Mongo 服务器上的 CPU 使用率很高,但 Mongo 似乎处于空闲状态
设置:我们在 4.2.13 版本中运行 MongoDB。副本集,主副本和两个副本。服务器有 4 个 CPU 和 16 GB 的 RAM(m5.xlarge 实例和 gp2 磁盘)并且只专用于 Mongo。Primary 主要用于写入,而我们的读取主要从副本执行。我们正在运行 Mongo,默认配置和 transactionLifetimeLimitSeconds 设置为 900。问题:在负载测试期间
设置:
我们在 4.2.13 版本中运行 MongoDB。副本集,主副本和两个副本。服务器有 4 个 CPU 和 16 GB 的 RAM(m5.xlarge 实例和 gp2 磁盘)并且只专用于 Mongo。Primary 主要用于写入,而我们的读取主要从副本执行。
我们正在运行 Mongo,默认配置和 transactionLifetimeLimitSeconds 设置为 900。
问题:
在负载测试期间,我们经常遇到主节点卡住的情况。平均负载变为 ~9 )并且通过观察 mongotop 和 mongostat 似乎Mongo当时没有执行任何(重要的)数据库操作。
即使打开了探查器,我们也找不到任何提示(配置文件级别:1,记录速度低于 40 毫秒)。
当前的操作也没有向我们透露任何明显的异常以及查看 mongo 日志。
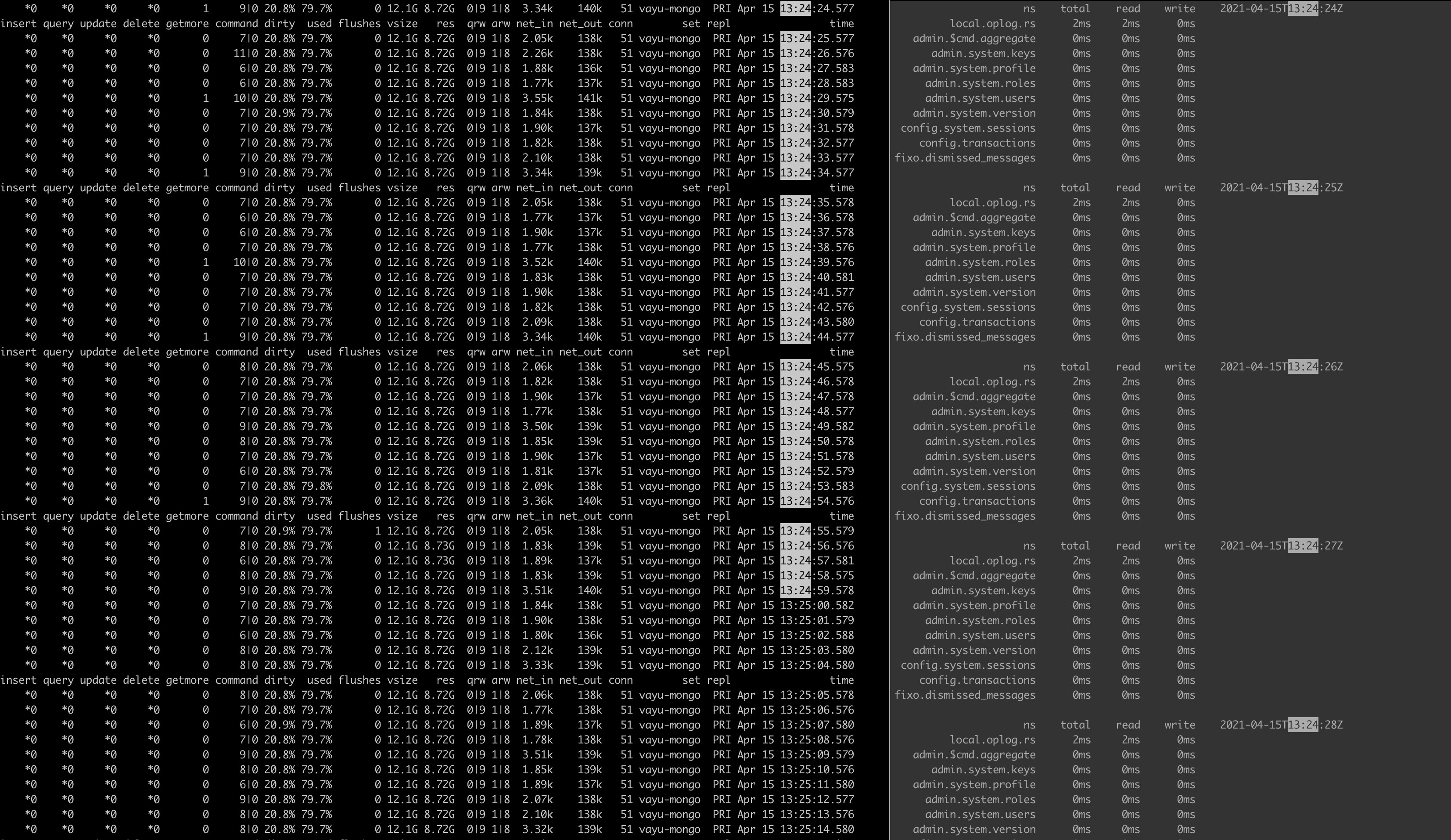
在 cpu 负载非常高的时候,我们的 mongostat 、 mongtop 输出切片:
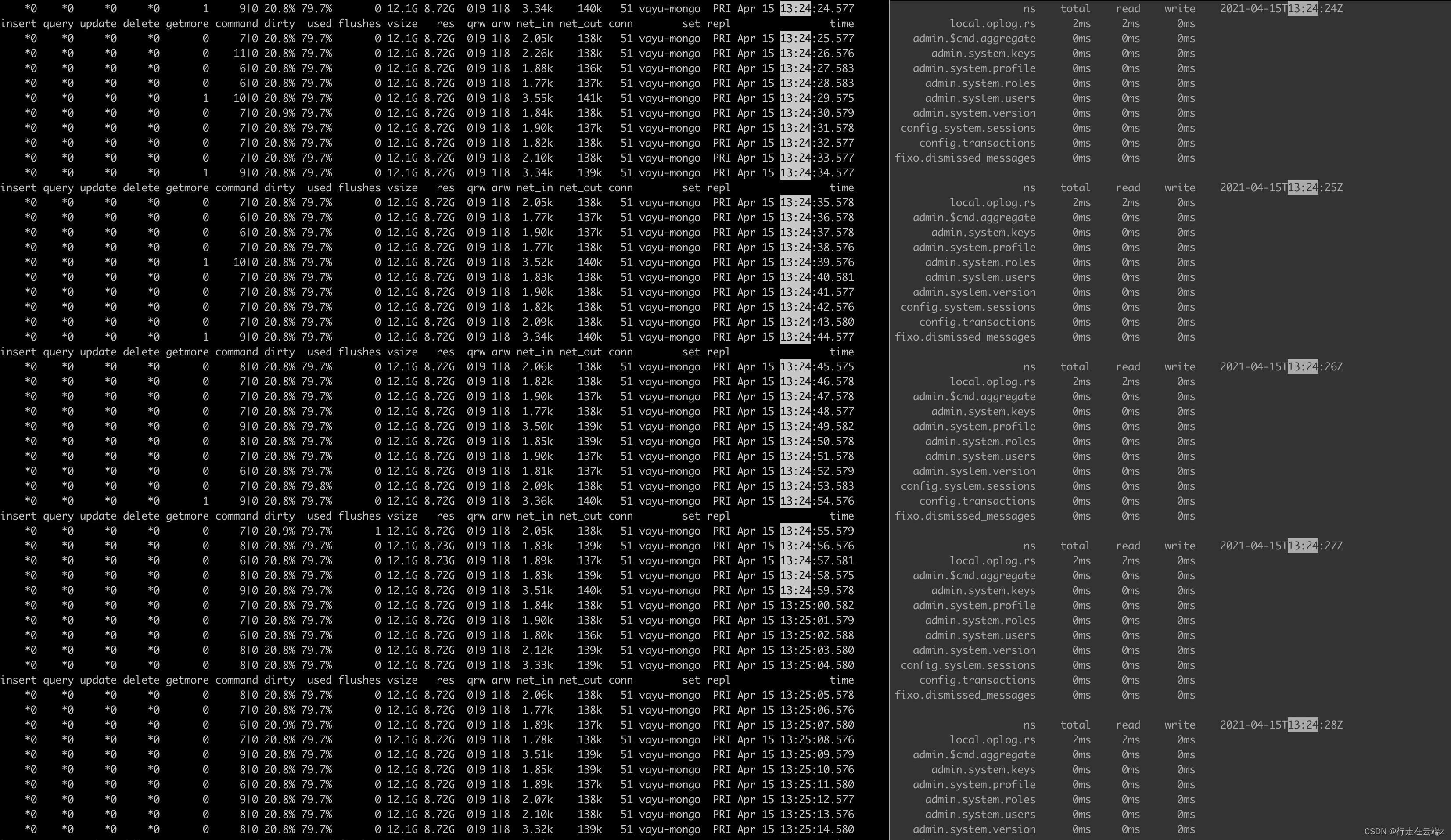
这段时间内的平均负载:
13:24:00 up 13 days, 23:04, 3 users, load average: 10.73, 9.43, 7.35
13:24:01 up 13 days, 23:04, 3 users, load average: 10.73, 9.43, 7.35
13:24:02 up 13 days, 23:04, 3 users, load average: 10.73, 9.43, 7.35
13:24:03 up 13 days, 23:04, 3 users, load average: 10.73, 9.43, 7.35
13:24:04 up 13 days, 23:04, 3 users, load average: 10.73, 9.43, 7.35
13:24:05 up 13 days, 23:04, 3 users, load average: 10.59, 9.42, 7.36
13:24:06 up 13 days, 23:04, 3 users, load average: 10.59, 9.42, 7.36
13:24:07 up 13 days, 23:04, 3 users, load average: 10.59, 9.42, 7.36
13:24:08 up 13 days, 23:04, 3 users, load average: 10.59, 9.42, 7.36
13:24:09 up 13 days, 23:04, 3 users, load average: 10.59, 9.42, 7.36
13:24:10 up 13 days, 23:04, 3 users, load average: 10.54, 9.43, 7.37
13:24:11 up 13 days, 23:04, 3 users, load average: 10.54, 9.43, 7.37
13:24:12 up 13 days, 23:04, 3 users, load average: 10.54, 9.43, 7.37
13:24:13 up 13 days, 23:04, 3 users, load average: 10.54, 9.43, 7.37
13:24:14 up 13 days, 23:04, 3 users, load average: 10.54, 9.43, 7.37
13:24:15 up 13 days, 23:04, 3 users, load average: 9.86, 9.31, 7.34
13:24:16 up 13 days, 23:04, 3 users, load average: 9.86, 9.31, 7.34
13:24:17 up 13 days, 23:04, 3 users, load average: 9.86, 9.31, 7.34
13:24:18 up 13 days, 23:04, 3 users, load average: 9.86, 9.31, 7.34
13:24:19 up 13 days, 23:04, 3 users, load average: 9.86, 9.31, 7.34
13:24:20 up 13 days, 23:04, 3 users, load average: 9.87, 9.32, 7.36
13:24:21 up 13 days, 23:04, 3 users, load average: 9.87, 9.32, 7.36
13:24:22 up 13 days, 23:04, 3 users, load average: 9.87, 9.32, 7.36
13:24:23 up 13 days, 23:04, 3 users, load average: 9.87, 9.32, 7.36
13:24:24 up 13 days, 23:04, 3 users, load average: 9.87, 9.32, 7.36
13:24:25 up 13 days, 23:04, 3 users, load average: 9.96, 9.35, 7.38
13:24:26 up 13 days, 23:04, 3 users, load average: 9.96, 9.35, 7.38
13:24:27 up 13 days, 23:04, 3 users, load average: 9.96, 9.35, 7.38
13:24:28 up 13 days, 23:04, 3 users, load average: 9.96, 9.35, 7.38
13:24:29 up 13 days, 23:04, 3 users, load average: 9.96, 9.35, 7.38
13:24:30 up 13 days, 23:04, 3 users, load average: 10.68, 9.51, 7.44
13:24:31 up 13 days, 23:04, 3 users, load average: 10.68, 9.51, 7.44
13:24:32 up 13 days, 23:04, 3 users, load average: 10.68, 9.51, 7.44
13:24:33 up 13 days, 23:04, 3 users, load average: 10.68, 9.51, 7.44
13:24:34 up 13 days, 23:04, 3 users, load average: 10.68, 9.51, 7.44
13:24:35 up 13 days, 23:04, 3 users, load average: 10.47, 9.48, 7.44
13:24:36 up 13 days, 23:04, 3 users, load average: 10.47, 9.48, 7.44
13:24:37 up 13 days, 23:04, 3 users, load average: 10.47, 9.48, 7.44
13:24:38 up 13 days, 23:04, 3 users, load average: 10.47, 9.48, 7.44
13:24:39 up 13 days, 23:04, 3 users, load average: 10.47, 9.48, 7.44
如果需要,我可以提供您在该时间段内从 db.serverStatus 中找到的任何相关信息。
任何确定此问题原因的线索将不胜感激。
你好@Sasa_Trifunovic欢迎来到社区!
乍一看,我从您的 mongostat 输出中看到您的dirty%数字超过 20%。在这个级别,服务器将停止处理传入的命令,并且会非常努力地将这些脏页刷新到磁盘。
的关键值dirty%是:
- 在 >5% 时,它将非常努力地刷新脏页,您应该会看到响应速度有所下降。
- 在 >20% 时,它将停止处理传入的工作以刷新脏页,您应该会看到服务器停止。
因此,尽管您在 mongostat 中看不到任何正在进行的操作,但我怀疑此时您会看到磁盘已充分利用,因为服务器正忙于处理积压的工作。
至于造成这种情况的原因,我认为主要有两点:
- 这表明您所做的工作超出了硬件的处理能力。配置更大的硬件应该可以缓解这种情况。
- 设置
transactionLifetimeLimitSeconds回其默认值也应该可以缓解这种情况。默认值为 30 秒,将其设置为 900(推荐值的 30 倍)将导致在大量事务使用期间内存使用量增加。
最好的问候
凯文
嗨凯文,
首先感谢您对我的帮助和欢迎。
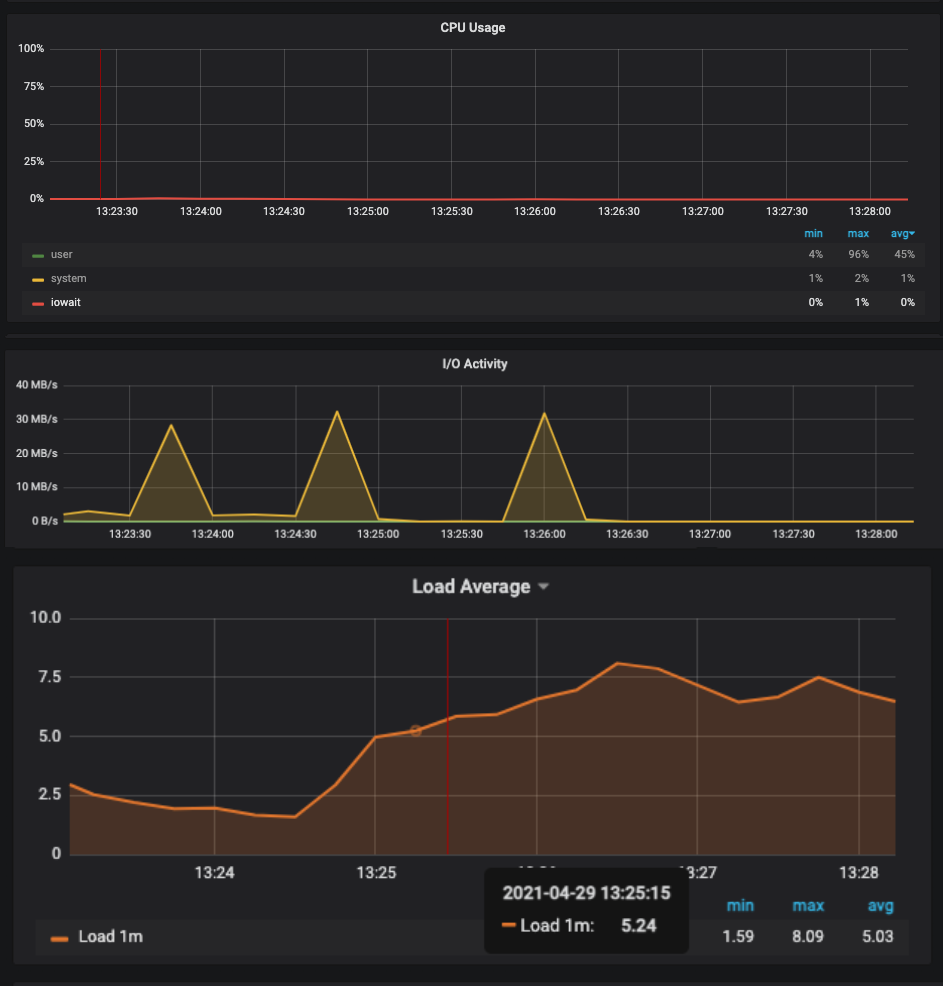
我们目前正在运行负载测试,正如之前发生的那样,Mongo 开始停滞,但我们的 gp2 磁盘并没有得到太多使用。似乎它们在(很少)爆发中被使用。我们还尝试使用 iotop 直接观察 io,这证实了我们在 Prometheus 上的指标,这意味着 io 是爆发式的,并且通过 aws 指标,磁盘未得到充分利用。
我们尝试将我们的实例提高到 m5.2xlarge(前一个的两倍),但是在第一次成功测试之后,当我们运行第二个时它也开始停止。
我们还尝试将交易时间限制在 60 秒,但这也无济于事。
昨天我们尝试降低写关注以消除复制问题,并以无序而不是有序的方式批量插入我们的记录,但这些都没有显示出任何改进。
再次感谢您指出脏页百分比的问题,如果您有更多见解,我们将不胜感激。
最好的,
萨沙
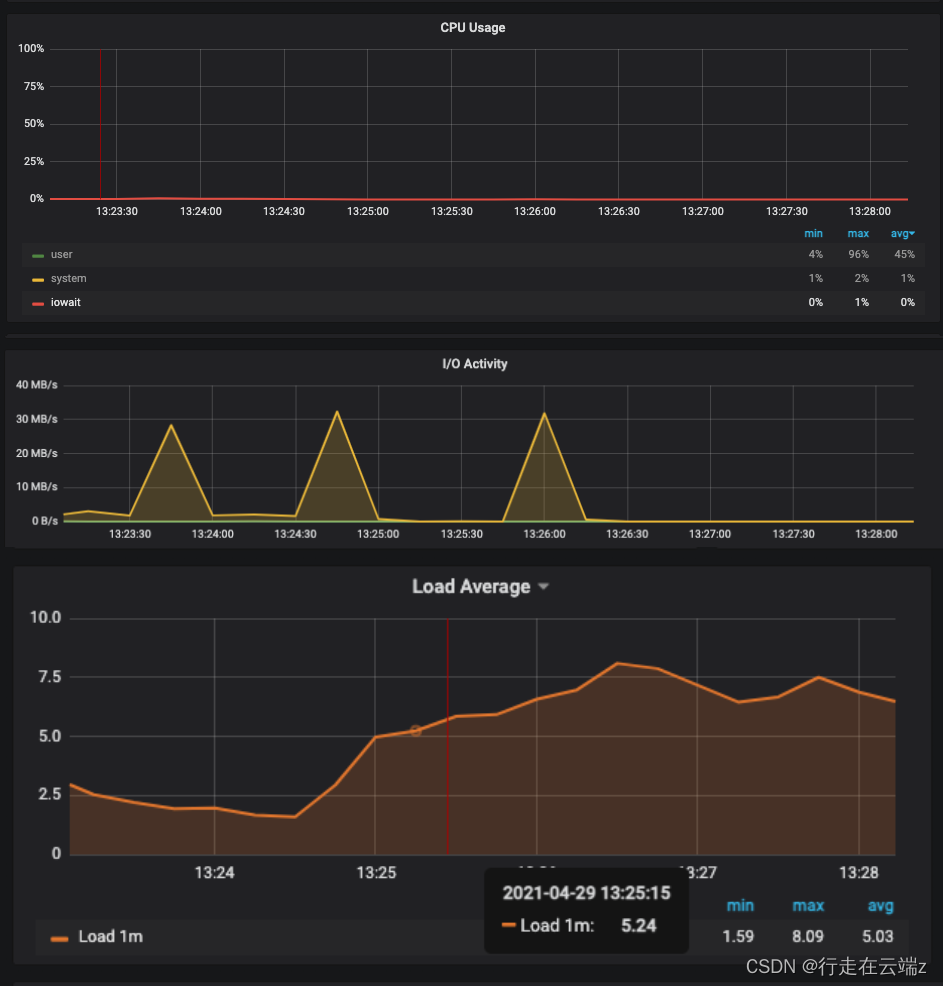
我已经看到 AWS 中的可突发实例存在一些问题。事情通常是这样进行的:
- 传入工作突然激增,这对于集群来说是不寻常的。
- 性能保持了一段时间,但即将到来的工作不断涌入。
- 由于传入工作的持续水平,磁盘/cpu 耗尽了突发信用。
- AWS 限制了磁盘/cpu 性能,因为实例用完了突发信用。
- 节点保持在其“基线”性能。此时,一切都在停滞不前,节点看起来未得到充分利用,由于节点性能受到 AWS 的限制,可以处理的工作积压非常少。
- 进来的工作停止进来,节点慢慢赶上工作并再次累积突发信用,最终一切恢复正常。
- 一组新的工作又进来了,我们又回到了(1)。
由于您使用的是 gp2 磁盘,我认为您遇到了这个突发信用问题。这在 gp2 下的 Amazon EBS 卷类型中进行了说明 15.
请注意,在大多数情况下,这种突发信用系统实际上是有益的。这使您可以处理突然的工作高峰,而无需为偶尔发生的事件配置更大的硬件。然而,这个想法是工作是一个峰值,而不是持续的负载。
如果您希望集群的正常状态与负载测试一致,那么使用预置的 iops 磁盘 15与使用 gp2 实例相比,可能是更好的选择。
最好的问候,
凯文
使用这个版本的 mongostat,在 linux 上,如何显示“dirty %”字段?
mongostat --version
mongostat 版本:100.5.0
git 版本:460c7e26f65c4ce86a0b99c46a559dccaba3a07d
Go 版本:go1.16.3
操作系统:linux
arch:amd64
编译器:gc
insert query update delete getmore 命令刷新映射的 vsize res 故障 qrw arw net_in net_out conn time
*0 *0 1 1094 0 2|0 0 0B 1.54G 111M 0 0|0 0|0 2.55m 18.3k 11 月 2 日 19:05: 57.139

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

{kind=link}
{kind=link}
所有评论(0)