Elasticsearch如何提升查询效率
分析面试官问这个问题,一般就是向要考校你是否真的用过Elasticsearch分布式搜索引擎,对于查询效率的优化有没有真正的应用场景。es这个东西,真正来说并没有想象中那么牛逼。很多时候数据量太大的话,特别是如果有几亿条数据,搜索效率是很低的,第一次跑的时候你会发现在5-10秒之间,至于为什么第一次跑会这么久呢,下面会给你答案。我们要知道,对于一些现在运用的大部分主流技术,对于性能优化基本都是没有
分析
面试官问这个问题,一般就是向要考校你是否真的用过Elasticsearch分布式搜索引擎,对于查询效率的优化有没有真正的应用场景。
es这个东西,真正来说并没有想象中那么牛逼。很多时候数据量太大的话,特别是如果有几亿条数据,搜索效率是很低的,第一次跑的时候你会发现在5-10秒之间,至于为什么第一次跑会这么久呢,下面会给你答案。
我们要知道,对于一些现在运用的大部分主流技术,对于性能优化基本都是没有什么银弹的(指优化某一点就可以得到大的提升),不要期待随便修改一个参数配置之类的,就可以天下无敌。也许某个场景很适用,但是换个场景可能就凉凉了。
如何优化?
1、通过os cache磁盘缓存优化
当我们往es里面写数据的时候,实际上都是写到了磁盘文件中去了,而磁盘中的操作系统会自动将数据缓存到os cache中。
于是我们查询的时候就变成了这样:
- 当客户端访问es进程shard分片时,会先访问磁盘缓存区os cache
- 当磁盘缓存区检索不到数据时,再去磁盘文件中搜索
- 磁盘文件将数据返回,并且会在缓存区存储一份,所以下次查询的时候速度会非常快
- 缓存区再将数据向客户端返回
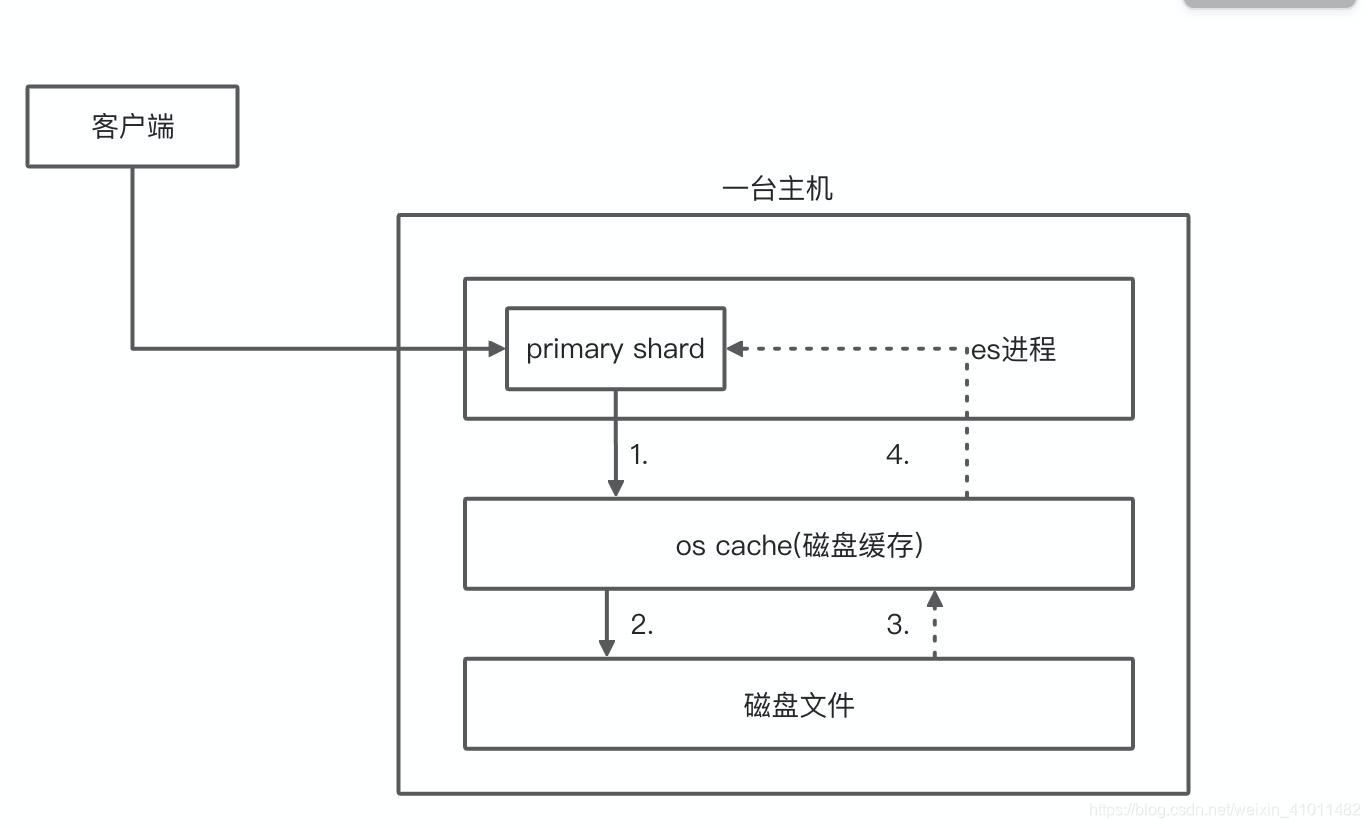
查询时候走磁盘和内存的性能差距有多大,我们测试的时候,从磁盘查询数据一般都是秒级的,1s、3s、5s都有。但是从内存os cache搜索数据的话,毫秒级绝对返回,一般就是几十毫秒到几百毫秒不等。
给大家举个例子,比如现在你有500G的es数据,都已经存在了一个主机的磁盘中,这个主机的内存区配置为32G。那你查询数据的时候内存中只存在全部数据中的%6.4,其余百分之90多都是要查询磁盘文件,那效率肯定上不去啊。
所以我们分配数据的时候,尽量把一些主要数据存在es磁盘文件中,并且数据量不要比磁盘内存去大太多。比如:es中可以存储一些关键字,名字、号码、邮箱之类的数据,拿到主数据key之后再去hbase中查询全部数据,这样一来效率就高了许多
2、缓存预热
根据es优先查询内存缓冲区的特性,我们就可以将一些热点数据提前刷到缓存中,这样用户访问的时候可以一定程度上提升效率。
比如:某个索引数据中,有10%在中午的时候属于热点数据。那么每到中午时,我可以提前在访问峰值之前,先用自己的程序搜索一下这些热点数据。保证它们存在内存缓冲区中,那是不是用户访问的这部分热点数据的时候就不用访问磁盘文件了。自然就提升了一部分效率
3、冷热分离
根据第2点,我们做了数据预热,但是其他数据并不是没有用户访问呀。当个别用户访问一些冷门数据的时候,依然会把它存在内存缓冲区,那这样一来不就把热点数据挤掉了吗。
那我们就可以根据数据的热度,将热门数据放在一个索引中,冷门数据放在另一个索引中,防止内存缓冲区中热门数据被挤掉的过多,从而影响效率。当数据做了冷热分离,那么大部分的热门数据一直存在于内存内存缓冲区,那么也能在一定程度上提升效率
4、document设计模型
我们都知道,在mysql或者oracle数据库中都有多表查询,通过某一个字段join一下另一张表,如果数据库索引用得好的话,对性能基本不会有什么影响。
但是!重点来了,es的document索引搜索的时候,最好不要这么做,es索引如果做关联查询的话是很浪费性能的。这时候就需要在设计索引的时候就将需要关联的数据放在同一个索引中,或者放在java工程中去去做关联,避免es搜索的时候做一些复杂的关联操作。虽然es是支持这个功能,但是并不提倡使用。
5、分页查询优化
es的分页性能是比较坑的,为什么呢?举个例子,当我们现在每页10条数据,当前要查询第100页,那么es的协调节点会把每一个shard的千1000条数据都拿过来,如果有5个shard,那么就会有5000条数据。再把这5000条数据排序,取990-1000条。那么这样一来页数越大,那性能肯定就越低咯。
所以这个该如何优化呢
- 一个是比较流氓的方法,你就直接告诉产品经理,尽量不要让用户翻大的页面查询,如果真的要查询,那就默认接受查询性能低下。(这时候容易和产品经理打起来)
- 另一种比较靠谱,可以通过scroll进行查询优化,但是只能让用户一页一页的往后翻,因为scroll api是通过一个游标查询去暂时记录当前获取数据的下一页,这样获取下一页的时候可以直接返回。相当于一个数据快照之类的,所损失的就是不能跳转页,只能一页一页的往后翻。当然这个scroll我们可以自己设置超时时间,一段时间不访问之后会自动释放掉。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)