解决ValueError: too many values to unpack
bug解决
·
遇到了两次上述的bug,特此来记录一下,第一个来自于加载权重部分,第二个来自于代码运行时。
首先看第一个:
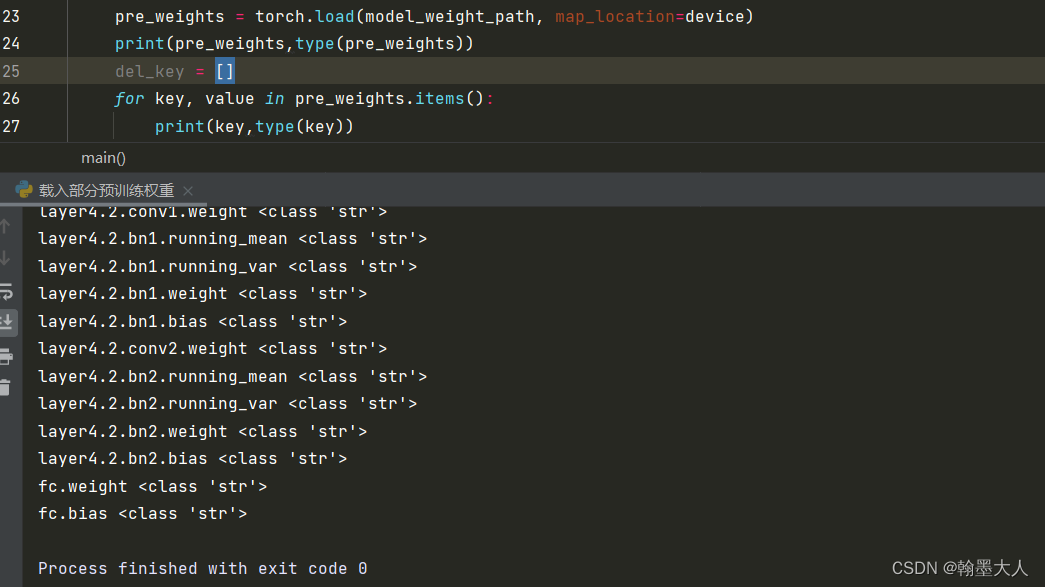
pre_weights = torch.load(model_weight_path, map_location=device)
print(pre_weights,type(pre_weights))
del_key = []
for key, value in pre_weights:
print(key,type(key))当我运行上述代码会发生错误:
Traceback (most recent call last):
File "D:\PycharmProjects\python function\预训练权重\载入部分预训练权重.py", line 38, in <module>
main()
File "D:\PycharmProjects\python function\预训练权重\载入部分预训练权重.py", line 26, in main
for key, value in pre_weights:
ValueError: too many values to unpack (expected 2)报错原因是因为有太多的值需要解压,其中pre_weights是一个有序字典,里面包含了网络的参数,将过查询发现遍历字典需要在字典后面增加items函数,items函数返回一个可遍历的键值对列表。这个是python基础的语法错误。
修改后正确运行:

第二个是代码:在运行到如下一行时发生错误,说明要么输入的少了或多了,要么输出的少了或多了。
encoded1,encoded2 = self.encoder(emb1,emb2)ValueError: too many values to unpack (expected 2)然后往上回溯,寻找到encoder函数。发现输入为两个,输出为三个,而看我的报错代码行,发现输出只有两个,所以是因为漏了一个输出。
def forward(self, fuse,out): #((1,196,256),(1,196,512))
attn_weights = []
for layer_block in self.layer:
emb1,emb2,weights = layer_block(fuse,out)
if self.vis:
attn_weights.append(weights)
emb1 = self.encoder_norm1(emb1) if emb1 is not None else None
emb2 = self.encoder_norm2(emb2) if emb2 is not None else None
return emb1,emb2,attn_weights修改代码即可正常运行。
encoded1,encoded2,attn_weights = self.encoder(emb1,emb2) 
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)