mean shift1. mean shift的概念2. 算法解析2.1 算法流程2.2 算法公式3.mean shift的应用场景4.实例分析1. mean shift的概念相对于k-mean和k-mean++算法,mean shift(均值便宜)算法,都是基于聚类中心的聚类算法。但是,mean shift的优势在于不需要事先制定类别个数k(无监督学习)。mean shift的基本概念
聚类算法之mean shift
1. mean shift的概念
相对于k-mean和k-mean++算法,mean shift(均值偏移)算法,都是基于聚类中心的聚类算法。但是,mean shift的优势在于不需要事先制定类别个数k(无监督学习)。
mean shift的基本概念:沿着密度上升方向寻找聚簇点。
2. 算法解析
2.1 算法流程
设想在一个有N个样本点的特征空间,利用mean shift算法对数据进行分类
- 初始确定一个中心点center,计算在设置的半斤为D的圆形空间内所有的点与中心点center 的向量
- 计算整个圆形空间内所有向量的平均值,得到一个偏移均值
- 将中心点center移动到偏移均值位置
- 重复移动,直到满足一定条件结束
图一所示,绿色圈的中心以偏移向量的方向移动,一步一步移动,直到移动到红色圈的中心位置(此处是密度最大的地方)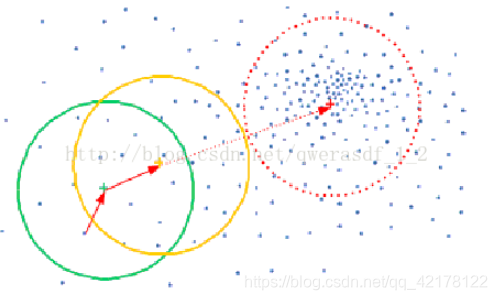
图二:先算出当前点的偏移均值,将该点移动到此偏移均值,然后以此为新的起始点,继续移动,直到满足最终的条件。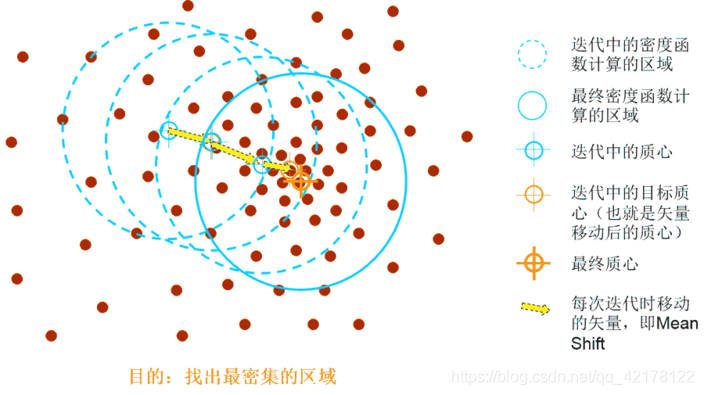
2.2 算法公式
偏移均值的公式: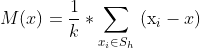
Sh:以x为中心点,半径为h的高维球区域; k:包含在Sh范围内点的个数; xi:包含在Sh范围内的点
中心更新:(将中心点朝向偏移均值的矢量方向移动)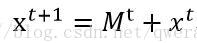
Mt为t状态下求得的偏移均值; xt为t状态下的中心
后来,Yizong Cheng对mean shift进行补充,主要提出了两点的改进:定义了核函数,增加了权重系数。核函数的定义使得偏移值对偏移向量的贡献随之样本与被偏移点的距离的不同而不同。权重系数使得不同样本的权重不同。
引入核函数的mean shift公式:
核函数:只是用来计算映射到高维空间之后的内积的一种简便方法,目的为让低维的不可分数据变成高维可分。利用核函数,可以忽略映射关系,直接在低维空间中完成计算(引用核函数的优势:能够使计算中距离中心的点具有更大的权值,反映距离越短,权值越大的特性)。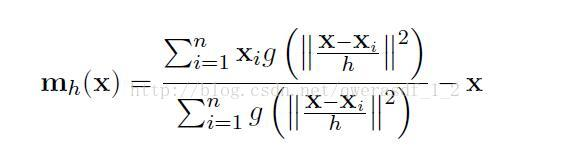
其中,x为中心点;xi为带宽范围内的点;n为带宽范围内的点的数量;g(x)为对核函数的导数求负
3.mean shift的应用场景
Mean Shift算法在很多领域都有成功应用,例如图像平滑、图像分割、物体跟踪等,这些属于人工智能里面模式识别或计算机视觉的部分;另外也包括常规的聚类应用。
- 图像平滑:图像最大质量下的像素压缩;
- 图像分割:跟图像平滑类似的应用,但最终是将可以平滑的图像进行分离已达到前后景或固定物理分割的目的;
- 目标跟踪:例如针对监控视频中某个人物的动态跟踪;
- 常规聚类,如用户聚类等
4.实例分析
基于均值漂移的分类:
- 在未被分类的数据点中随机选择一个点作为中心点;
- 找出离中心点距离在带宽之内的所有点,记做集合M,认为这些点属于簇c
- 计算从中心点开始到集合M中每个元素的向量,将这些向量相加,得到偏移向量
- 中心点沿着shift的方向移动,移动距离是偏移向量的模
- 重复步骤2、3、4,直到偏移向量的大小满足设定的阈值要求,记住此时的中心点
- 重复1、2、3、4、5直到所有的点都被归类
- 分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
参考链接:

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)