容器技术—docker swarm(一)
我们的应用随着业务的扩展,从开始的单体架构,到分布式架构,再到微服务架构,其中的核心理念就是用资源换取性能。单台服务器的性能是由瓶颈的,随着业务的扩展、访问量的增大、计算量的增大,IO读写需求的增大,逐渐无法支撑,于是便通过集群技术将多台机器构成集群,调度集群内的多台服务器协同进行工作,以满足应用运行的需要,提升应用的性能。这是分布式架构的基本思想。这里的关键技术就是集群技术。集群是一组相互独立的
容器技术—docker swarm(一)
1. 集群的基本概念
我们的应用随着业务的扩展,从开始的单体架构,到分布式架构,再到微服务架构,其中的核心理念就是用资源换取性能。单台服务器的性能是由瓶颈的,随着业务的扩展、访问量的增大、计算量的增大,IO读写需求的增大,逐渐无法支撑,于是便通过集群技术将多台机器构成集群,调度集群内的多台服务器协同进行工作,以满足应用运行的需要,提升应用的性能。这是分布式架构的基本思想。
这里的关键技术就是集群技术。集群是一组相互独立的、通过高速网络互联的计算机构成了一个组,并以单一系统的模式加以管理。每个集群节点都是运行其自己进程的一个独立服务器,但是对于用户来讲,集群却像是一个独立的服务器、一个单一的系统,集群框架就像是多台电脑的操作系统,它将各个节点协同起来向用户提供系统资源,系统服务,通过网络连接形成一个个组合来共同完一个个任务。集群系统最核心的技术就是调度技术,就像一台电脑最核心的就是cpu的调度能力一样.
构建集群的目的:
- 1 提高性能
一些计算密集型应用,如:天气预报、核试验模拟等,需要计算机要有很强的运算处理能力,现有的技术,即使普通的大型机器计算也很难胜任。这时,一般都使用计算机集群技术,集中几十台甚至上百台计算机的运算能力来满足要求。提高处理性能一直是集群技术研究的一个重要目标之一。 - 2 降低成本
通常一套较好的集群配置,其软硬件开销要超过100000美元。但与价值上百万美元的专用超级计算机相比已属相当便宜。在达到同样性能的条件下,采用计算机集群比采用同等运算能力的大型计算机具有更高的性价比。 - 3 提高可扩展性
用户若想扩展系统能力,不得不购买更高性能的服务器,才能获得额外所需的CPU 和存储器。如果采用集群技术,则只需要将新的服务器加入集群中即可,对于客户来看,服务无论从连续性还是性能上都几乎没有变化,好像系统在不知不觉中完成了升级。 - 4 增强可靠性
集群技术使系统在故障发生时仍可以继续工作,将系统停运时间减到最小。集群系统在提高系统的可靠性的同时,也大大减小了故障损失。
集群根据应用场景和侧重点的不同有不同的分类,包括高性能计算集群(侧重并行计算)、负载均衡集群、高可用性集群。集群是通过集群框架组织起多台机器形成的,集群框架相当于集群的操作系统,除了组成集群的机器的性能影响外,影响集群能力就是集群框架的调度算法了。如我在平常工作中经常接触曙光超算就是高性能计算机集群(HPC)。
现如今,很多应用都支持集群化部署,如侧重数据存储的mysql集群、ElasticSearch集群等,侧重大数据处理的Hadoop集群、spark集群等,侧重任务调度的Jenkins集群、chronos集群等,集群化应用的调度算法注重应用自身的任务,根据应用不同有各自的侧重点。
而我们的应用在微服务架构下,随着业务的扩展,服务越来越多,总不能一直将所有服务及其依赖的容器全部部署在一台机器上,这样服务器撑不住,也失去了分布式架构的意义。要将docker容器部署到不同机器上,又要让它们协调工作,并且能够对这些容器对进行敏捷的生命周期的管理,就需要构建容器集群了。能实现docker容器集群构建和管理的工具也有多种,其中最基础的就是Docker Swarm。
2. Docker Swarm
Swarm 是 Docker 官方提供的一款集群管理工具,内置在docker之中,通过docker引擎的SwarmKit成为 Docker 的一个子命令,是原生的docker集群编排工具,是曾经的Docker三剑客项目之一。通过Swarm可以用几条简单的命令就将若干台 Docker 主机抽象为一个整体,快速的创建一个docker集群,并且通过一个入口统一管理集群各个机器上的各种 Docker 资源。
提起容器集群管理就绕不开k8s,现在主流的容器管理工具就是k8s,但是Swarm项目也是一个经典,和k8s对比,Swarm更轻量级,是了解容器集群技术的入门工具,对于一些小型的容器集群应用场景是很简单而有效的解决方案。
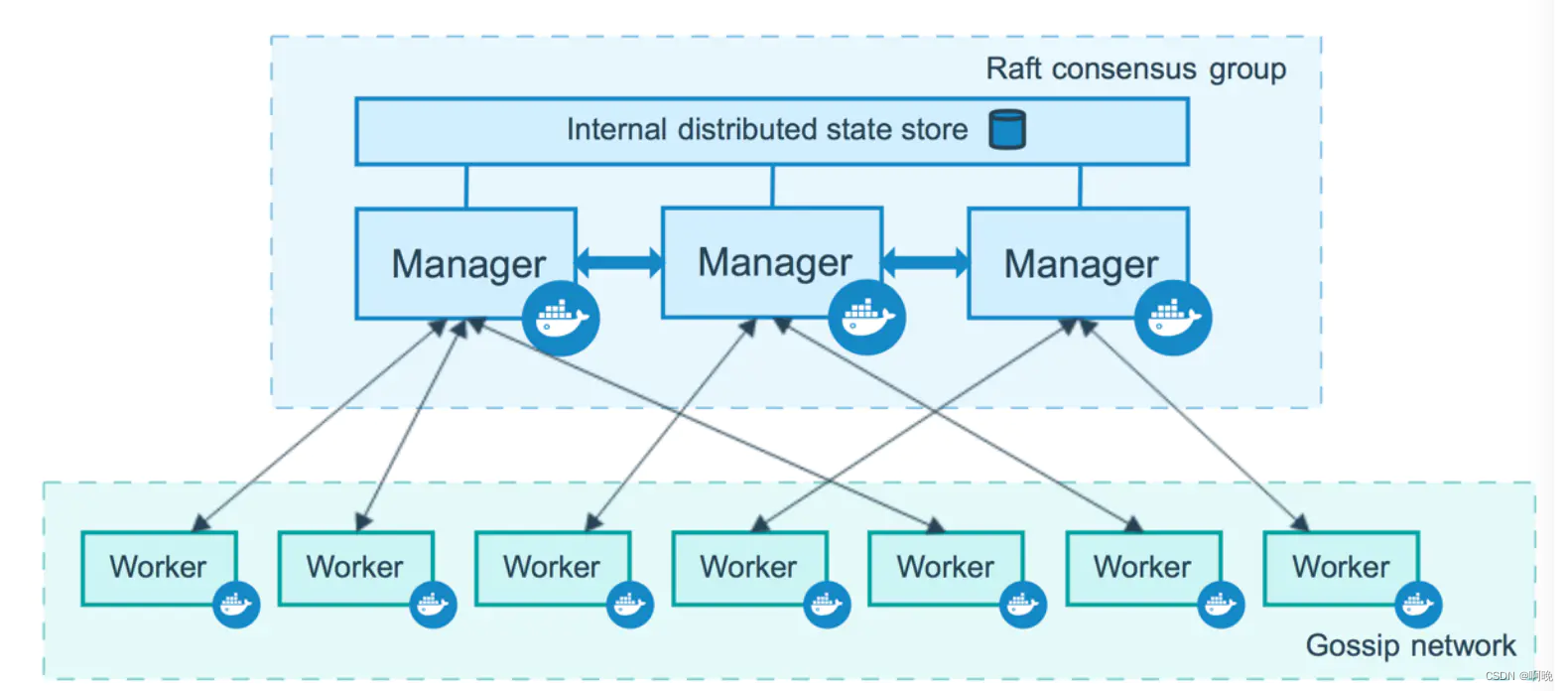
一个 Swarm 集群由一个或多个 Docker 节点组成,这些节点可以是物理服务器、虚拟机或云实例,唯一的前提就是所有节点通过可靠的网络相连。节点在加入集群的时候会被配置为管理节点(Manager)或工作节点(Worker),后续还能进行升级或降级。
管理节点负责执行容器的编排和集群的管理工作,集群编排管理指令在manger节点下达。由于Swarm实际上是通过agent调用了本地的Docker daemon来运行容器,当Swarm集群服务出现故障时,无法接受新的请求,但已经运行起来的容器将不会受到影响。在生产环境中,为避免单点故障,swarm可以部署多个manager节点,docker官方建议使用奇数个节点,最好是3到5个,不能大于7个,这些管理节点采用主从模式,分为leader和follower,follwer接收到命令时会转发给leader,它们会通过Raft协议进行状态同步,并在Leader节点发生故障时分布式选举出另一个Leader继续执行编排任务。
工作节点接收来自管理节点的任务并执行,并且默认manager node也是一个work node,不过可以将它设置为Drain模式,让它只负责编排和管理工作。
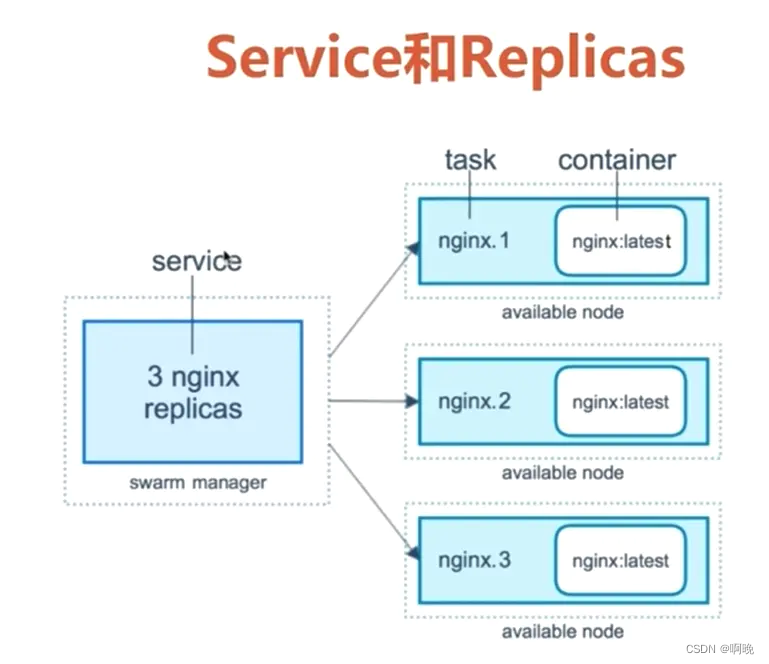
服务是要在集群节点上执行的任务的定义,它是swarm系统的中心结构,是用户与swarm交互的主要根源。创建服务时,指定在运行的容器中使用的容器映像和执行的命令,服务中还有诸如扩缩容、滚动升级以及简单回滚等特性。
服务分为两种类型:全局服务(global)和复制服务(replicated)。
复制服务:swarm manager会根据指令设置的规模在节点之间分配特定数量的副本任务。
全局服务:会在集群中的每个可用节点上为该服务运行一个任务。
任务包含一个Docker容器和容器运行的命令,它是swarm的最小调度单元,似于调度器放置容器的“槽”。管理器节点根据服务规模中设置的副本数将任务分配给工作节点,由工作节点去执行。任务一旦分配给节点,就不能移动到另一个节点。它只能在指定的节点上运行或失败。一旦容器处于活动状态,调度程序就会识别出任务处于运行状态。如果容器未通过运行状况检查或终止,则任务将终止。
swarm manager默认使用 ingress 负载均衡来暴露需要让外部访问的服务。我们可以为服务配置一个外部端口,如果没有显式指定端口的话,那么swarm manager会自动分配30000-32767之间的任意一个端口给到service。
swarn模式有一个内部的DNS组件,Swarm manager节点会为集群中的每个服务分配唯一的DNS记录和负载均衡VIP,通过Swarm内置的DNS服务器可以查询到集群中每个运行的容器,实现对服务的各个副本容器的服务发现,使用内部负载均衡机制来接受集群中节点的请求,基于DNS名字解析来实现。
3. 集群节点准备
在搭建集群之前需要先准备节点机器,这里我使用以下三台机器来构建集群。
| 操作系统 | 主机名 | ip地址 |
|---|---|---|
| centOS7.6 | server | 192.168.137.200 |
| centOS7.6 | woker1 | 192.168.137.201 |
| centOS7.6 | woker2 | 192.168.137.202 |
对于节点机器需要做以下准备:
- 安装 Docker
- 确保能与其他节点通信,防火墙放行,或者至少开放以下端口
- 配置主机名称以区分不同机器
- 确保节点机器之间时间同步
集群机器比较少的时候我们可以手动进行配置,如果正式环境集群机器比较多的话,可以参考这篇文章Docker Swarm集群环境手动部署,通过shell脚本同时对远程机器进行配置。
我自己整理的shell脚本如下:
SERVER_NAME=(server worker1 worker2)
SERVER_IP=(192.168.137.201 192.168.137.202 192.168.137.203)
# 配置本地hosts
sed -i '3,$d' /etc/hosts
echo -e "
# swarm cluster" >> /etc/hosts
let SER_LEN=${#SERVER_IP[@]}-1
for ((i=0;i<=$SER_LEN;i++)); do
echo "${SERVER_IP[i]} ${SERVER_NAME[i]}" >> /etc/hosts
done
# 同步server的密钥到其他节点
SSH_RROT_PASSWD=123456
bash <(curl -sSL https://gitee.com/yx571304/olz/raw/master/shell/ssh-key-copy.sh) "$(echo ${SERVER_IP[@]})" root $SSH_RROT_PASSWD
# 同步 hosts 到其他节点
for node in ${SERVER_IP[@]}; do
echo "[INFO] scp hosts -----> $node"
scp /etc/hosts $node:/etc/hosts
done
# 手动指定网卡 eth0(此网卡为 SERVER_IP 变量中的IP网卡)
for node in ${SERVER_IP[@]}; do
ssh -T $node <<'EOF'
HOST_IF=eth0
HOST_IP=$(ip a|grep "$HOST_IF$"|awk '{print $2}'|cut -d'/' -f1)
hostnamectl set-hostname $(grep $HOST_IP /etc/hosts | awk '{print $2}')
EOF
done
for node in ${SERVER_IP[@]}; do
echo "[INFO] Config -----> $node"
ssh -T $node <<'EOF'
# 优化ssh连接速度
sed -i "s/#UseDNS yes/UseDNS no/" /etc/ssh/sshd_config
sed -i "s/GSSAPIAuthentication .*/GSSAPIAuthentication no/" /etc/ssh/sshd_config
systemctl restart sshd
# 配置阿里云yum源
rm -f /etc/yum.repos.d/*.repo
curl -so /etc/yum.repos.d/epel-7.repo http://mirrors.aliyun.com/repo/epel-7.repo
curl -so /etc/yum.repos.d/Centos-7.repo http://mirrors.aliyun.com/repo/Centos-7.repo
sed -i '/aliyuncs.com/d' /etc/yum.repos.d/Centos-7.repo /etc/yum.repos.d/epel-7.repo
# 防火墙
firewall-cmd --set-default-zone=public
firewall-cmd --complete-reload
firewall-cmd --zone=public --add-port=2377/tcp --permanent
firewall-cmd --zone=public --add-port=7946/tcp --permanent
firewall-cmd --zone=public --add-port=7946/udp --permanent
firewall-cmd --zone=public --add-port=4789/udp --permanent
firewall-cmd --reload
# 文件/进程 限制
if [ ! "$(grep '# My Limits' /etc/security/limits.conf)" ]; then
echo -e "
# My Limits" >> /etc/security/limits.conf
echo "* soft nofile 65535" >> /etc/security/limits.conf
echo "* hard nofile 65535" >> /etc/security/limits.conf
echo "* soft nproc 65535" >> /etc/security/limits.conf
echo "* hard nproc 65535" >> /etc/security/limits.conf
echo "* soft memlock unlimited" >> /etc/security/limits.conf
echo "* hard memlock unlimited" >> /etc/security/limits.conf
fi
# 启用路由转发
echo 'net.ipv4.ip_forward = 1' >> /etc/sysctl.conf
echo 'net.bridge.bridge-nf-call-iptables = 1' >> /etc/sysctl.conf
echo 'net.bridge.bridge-nf-call-ip6tables = 1' >> /etc/sysctl.conf
# 同时同一用户可以监控的目录数量
echo 'fs.inotify.max_user_watches=524288' >> /etc/sysctl.conf
# 进程拥有VMA(虚拟内存区域)的数量
echo 'vm.max_map_count=655360' >> /etc/sysctl.conf
# TIME_WAIT
echo 'net.ipv4.tcp_syncookies = 1' >> /etc/sysctl.conf
echo 'net.ipv4.tcp_tw_reuse = 1' >> /etc/sysctl.conf
echo 'net.ipv4.tcp_tw_recycle = 1' >> /etc/sysctl.conf
modprobe br_netfilter
sysctl -p -w /etc/sysctl.conf
# stop/disable selinux
setenforce 0
sed -i 's#SELINUX=.*#SELINUX=disabled#' /etc/selinux/config
EOF
done
# 设置时间同步
for node in ${SERVER_IP[@]}; do
echo "[INFO] Install ntpdate -----> $node"
ssh -T $node <<'EOF'
yum install -y ntpdate
ntpdate ntp1.aliyun.com
hwclock -w
crontab -l > /tmp/crontab.tmp
echo "*/20 * * * * /usr/sbin/ntpdate ntp1.aliyun.com > /dev/null 2>&1 && /usr/sbin/hwclock -w" >> /tmp/crontab.tmp
cat /tmp/crontab.tmp | uniq > /tmp/crontab
crontab /tmp/crontab
rm -f /tmp/crontab.tmp /tmp/crontab
EOF
done
# 安装docker, 从安装源获取最新稳定版本并安装(二进制版)
for node in ${SERVER_IP[@]}; do
echo "[INFO] Install docker -----> $node"
ssh -T $node <<'EOF'
bash <(curl -sSL https://gitee.com/yx571304/olz/raw/master/shell/docker/install.sh) -i docker
sed -i 's/"live-restore": true/"live-restore": false/g' /etc/docker/daemon.json
systemctl daemon-reload
systemctl restart docker.service
EOF
done
以上脚本将把集群机器的环境配置好,并且为每台机器安装好docker,使用的时候注意修改ERVER_NAME、SERVER_IP、SSH_RROT_PASSWD以及HOST_IF。
Ps: 测试环境下也可以利用docker machine快速创建docker虚拟主机用作集群节点,或者通过以下网站https://labs.play-with-docker.com/,免费创建几台机器进行测试,这里提供的在线虚拟机地址只能使用四个小时。
4. 集群构建
不包含在任何 Swarm 中的 Docker 节点,称为运行于单引擎(Single-Engine)模式。一旦被加入 Swarm 集群,则切换为 Swarm 模式。第一步我们要做的就是初始化 Swarm。
4.1 初始化swarm集群
这里我将server机器作为manager节点,执行以下命令
docker swarm init --advertise-addr 192.168.137.201
docker swarm init 会通知 Docker 来初始化一个新的 Swarm,并将自身设置为第一个管理节点,同时也会使该节点开Swarm 模式。
--advertise-addr 参数配置当前管理节点的发布地址,其他节点必须能连接这个地址。在机器只有一个ip的情况下可以省略,如果由多个ip则必须手动指定。
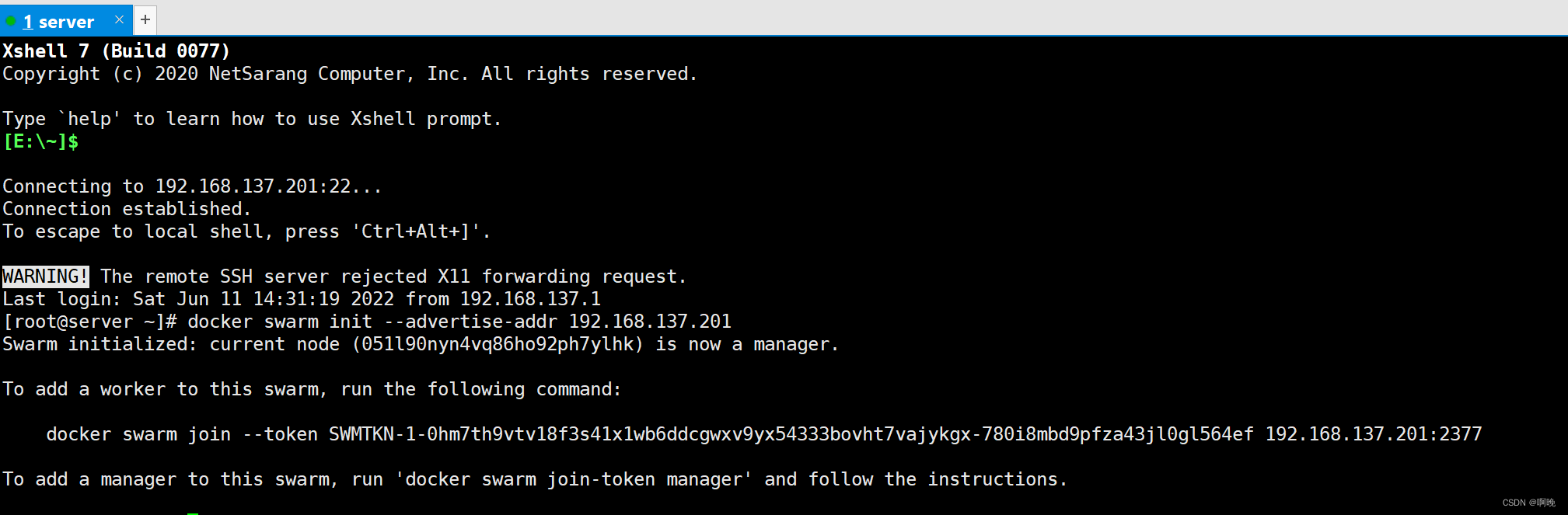
看到以上输出就代表这swarm集群初始化成功。输出信息中还包含了将其他节点作为管理节点或者工作节点加入到集群的提示。
可以通过以下命令查看集群和节点的状态:
docker info

docker node ls

可以看到当前机器已经作为管理节点中的leader加入到集群中了。
4.2 节点加入集群
其他节点可以以工作节点或管理节点的方式加入集群。如果是作为工作节点,只需要复制集群初始化后的提示命令在节点机器上执行即可。
docker swarm join --token SWMTKN-1-0hm7th9vtv18f3s41x1wb6ddcgwxv9yx54333bovht7vajykgx-780i8mbd9pfza43jl0gl564ef 192.168.137.201:2377

我们也可以根据需要新增的节点的类型,使用以下命令重新获取加入机器的命令:
docker swarm join-token worker # 查看工作节点加入集群的指令和令牌

docker swarm join-token manager # 查看管理节点加入集群的指令和令牌

远程连接到worker1机器,将其加入到集群中

再远程连接到worker2机器,将其加入到集群中

之后在manager节点,也就是server机器,就可以看到集群的节点信息了(只能是manager身份才可查看)。

以上是手动加入集群的过程,如果在需要快速加入集群的话,可以在上面配置节点机器的shell脚本的基础上进行修改,在机器配置完成之后自动构建集群
4.3 刷新令牌
token是一个节点加入swarm集群的唯一必要条件,非常重要,特别是管理器令牌,因为它们允许新的管理器节点加入并获得对整个进程的控制。token不应该给和应用源码那些存放在一起,官方推荐至少6个月对token进行一次刷新。
刷新令牌命令如下,可以指定刷新worker节点令牌还是manager节点令牌:
docker swarm join-token --rotate worker

token刷新对已加入集群的节点不会有影响,但是后续想加入集群的节点必须使用新的token。
4.4 集群锁定
尽管swarm内置有很多的原生安全机制,但是重启一个旧的管理节点或进行备份恢复仍有可能对集群造成影响。
一个旧的管理节点重新接入 Swarm 会自动解密并获得 Raft 数据库中长时间序列的访问权,这会带来安全隐患。
进行备份恢复可能会抹掉最新的 Swarm 配置。
为了规避以上问题,Docker 提供了自动锁机制来锁定 Swarm,这会强制要求重启的管理节点在提供一个集群解锁码之后才有权从新接入集群。
我们可以在集群初始化的时候启用swarm集群的自动锁定功能:
docker swarm init --autolock --advertise-addr 192.168.137.201
对于已经存在的集群,可以在管理节点上通过以下方式启动或禁用自动锁定功能:
docker swarm update --autolock=true
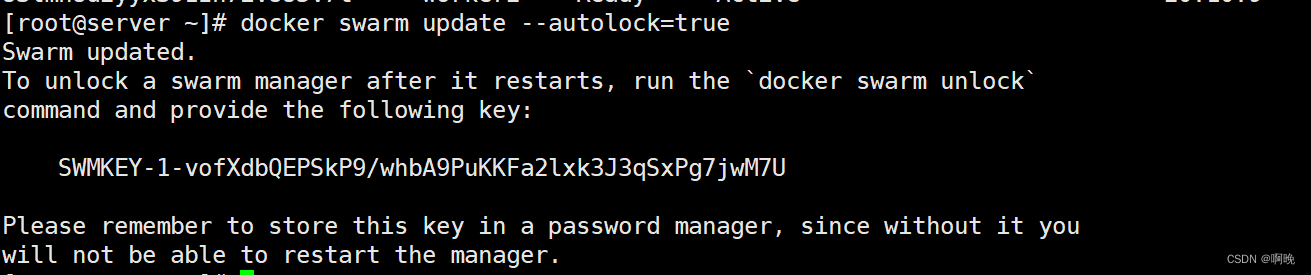
启用了自动锁定功能之后输出的密钥非常重要,后续集群里的管理节点重启等操作需要用到,请妥善保存。
下面我将两个工作节点都先升级到管理节点

启用了自动锁定功能之后,管理节点将重启之后将无法直接加入到集群中,在worker1上重启docker

尝试使用docker node命令

从server机器上可以看到worker1节点处于 unreachable 状态

在worker1上执行 docker swarm unlock 命令来为解锁 Swarm,需要提供解锁码,也就是刚才配置 --autolock=true 时生产的密钥。

解锁之后,worker1就重新接入 Swarm,再次执行 docker node ls 命令可以看到显示 ready 和 reachable状态了
有些时候我们可能会忘记解锁码,这时候我们可以通过以下命令来查看现用的解锁码
docker swarm unlock-key
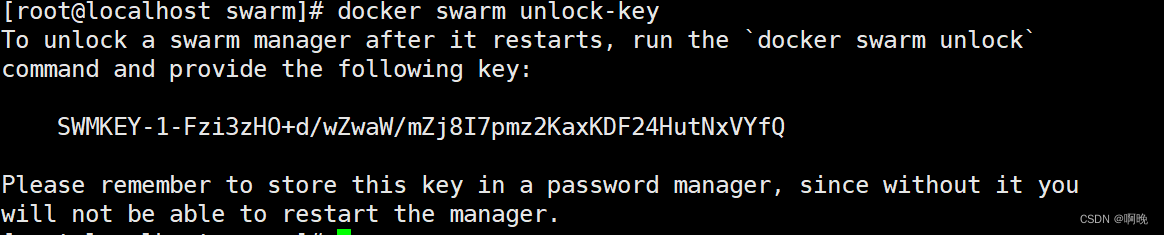
为了保证解锁码的安全,避免泄露,我们可以定期的刷新更换解锁码
docker swarm unlock-key --rotate
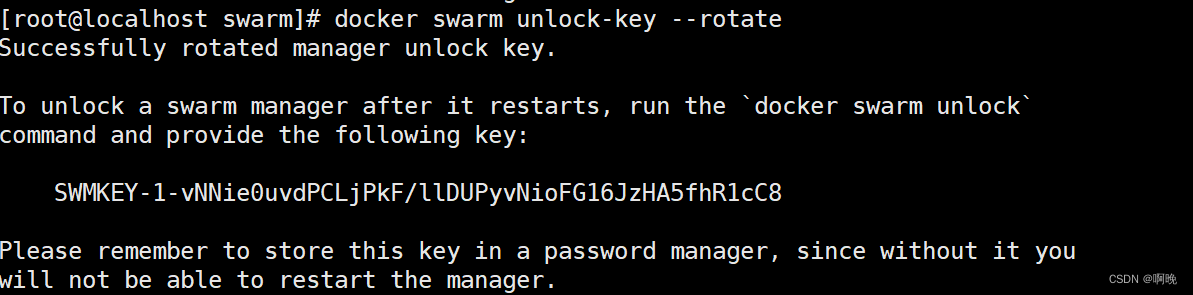
当刷新解锁钥匙时,我们将旧解锁码的记录保存一段时间,因为解锁码在管理节点之间同步需要一小段时间,如果其他管理节点在拿到新解锁码之前宕机,那么它仍可能用旧解锁码解锁。
5. swarm集群管理基本命令
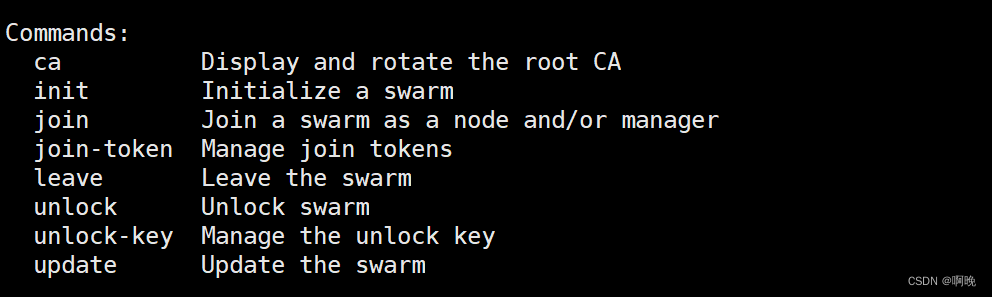
5.1 docker swarm
docker swarm 命令用于集群管理,常用的命令如下,可用–help查看详细说明:
5.1.1 docker swarm init [OPTION]
初始化集群,常用参数有:
- –advertise-addr: 多网卡的情况下,指定需要使用的ip,或者指定一个节点上没有的 IP,比如一个负载均衡的 IP
- –listen-addr: 指定监听的 ip 与端口,通常与
--advertise-addr相匹配,如果--advertise-addr设置了一个远程 IP 地址(如负载均衡的IP地址),该属性也是需要设置的 - –autolock: 指定集群启用自动锁定功能
- –availability: 节点的有效性(“active”|“pause”|“drain”)
- Active:集群中该Node可以被指派Task
- Pause:集群中该Node不可以被指派新的Task,但是其他已经存在的Task保持运行
- Drain:集群中该Node不可以被指派新的Task,Swarm Scheduler停掉已经存在的Task,并将它们调度到可用的Node上
5.1.2 docker swarm join-token [OPTION] (worker | manager)
管理集群令牌,可查看、刷新令牌,只能在管理节点执行,参数如下:
- -q:只输出令牌
- –rotate: 刷新令牌
5.1.3 docker swarm join [OPTIONS] HOST:PORT
将一个节点机器加入集群,需要在节点机器上执行,常用参数如下:
- –advertise-addr: 多网卡的情况下,指定需要使用的ip
- –listen-addr: 指定监听的 ip 与端口,通常与 --advertise-addr 相匹配
- –availability: 节点的有效性(“active”|“pause”|“drain”)
- –token:集群令牌
5.1.4 docker swarm update [OPTIONS]
更新集群状态,只能在管理节点执行,常用参数如下:
- –autolock:修改管理节点的自动锁定功能配置,可用值有: true、false
- –cert-expiry:验证节点之间的通讯令牌的间隔,默认时2160小时,可用单位: ns|us|ms|s|m|h
- –dispatcher-heartbeat:心跳包间隔时长,默认5秒,可用单位:ns|us|ms|s|m|h
- –task-history-limit:任务历史记录保留限制
5.1.5 docker swarm leave [OPTIONS]
脱离集群,在需要退出的节点执行,如果只有一个管理节点的情况下,管理节点退出集群,集群解散。参数如下:
- -f: 强制退出集群
一个节点退出集群之后,docker node ls命令还可以看到该节点信息,只是处于down状态。
5.1.6 docker swarm unlock-key [OPTIONS]
管理解锁码,可查看、刷新解锁码
- -q:只输出解锁码
- –rotate:刷新解锁码
5.1.7 docker swarm unlock
解锁一个管理节点
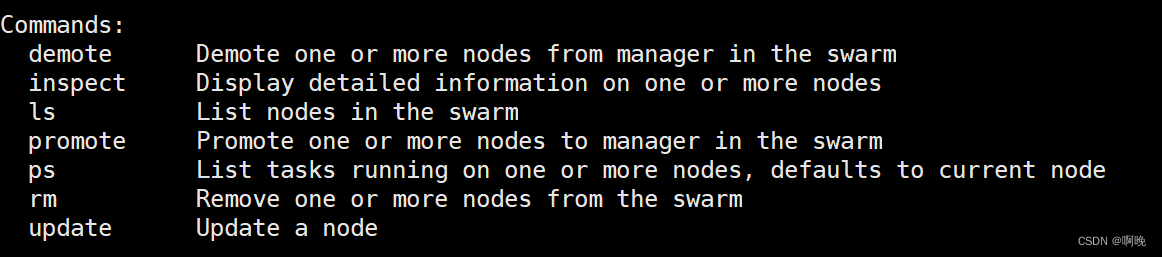
5.2 docker node
docker node 命令用于节点管理,常用的命令如下:
5.2.1 docker node ls [OPTIONS]
列出集群中的节点,只能在管理节点操作
5.2.2 docker node inspect [OPTIONS] self|NODE [NODE…]
查看节点的详细信息,只能在管理节点操作
- –pretty:格式化输出信息
可以使用self查看当前节点,也可以使用节点名称查看其他节点,可以通过多个节点名称一次性查看多个节点
5.2.3 docker node demote NODE [NODE…]
对节点进行降级,从管理节点降级到工作节点,通过节点名称一次性可以对多个几点进行操作,尽量多个节点进行操作,保持管理节点是奇数个,只能在管理节点操作
5.2.4 docker node promote NODE [NODE…]
对节点进行升级,从工作节点升级到管理节点,通过节点名称一次性可以对多个几点进行操作,尽量多个节点进行操作,保持管理节点是奇数个,只能在管理节点操作
5.2.5 docker node ps [OPTIONS] [NODE…]
查看节点上正在执行的任务,可以通过节点名称查看某一节点的任务,默认是当前节点,只能在管理节点操作
5.2.6 docker node update [OPTIONS] NODE
更改一个节点的配置,只能在管理节点操作
- –availability:更改节点的状态,可用状态有:“active”、“pause”、“drain”
- –label-add:为节点添加或更新标签,以key=value的形式
- –label-rm:移除节点标签
- –role:设置节点角色,可用值:“worker”、“manager”,相当于升降级
5.2.7 docker node rm [OPTIONS] NODE [NODE…]
通过节点名称移除节点,只能在管理节点操作,可以一次移除多个节点,一个节点使用docker swarm leave命令脱离集群之后还可以用docker node ls命令看到,使用docker node rm移除的节点将彻底不再集群中。
- -f:强制移除
这一篇先到这里,讲解了swarm集群的构建,下一篇再在这个基础上继续深入容器集群的使用。
微服务系列文章:
上一篇:容器技术—docker compose
上一篇:容器技术—docker swarm(二)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)