Hive实战:计算总分与平均分
本次实战以Hive为核心,针对学生成绩数据进行统计分析。首先,在虚拟机中创建score.txt文件存储五名学生的成绩记录,并上传至HDFS的路径下。接着启动Hive Metastore服务和客户端,创建与成绩表结构对应的内部表t_score,并运用load data命令将HDFS数据导入该表。最后,通过编写SQL语句按学生姓名分组,对各科成绩求和计算总分、平均分。此过程充分展示了Hive在大数据处
文章目录
一、实战概述
- 本次实战以Hive为核心,针对学生成绩数据进行统计分析。首先,在虚拟机中创建
score.txt文件存储五名学生的成绩记录,并上传至HDFS的/hivescore/input路径下。接着启动Hive Metastore服务和客户端,创建与成绩表结构对应的内部表t_score,并运用load data命令将HDFS数据导入该表。最后,通过编写SQL语句按学生姓名分组,对各科成绩求和计算总分、平均分。此过程充分展示了Hive在大数据处理中的高效性及便利性,只需简单SQL即可实现复杂的数据统计任务,为深入数据分析实践提供了有力支持。
二、提出任务
- 成绩表,包含六个字段(姓名、语文、数学、英语、物理、化学),有五条记录
| 姓名 | 语文 | 数学 | 英语 | 物理 | 化学 |
|---|---|---|---|---|---|
| 李小双 | 89 | 78 | 94 | 96 | 87 |
| 王丽霞 | 94 | 80 | 86 | 78 | 80 |
| 吴雨涵 | 90 | 67 | 85 | 82 | 60 |
| 张晓红 | 87 | 76 | 90 | 79 | 59 |
| 陈燕文 | 97 | 95 | 92 | 88 | 86 |
- 利用Hive框架,计算每个同学的总分与平均分
吴雨涵 404 404.0
张晓红 391 391.0
李小双 444 444.0
王丽霞 418 418.0
陈燕文 458 458.0
三、完成任务
(一)准备数据文件
1、在虚拟机上创建文本文件
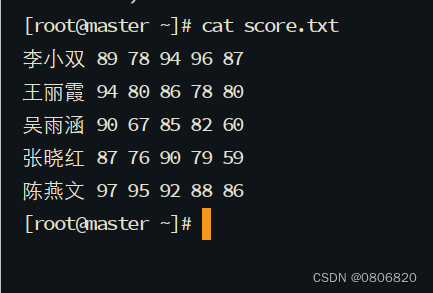
- 在master虚拟机上创建
score.txt文件
李小双 89 78 94 96 87
王丽霞 94 80 86 78 80
吴雨涵 90 67 85 82 60
张晓红 87 76 90 79 59
陈燕文 97 95 92 88 86

2、将文本文件上传到HDFS指定目录
- 在HDFS上创建
/hivescore/input目录

- 将score.txt文件上传到HDFS的
/hivescore/input目录

(二)实现步骤
1、启动Hive Metastore服务
- 执行命令:
hive --service metastore &,在后台启动metastore服务
2、启动Hive客户端
- 执行命令:
hive,看到命令提示符hive>
3、创建Hive表,加载HDFS数据文件
-
创建内部表
t_score,执行命令: -
CREATE TABLE t_score ( name STRING, chinese INT, math INT, english INT, physics INT, chemistry INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';

-
在MySQL的hive数据库的
TBLS表里可以查看内部表t_score对应的记录 -
先进入
mysql,更改数据库,执行命令:use metastore;

-
然后查看内部表对应的记录,执行命令:
select TBL_ID,DB_ID,TBL_NAME,TBL_TYPE from TBLS;

-
加载成绩数据文件到内部表
t_score,执行命令:load data inpath '/hivescore/input/score.txt' into table t_score;

-
查看成绩表全部记录,执行语句:
select * from t_score;

4、利用Hive SQL统计总分与平均分
- 编写Hive SQL语句,进行词频统计
- 执行命令:
SELECT name, SUM(chinese + math + english + physics + chemistry) AS total_score, AVG(chinese + math + english + physics + chemistry) AS average_score FROM t_score GROUP BY name;


- 这个SQL语句的功能是在一个名为
t_score的表中,根据学生的姓名(name)进行分组,并对每个学生各科成绩进行统计计算。 SELECT name: 选择t_score表中的name列,表示我们要按照姓名来显示结果。SUM(chinese + math + english + physics + chemistry) AS total_score: 对每个学生的语文、数学、英语、物理和化学成绩进行求和,并将这一结果命名为total_score。这将计算出每个学生的总分。AVG(chinese + math + english + physics + chemistry) AS average_score: 对每个学生的语文、数学、英语、物理和化学成绩进行求平均值,并将这一结果命名为average_score。这将计算出每个学生的平均分。FROM t_score: 指定数据来源是名为t_score的表。GROUP BY name: 根据name列进行分组,这意味着对于表中的每一条具有不同姓名的记录,都会分别进行总分和平均分的计算。- 因此,这个SQL语句的最终功能是输出一个结果集,其中包含每个学生的姓名、他们的总分以及平均分。
四、拓展练习
-
改变输出格式
SELECT CONCAT('(', name, ',', total_score, ',', average_score, ')') AS formatted_scores FROM ( SELECT name, SUM(chinese + math + english + physics + chemistry) AS total_score, AVG(chinese + math + english + physics + chemistry) AS average_score FROM t_score GROUP BY name ) subquery; -
子查询(Subquery)在SQL中是指嵌套在另一个查询语句内部的查询。它是一个独立的SELECT语句,作为外部查询的一部分(如WHERE、FROM或JOIN子句中的一个表达式),用于从数据库中检索数据来帮助定义外部查询的行为。
-
简单来说,子查询首先会执行其内部的查询逻辑,获取结果集,然后这个结果集被用作外部查询条件或者与其他表的数据进行比较、连接等操作。



华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)