初探语音识别ASR算法
摘要:语音转写文字ASR技术的基本概念与数学原理简介。
摘要:语音转写文字ASR技术的基本概念与数学原理简介。
本文分享自华为云社区《新手语音入门(三): 语音识别ASR算法初探 | 编码与解码 | 声学模型与语音模型 | 贝叶斯公式 | 音素》,作者:黄辣鸡 。
语音识别技术的发展已有数十年发展历史,大体来看可以分成传统的识别的方法和基于深度学习网络的端到端的方法。
无论哪种方法,都会遵循“输入-编码-解码-输出”的过程。
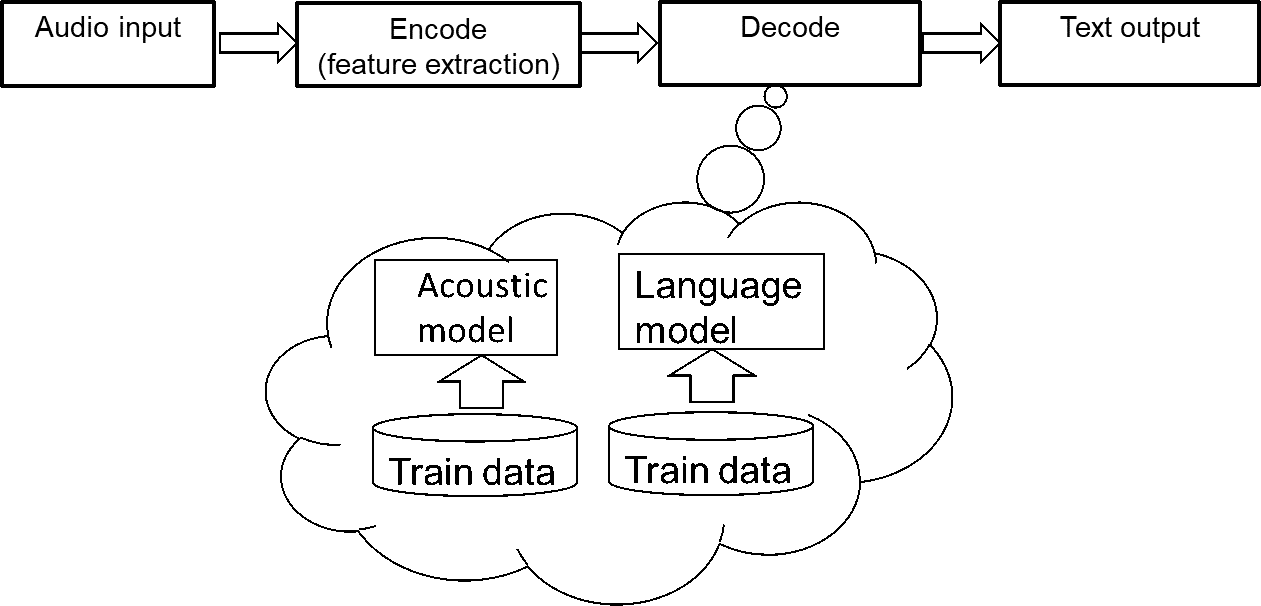
图1 语音识别过程
编码过程:
语音识别的输入是声音,属于计算机无法直接处理的信号,所以需要编码过程将其转变为数字信息,并提取其中的特征进行处理。编码时一般会将声音信号按照很短的时间间隔,切成小段,成为帧。对于每一帧,可以通过某种规则(例如MFCC特征)提取信号中的特征,将其变成一个多维向量。向量中的每个维度都是这帧信号的一个特征。
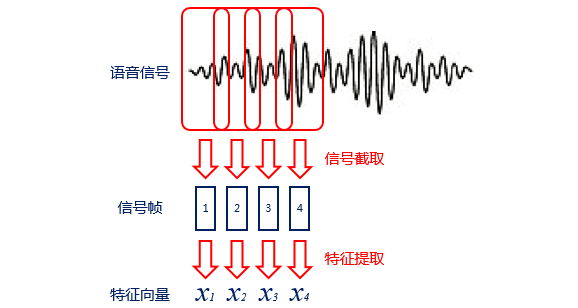
图2 语音识别编码过程
解码过程:
解码过程则是将编码得到的向量变成文字的过程,需要经过两个模型的处理,一个模型是声学模型,一个模型是语言模型。声学模型通过处理编码得到的向量,将相邻的帧组合起来变成音素,如中文拼音中的声母和韵母,再组合起来变成单个单词或汉字。语言模型用来调整声学模型所得到的不合逻辑的字词,使识别结果变得通顺。两者都需要大量数据用来训练。
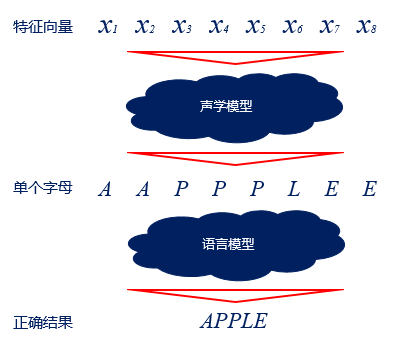
图3 语言模型处理过程
已知一段音频信号,处理成声学特征向量Acoustic Feature Vector后表示为X=[x1,x2,x3,…]X=[x1,x2,x3,…],其中x_ixi表示一帧特征向量;可能的文本序列表示为W=[w1,w2,w3,…]W=[w1,w2,w3,…],其中wi表示一个词,求W∗=argmaxwP(W∣X),这便是语音识别的基本出发点。并且由贝叶斯公式可知:
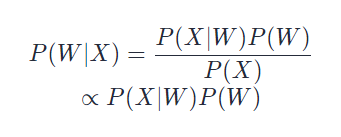
其中,P(X|W)P(X∣W)称之为声学模型(Acoustic Model, AM), P(W)P(W)称之为语言模型(Language Model, LM),由于P(W)P(W)一般是一个不变量,可以省去不算。
目前许多研究将语音识别问题看做声学模型与语音模型两部分,分别求取P(X|W)P(X∣W)和P(W)P(W)。后来,基于深度学习和大数据的端对端(End-to-End)方法发展起来,直接计算P(W|X)P(W∣X),把声学模型和语言模型融为了一体。
语音识别的问题可以看做是语音到文本的对应关系,语音识别问题大体可以归结为文本基本组成单位的选择上。单位不同,则建模力度也随之改变。
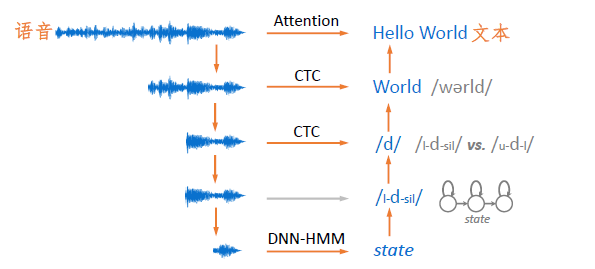
图4 语音识别的基本途径
根据图中文本基本组成单位从大到小分别是:
- 整句文本,如“Hello
World”,对应的语音建模尺度为整条语音。 - 词,如孤立词“Good”、“World”、对应的语音建模尺度大约为每个词的发音范围。
- 音素,如将“world”进一步表示为“/wɘrld//wɘrld/”,其中的每个音标作为基本单位,对应的语音建模尺度则缩减为每个音素的发音范围。
- 三音素,即考虑上下文的音素,如将音素“/d//d/”进一步表示为“{/l-d-sil, /u-d-l/,…}/l−d−sil,/u−d−l/,…”,对应的语音建模尺度是每个三音素的发音范围,长度与单音素差不多。
- 隐马尔可夫模型状态,即将每个三因素都用一个三状态隐马尔可夫模型表示,并用每个状态作为建模粒度,对应的语音建模尺度将进一步缩短。
上面每种实现方法都对应着不同的建模粒度,大体可以分为以隐马尔可夫模型结构和端对端的结构。后面两期博文将详细介绍基于两种结构的语音识别算法设计。
参考
- 语音识别基本法 - 清华大学语音和语言技术中心[PDF]

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献6320条内容
已为社区贡献6320条内容

所有评论(0)