基于华为开发者空间,使用Apache Spark实现商品推荐算法
通过本案例,开发者通过Hadoop、Spark对基于商品的信息做一些推荐的案例,可以掌握包括组件的安装,工程的创建、编译和运行。
1、 概述
1.1 实验介绍
Apache Spark 是强大的分布式计算框架,能高效处理大规模数据,具备 RDD、DataFrame 等核心组件。本实验利用其优势,结合商品详细信息及用户行为数据,采用基于用户/物品的协同过滤、矩阵分解等推荐算法,依次完成数据预处理、算法实现、模型训练评估与系统集成优化等流程,以此深入掌握 Spark 应用及推荐算法精髓,衡量系统推荐准确性、召回率等性能指标,为商品精准推荐及后续相关实践提供有力支撑。
通过本案例,开发者通过Hadoop、Spark对基于商品的信息做一些推荐的案例,可以掌握包括组件的安装,工程的创建、编译和运行。
1.2 实验对象
- 企业
- 个人开发者
- 高校学生
1.3 实验时间
本次实验总时长预计90分钟。
1.4 实验流程
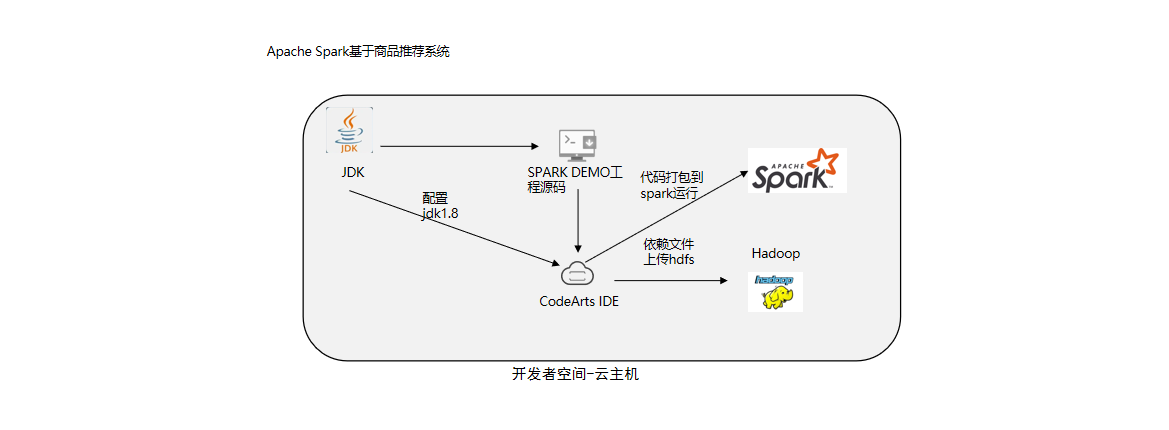
说明:
- 安装Java环境;
- 安装hadoop;
- 安装spark;
- 代码编写;
- 打包、运行结果。
1.5 实验资源
本次实验花费0元。
| 资源名称 | 规格 | 单价(元) | 时长(h) |
|---|---|---|---|
| JDK | 1.8 | 免费 | 1.5 |
| Hadoop | 3.3.5 | 免费 | 1.5 |
| Spark | 3.4.0 | 免费 | 1.5 |
| 华为开发者空间 - 云主机 | 鲲鹏通用计算增强型 kc2 | 4vCPUs | 8G | Ubuntu | 免费 | 1.5 |
基于Apache Spark实现商品推荐算法 👈👈👈体验完整版案例,点击这里。
2、 Spark环境安装搭建
2.1 安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
~的含义: 在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 后面的文字是注释,只需要输入前面命令即可。
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了。
2.2 安装Java环境
jdk1.8的安装包如下,请把压缩格式的文件jdk-8u391-linux-aarch64.tar.gz下载到云主机
复制下面链接到浏览器下载。
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0001/jdk-8u391-linux-aarch64.tar.gz
把安装包上传到/home/developer/Downloads的目录下执行如下命令:
sudo mkdir -p /usr/lib/jvm #创建/usr/lib/jvm目录用来存放JDK文件
sudo tar -zxvf /home/developer/Downloads/jdk-8u391-linux-aarch64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_391目录。
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc
使用vim编辑器,打开了developer这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_391
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
java -version
如果能够在屏幕上返回如下信息,则说明安装成功:

至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
2.3 安装Hadoop
Hadoop安装包如下,上传安装包到/home/developer/Downloads的目录下执行如下命令。
复制下面链接到浏览器下载:
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0001/hadoop-3.3.5.tar.gz
sudo tar -zxvf /home/developer/Downloads/hadoop-3.3.5.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.3.5/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R developer:developer ./hadoop
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version

Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
cd /usr/local/hadoop/etc/hadoop/
修改配置文件 core-site.xml
sudo vim core-site.xml
将之前配置如下:
<configuration>
</configuration>
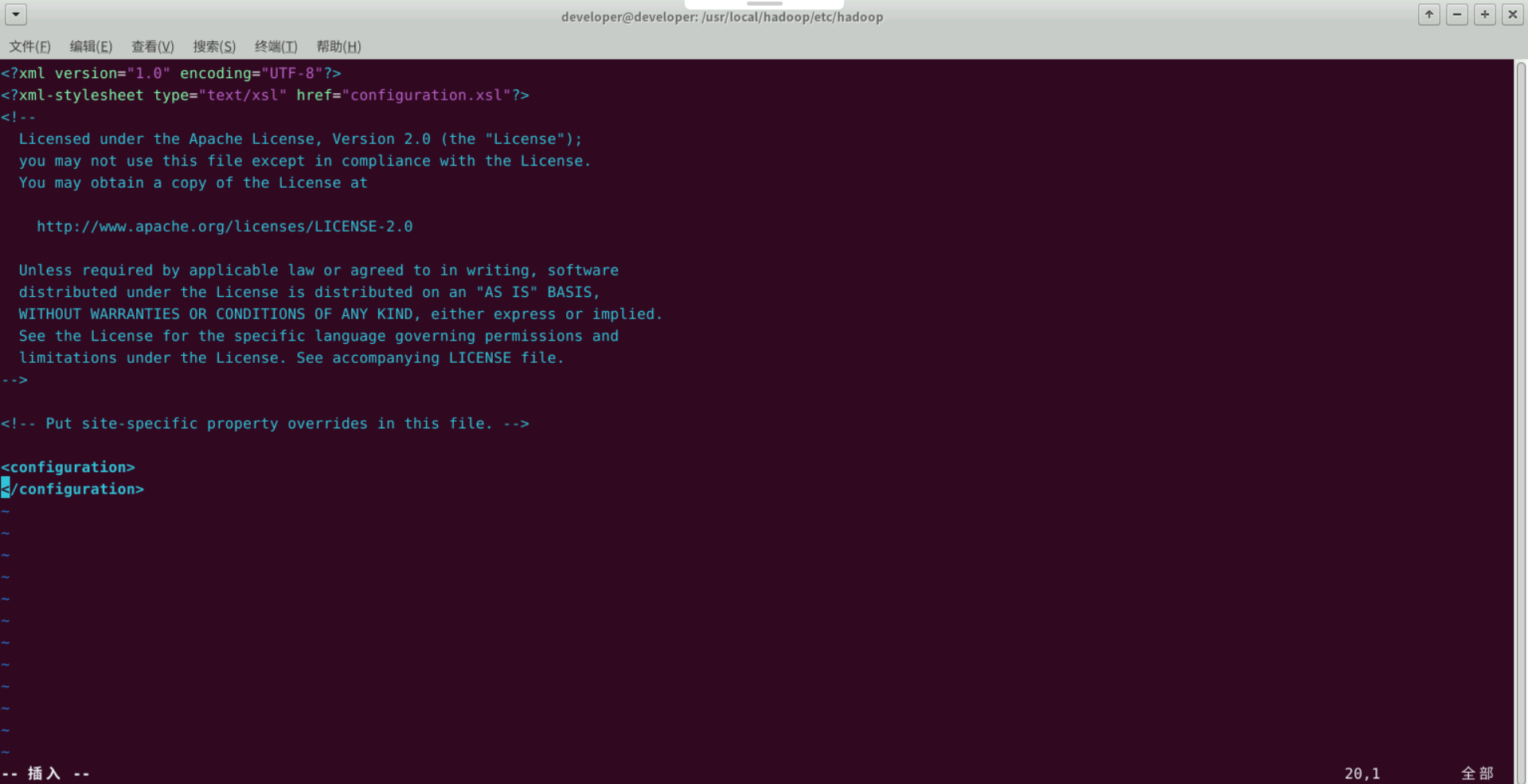
修改为下面的配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样的,修改配置文件 hdfs-site.xml:
sudo vim hdfs-site.xml
文件内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
Hadoop配置文件说明:
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
执行下面命令:
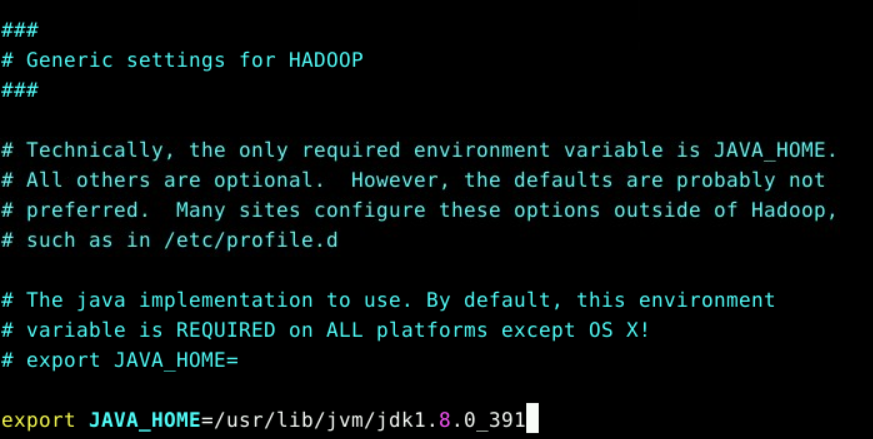
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_391
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 的提示,具体返回信息类似如下:
2024-11-18 14:28:30,560 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.3.5
*************************************************************/
......
2024-11-18 15:31:35,677 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name **has been successfully formatted**.
2024-11-18 15:31:35,700 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2024-11-18 15:31:35,770 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .
2024-11-18 15:31:35,810 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2024-11-18 15:31:35,816 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2024-11-18 15:31:35,816 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop/127.0.1.1
*************************************************************/
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh
成功启动后,可以访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
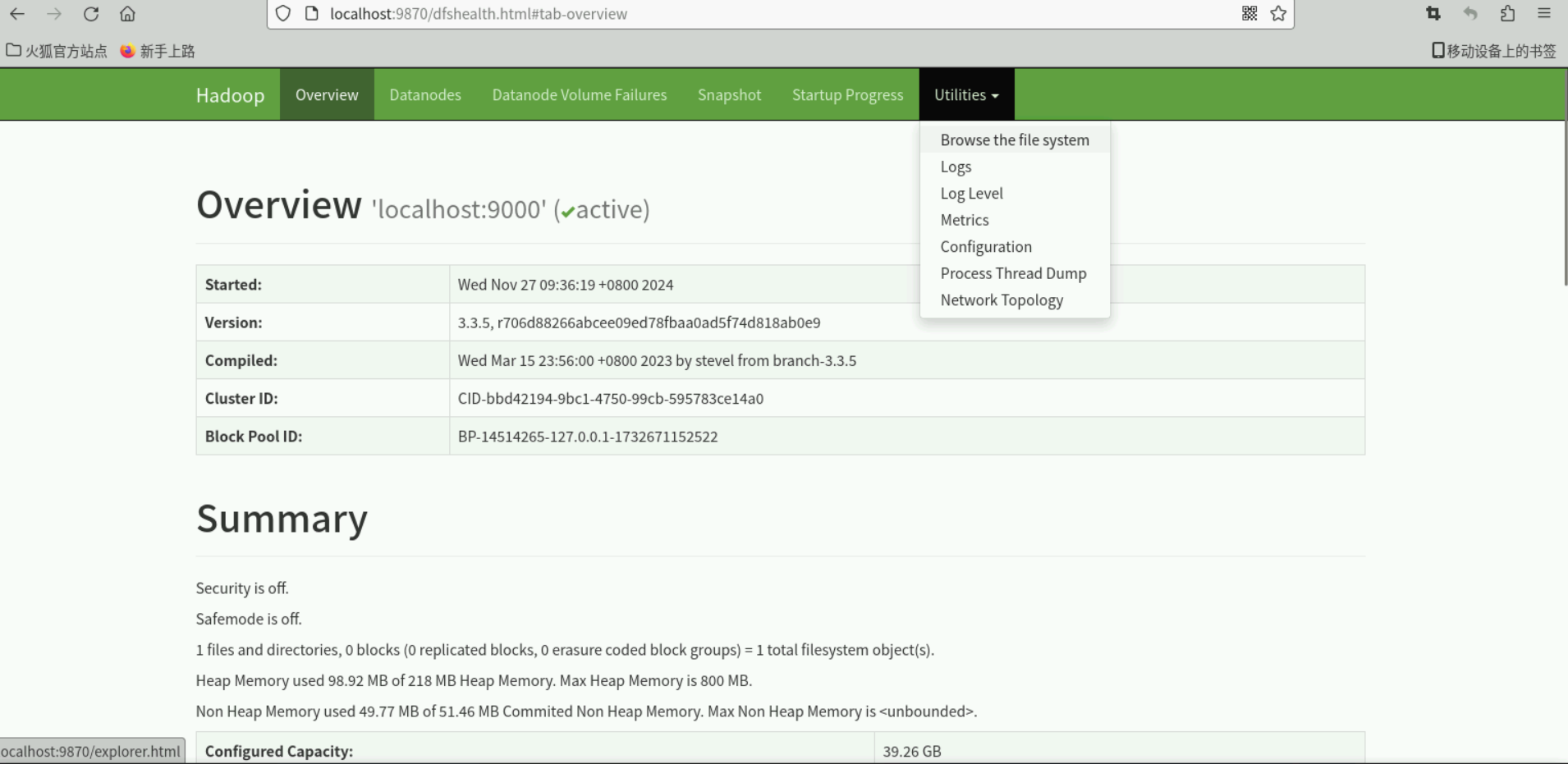
2.4 安装 Spark
将spark-3.4.0-bin-without-hadoop.tgz安装包放到/home/developer/Downloads的目录下执行如下命令。
复制下面链接到浏览器下载
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0001/spark-3.4.0-bin-without-hadoop.tgz
sudo tar -zxf /home/developer/Downloads/spark-3.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-3.4.0-bin-without-hadoop/ ./spark
安装后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
vim ./conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi
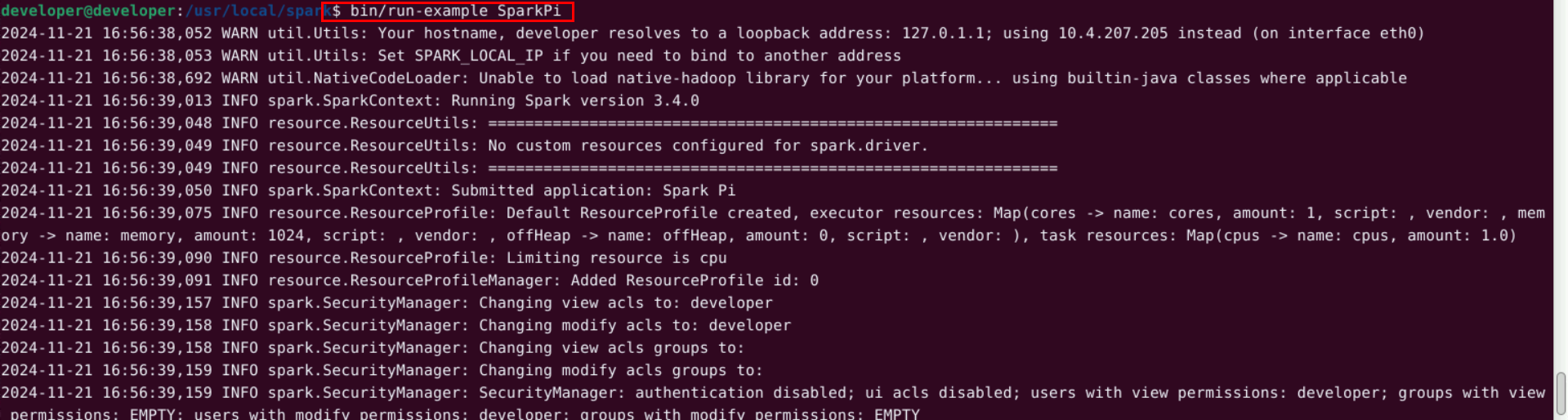
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
bin/run-example SparkPi 2>&1 | grep "Pi is"
运行结果如下,spark安装成功

3、推荐系统实现
3.1 编写代码
云主机桌面打开CodeArts IDE for Java 。

新建工程,名称自定义,位置默认,JDK选择之前安装的jdk1.8版本,构建系统选择maven。
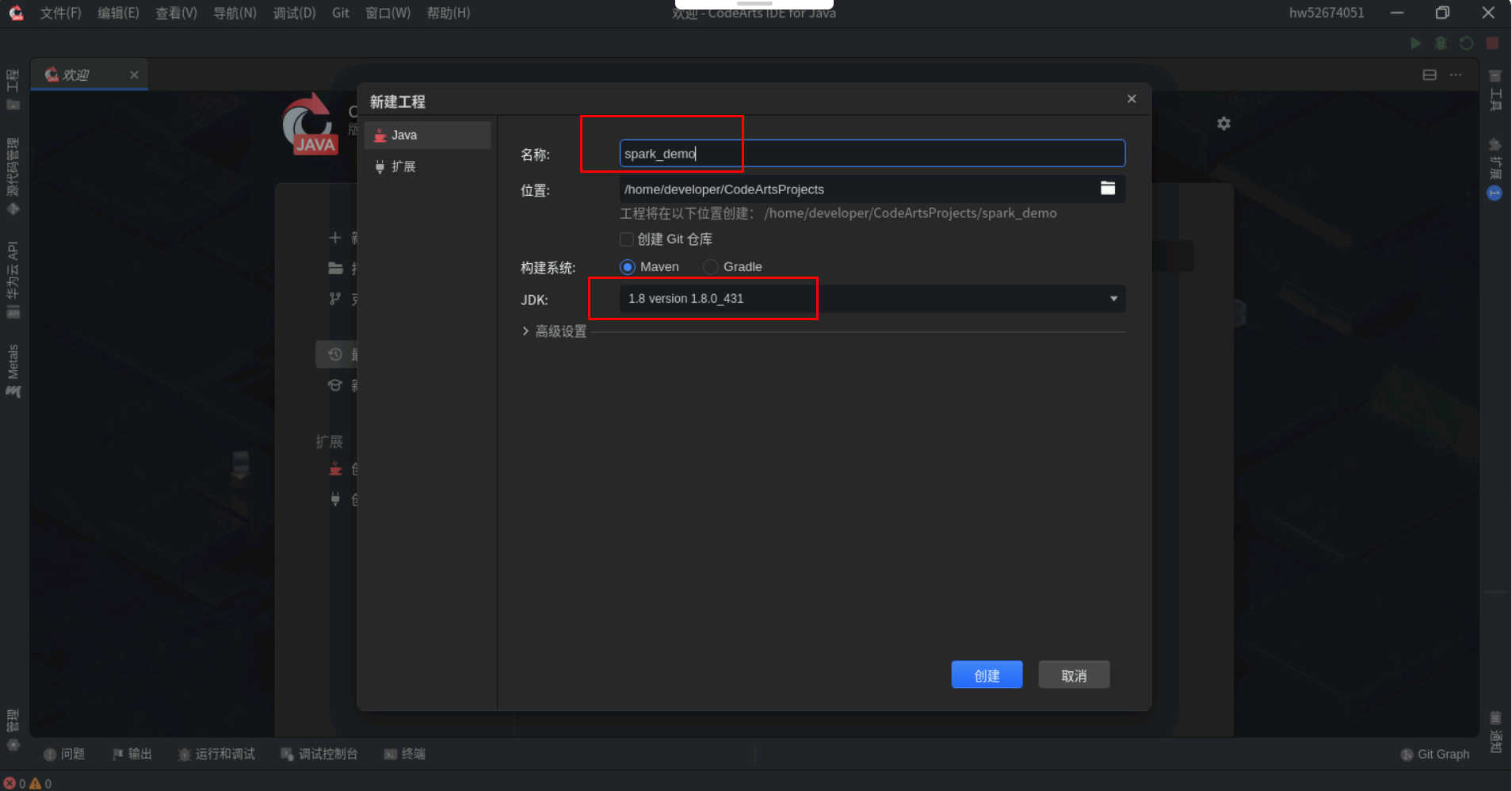
工程创建好之后打开pom文件配置pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<name>demo</name>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>1.0-SNAPSHOT</version>
<description></description>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.17</scala.version>
<spark.version>3.4.0</spark.version>
<hadoop.version>3.3.5</hadoop.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<!-- scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- hivecontext-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- hadoop-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<!-- scala-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<!-- java -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
配置settings.xml文件
在命令行执行
vim /home/developer/.m2/settings.xml
将内容替换如下
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<!-- 默认的值是${user.home}/.m2/repository -->
<!--<localRepository></localRepository>-->
<!-- 如果Maven要试图与用户交互来得到输入就设置为true,否则就设置为false,默认为true。 -->
<!--
<interactiveMode>true</interactiveMode>
-->
<!-- 如果Maven使用${user.home}/.m2/plugin-registry.xml来管理plugin的版本,就设置为true,默认为false。 -->
<!--
<usePluginRegistry>false</usePluginRegistry>
-->
<!-- 如果构建系统要在离线模式下工作,设置为true,默认为false。 如果构建服务器因为网络故障或者安全问题不能与远程仓库相连,那么这个设置是非常有用的。 -->
<!--
<offline>false</offline>
-->
<servers>
<!-- server
| Specifies the authentication information to use when connecting to a particular server,
identified by
| a unique name within the system (referred to by the 'id' attribute below).
|
| NOTE: You should either specify username/password OR privateKey/passphrase, since these pairings
are
| used together.
|
-->
<!-- server标签的作用 ,如下 -->
<!-- 使用mvn install时,会把项目打的包安装到本地maven仓库 -->
<!-- 使用mvn deploye时,会把项目打的包部署到远程maven仓库,这样有权限访问远程仓库的人都可以访问你的jar包 -->
<!-- 通过在pom.xml中使用 distributionManagement 标签,来告知maven 部署的远程仓库地址,-->
</servers>
<mirrors>
<mirror>
<id>huaweiyun</id>
<mirrorOf>*</mirrorOf><!--*代表所有的jar包都到华为云下载-->
<!--<mirrorOf>central</mirrorOf>--><!--central代表只有中央仓库的jar包才到华为云下载-->
<!-- maven 会有默认的id为 “central” 的中央仓库-->
<name>huaweiyun-maven</name>
<url>https://mirrors.huaweicloud.com/repository/maven/</url>
</mirror>
</mirrors>
<!-- settings.xml中的profile是pom.xml中的profile的简洁形式。
它包含了激活(activation),仓库(repositories),插件仓库(pluginRepositories)和属性(properties)元素。
profile元素仅包含这四个元素是因为他们涉及到整个的构建系统,而不是个别的POM配置。
如果settings中的profile被激活,那么它的值将重载POM或者profiles.xml中的任何相等ID的profiles。 -->
<!-- 如果setting中配置了 repository,则等于项目的pom中配置了 -->
<profiles>
<profile>
<!-- 指定该 profile的id -->
<id>dev</id>
<!-- 远程仓库-->
<repositories>
<!-- 华为云远程仓库-->
<repository>
<id>huaweicloud</id>
<name>huaweicloud maven Repository</name>
<url>https://mirrors.huaweicloud.com/repository/maven/</url>
<!-- 只从该仓库下载 release版本 -->
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestone</id>
<name>Spring Milestone Repository</name>
<url>https://repo.spring.io/milestone</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
<layout>default</layout>
</repository>
<repository>
<id>spring-snapshot</id>
<name>Spring Snapshot Repository</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
<layout>default</layout>
</repository>
</repositories>
<pluginRepositories>
<!-- 插件仓库。插件从这些仓库下载 -->
<pluginRepository>
<id>huaweicloud</id>
<url>https://mirrors.huaweicloud.com/repository/maven/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</profile>
</profiles>
<!-- activations是profile的关键,就像POM中的profiles,profile的能力在于它在特定情况下可以修改一些值。
而这些情况是通过activation来指定的。 -->
<!-- <activeProfiles/> -->
<activeProfiles>
<activeProfile>dev</activeProfile>
</activeProfiles>
</settings>
重新下载依赖,点击右边maven会出现一个刷新按钮,点击按钮,下载依赖。
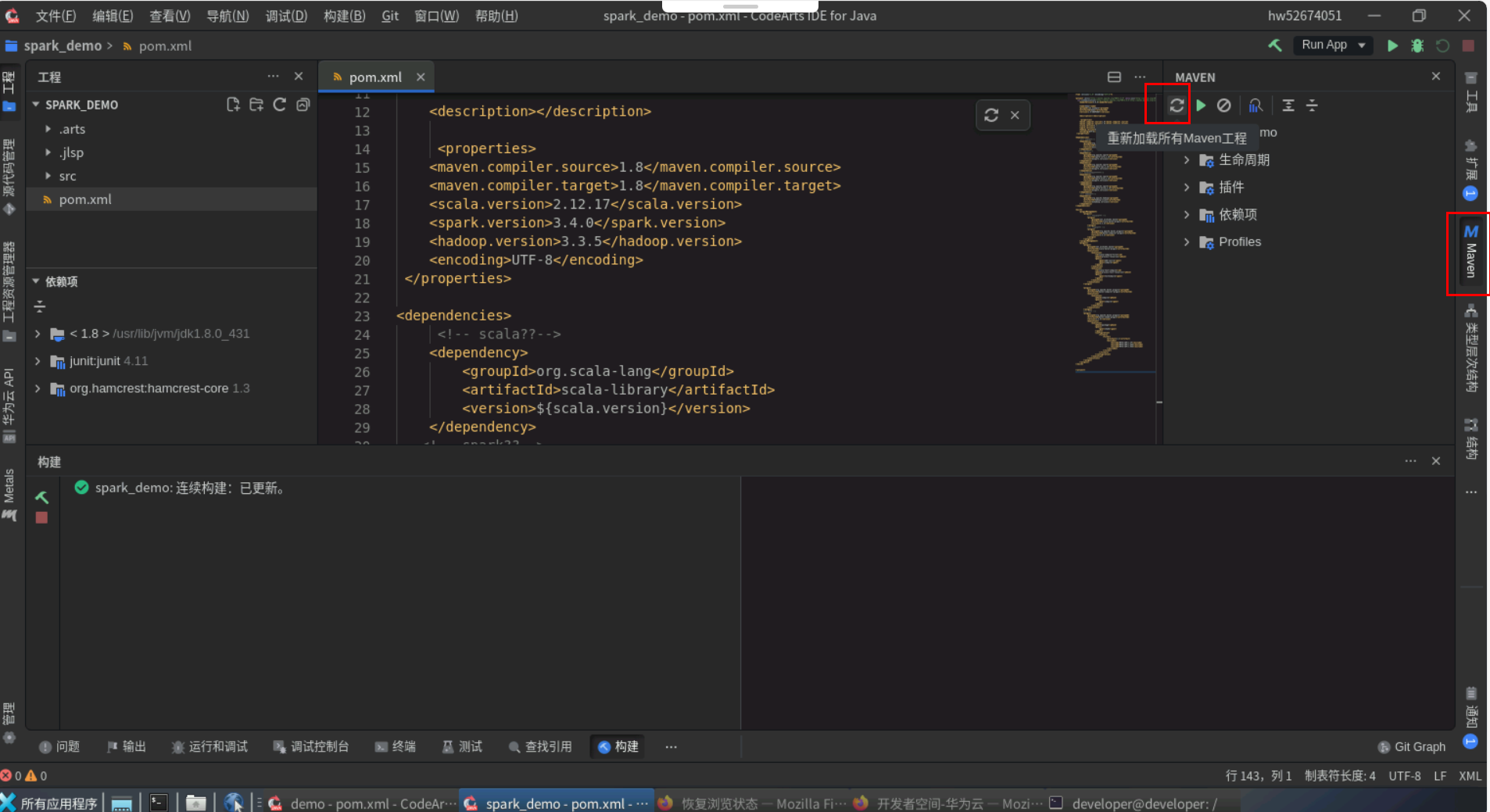
依赖下载完之后,分析基础数据准备
在工程src下新建resource文件夹
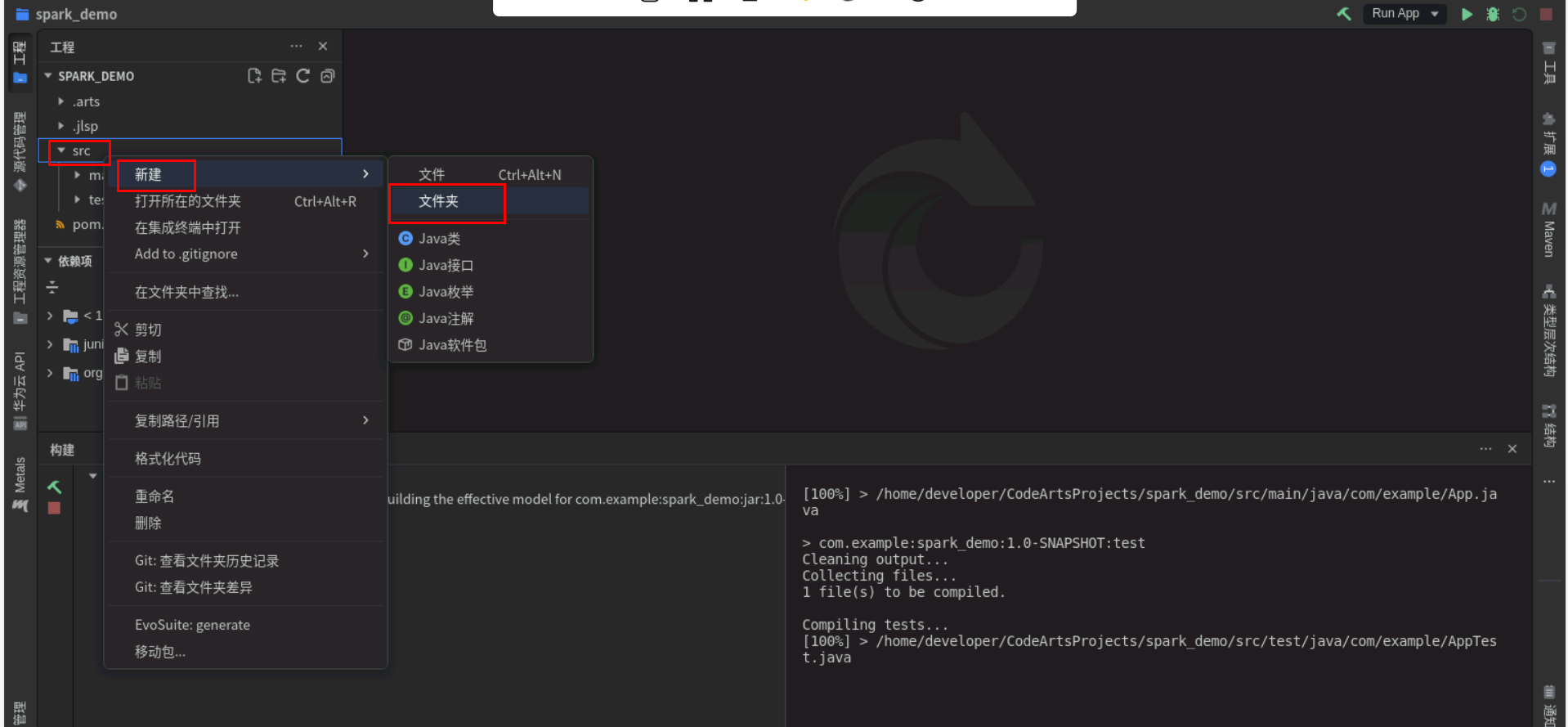

从https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0047/test.csv下载test.csv,并放到resource目录下。
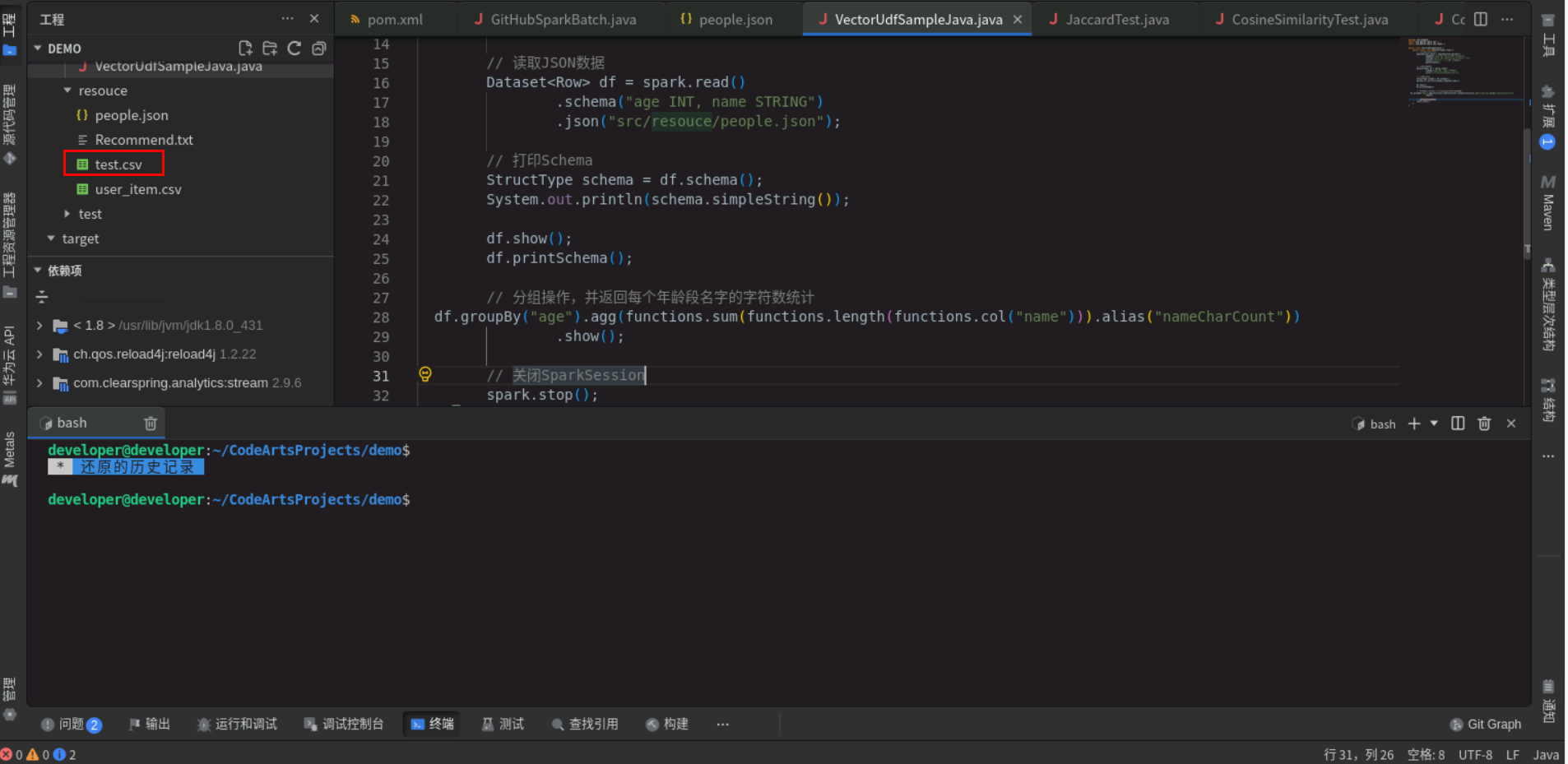
然后点击右上角src,在main/java/com/example下创建java类
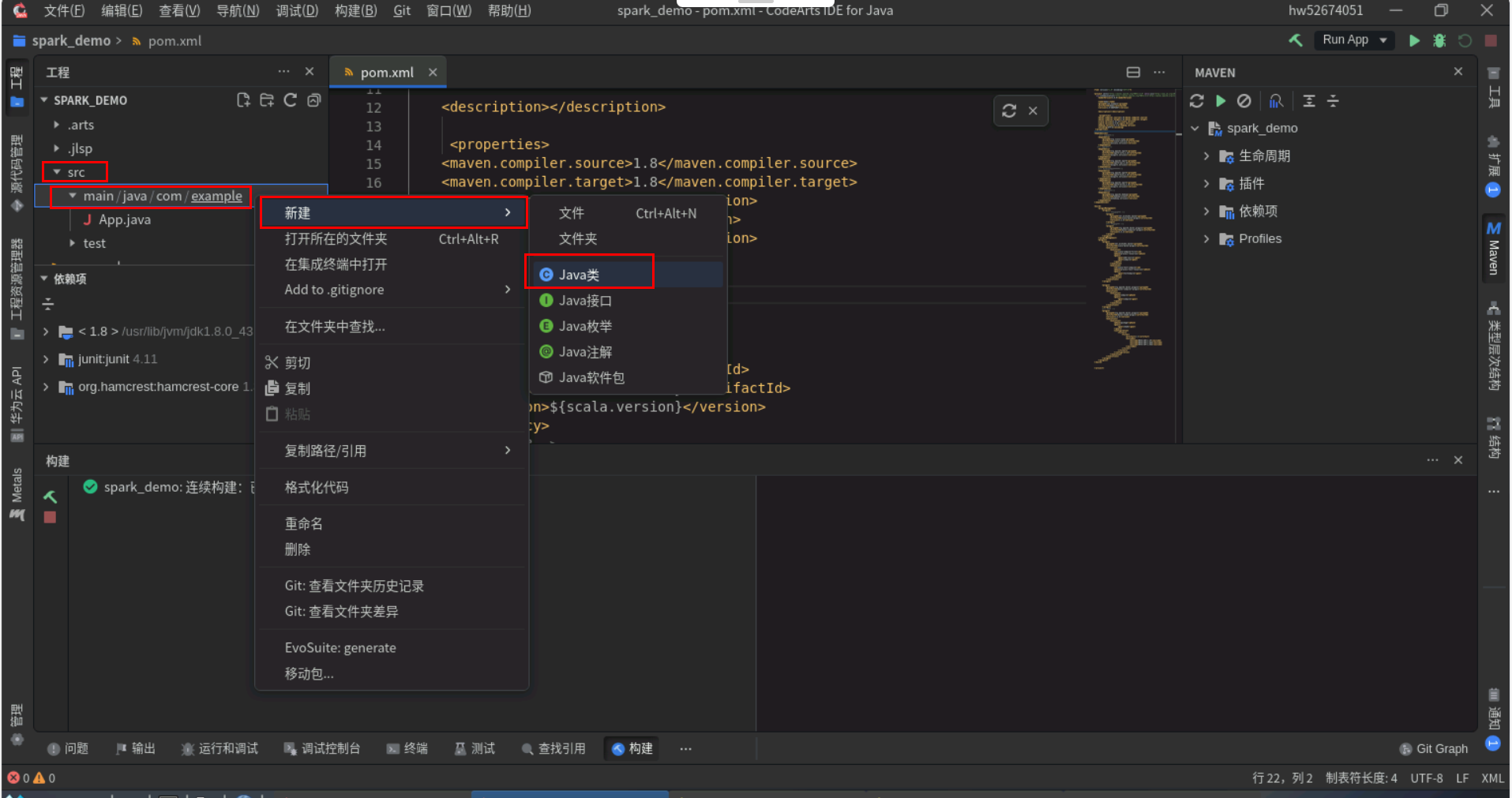
处理并分析数据,创建GitHubSparkBatch类将下面代码复制进去
package com.example;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.functions;
import org.apache.spark.sql.types.DataTypes;
public class GitHubSparkBatch {
public static void main(String[] args) {
// 创建SparkSession
SparkSession spark = SparkSession.builder()
.appName("GitHub and Spark Batch")
.master("local")
.getOrCreate();
// 读取CSV文件并指定模式,这里使用了自定义的模式字符串
Dataset<Row> projectsDf = spark.read()
.schema("id INT, url STRING, owner_id INT, " +
"name STRING, descriptor STRING, language STRING, " +
"created_at STRING, forked_from INT, deleted STRING," +
"updated_at STRING")
.csv("/user/hadoop/input/test.csv");
projectsDf.show();
// 处理包含空值(NA)的行
Dataset<Row> cleanedProjects = projectsDf.na().drop("any");
// 删除不必要的列
cleanedProjects = cleanedProjects.drop("id", "url", "owner_id");
cleanedProjects.show();
//spark.stop();
// 按照language分组并计算forked_from的平均值
Dataset<Row> groupedDF = cleanedProjects.groupBy("language")
.agg(functions.avg(cleanedProjects.col("forked_from")).alias("avg_forked_from"));
// 按照平均forked数量降序排序并显示
groupedDF.orderBy(functions.desc("avg_forked_from")).show();
// 注册udfUDF
spark.udf().register("MyUDF", (String date) -> {
if (date == null) {
return false;
}
try {
java.time.LocalDateTime localDateTime = java.time.LocalDateTime.parse(date, java.time.format.DateTimeFormatter.ofPattern("M/d/yyyy H:mm"));
return localDateTime.isAfter(java.time.LocalDateTime.now());
} catch (java.time.format.DateTimeParseException e) {
return false;
}
}, DataTypes.BooleanType);
// 创建临时视图
cleanedProjects.createOrReplaceTempView("dateView");
// 使用SQL查询并显示结果
Dataset<Row> dateDf = spark.sql("SELECT *, MyUDF(dateView.updated_at) AS datebefore FROM dateView");
dateDf.show();
spark.stop();
}
}
向量分析
数据准备,项目工程的resource下创建people.json文件并将下面数据复制进去
{"name":"Michael", "age":43}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
创建VectorUdfSampleJava类将下面代码复制进去
package com.example;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.*;
public class VectorUdfSampleJava {
public static void main(String[] args) {
// ??SparkSession
SparkSession spark = SparkSession.builder()
.appName("Java SQL VectorUdfs Example")
.config("spark.sql.shuffle.partitions", "3")
.master("local") // 设置为本地模式
.getOrCreate();
// 读取JSON数据
Dataset<Row> df = spark.read()
.schema("age INT, name STRING")
.json("/user/hadoop/input/people.json");
// 打印Schema
StructType schema = df.schema();
System.out.println(schema.simpleString());
df.show();
df.printSchema();
// 分组操作,并返回每个年龄段名字的字符数统计
df.groupBy("age").agg(functions.sum(functions.length(functions.col("name"))).alias("nameCharCount"))
.show();
// 停止SparkSession
spark.stop();
}
}
相似度计算方式
数据准备
"1","1","1"
"2","1","2"
"3","1","4"
"4","2","2"
"5","2","4"
"6","3","3"
"7","3","1"
"8","3","4"
"9","4","1"
把上面数据放到项目工程的resource下创建user_item.csv文件中,进行项目的分析计算
创建JaccardTest类将下面代码复制进去
package com.example;
import org.apache.spark.sql.*;
import static org.apache.spark.sql.functions.*;
public class JaccardTest {
public static void main(String[] args) {
// 创建 SparkSession
SparkSession session = SparkSession.builder()
.appName("ItemCFApp")
.master("local[*]")
.getOrCreate();
// 从CSV文件读取数据
DataFrameReader reader = session.read();
Dataset<Row> projectsDf = reader
.schema("id INT, user_id INT, item_id INT")
.csv("/user/hadoop/input/user_item.csv");
projectsDf.show();
// 统计每种商品的数量
Dataset<Row> itemCount = projectsDf.groupBy("item_id").count();
// 获取与商品的向量矩阵
Dataset<Row> item2ItemCount = projectsDf.as("a")
.join(projectsDf.as("b"), col("a.user_id").equalTo(col("b.user_id")))
.where(col("a.item_id").notEqual(col("b.item_id")))
.select(col("a.item_id").alias("a_item_id"), col("b.item_id").alias("b_item_id"))
.groupBy("a_item_id", "b_item_id")
.count();
item2ItemCount.show();
// 计算商品与商品的相似度
Dataset<Row> result = item2ItemCount.as("i2i")
.join(itemCount.as("ic1"), col("i2i.a_item_id").equalTo(col("ic1.item_id")))
.join(itemCount.as("ic2"), col("i2i.b_item_id").equalTo(col("ic2.item_id")))
.selectExpr("i2i.a_item_id", "i2i.b_item_id",
"i2i.count / (ic1.count + ic2.count - i2i.count) as similarity");
result.show();
// 停止SparkSession
session.stop();
}
}
基于物品的余弦相似度
创建CosinTest类将下面代码复制进去
package com.example;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;
public class CosinTest {
public static void main(String[] args) {
// 创建SparkSession
SparkSession session = SparkSession.builder()
.appName("ItemCFApp")
.master("local[*]")
.getOrCreate();
// 从csv文件中读取数据
Dataset<Row> projectsDf = session.read()
.schema("id INT, user_id INT, item_id INT")
.csv("/user/hadoop/input/user_item.csv");
projectsDf.show();
// 统计每种商品数量
Dataset<Row> itemCount = projectsDf.groupBy("item_id").count();
itemCount.show();
// 获取商品与商品的向量矩阵
Dataset<Row> item2ItemCount = projectsDf.as("a")
.join(projectsDf.as("b"), col("a.user_id").equalTo(col("b.user_id")))
.filter(col("a.item_id").notEqual(col("b.item_id")))
.select(col("a.item_id").as("a_item_id"), col("b.item_id").as("b_item_id"))
.groupBy("a_item_id", "b_item_id").count();
item2ItemCount.show();
// 计算商品与商品的相似度
Dataset<Row> result = item2ItemCount.as("i2i")
.join(itemCount.as("ic1"), col("i2i.a_item_id").equalTo(col("ic1.item_id")))
.join(itemCount.as("ic2"), col("i2i.b_item_id").equalTo(col("ic2.item_id")))
.selectExpr("i2i.a_item_id", "i2i.b_item_id", "i2i.count / pow(ic1.count * ic2.count, 0.5) as count");
result.show();
// 停止SparkSession
session.stop();
}
}
基于Cosine Similarity算法
创建CosinUserTest类将下面代码复制进去
package com.example;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;
public class CosinUserTest {
public static void main(String[] args) {
// 创建SparkSession
SparkSession session = SparkSession.builder()
.appName("ItemCFApp")
.master("local[*]")
.getOrCreate();
// 读取CSV文件到DataFrame
Dataset<Row> projectsDf = session.read()
.schema("id INT, user_id INT, item_id INT")
.csv("/user/hadoop/input/user_item.csv");
projectsDf.show();
// 计算每个用户的项目数
Dataset<Row> userCount = projectsDf.groupBy("user_id").count();
userCount.show();
// 计算用户-用户共同项目数
Dataset<Row> user2userCount = projectsDf.as("a")
.join(projectsDf.as("b"), col("a.item_id").equalTo(col("b.item_id")))
.filter(col("a.user_id").notEqual(col("b.user_id")))
.select(col("a.user_id").as("a_user_id"), col("b.user_id").as("b_user_id"))
.groupBy("a_user_id", "b_user_id").count();
user2userCount.show();
// 计算用户-用户相似度
Dataset<Row> result = user2userCount.as("u2u")
.join(userCount.as("uc1"), col("u2u.a_user_id").equalTo(col("uc1.user_id")))
.join(userCount.as("uc2"), col("u2u.b_user_id").equalTo(col("uc2.user_id")))
.selectExpr("u2u.a_user_id", "u2u.b_user_id", "u2u.count / pow(uc1.count * uc2.count, 0.5) as similarity");
result.show();
// 停止SparkSession
session.stop();
}
}
删除工程test下自带的代码
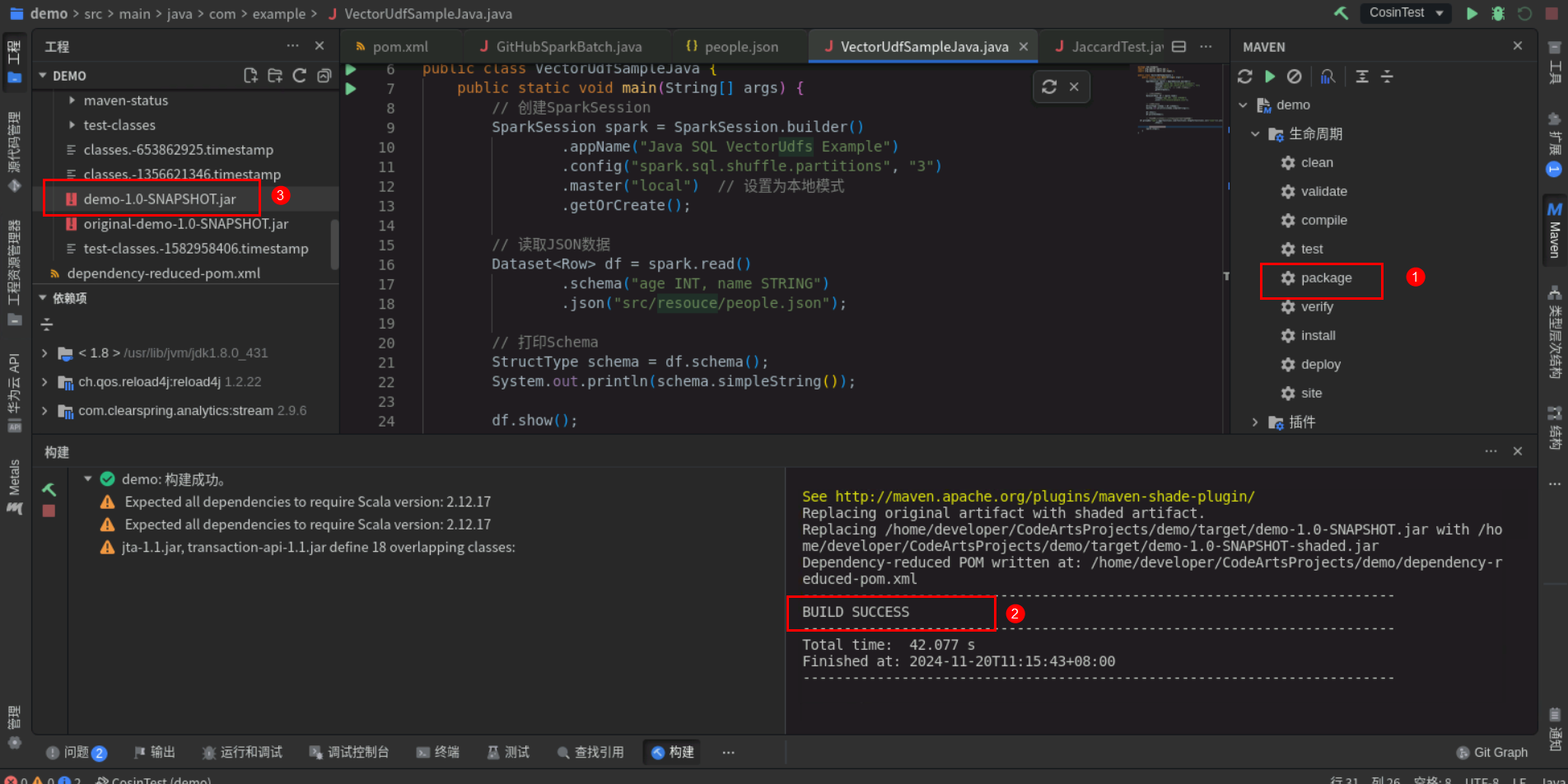
3.2 打包代码
点击右边maven->生命周期->双击package,进行代码打包,打包成功后控制台会出现BUILD SUCCESS,左边工程下面target下会有打好的jar包
3.3 运行代码
打开终端,执行命令启动hadoop。
/usr/local/hadoop/sbin/start-dfs.sh

创建hdfs文件夹
/usr/local/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/input
上传之前代码找那个需要的数据文件到hdfs,注意修改/home/developer/CodeArtsProjects/demo部分为项目实际路径。
/usr/local/hadoop/bin/hdfs dfs -put /home/developer/CodeArtsProjects/demo/src/resource/* /user/hadoop/input
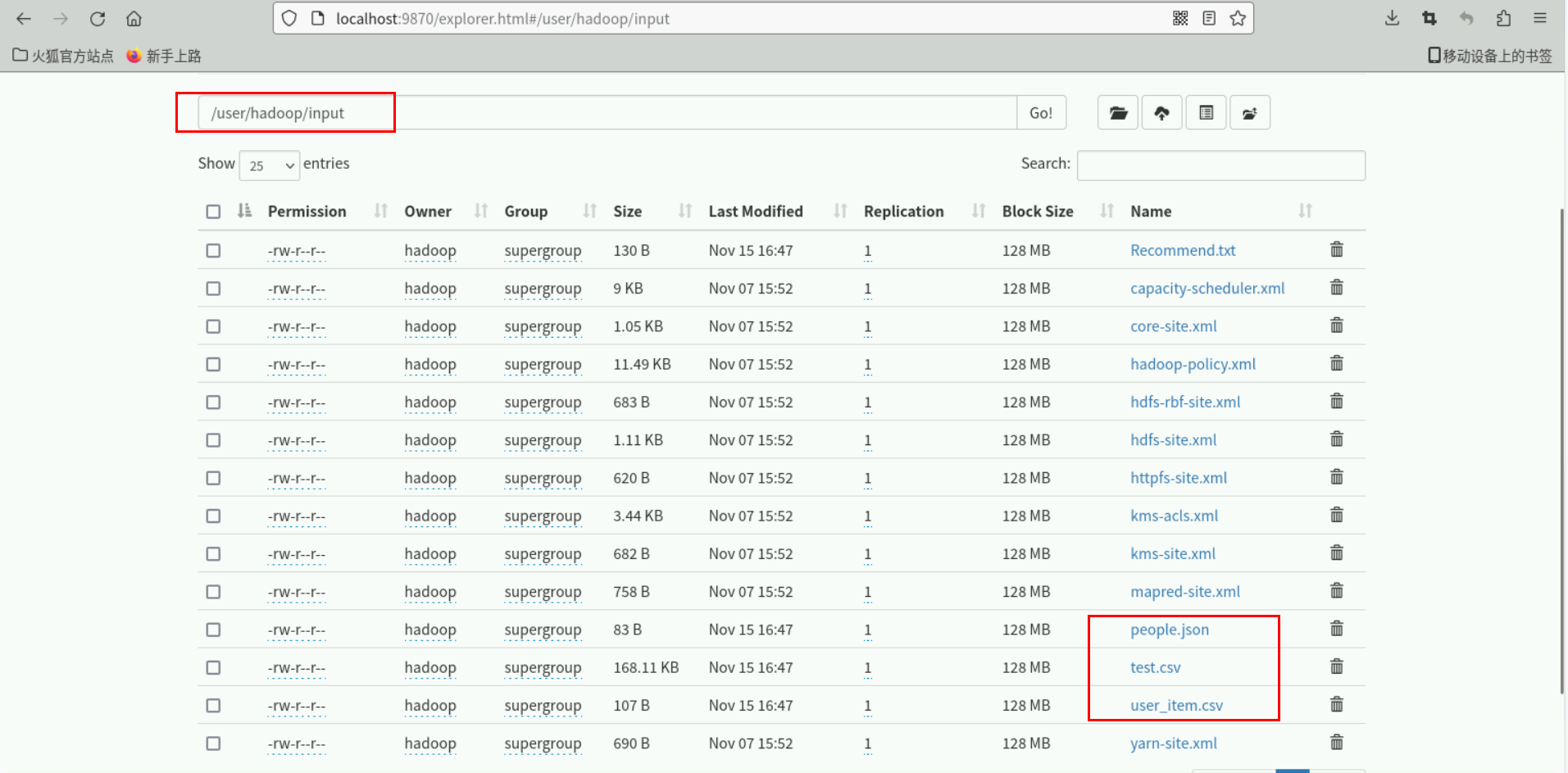
可以访问 Web 界面 http://localhost:9870,查看文件上传是否成功
终端运行GitHubSparkBatch代码,注意修改/home/developer/CodeArtsProjects/demo部分为项目实际路径。
sudo /usr/local/spark/bin/spark-submit --class com.example.GitHubSparkBatch /home/developer/CodeArtsProjects/demo/target/demo-1.0-SNAPSHOT.jar
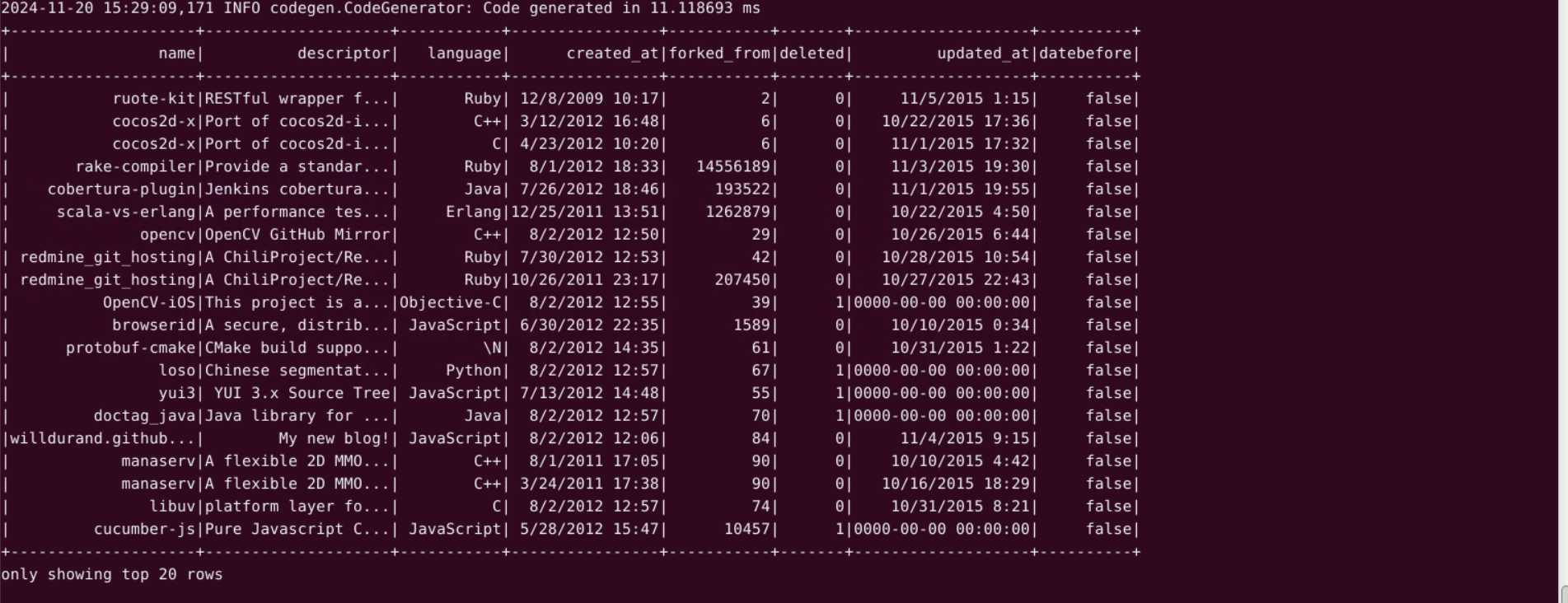
结果如下:
name的值是项目的名称
descriptor是描述信息
Language 使用的语言
created_at创建时间
forked_from每种语言在项目中的占比
updated_at更新时间
datebefore创建时间是否是在当前时间之前
根据计算结果可了解不同编程语言项目的平均 forked_from 情况,若某语言分组平均 forked_from 值高,暗示该语言项目在派生关系上更活跃或受关注,对项目关联和发展趋势研究有参考意义,助力资源分配与决策
运行向量分析代码VectorUdfSampleJava,注意修改/home/developer/CodeArtsProjects/demo部分为项目实际路径。
sudo /usr/local/spark/bin/spark-submit --class com.example.VectorUdfSampleJava /home/developer/CodeArtsProjects/demo/target/demo-1.0-SNAPSHOT.jar
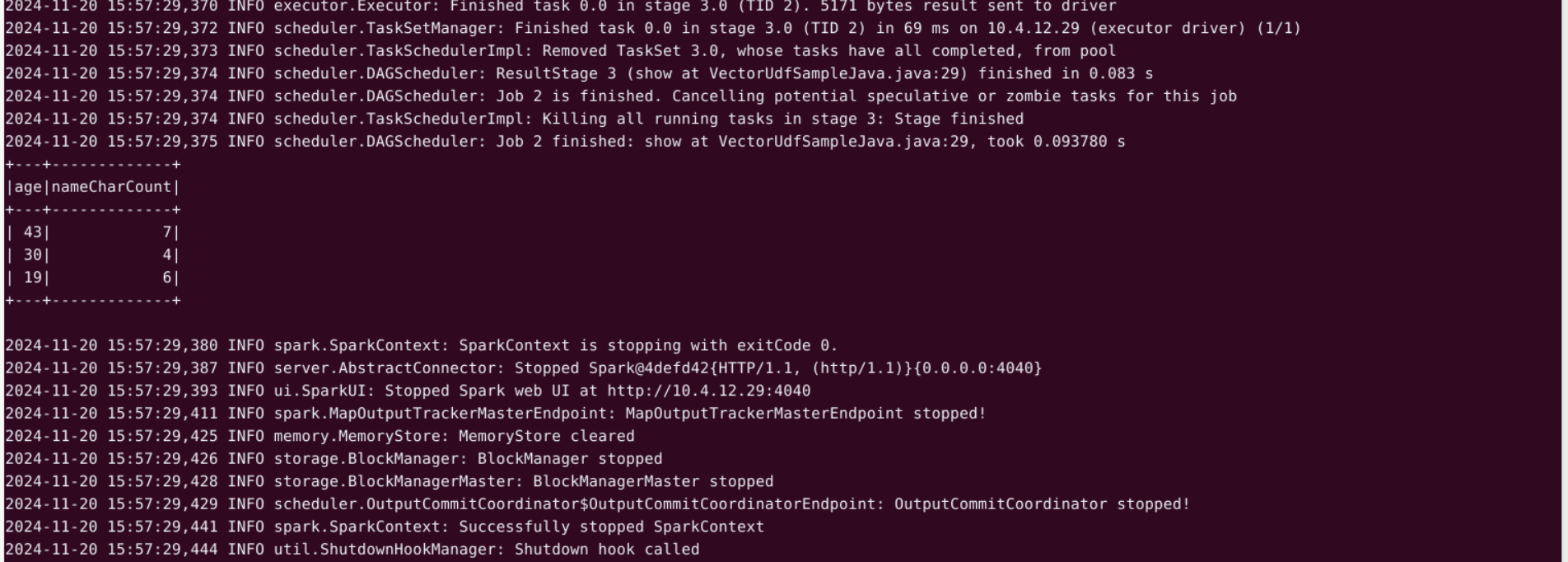
结果如下:
age年龄
nameCharCount 名字字符数,每个年龄组内所有人名字字符串的字符数总和
结果可以看出不同年龄组与其对应的名字字符数总和之间的关系
运行基于物品的Jaccard相似度代码JaccardTest,注意修改/home/developer/CodeArtsProjects/demo部分为项目实际路径。
sudo /usr/local/spark/bin/spark-submit --class com.example.JaccardTest /home/developer/CodeArtsProjects/demo/target/demo-1.0-SNAPSHOT.jar
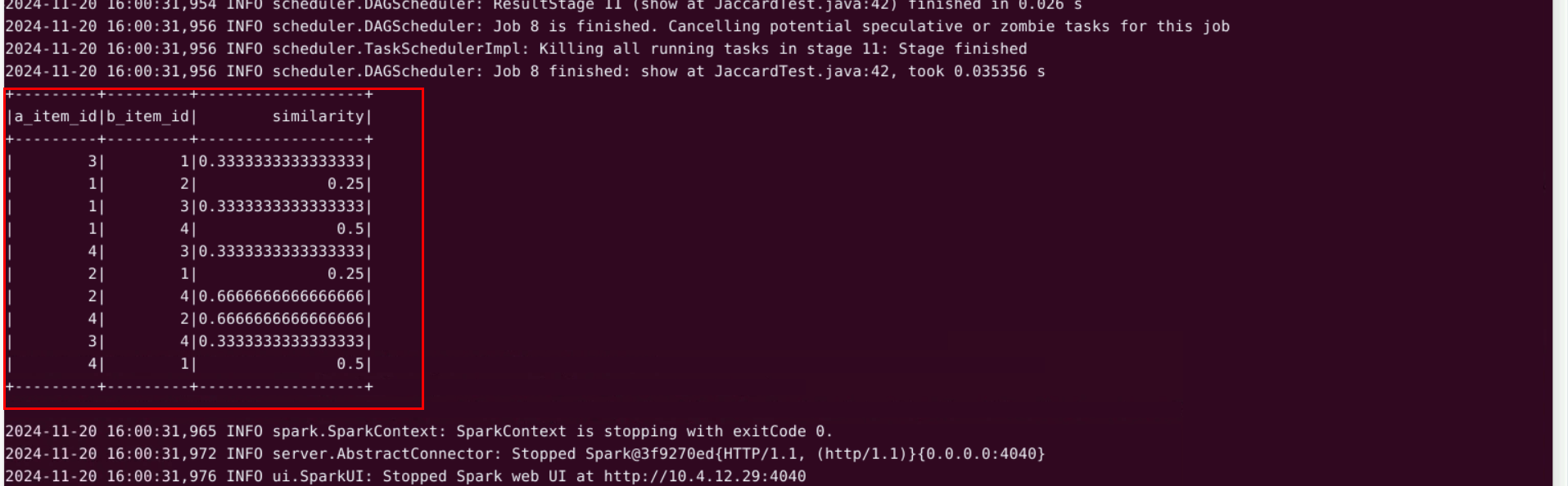
Jaccard 相似度主要用于衡量两个集合的相似程度
运行结果如下
a_item_id a商品列
b_item_id b商品列
similarity 根据Jaccard算法计算出的两个商品之间的相似度
根据计算出的相似度,用户购买或浏览商品可以推荐相似度较高的商品
运行基于物品的余弦相似度代码CosinTest,注意修改/home/developer/CodeArtsProjects/demo部分为项目实际路径。
sudo /usr/local/spark/bin/spark-submit --class com.example.CosinTest /home/developer/CodeArtsProjects/demo/target/demo-1.0-SNAPSHOT.jar
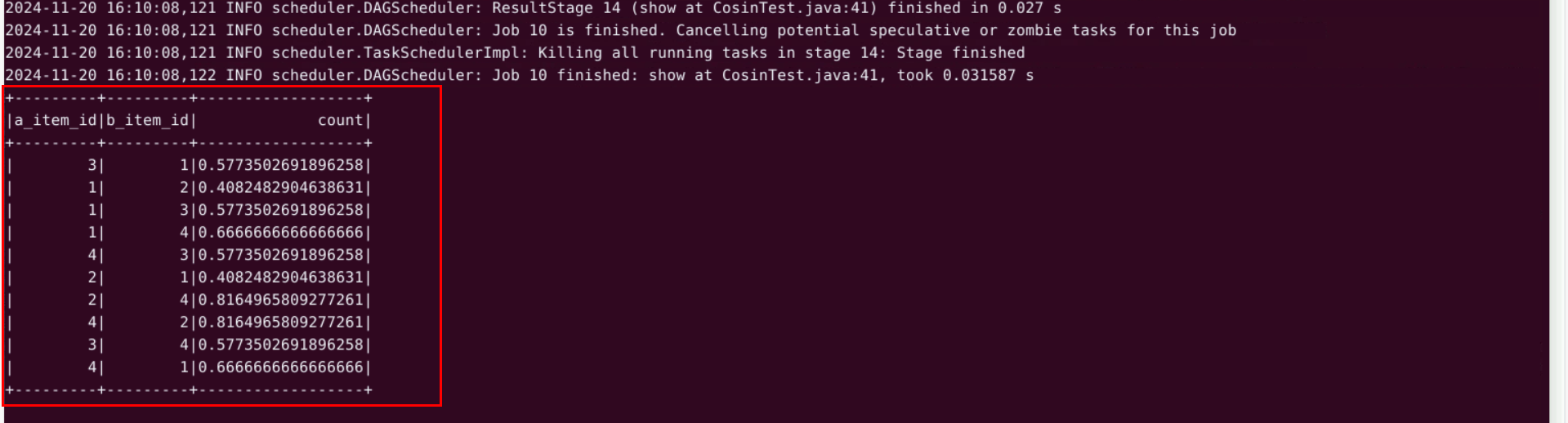
余弦相似度是通过计算两个向量之间的夹角余弦值来衡量它们的相似程度
运行结果如下:
a_item_id a商品列
b_item_id b商品列
similarity 根据余弦相似度算法计算出的两个商品之间的相似度
根据计算出的相似度,用户购买或浏览商品可以推荐相似度较高的商品
基于Cosine Similarity计算用户与用户相似度代码CosinUserTest,注意修改/home/developer/CodeArtsProjects/demo部分为项目实际路径。
sudo /usr/local/spark/bin/spark-submit --class com.example.CosinUserTest /home/developer/CodeArtsProjects/demo/target/demo-1.0-SNAPSHOT.jar
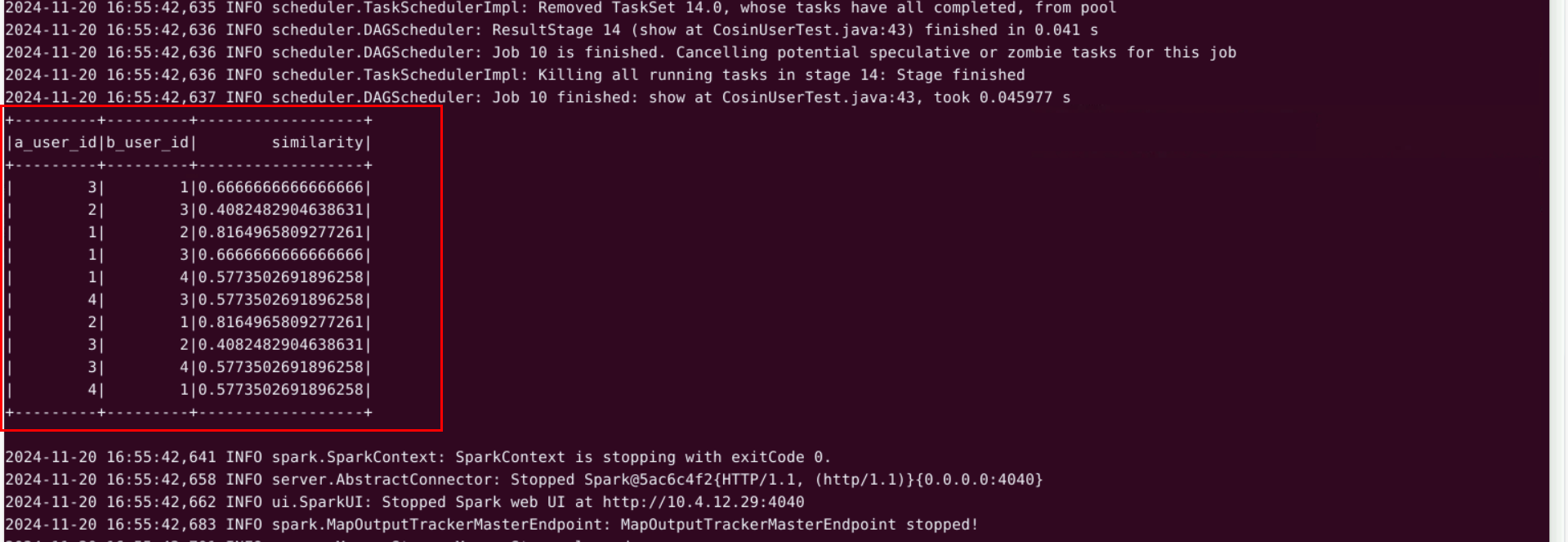
运行结果如下
a_user_id a用户列
b_user_id b用户列
similarity 根据余弦相似度算法计算出的两个用户之间的相似度
根据计算出的相似度,用户购买或浏览商品可以推荐相似度较高的用户之前购买的商品,以增加销量
到此本次实验结束。
3.4 反馈改进建议
如您在案例实操过程中遇到问题或有改进建议,可以到论坛帖评论区反馈即可,我们会及时响应处理,谢谢!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 19
19 0
0- 0



 已为社区贡献6177条内容
已为社区贡献6177条内容

所有评论(0)