基于华为开发者空间,实现RFM分析与CLTV预测的电商客户细分与营销策略优化
本案例将基于华为开发者空间,通过RFM分析与CLTV预测的结合,实现电商客户细分与营销策略优化。
本案例由开发者:天津师范大学协同育人项目–翟羽佳提供
最新案例动态,请查阅 《【案例共创】基于华为开发者空间,实现RFM分析与CLTV预测的电商客户细分与营销策略优化》。小伙伴快来领取华为开发者空间进行实操吧!
一、概述
1. 案例介绍
随着电子商务行业的竞争加剧,企业需要更加精细化的客户管理策略来提升客户忠诚度和营销效率。根据最新的市场调研,电商行业平均客户流失率高达35%,而营销活动的平均投资回报率(ROI)仅为 1:4,远低于行业标杆水平(数据来源:2024 年电商行业报告)。
在此背景下,客户关系管理(CRM)和客户生命周期价值(CLTV)分析成为提升企业竞争力的关键。通过客户细分和精准营销,企业可以有效提升客户价值,优化资源配置,实现可持续增长。数据科学价值通过RFM模型和CLTV预测的结合,项目实现:
1.算法创新:使用 BG-NBD 模型预测客户的未来购买行为,Gamma-Gamma 模型预测客户的平均交易价值,结合RFM分群实现精准客户细分;
2.业务落地:识别高价值“忠诚客户群体” (占比 “10%”,CLTV 值超均值 3 倍);定位“高潜流失群”体 (购买频次下降且消费金额减少),设计专属挽回策略;
3.财务收益:预计首年推动营销成本下降 15%,高价值客户 LTV 提升25%。
2. 适用对象
- 企业
- 个人开发者
- 高校学生
3. 案例时间
本案例总时长预计90分钟。
4. 案例流程
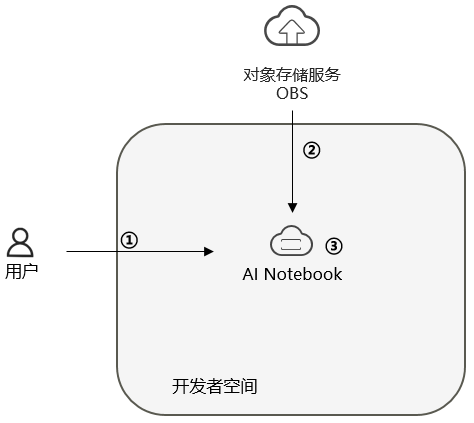
说明:
- 配置AI Notebook和运行环境环境;
- 从OBS下载文件;
- 编辑并运行代码;
5. 资源总览
本案例预计花费0元。
| 资源名称 | 规格 | 单价(元) | 时长(分钟) |
|---|---|---|---|
| 开发者空间AI Notebook | NPU basic | 1 * NPU 910B | 8v CPU | 24GB | euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook | 0 | 90 |
二、开发者空间AI Notebook和运行环境配置
1. 开发者空间AI Notebook配置
本案例中,使用开发者空间AI Notebook进行代码编写、功能实现,华为开发者空间Notebook是一款面向开发者的一站式云端开发工具,主要用于AI开发、数据分析、模型训练等场景。
开发者直接进入到开发者空间工作台。
进入到开发者空间工作台后,找打AI Notebook,点击立即前往。
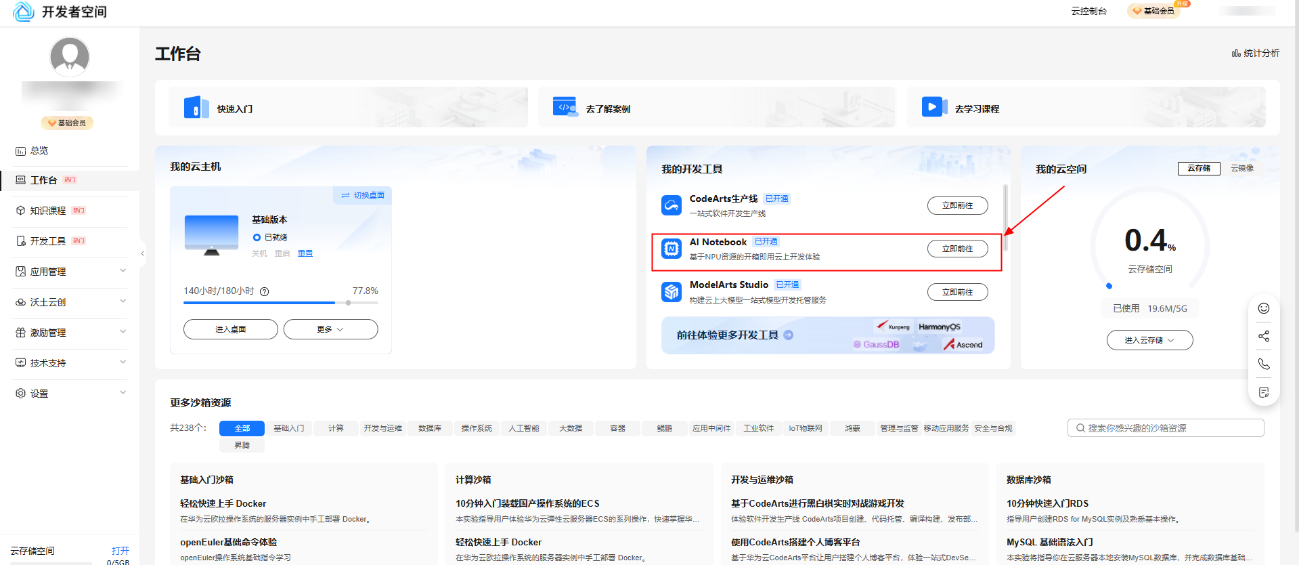
进入到AI Notebook页面后,选择NPU环境点击立即启动。
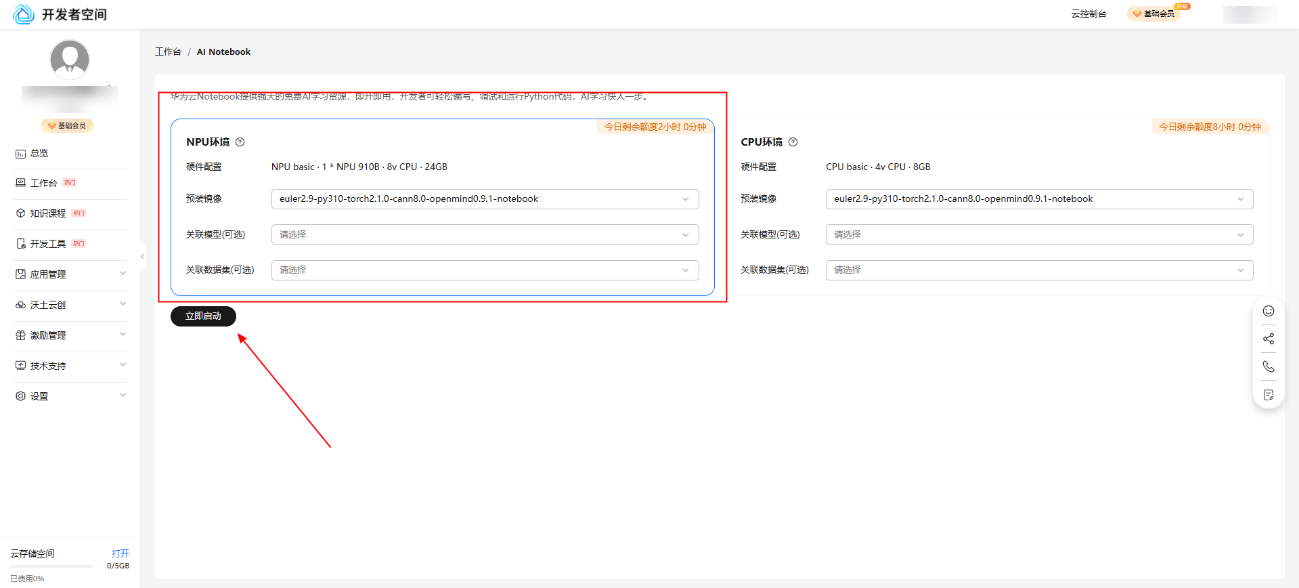
稍等片刻后点击查看Notebook,前往Notebook主页面。
至此,成功打开Notebook。
2. 运行环境配置
打开Notebook后,点击笔记下的python 3,创建代码编写文件。
3. 安装依赖库
通过如下指令,安装python第三方依赖库。
pip install numpy
pip install pandas
pip install matplotlib
pip install scikit-learn
pip install seaborn
pip install pygments
pip install lifetimes
pip install openpyxl
pip install squarify
pip install sqlalchemy

注:若安装失败或安装过程较慢,可以更换国内镜像源。
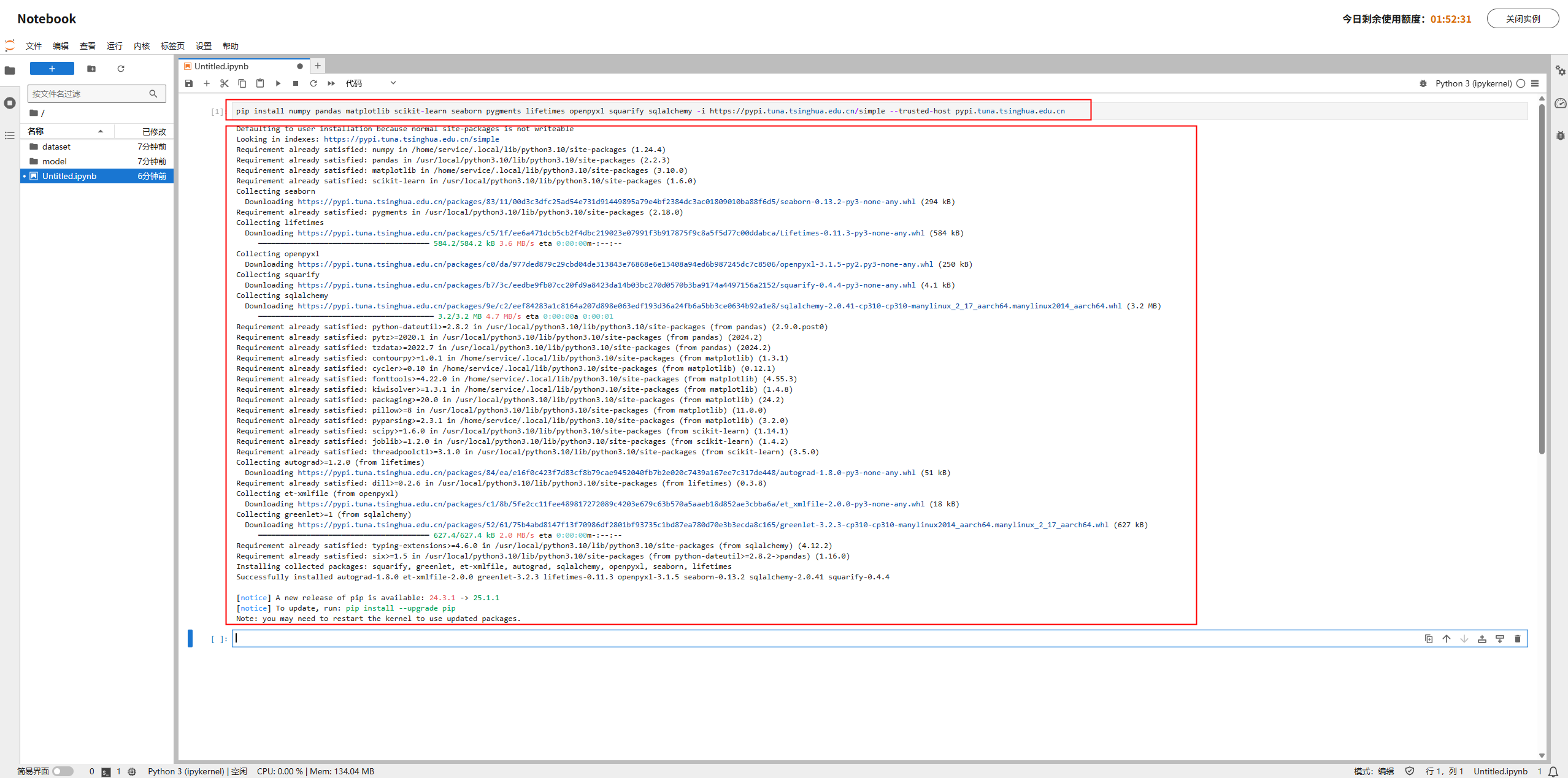
pip install numpy pandas matplotlib scikit-learn seaborn pygments lifetimes openpyxl squarify sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
系统会自动安装相关的包和工具,当安装完成后,系统会返回所有已成功安装的库,如下图所示:
安装成功后对脚本进行运行可得到关于 Python 数据处理全流程开发,并具备将本地模型迁移至华为云实现工业级部署的能力。
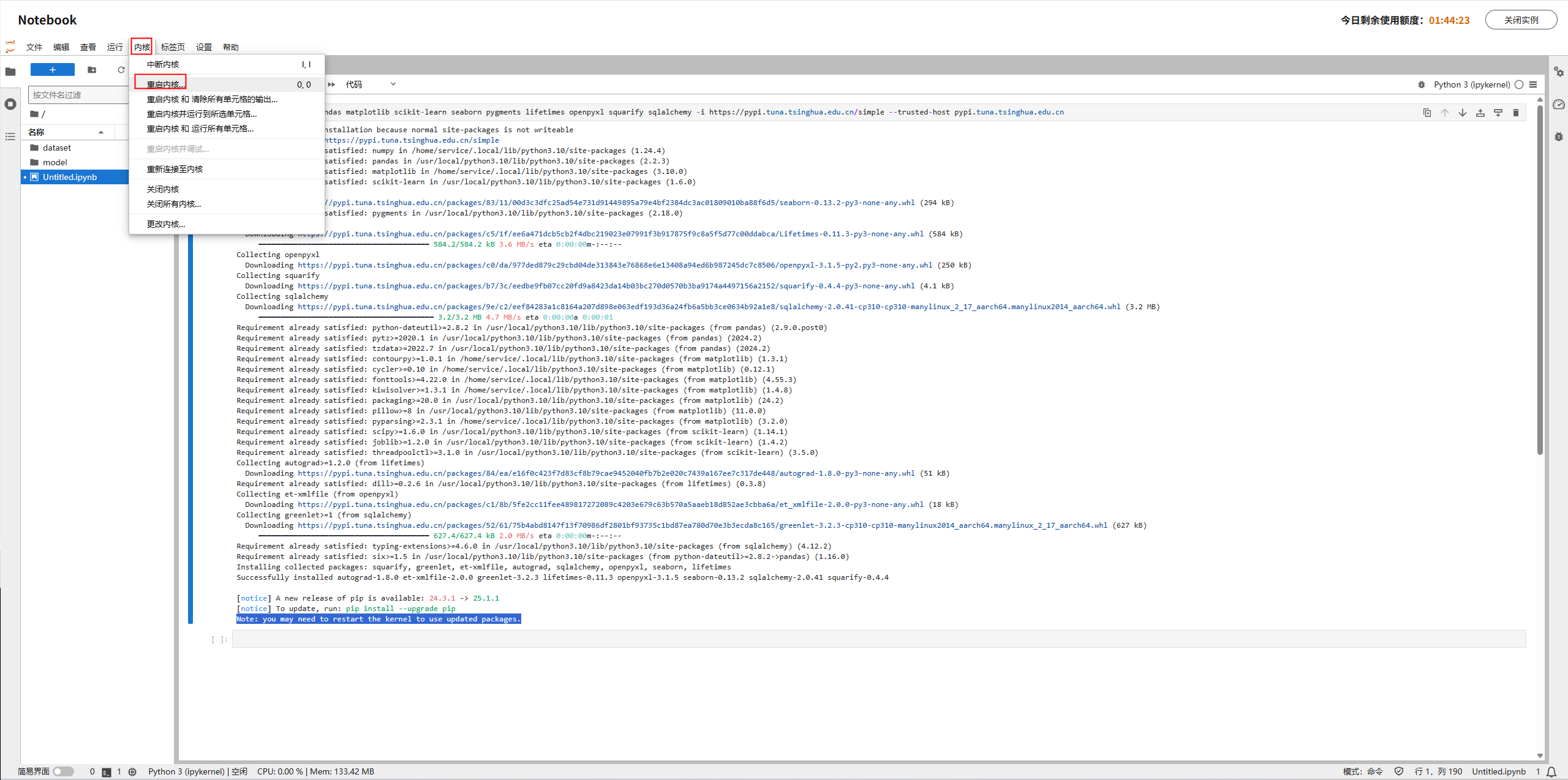
注:在安装三方库的末尾,日志显示Note: you may need to restart the kernel to use updated packages.,这里系统提示我们需要手动重启内核来更新环境,点击Notebook顶部菜单栏内核>重启内核。
三、代码实现与运行验证
1. 获取原始数据
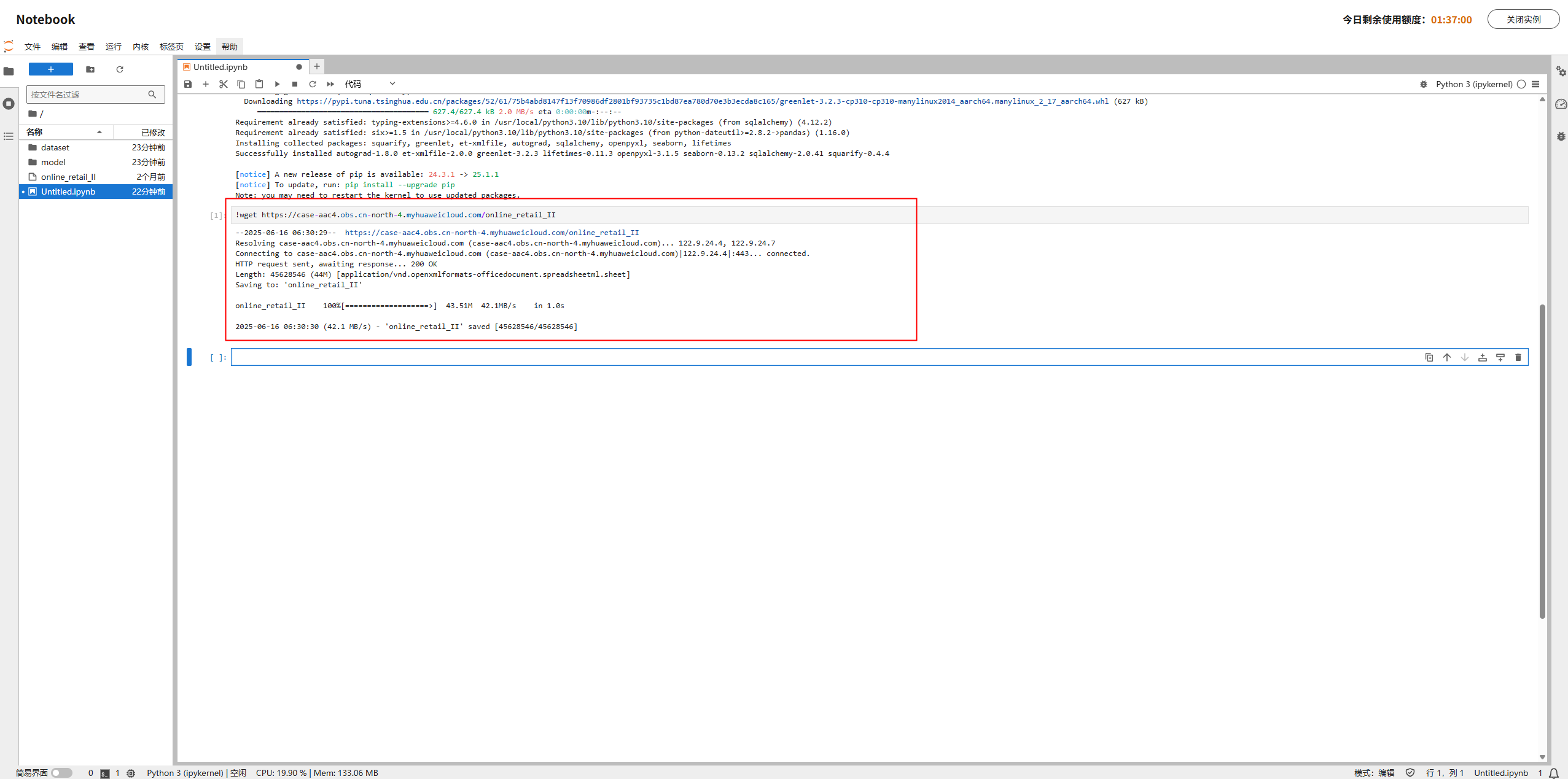
为了方便项目运行,已提前将文件上传OBS,之后通过分享链接在Notebook中可直接下载使用。文件压缩包中包含后续所有的文件:
OBS链接地址:https://case-aac4.obs.cn-north-4.myhuaweicloud.com/online_retail_II
下载命令行:
!wget https://case-aac4.obs.cn-north-4.myhuaweicloud.com/online_retail_II
2. 功能分析
数据清洗:处理缺失值、异常值、退货订单。
RFM分析:通过Recency、Frequency、Monetary对客户分层。
CLTV预测:结合概率模型预测客户长期价值,支持业务决策。
可视化:贯穿始终,辅助理解数据分布和结果。
3. 代码实现
3.1 数据导入与初始化
# 导入所需的库
from sqlalchemy import create_engine # 用于创建数据库连接
import datetime as dt # 用于处理日期和时间
import pandas as pd # 用于数据处理和分析
import seaborn as sns # 用于数据可视化
import matplotlib.pyplot as plt # 用于绘图
from lifetimes import BetaGeoFitter # 用于BG/NBD模型的拟合
from lifetimes import GammaGammaFitter # 用于Gamma-Gamma模型的拟合
from lifetimes.plotting import plot_period_transactions # 用于绘制周期交易图
from sklearn.preprocessing import MinMaxScaler # 用于数据归一化
import squarify # 用于绘制树状图(treemap)
import warnings # 用于处理警告信息
warnings.filterwarnings("ignore") # 忽略警告信息
# 遍历指定目录下的文件
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# 使用 Pandas 的 read_excel 函数读取 Excel 文件中的数据
df_2010_2011 = pd.read_excel(r"online_retail_II", sheet_name="Year 2010-2011")
# 创建一个 DataFrame 的副本,命名为 df保留原始数据 df_2010_2011
df = df_2010_2011.copy()
# 使用 DataFrame 的 head() 方法查看数据的前 5 行
df.head()
3.2 数据预处理
# 使用 Pandas 的字符串操作方法 str.contains() 检查 "Invoice" 列中的值是否包含 "C"
df = df[~df["Invoice"].str.contains("C", na=False)]
# 删除 DataFrame 中包含缺失值的所有行
df.dropna(inplace=True)
# 定义异常值处理函数
def outlier_thresholds(dataframe, variable):
quartile1 = dataframe[variable].quantile(0.01)
quartile3 = dataframe[variable].quantile(0.99)
interquantile_range = quartile3 - quartile1
up_limit = quartile3 + 1.5 * interquantile_range
low_limit = quartile1 - 1.5 * interquantile_range
return low_limit, up_limit
def replace_with_thresholds(dataframe, variable):
low_limit, up_limit = outlier_thresholds(dataframe, variable)
dataframe.loc[(dataframe[variable] < low_limit), variable] = low_limit
dataframe.loc[(dataframe[variable] > up_limit), variable] = up_limit
# 处理异常值
replace_with_thresholds(df, "Quantity")
replace_with_thresholds(df, "Price")
3.3 数据概览函数
# 定义函数 check_df,用于快速检查 DataFrame 的基本信息
def check_df(dataframe):
print("################ Shape ####################")
print(dataframe.shape)
print("############### Columns ###################")
print(dataframe.columns)
print("############### Types #####################")
print(dataframe.dtypes)
print("############### Head ######################")
print(dataframe.head())
print("############### Tail ######################")
print(dataframe.tail())
print("############### Describe ###################")
print(dataframe.describe().T)
# 调用 check_df 函数
check_df(df)
3.4 类别型变量分析
# 获取类别型变量
cat_cols = [col for col in df.columns if df[col].dtypes == "O"]
cat_but_car = [col for col in df.columns if df[col].nunique() > 100 and df[col].dtypes == "O"]
cat_cols = [col for col in cat_cols if col not in cat_but_car]
# 定义类别型变量分析函数
def cat_summary(dataframe, col_name, plot=False):
print(pd.DataFrame({col_name: dataframe[col_name].value_counts(),
"Ratio": 100 * dataframe[col_name].value_counts() / len(dataframe)}))
print("##########################################")
if plot:
fig_dims = (15, 5)
fig, ax = plt.subplots(figsize=fig_dims)
sns.countplot(x=dataframe[col_name], data=dataframe)
plt.xticks(rotation=45, ha='right')
plt.savefig("Country")
plt.close()
# 分析国家分布
cat_summary(df, "Country", plot=True)
3.5 数值型变量分析
# 获取数值型变量
num_cols = [col for col in df.columns if df[col].dtypes != 'O' and col not in ["Customer ID"]]
# 定义数值型变量分析函数
def num_summary(dataframe, numerical_col, plot=False):
if dataframe[numerical_col].dtype in ['int64', 'float64']:
quantiles = [0.05, 0.10, 0.20, 0.30, 0.40, 0.50, 0.60, 0.70, 0.80, 0.90, 0.95, 0.99]
print(dataframe[numerical_col].describe(quantiles).T)
if plot:
dataframe[numerical_col].hist(bins=20)
plt.xlabel(numerical_col)
plt.title(numerical_col)
plt.savefig(f"{numerical_col}_histogram.png")
plt.close()
# 分析数值型变量
for col in num_cols:
num_summary(df, col, plot=True)
3.6 商品销售分析
# 分析商品销售情况
df["StockCode"].nunique()
df_product = df.groupby("Description").agg({"Quantity": "count"}).reset_index()
top_pr = df_product.sort_values(by="Quantity", ascending=False).head(10)
sns.barplot(x="Description", y="Quantity", data=top_pr)
plt.xticks(rotation=90)
plt.savefig("Description")
plt.close()
3.7 RFM分析
# 计算总销售额
df["TotalPrice"] = df["Price"] * df["Quantity"]
# 计算RFM指标
df["InvoiceDate"] = pd.to_datetime(df["InvoiceDate"])
today_date = dt.datetime(2011, 12, 11)
rfm = df.groupby("Customer ID").agg({
"InvoiceDate": lambda InvoiceDate: (today_date - InvoiceDate.max()).days,
"Invoice": lambda Invoice: Invoice.nunique(),
"TotalPrice": lambda TotalPrice: TotalPrice.sum()
})
rfm.columns = ["recency", "frequency", "monetary"]
rfm = rfm[rfm["monetary"] > 0]
# 计算RFM分数
rfm["recency_score"] = pd.qcut(rfm['recency'], 5, labels=[5, 4, 3, 2, 1])
rfm["frequency_score"] = pd.qcut(rfm["frequency"].rank(method="first"), 5, labels=[1, 2, 3, 4, 5])
rfm["monetary_score"] = pd.qcut(rfm["monetary"], 5, labels=[1, 2, 3, 4, 5])
rfm["RFM_SCORE"] = (rfm["recency_score"].astype(str) + rfm["frequency_score"].astype(str))
# 客户分段
seg_map = {
r'[1-2][1-2]': 'hibernating',
r'[1-2][3-4]': 'at_Risk',
r'[1-2]5': 'cant_loose',
r'3[1-2]': 'about_to_sleep',
r'33': 'need_attention',
r'[3-4][4-5]': 'loyal_customers',
r'41': 'promising',
r'51': 'new_customers',
r'[4-5][2-3]': 'potential_loyalists',
r'5[4-5]': 'champions'
}
rfm['segment'] = rfm['RFM_SCORE'].replace(seg_map, regex=True)
# 分段分析
rfm[["segment", "recency", "frequency", "monetary"]].groupby("segment").agg(["mean", "count"])
# 可视化
sgm = rfm["segment"].value_counts()
plt.figure(figsize=(10, 7))
sns.barplot(x=sgm.index, y=sgm.values)
plt.xticks(rotation=45)
plt.title('Customer Segments2', color='blue', fontsize=15)
plt.savefig("Customer Segments2")
plt.close()
# 树状图
df_treemap = rfm.groupby('segment').agg('count').reset_index()
fig, ax = plt.subplots(1, figsize=(10, 10))
squarify.plot(sizes=df_treemap['RFM_SCORE'],
label=df_treemap['segment'],
alpha=0.8,
color=['tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray'])
plt.axis('off')
plt.savefig("2")
plt.close()
3.8 CLTV预测
# 准备CLTV数据
cltv_df = df.groupby('Customer ID').agg({
'InvoiceDate': [lambda date: (date.max() - date.min()).days,
lambda date: (today_date - date.min()).days],
'Invoice': lambda num: num.nunique(),
'TotalPrice': lambda TotalPrice: TotalPrice.sum()
})
cltv_df.columns = ['recency', 'T', 'frequency', 'monetary']
cltv_df["monetary"] = cltv_df["monetary"] / cltv_df["frequency"]
cltv_df = cltv_df[(cltv_df['frequency'] > 1) & (cltv_df['monetary'] > 0)]
cltv_df["recency"] = cltv_df["recency"] / 7
cltv_df["T"] = cltv_df["T"] / 7
# BG/NBD模型
bgf = BetaGeoFitter(penalizer_coef=0.001)
bgf.fit(cltv_df['frequency'], cltv_df['recency'], cltv_df['T'])
cltv_df["expected_purc_1_week"] = bgf.predict(1, cltv_df['frequency'], cltv_df['recency'], cltv_df['T'])
cltv_df["expected_purc_1_month"] = bgf.predict(4, cltv_df['frequency'], cltv_df['recency'], cltv_df['T'])
# Gamma-Gamma模型
ggf = GammaGammaFitter(penalizer_coef=0.01)
ggf.fit(cltv_df['frequency'], cltv_df['monetary'])
cltv_df["expected_average_profit"] = ggf.conditional_expected_average_profit(cltv_df['frequency'], cltv_df['monetary'])
# 计算CLTV
cltv = ggf.customer_lifetime_value(
bgf, cltv_df['frequency'], cltv_df['recency'], cltv_df['T'], cltv_df['monetary'],
time=6, freq="W", discount_rate=0.01
)
cltv_final = cltv_df.merge(cltv.reset_index(), on="Customer ID", how="left")
# 归一化和分段
cltv_final["scaled_clv"] = MinMaxScaler().fit_transform(cltv_final[["clv"]])
cltv_final["segment"] = pd.qcut(cltv_final["scaled_clv"], 4, labels=["D", "C", "B", "A"])
4 运行程序代码
代码编辑完成后,点击运行按钮,等待程序运行(过程约5分钟)。
程序运行结束后,输出分析结果:
################ Shape ####################
(397925, 8)
############### Columns ###################
Index(['Invoice', 'StockCode', 'Description', 'Quantity', 'InvoiceDate',
'Price', 'Customer ID', 'Country'],
dtype='object')
############### Types #####################
Invoice object
StockCode object
Description object
Quantity float64
InvoiceDate datetime64[ns]
Price float64
Customer ID float64
Country object
dtype: object
############### Head ######################
Invoice StockCode Description Quantity \
0 536365 85123A WHITE HANGING HEART T-LIGHT HOLDER 6.0
1 536365 71053 WHITE METAL LANTERN 6.0
2 536365 84406B CREAM CUPID HEARTS COAT HANGER 8.0
3 536365 84029G KNITTED UNION FLAG HOT WATER BOTTLE 6.0
4 536365 84029E RED WOOLLY HOTTIE WHITE HEART. 6.0
InvoiceDate Price Customer ID Country
0 2010-12-01 08:26:00 2.55 17850.0 United Kingdom
1 2010-12-01 08:26:00 3.39 17850.0 United Kingdom
2 2010-12-01 08:26:00 2.75 17850.0 United Kingdom
3 2010-12-01 08:26:00 3.39 17850.0 United Kingdom
4 2010-12-01 08:26:00 3.39 17850.0 United Kingdom
############### Tail ######################
Invoice StockCode Description Quantity \
541905 581587 22899 CHILDREN'S APRON DOLLY GIRL 6.0
541906 581587 23254 CHILDRENS CUTLERY DOLLY GIRL 4.0
541907 581587 23255 CHILDRENS CUTLERY CIRCUS PARADE 4.0
541908 581587 22138 BAKING SET 9 PIECE RETROSPOT 3.0
541909 581587 POST POSTAGE 1.0
InvoiceDate Price Customer ID Country
541905 2011-12-09 12:50:00 2.10 12680.0 France
541906 2011-12-09 12:50:00 4.15 12680.0 France
541907 2011-12-09 12:50:00 4.15 12680.0 France
541908 2011-12-09 12:50:00 4.95 12680.0 France
541909 2011-12-09 12:50:00 18.00 12680.0 France
############### Describe ###################
count mean min \
Quantity 397925.0 11.833709 1.0
InvoiceDate 397925 2011-07-10 23:44:09.817126400 2010-12-01 08:26:00
Price 397925.0 2.893201 0.0
Customer ID 397925.0 15294.308601 12346.0
25% 50% 75% \
Quantity 2.0 6.0 12.0
InvoiceDate 2011-04-07 11:12:00 2011-07-31 14:39:00 2011-10-20 14:33:00
Price 1.25 1.95 3.75
Customer ID 13969.0 15159.0 16795.0
max std
Quantity 298.5 25.534486
InvoiceDate 2011-12-09 12:50:00 NaN
Price 37.06 3.227143
Customer ID 18287.0 1713.172738
Country Ratio
Country
United Kingdom 354345 89.048187
Germany 9042 2.272287
France 8343 2.096626
EIRE 7238 1.818936
Spain 2485 0.624490
Netherlands 2363 0.593830
Belgium 2031 0.510398
Switzerland 1842 0.462901
Portugal 1462 0.367406
Australia 1185 0.297795
Norway 1072 0.269397
Italy 758 0.190488
Channel Islands 748 0.187975
Finland 685 0.172143
Cyprus 614 0.154300
Sweden 451 0.113338
Austria 398 0.100019
Denmark 380 0.095495
Poland 330 0.082930
Japan 321 0.080668
Israel 248 0.062323
Unspecified 244 0.061318
Singapore 222 0.055789
Iceland 182 0.045737
USA 179 0.044983
Canada 151 0.037947
Greece 145 0.036439
Malta 112 0.028146
United Arab Emirates 68 0.017089
European Community 60 0.015078
RSA 58 0.014576
Lebanon 45 0.011309
Lithuania 35 0.008796
Brazil 32 0.008042
Czech Republic 25 0.006283
Bahrain 17 0.004272
Saudi Arabia 9 0.002262
##########################################
count 397925.000000
mean 11.833709
std 25.534486
min 1.000000
5% 1.000000
10% 1.000000
20% 2.000000
30% 2.000000
40% 4.000000
50% 6.000000
60% 8.000000
70% 12.000000
80% 12.000000
90% 24.000000
95% 36.000000
99% 120.000000
max 298.500000
Name: Quantity, dtype: float64
count 397925.000000
mean 2.893201
std 3.227143
min 0.000000
5% 0.420000
10% 0.550000
20% 0.850000
30% 1.250000
40% 1.650000
50% 1.950000
60% 2.100000
70% 2.950000
80% 4.150000
90% 6.350000
95% 8.500000
99% 14.950000
max 37.060000
Name: Price, dtype: float64
相应的生成的图片以及统计图以图片的形式保存在左侧文件中,可以手动点击进行查看:
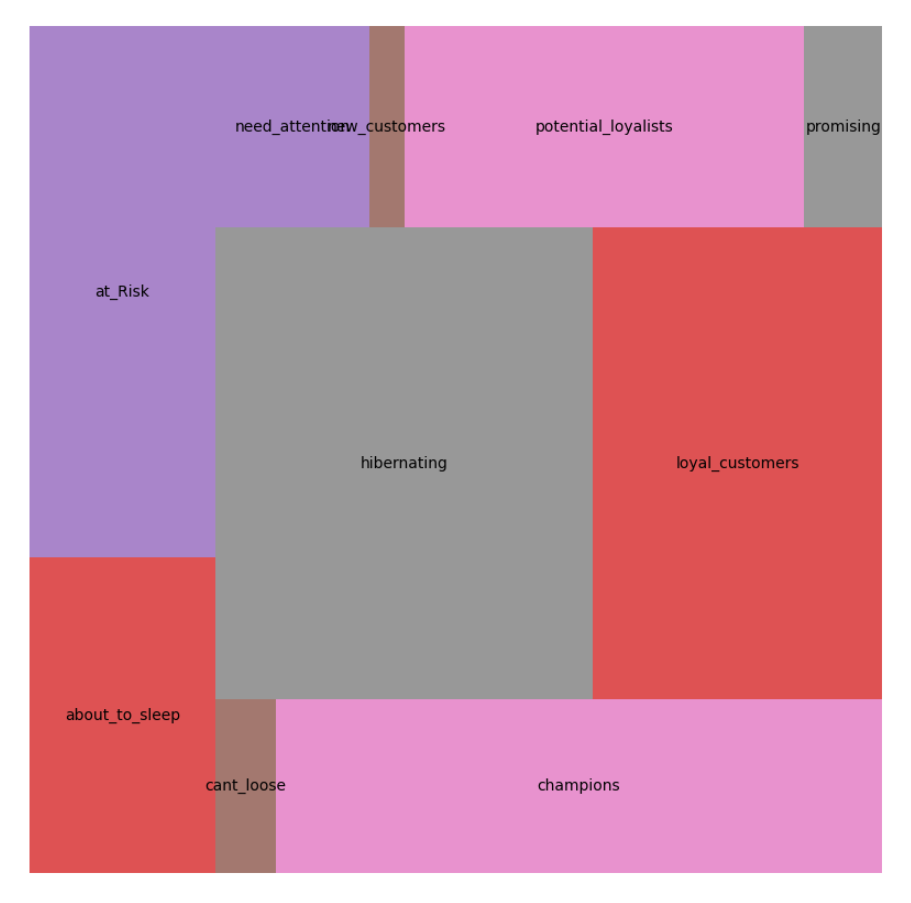
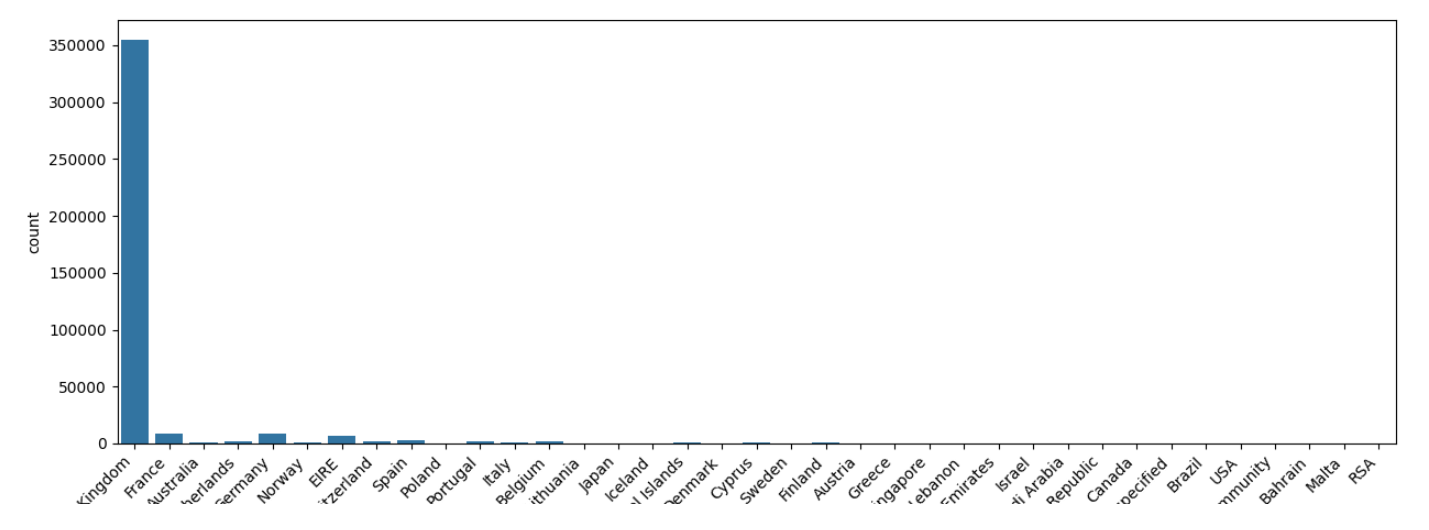
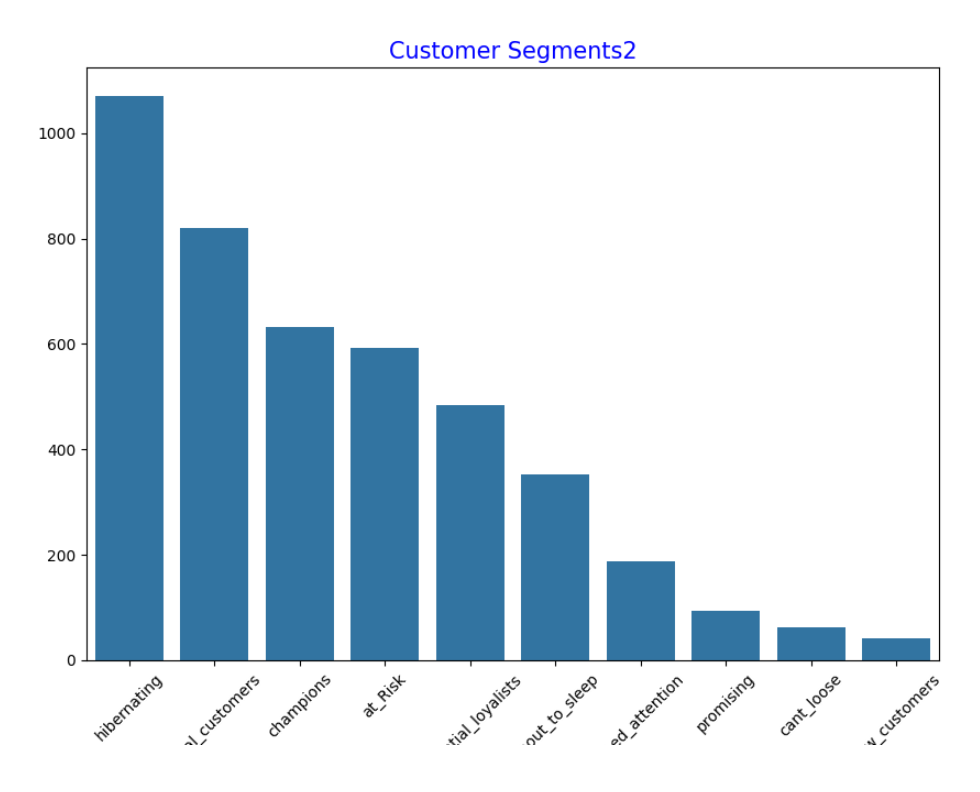
至此,基于华为开发者空间,实现RFM分析与CLTV预测的电商客户细分与营销策略优化案例结束。
四、释放资源
在运行完成后,点击关闭实例按钮,停止资源倒计时:

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 43
43 0
0- 0



 已为社区贡献6257条内容
已为社区贡献6257条内容

所有评论(0)