【openGauss】Oracle与openGauss/GaussDB数据一致性高效核对方案
抛开那种直接count算行数的极不精确算法,现有的异构数据库的数据核对工具,一般是把数据都查到工具的内存里,对日期时间数字等非文本类型,进行统一的格式化处理,将一行的所有字段拼成一个长字符串,然后hash一下,得到一个值,比较两个库这行数据得到的这个hash值是否一致,则可以知道这行数据是否一致。而且假设表上没有主键,就只能把所有字段作为主键;所以,这种场景下,客户更需要的是,上线的时候,核对工具
一种快速进行ORACLE和openGauss/GaussDB之间数据一致性核对的方案
背景
应用软件的信创改造中,在数据迁移后,对数据进行一致性核对是非常重要的一个环节。数据核对需要面对的考验有且不限于:
1、核对巨量数据的性能
2、异构数据库不同数据类型的统一格式化
3、源库和目标库可能使用不同的字符集
4、核对工具对源库和目标库之间的网络带宽
5、能否找到差异的行
但是一个反复测试多次且成熟的数据迁移软件,不应该在迁移后还存在数据不一致的情况。
想象一下,某个线上的软件项目,准备正式切换到国产数据库,一切准备就绪,源端和目标端的数据都是静止的,使用软件迁移数据后,如果发现存在数据差异,是去找差异原因,还是终止切换,进行回退呢?
所以,这种静态数据迁移,宁愿在项目上线前期,多次进行数据迁移及数据核对的测试,找到数据不一致的原因并进行相关软件和实施方案的调整,确保上线时能保证数据符合预期的一致性标准,而不是在时间窗口极度有限的上线那天,靠着数据核对工具强大的算法去精确找到那行数据有差异。
所以,这种场景下,客户更需要的是,上线的时候,核对工具用最快的速度,直接告诉我,这两边数据是不是一致的,而不是经过很长一段时间的数据核对后,精确地告诉我差异在哪。
在这种背景下,催生出了下文的这种数据核对方案。
分析思路
抛开那种直接count算行数的极不精确算法,现有的异构数据库的数据核对工具,一般是把数据都查到工具的内存里,对日期时间数字等非文本类型,进行统一的格式化处理,将一行的所有字段拼成一个长字符串,然后hash一下,得到一个值,比较两个库这行数据得到的这个hash值是否一致,则可以知道这行数据是否一致。
但是这种方式需要把数据全部取到工具里,消耗了大量的网络带宽以及内存;而且假设表上没有主键,就只能把所有字段作为主键;如果数据量超大,需要分批核对,就必然要排序,遇上没有主键的表就是全字段排序,性能就极差了。
而我们设计的核对方案,需要规避上述的这些缺点,所以:
1、禁止排序
2、禁止将原表数据全部取到工具里
3、不按每行数据核对,直接按表级核对
也就是说,我们需要在两个数据库中,设计一种相同的计算方式,将整个表的所有列所有行的数据,浓缩成一个值,且这个值的计算不依赖数据行在表中的顺序。
不依赖顺序,最简单的就是加法,也就是说,我们可以针对每行数据,转换成一个数值,然后把数值相加,得到整个表的特征值(checksum)。
然后就是要解决如何把一行数据按照相同的格式拼成一个字符串。
在ORACLE里写过用存储过程导出数据的大多应该都知道,识别字段数据类型来进行不同的格式化处理其实很简单,用dbms_sql就行,但是难点在于管道符拼接。SQL里最长只能拼4000字节,PLSQL里最长只能拼32767字节,再长就只能在plsql里用dbms_lob去拼lob了。这样甚至可能需要在两边数据库创建相同的存储过程,而且整个拼接过程是在plsql里,需要逐行逐个字段循环,性能也不会好到哪去。
所以需要找到ORACLE和openGauss是否有自带的函数,能实现把格式化好的后一行多列的数据转换成一个值,而且这一列能超过4000字节长度的限制。这个时候我自然就想到了ORACLE 19C里的json_object和openGauss中的row_to_json这两个函数。
json_object是ORACLE12C引入的,但是当时并不完善,只能返回成varchar2类型,即限制了一个json的长度,但在19C中,可以直接返回成CLOB/BLOB类型,这样放下一整行数据就基本不在话下了。但是 json_object和 row_to_json存在一些差异,json_object(*)返回的key是大写,而 row_to_json返回的key是小写,这是由于两个数据库对标识符的默认大小写差异引起的。所以格式化字段时,需要强制指定别名并带上双引号,来确保两边的字段名也是一致的。
openGauss里也有json_object,为什么不用呢?一是因为openGauss里的json_object不支持直接传 *,得自己按指定的语法传key和value;二是因为它返回的json里,中间穿插了空格,而ORACLE里并不会有这些空格,这一点点的格式差异对于数据核对来说是致命的。
一行拼成一个长文本串了,下一步就是把这个值转换成一个数字。这个转换方式需要尽量避免自己在plsql里写算法细节,因为肯定性能会不如数据库自带函数。但是我并没有找到两个数据库里有哪个相同的函数能直接把一个长字符串转换成一个数字的。
只能退而求其次,把这个长字符串转换成md5值,然后再把这个md5用某种算法转换成数字。
方案梳理
1、指定需要核对的一个表或者一段select查询语句
2、使用dbms_sql对这个表的查询进行字段类型解析,组装格式化的SQL
3、组装时,把每种数据类型都格式化成字符串,且用双引号指定字段名
4、生成ORACLE的SQL时,用 select json_object(t.* returning blob) from (select 格式化字段列表 from (表或查询)) t,生成opengauss的SQL时,用 select row_to_json(t) from (select 格式化字段列表 from (表或查询)) t
5、对这两个查询再套个md5,oracle用 dbms_crypto.hash(:value,2),opengauss用 md5(:value)
6、把md5值拆成四段,每段分别转换成对应的整型数值,然后相加
7、用sum函数聚合md5转换出来的数值,SQL拼接完成
8、在两个库分别执行对应的SQL,各自返回一个数值
9、比较这两个数值是否相等
10、如果相等,则被查的表数据一致;否则,不一致
补充:这整个方案其实可以不需要再在数据库中创建对象,调用dbms_sql是可以使用匿名块的,ORACLE绑定变量出来很容易,至于md5转换成数字的算法也非常简单,直接内联到sql里即可。
编写工具
思路原理出来了,接下来就是开发工具。
首先我把SQL组装的匿名块写出来了,因为我知道这是AI目前可能不太擅长但我非常擅长的事。然后就把思路告诉AI,让它使用java开发出了一个工具(promot不小心删了,里面主要说明了配置文件里可以配置什么东西,以及程序运行的机制)。
然后AI就把工具写好了,下面是AI生成的readme
Oracle与GaussDB数据一致性校验工具
概述
本工具是一款用于校验Oracle与GaussDB之间数据一致性的工具。通过MD5算法,对两个数据库中的相同表进行哈希计算和并比较结果,从而判断数据是否一致。
原理
1、连接ORACLE,使用ORACLE的dbms_sql解析每个字段的字段名和字段类型
2、将每个字段按照不同的数据类型进行格式化,拼接成长文本(ORACLE中使用json returning blob,可超4000长度)
3、计算长文本的MD5,并切割成4个有符号整型值相加,将整列进行sum求和
4、在两个数据库中分别执行相同逻辑的SQL,比较结果数值
5、如果两个数值相等,则数据一致;否则数据不一致
文件说明
DataConsistencyChecker.java - 主程序文件
config.yml - YAML格式配置文件
config.yml.example - 详细的YAML配置示例
build.sh / build.bat - 编译脚本
run.sh / run.bat - 执行脚本
README.md - 说明文档
环境要求
JDK 1.8 或更高版本
cmd(Windows)或 Bash(Linux)
Oracle数据库连接权限(需要DBA_TABLES视图访问权限,dbms_crypto执行权限)
GaussDB数据库连接权限
相应的JDBC驱动jar包
SnakeYAML库(放置在lib目录下)
ORACLE服务端 19c以上 (12c实测不支持)
安装步骤
1、准备依赖库
创建lib目录
下载并放置SnakeYAML库到lib目录
下载并放置Oracle JDBC驱动到lib目录
下载并放置GaussDB JDBC驱动到lib目录
2、配置数据库连接
复制 config.yml.example 为 config.yml
编辑 config.yml 文件
填写Oracle和GaussDB的连接信息
配置需要检查的表名(支持schema.table格式)或自定义SQL
3、编译程序
# Windows
build.bat
# Linux
./build.sh
运行程序
# Windows - 使用默认config.yml
run.bat
# Windows - 使用指定配置文件
run.bat my_config.yml
# Linux - 使用默认config.yml
./run.sh
# Linux - 使用指定配置文件
./run.sh my_config.yml
命令行参数
工具支持通过命令行参数指定配置文件:
# 直接使用Java运行
java -cp ".;lib/*" DataConsistencyChecker [config_file]
# 使用脚本运行
.\run.bat [config_file] # Windows
./run.sh [config_file] # Linux
如果不指定配置文件参数,将默认使用 config.yml。
配置文件说明
配置文件使用YAML格式,具有更好的可读性和灵活性:
数据库连接配置
databases:
oracle:
url: "jdbc:oracle:thin:@localhost:1521:orcl"
user: "username"
password: "password"
driver_jar: "ojdbc8-12.2.0.1.jar"
gauss:
url: "jdbc:postgresql://localhost:5432/dbname"
user: "username"
password: "password"
driver_jar: "gsjdbc4-1.1.jar"
检查范围配置
performance:
thread_count: 4
check_scope:
# Schema映射配置:Oracle schema -> GaussDB schema
schema_mapping:
system: public # Oracle的system schema映射到GaussDB的public schema
hr: hr_schema # Oracle的hr schema映射到GaussDB的hr_schema
# Schema列表:自动从Oracle中查询指定schema下的所有表
schemas:
- system # 自动查询system schema下的所有表并加入检查范围
- hr # 自动查询hr schema下的所有表并加入检查范围
# 表列表(支持换行,支持schema.table格式)
tables:
- hr.employees
- hr.departments
- sales.customers
# 自定义SQL(支持多行,不受分号影响)
custom_sqls:
- name: "近期订单数据"
sql: |
SELECT * FROM finance.orders
WHERE order_date >= '2023-01-01'
AND status IN ('PENDING', 'PROCESSING')
- name: "包含分号的查询"
sql: |
SELECT
CASE
WHEN price > 100 THEN 'High; Premium'
ELSE 'Low; Basic'
END as category
FROM products
使用示例
- 检查指定schema下的所有表
check_scope:
schema_mapping:
system: public
hr: hr_schema
schemas:
- system # 自动发现system schema下的所有表
- hr # 自动发现hr schema下的所有表
tables: [] # 可为空,由schemas自动填充
custom_sqls: []
- 检查特定表
check_scope:
schema_mapping:
hr: hr_schema
system: public
schemas: [] # 不使用自动发现
tables:
- hr.employees
- hr.departments
- sales.customers
custom_sqls: []
- 检查自定义查询
check_scope:
schemas: []
tables: []
custom_sqls:
- name: "大表分区数据"
sql: |
SELECT * FROM large_table
WHERE partition_key = '2023'
- name: "汇总统计"
sql: "SELECT count(*) FROM summary_table"
- 混合检查(推荐)
check_scope:
schema_mapping:
system: public
hr: hr_schema
schemas:
- system # 自动发现system schema下的所有表
tables:
- hr.specific_table # 另外指定特定表
custom_sqls:
- name: "近期数据"
sql: |
SELECT * FROM sales.large_table
WHERE create_time > sysdate - 30
执行流程
1、Schema扩展: 如果配置了schema列表,从Oracle中查询并自动添加表到检查列表
2、表排序: 根据Oracle统计信息按表大小排序(从大到小)
3、SQL生成: 为每个表和自定义SQL生成格式化的checksum查询
4、并发执行: 同时在Oracle和GaussDB中执行相应的查询
5、结果比较: 比较两个数据库的checksum结果
6、报告生成: 生成详细报告和汇总报告
错误处理
工具具有强大的错误处理能力:
不中断执行: 即使某些表或SQL执行失败,程序会继续处理其他项目
详细错误记录: 所有错误都会记录在日志和报告中
错误分类: 区分SQL生成错误和执行错误
graceful degradation: 程序在遇到错误时优雅降级,而不是崩溃
错误类型
SQL生成错误: 表不存在、字段无效、语法错误等
执行错误: 数据库连接问题、权限不足、查询超时等
配置错误: 配置文件格式错误、连接参数无效等
报告说明
工具会在 reports 目录下生成两种报告:
详细报告 (detail_report_yyyyMMdd_HHmmss.txt)
每个检查项目的具体结果
Oracle和GaussDB的checksum值
一致性状态
错误信息(如有)
汇总报告 (summary_report_yyyyMMdd_HHmmss.txt)
总配置项目数
SQL生成失败项目数
数据一致、不一致、执行失败的统计
数据一致性率(基于有效SQL的一致性百分比)
各类问题项目列表
注意事项
1、权限要求: 确保Oracle用户有DBA_TABLES及查询表的权限
2、网络连接: 确保可以同时连接到Oracle和GaussDB
3、资源使用: 并发线程数建议根据数据库性能调整
4、数据类型: 工具会跳过某些不支持的数据类型(如BLOB、CLOB等)
5、时间格式: 日期时间字段会被格式化为统一格式进行比较
6、YAML格式优势:
支持多行SQL,便于阅读和维护
不受SQL中分号影响
支持注释,便于文档化
层次结构清晰,易于理解
表名支持换行列表,便于管理
支持schema级别的自动表发现功能
故障排除
常见错误
1、编译失败
检查JDK版本是否为1.8+
确保源文件编码为UTF-8
2、连接失败
检查数据库连接字符串是否正确
确保JDBC驱动jar包和SnakeYAML库存在且正确
验证用户名密码是否正确
3、权限错误
确保Oracle用户有dbms_crypto的执行权限
确保Oracle用户有DBA_TABLES视图的SELECT权限
检查对所有需要校验表的SELECT权限
4、内存不足
减少并发线程数
分批处理大表
日志查看
程序运行时会在控制台输出详细的执行信息,包括:
初始化状态
各项检查的执行进度
错误信息
最终结果统计
技术支持
如遇到问题,请检查:
配置文件是否正确
数据库连接是否正常
权限是否充足
JDBC驱动是否匹配
更多技术细节请参考源代码注释。
执行流程: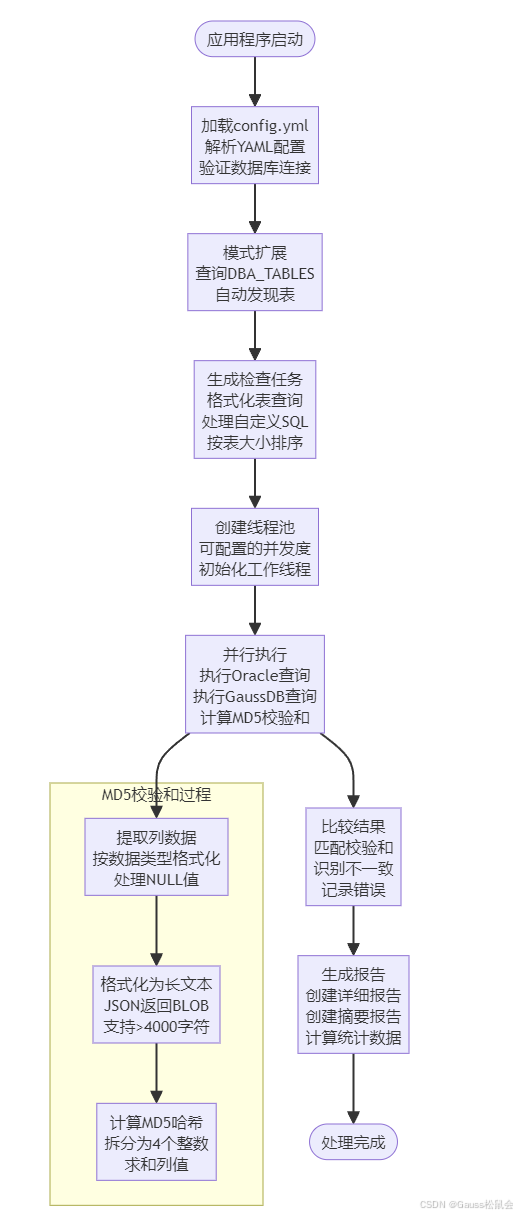
项目开源地址:https://gitee.com/darkathena/data-check-tool
源码解读wiki (en): https://deepwiki.com/Dark-Athena/data-check-tool
源码解读wiki (cn): https://gitee.com/darkathena/data-check-tool/wikis

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 16
16 0
0- 0



 已为社区贡献453条内容
已为社区贡献453条内容

所有评论(0)