

一、概述
前些日子开始着手高校云平台的搭建,其中涉及很重要的一部分是hadoop集群测试环境的安装与配置,大概用了两天的时间,终于搞定了基本轮廓,把我的经验分享给大家。
二、硬件环境
1、windows 7 旗舰版 64位
2、VMware Workstation ACE 版 6.0.2
3、Redhat Linux 5
4、Hadoop-1.2.0
| Windows | VM | 虚拟机器Linux | IP | 作用 |
| Window 7 64位 | VMware Workstation | Redhat1 | 192.168.24.250 | NameNode、master、jobTracker |
| Redhat2 | 192.168.24.249 | DataNode、slave、taskTracker | ||
| Redhat3 | 192.168.24.248 | DataNode、slave、taskTracker |
三、安装 VMware Workstation 和Redhat Linux 5
1、VMware Workstation和Redhat Linux 5的安装,网上到处都是,我也是在网上随便找的,你可以找写得更详细准确的,这里不再赘述,可参考:
注:当你在虚拟机上安装完一个Linux后,不要重复安装步骤,使用虚拟机带的克隆功能,可以很容易复制出多台一模一样的Linux。
可参考:
完成这一步骤后的效果

四、安装配置Hadoop
1、安装hadoop前先配置Linux
(1)更改三台机器的网络连接方式
选中要更改的虚拟机,右击-设置(Settings)
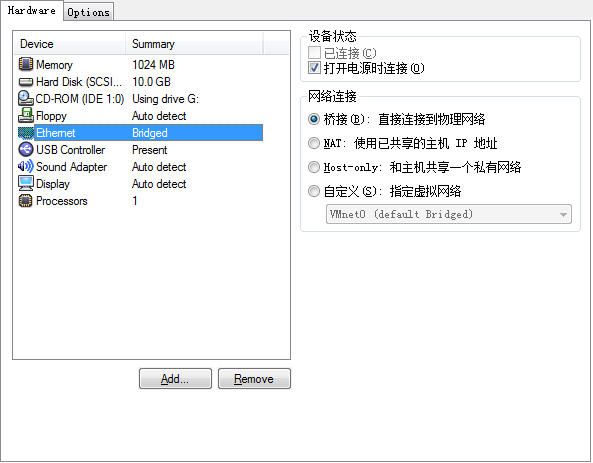
(2)以root用户登录Linux,
设置
IP
地址和默认网关(三台机器都要设置)
输入vi /etc/sysconfig/network-scripts/ifcfg-eth0 ,(vi的使用不再赘述,不懂自己网上查)修改该文件内容为:
DEVICE=eth0
BOOTPROTO=static
IPADDR=192.168.24.250
GATEWAY=192.168.27.254
NETMASK=255.255.255.0
ONBOOT=yes
IP地址和默认网关根据自己需要进行设置
(3)配置虚拟机的主机名(三台机器都要设置)
输入vi /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=yes
HOSTNAME=redhat1
(4)配置主机名与ip地址的对应关系(三台机器都要设置)
输入 vi /etc/hosts
127.0.0.1 localhost
192.168.24.250 redhat1
192.168.24.249 redhat2
192.168.24.248 redhat3
这是标准内容。去掉多余的,否则可能出现
Hadoop
在
master
查看
live nodes
为
0
(5)关闭防火墙
(三台机器都要设置)
输入 chkconfig iptables off 开机不启动防火墙
输入 service iptables stop 关闭当前防火墙服务
当然也可以设置防火墙对hadoop放行,为了简单起见,我这里就直接关闭防火墙了。
(6)测试网络是否联通
设置完成之后,在每台虚拟机之间执行ping命令,保证虚拟机之间网络没有问题
如:ping 192.168.24.249
2、建立linux之间ssh无密码登录
这个网上也到处都是,参考:
到此为止,铺垫工作算是做完了。
3、安装和配置JDK
(三台机器都要安装)
这个参考我的文章
4、安装hadoop
(三台机器都要安装)
(1)到hadoop官网下载hadoop1.2.0
(2)使用ftp上传到linux,如果不懂,可以参考我的文章:
(3)解压安装
进入hadoop-1.2.0.tar.gz所在的目录
输入:
tar -zvxf hadoop-1.2.0.tar.gz
即安装完毕
5、配置Hadoop(三台机器都要设置)
(1)配置hadoop环境变量
和设置jdk环境变量一样
命令:vi /etc/profile
在文件最后输入:
export HADOOP_HOME=/usr/local/hadoop-1.2.0
export PATH=$PATH:$HADOOP_HOME/bin
执行命令source /etc/profile 使profile生效
(2)配置hadoop运行参数
更改hadoop安装路径下/conf/hadoop-env.sh的文件(三台机器都要设置)
第9行加入export JAVA_HOME=/usr/java/jdk1.7.0_21
更改hadoop安装路径/conf/masters和slaves两个文件。(只配置192.168.24.250虚拟机)
masters中输入:192.168.24.250
slaves中输入:
192.168.24.249
192.168.24.248
配置hadoop安装路径/conf/core-site.xml、hdfs-site.xml和mapred-site.xml三个文件。(三台机器都要设置)
core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.24.250:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.24.250:9001</value>
</property>
</configuration>
(3)格式化文件系统
命令:Hadoop namenode –format
至此hadoop已经安装配置完毕了。
五、测试
1、启动hadoop
在192.168.24.250机器上执行如下指令,启动hadoop安装目录bin下:
Start-all.sh
对于hadoop来说,启动所有进程是鼻血的,但是如果有必要,你依然可以只启动HDFS(start-dfs)或MapReduce(start-mapred.sh)
Web浏览器监视HDFS文件系统状态和MAPREDUCE执行任务的情况。
HDFS文件系统
浏览器中输入:
http://192.168.11.188:50070/
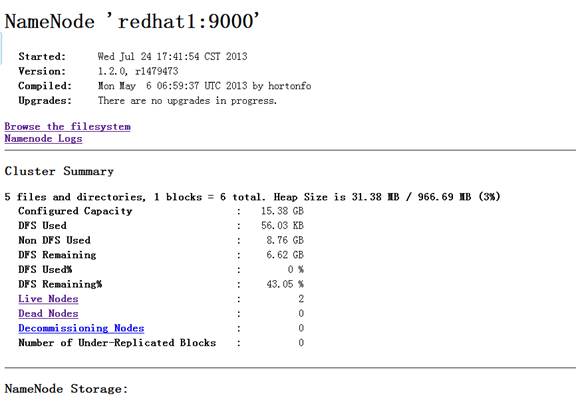
浏览器中输入:http://192.168.11.188:50030

2、运行hadoop自带的wordcount示例
依次执行命令:
echo “It is a dog”> input1
echo "it is not a dog" > input2
hadoop fs -mkdir input
hadoop fs -copyFromLocal /root/input* input
hadoop jar /usr/local/hadoop-1.2.0/hadoop-examples-1.2.0.jar wordcount input output
可以查看运行状态
http://192.168.24.250:50030

查看运行结果
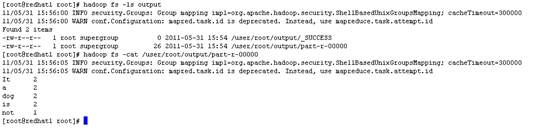
至此全部成功!
六、总结
利用多台虚拟机模拟的hadoop集群环境基本搞定,剩下的就是根据需要再做详细的配置了。如果要移植到物理存在的机器上,只需把虚拟机上的安装方式直接搬过去用就可以了。
接下来,还会继续出一篇文章介绍eclipse连接远程hadoop集群进行开发,其中也涉及一些比较麻烦的问题,不过幸好都解决了,马上整理出来,期待吧。







 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)