Kafka和RabbitMQ可靠性比较(终极版)
Kafka和RabbitMQ对比
Kafka和RabbitMQ是最常用的两个消息中间件,很多场合两种都能使用,关于他们的选型,基本都会从吞吐量和可靠性两方面进行比较。吞吐量的比较一般认为Kafka优,这方便从架构和性能测试能明确回答,本文不再赘述,本文从两者的架构原理讨论两者的可靠性优劣。
大多数网上文章简单的认为,RabbitMQ有消息确认机制,所以认为RabbitMQ更为可靠,但实际情况并非如此!
先说结论:
- 正确使用的情况下,两者的可靠性其实是相当的;
- 粗犷的使用情况下,由于Kafka默认做了持久化,Kafka要比RabbitMQ可靠。
何为可靠,就是不管是生产者出现宕机,还是消费者出现宕机,还是消息中间件宕机(RabbitMQ/Kafka),已经成功投递的消息,都应该正确投递(不丢失也不重复)。
先来分析Kafka的可靠性情况
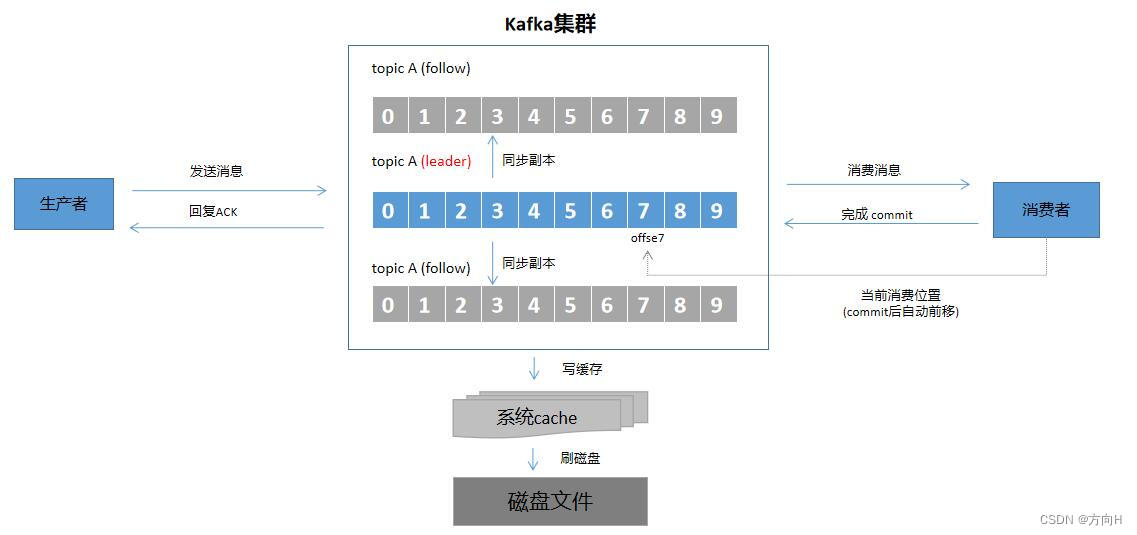
1、消息发送环节分析
生产者通过查询具体对应topic分区的leader,发消息发送过去,leader再把数据同步到follow(副本)。Kafka可以配置leader同步数据到follow前ACK,也可以配置为同步数据到follow后ACK(会损失性能)。
问题来了,如果生产者无视ACK,那么自然会导致消息丢失,无可靠性可言。如果配置leader同步数据到follow前ACK,那么如果在此刻leader宕机了,消息也会丢失。
2、持久化环节分析
假设经过上面消息发送环节,消息正确的同步到了所有的follow,此刻leader宕机了,只有有一个follow存活,数据也是稳固无疑的。当如果出现更糟糕的情况,整个Kafka集群宕掉了呢。嗯,如果磁盘上已经持久化了数据,数据也是稳固的。但但但。。。凡事不能说的太死,其实数据刷到磁盘,会经过一个cache,然后才会落到磁盘,虽然时间很短,仍然存在机器掉电而数据未落盘的情况。并且这个不由Kafka本身控制,是操作系统自身行为。
3、消费环节分析
在消费者环节,Kafka会未每个消费者组维护一个offset(未指定消费者组的消费者会分配一个随机的消费者组)。消费者完成消费并commit后,offset会自动前移。
假设一个经验缺乏的程序员,他的代码是取得消息还没有执行业务处理就commit,如果此刻消费者宕机了,但offset已自动前移,那么也可以认为消息丢失。
再来分析RabbitMQ的可靠性情况

1、消息发送环节分析
生产者将消息发送到其中的Exchange上,为了保证可靠性,RabbitMQ在消息方式环节建立了两种机制:事务机制和确认机制。但事务机制性能极差基本不会使用,这里讨论确认机制。
RabbitMQ会根据消息成功与否,返回ack或者nack,生产者需要在ack或者nack的回调函数进行处理。但如果生产者无视,也就一样无可靠性可言。
2、消息分配环节分析
已经发送到Exchange的消息,会根据设定的规则分配到具体的Queue上,但如果没有任何规则适用的话,消息就会无法匹配任何的Queue。此情况消息会丢弃,但生产者也可以通过监听ReturnListener监听器来获取无法匹配的消息,进一步处理,如果这里无视的话,也可以任务损失可靠性。
有无可能出现消息已经发送到了Exchange,但在投递到Queue时,发生消息丢失呢?有的!所以RabbitMQ提出了备份交换器方案,但估计很多人没有,这里有损失了可靠性。
3、持久化环节分析
为了提高可靠性,RabbitMQ也有持久化消息队列的方案,但同上面的Kafka一样,数据也是先进cache,然后才会落盘,存在一个断的时间差。如果服务器掉电,同样会发生消息丢失。
4、消费环节分析
在消费环节,有一个消息确认机制,也就是大多数网上文章简单的认为保证了RabbitMQ可靠性的机制。消费者可以指定autoAck参数,当autoAck为false时,需要显式地回复确认信号后才从内存(或者磁盘)中移去消息,当autoAck为true时,RabbitMQ就不会管你是不是处理完了消息,都会删除消息。
那么问题来了,如果一个没有经验的程序员,autoAck设为true,后面的处理程序又写得一团糟,那么这个消息确认机制反而是导致不可靠的大冤种!因为不管你后面的程序是不是报错了没有正确处理,消息都删掉了。
咦,RabbitMQ怎么没有类似Kafka那一套副本机制?其实也是有的,叫镜像队列,镜像队列同样存在选取等机制,和Kafka类似。
以上就是Kafka和RabbitMQ可靠性分析。
总结:使用者如果缺乏对系统的理解,而泛泛的使用的话,任何系统都是无法获得可靠性保障的。系统的可靠性需要建立在正确的使用方法之上。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)