Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions
当生产系统发生故障时,优先做法是迅速缓解它。尽管这很重要,但故障缓解是以被动和特定的方式进行的:只有在观察到严重症状后才采取一些固定操作。对于云系统来说,这样的策略是不充分的。在本文中,我们提出了一个预防性和适应性的故障缓解服务——Narya,它被整合在一个云生产环境,即微软Azure的计算平台中。Narya根据多层系统信号预测即将发生的主机故障,然后决定智能缓解操作**。其目的是避免虚拟机故障。

原文获取:Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions
技术文章:Advancing failure prediction and mitigation—introducing Narya
Abstract
当生产系统发生故障时,最优先的做法是去迅速缓解它。尽管这很重要,但传统的故障缓解是以被动和特定的方式进行的:只有在观察到严重症状后才采取一些固定操作。对于云系统来说,这种策略是不充分的。在本文中,我们提出了一个预防性和适应性的故障缓解服务——Narya,并将其整合在云生产环境微软Azure的计算平台中。Narya根据多层系统信号预测即将发生的主机故障,然后决定智能缓解动作。其目的是避免虚拟机故障。**Narya的决策引擎采取一种新颖的在线实验方法,不断探索最佳的缓解动作,并通过强化学习进一步增强了自适应决策能力。**目前Narya已经在生产环境中运行了15个月。与以前的静态策略相比,它平均减少了26%的虚拟机中断。
1 Introduction
一旦发生故障,如何快速检测和缓解故障,使系统能够继续运行?
缓解故障意味着尝试使故障症状消失,而不必先诊断和修复潜在的错误。而对于大型云服务设施来说,故障后的检测与缓解是无法满足的,这是因为用户体验会受到影响。更何况对于大型系统而言,故障缓解需要时间,而加速缓解甚至可能使情况恶化
因此,云系统还应该设计技术来解决以下问题:故障是否可能即将发生,如果是,应该采取什么预防措施来避免这种故障?
最近有几项工作在磁盘故障的背景下解决了故障预测的问题。但他们只关注预测问题,目的是提醒操作员或提供分配提示。而预测到底带来了多少好处,更重要的是,系统应该采取什么预防性缓解措施来应对预测的故障,这些仍然悬而未决。回答这些问题需要一个全面的解决方案,该解决方案紧密集成在系统的控制回路中,不仅实时预测主机故障,而且自动决定适当的缓解动作(action),权衡收益,并根据权衡的收益不断调整其行为。
本文提出的Narya是一种端到端服务,具有预测性的智能故障缓解功能,完全集成在Azure计算平台中,用于其虚拟机(VM)主机环境。Narya的设计目标是提前预防VM故障,增强Azure计算平台的自我管理能力,为客户提供流畅的VM体验。
静态策略:根据症状和领域知识做出解决行为。
使用静态的策略不明智:由于具有多租户、不同的基础架构组件和多样化的客户工作负载,很难预先对大型云系统中的不同故障场景进行全面分类并确定好的缓解措施(或其参数),尤其是在不尝试的情况下。而且云系统时刻在变化,一些在过去十分有效的缓解行为目前可能无法起效。
例如,最初在接收到预测故障信号时重新启动主机节点可能是有效的,因为系统故障往往是由一些暂时的硬件问题引起的;但逐渐地,永久性节点故障变得更加常见,因此重启不再是最佳缓解措施,而将虚拟机从预测会发生故障的节点实时迁移到健康节点可能是更好的措施.
在一个复杂多变的系统中,采取一些缓解动作的效果往往是概率性的,因为有太多无法完全评估的影响因素(如网络状况、虚拟机大小、应用程序、硬件状态、用户活动等)。我们通常不会事先知道某种缓解动作是否好,或者是否有更好的动作,除非我们去尝试它。因此,在确定(近似)最佳的故障缓解动作时,对生产工作负载的探索是必不可少的。不过我们应该确保所采取的动作随着时间的推移能最大限度地提高预期效果(即最大限度地减少潜在的用户影响)。
基于此见解,Narya采取了一种新颖的在线实验方法。具体来说,Narya预测生产机群中的主机节点是否可能失效,然后利用A/B测试来不断试验不同的缓解动作,衡量效益,并发现最佳行动。A/B测试策略背后的原理是,它在本质上引入了随机化,避免了不同节点的偏向性,这有助于发现具有统计学意义的有效动作。A/B测试缺点是:是在找到统计学意义之前探索每个动作需要有消耗,然后总是选择估计出的最佳动作。
这是一个exploration-exploitation权衡问题。
学习智能体是否应该重复迄今运作良好的缓解动作,即
exploit,还是应该尝试一些新的选择,以期获得更好的奖励,即explore。
而我们通过以下方法增强Narya的决策引擎:multi-armed Bandit模型。
本文的主要贡献有:
- 提出了一个全面的故障避免解决方案,包括故障预测、新的故障缓解动作和智能缓解策略。
- 设计了一种新的方法,使用A/B测试进行生产工作负载的在线实验,以自动识别良好的故障缓解动作。
- 探索了一种更高级的强化学习方法,以优化缓解动作的选择。
- 在大规模生产云服务Azure中对建议的解决方案进行了评估,以验证其有效性。
2 Background and Motivation
传统的系统运维周期是:检测到故障;开发人员诊断故障并找出根本原因;编写补丁;重新部署系统。对于云系统,以这种精确的顺序运行是有问题的,因为确定根本原因和开发修复程序所需的时间通常很长,会超过预算。一旦检测到故障,应当首先应用一些缓解动作,如重启,而不一定要知道错误原因。
2.1 Target System and Goal
我们的特定目标系统是Azure计算平台中的VM主机环境,即节点。
我们的目标是进一步开发预测主机环境是否会很快出现故障的技术,并在多种选择中自动决定适当的缓解策略,最终目标是避免未来的VM故障事件
2.2 Are Failures Predictable?
要预测故障,有两个基本要求:(Ⅰ)即将发生的故障不是突然发生的;(Ⅱ)有遥测记录以指示退化。
一种可预见的硬件问题是某些硬件部件磨损。我们可以用年龄或磨损率来预测。结合其他系统信号(如工作负载模式),我们可以预测主机是否会很快出现故障。
资源泄漏,包括内存/文件柄/网络端口泄漏,是一种常见的可预测的软件故障类型。我们可以利用资源使用趋势来预测它们。如果失败与某些隐藏因素相关,例如超时设置、与计时器相关的错误和发布计划,则它们也可能在可预测的基础上发生。
2.3 Why Reacting on Predicted Failure?
对于云服务,如果预测到了失败而不去恢复,会使客户的虚拟机收到中断的危险,影响客户使用体验。
下表中举例说明了:如果预测到某个节点较有可能发生故障,但是没有去实施预防措施,会造成较为严重的后果。

2.4 Why Static Mitigation Is Insufficient?
对于传统的静态策略,所有预测的坏节点都将使用相同的缓解策略:
- 阻塞节点上的资源分配。
- 尝试实时迁移虚拟机。
- 等待7天后,短命的虚拟机就会被客户销毁。
- 强制迁移剩余的虚拟机。
- 将节点标记为脱机并将送去修复。
尽管这一计划看起来合理,但它很快就面临限制。阻塞分配会导致容量压力,而对于一些预测的故障,避免分配可能会更好。有些故障可能太严重,无法执行实时迁移(例如,磁盘损坏)。如果节点在7天后仍然运行正常,则强制迁移会对客户造成不必要的影响。当容量较低时,将节点标记为离线也是次优的。
使用静态分配使我们无法知道如果我们选择了不同的动作会发生什么,从而无法知道我们优化了多少用户体验,以及无从得知我们是否使用了最佳动作。还有,静态缓解会受到系统变化的影响,之前起效的方法在系统变化后可能就无法生效。
使用静态分配使我们无法知道如果我们选择了不同的动作会发生什么,从而无法知道我们节省了多少客户的痛苦,或者我们是否使用了最佳动作。
静态故障缓解的另一个限制是,它导致开发人员倾向于根据一些孤立的情况对缓解分配进行特别修改。
3 Overview
我们设计了Narya,这是一个集成在Azure计算平台中的端到端服务,用于预测主机故障,并自动决定对每个预测的故障采取什么缓解措施。Narya的设计目标是避免潜在的VM故障,同时将对客户的影响降至最低。Narya以两种方式推进了当前的故障缓解实践:(i)将现有的静态特定的缓解任务替换为自适应和系统化的决策算法;以及(ii)将传统的被动的、故障后的缓解活动转变为主动故障避免机制。
3.1 Narya Workflow
Narya采用了一种新颖的在线实验和学习方法来解决故障缓解问题。图1显示了Narya中的高级工作流概述。

① Azure中的每个节点都部署有监控代理收集有关主机环境的各种遥测信号。
② Narya中的预测组件持续使用这些信号,并预测某些节点是否很快会发生故障。预测基于两种方法:
2.a 使用不变的领域规则。
2.b 运行机器学习接口。
③ 每个预测结果都作为缓解请求流进入Narya中的决策组件。决策基于两种策略:
3.a A/B测试
3.b Bandit模型
④ 决策组件计算可用缓解动作选择的概率分布然后根据分布情况选择缓解动作。
⑤ 缓解控制器将所选择的缓解动作应用于可疑节点。
整个过程是一个自动反馈循环,可优化关键目标指标——虚拟机中断率。
⑥ Narya观察到缓解动作的影响。
⑦ 根据⑥的观测更新预测和决策组件。
3.2 Key Optimization Metric
在Azure中,我们重点关注的指标为Annual Interruption Rate(AIR),定义如下:
A
I
R
=
VM interruption count in
T
Total VM lifetime in
T
×
365
days
×
100
VMs
AIR=\frac{\text{VM interruption count in }T}{\text{Total VM lifetime in }T}\times 365 \text{ days}\times 100\text{ VMs}
AIR=Total VM lifetime in TVM interruption count in T×365 days×100 VMs
T是任何给定的测量间隔持续时间,以天为单位。本文中的VM中断主要是指重启或丢失心跳。
3.3 Challenges
我们遇到了一些设计挑战:
- 首先,由于根本原因未知,故障缓解必须在信息不完整的情况下采取动作。对于Narya来说,由于失败尚未发生,这一挑战更加紧迫。
- 其次,由于云系统的规模庞大,决策逻辑中需要考虑的因素很多。Narya必须足够强大,同时具有灵活性。
- 第三,经验表明,在将故障预测整合到生产云系统中时,由于复杂的系统环境、大量的噪声信号、意外的客户工作负载等,误报是不可避免的。在使用预测结果时,缓解机制应考虑到这一点,并以将不可避免的误报造成的影响降至最低的方式运行。
- 最后,故障缓解是一个任务关键型过程。如果设计不当,决策引擎可能弊大于利。确保安全应该是Narya的首要任务。
4 Predicting Node Failures
4.1 Input Signals
- Narya利用来自主机环境的整个堆栈的遥测信号,以进行预测。**对于硬件和固件,监控代理从磁盘SMART属性、内存(例如,无法纠正的错误)、CPU(例如,机器检查错误)、主板(例如,总线错误)等收集低级别的日志。更高层次的信号来自设备驱动程序,例如,超时事件。**这类事件的重复发生往往是即将发生故障的一个指标。
- Narya进一步利用关键的操作系统事件和聚合应用性能计数器。
- 预测器使用的另一个重要信号来源是控制面操作的结果。例如,重复的虚拟机创建动作错误可能表明严重的主机问题,即使主机看起来仍然在运行。
4.2 Rule-based Prediction
基于规则的预测利用了来自硬件、固件和软件专家的领域知识。我们分析常见的故障模式和可用的遥测信号,以预测对客户有重大影响的故障。例如,在某些情况下,CPU内部错误(IERR)是节点很快将再次出现故障的良好指示器;如果IERR在30天内出现两次,则预测规则可以标记该节点。规则通常编写为Json文件、Python脚本,有时也编写为C++。由于规则是手动编写的,因此它们简单易懂。预测规则直接部署在主机中,可以快速执行。我们总共使用了51条规则。
4.3 Learning-based Prediction
先前的工作使用有监督的学习来预测磁盘故障和节点故障。我们基于学习的预测与先前的解决方案一致。主要区别在于,我们专注于整体的主机健康和导致客户影响的故障,而不是单个组件的故障。正因为如此,Narya跨层分析了更多不同的信号,例如控制平面操作信号。
Prediction Horizon and Label
为了得到准确和有用的预测结果,我们只使用导致客户影响并且后来在诊断过程中确认是由一些硬件组件故障引起的主机故障。
对于一个给定的主机故障,如果它发生在时间t,我们为从 t − 1 t - 1 t−1到 t − n t - n t−n的信号分配正(故障)标签,其中 n n n是预测范围, h h h为单位。我们为 t − ( n + 1 ) t - (n + 1) t−(n+1)的信号分配负的(正常)标签。

在生产环境中,我们的预测期设置为7天。
Machine Learning Model
Narya使用信号、标签和主机元数据训练二元分类器,预测器输出主机的故障概率(我们使用0.5作为分界值)。
为了训练分类器,我们使用监督学习中常用的梯度提升树模型(gradient boosted tree model),它将来自一系列简单决策树的决策与称为梯度上升的模型集成技术相结合。
我们进一步探索了通过使用基于注意力的深度学习模型(attention-based deep learning model)直接学习特征来减少特征工程的工作量。在高层次上,我们的目标是学习空间特征和时间特征。
- 空间特征将一个组件与其相邻组件进行比较。例如,一台主机通常在RAID0下配置了多个磁盘,因此它们的性能应该是相似的。如果一个磁盘的性能比其相邻磁盘差,则可能表示即将发生主机故障。基于注意力的深度模型旨在捕捉这种模式,以便将更多的权重(注意力)分配给异常的邻居。
- 而时间特征表征了组件随时间的变化。
图3显示了该模型的结构。总体而言,该模型比具有手工特征的决策树模型实现了5-10%的改进。

5 Mitigation Actions
当一个主机被预测会失效时,Narya会在几种可能的动作中进行选择。表2列出了Azure中的主要基本动作。减轻故障通常需要多个原语动作。Narya缓解引擎专注于探索预先定义的复合动作(表2)。

Live Migration
将一个正在运行的虚拟机以最小的中断从一个主机移动到另一个主机。迁移过程包括虚拟机的内存、处理器和虚拟设备状态的迁移。并不是所有vm都有资格进行LM, LM可能因为各种原因而失败。
VM Preserving Soft Reboot
可在主机操作系统重启后保留 VM 状态。主机操作系统内核被重新加载到内存中,虚拟机的内存和设备状态被持久化到新加载的内核中。重新加载的内核启动后,持久化状态将被恢复,而先前内核中的其余状态将被丢弃。恢复后的虚拟机短暂暂停,类似于Live Migration。
Service Healing
用于恢复不健康或故障虚拟机的服务可用性。服务修复适用于更一般的场景。虚拟机将被关机或断开网络。控制器为虚拟机生成新的分配给健康节点。在这个过程中,会有一些中断。
Mark Unallocatable
在一段时间 T T T(默认为7天)内,禁止向主机分配新虚拟机。
在 U A − L M − H I UA-LM-HI UA−LM−HI模式下,控制器在标记主机不可分配后,尝试将该主机上的虚拟机热迁移到其他主机上。在所有虚拟机被客户迁移或销毁后,或该主机发生故障后,该主机将被送往诊断。如果在不可分配周期 T T T的末尾,一些VM仍然在运行(例如,因为它们不符合LM的条件),我们会在将主机推入诊断之前对它们进行服务治疗。
U A − L M − R H UA-LM-RH UA−LM−RH是 U A − L M − H I UA-LM-HI UA−LM−HI的变体,其中我们在 T T T末尾解除阻塞分配(重置节点健康状况)。
在 U A − S R UA-SR UA−SR中,控制器阻塞分配,然后尝试内核软重启操作。如果软重启成功,控制器将解除分配阻塞。否则,我们使用一种回退策略,通常是 L M − H I LM-HI LM−HI。
Avoid
通知分配器尽量避免在该主机上添加新的虚拟机。阻塞分配对容量有很大的影响因此,可以同时标记为不可分配的主机数量是有限的。避免操作提供了一个较弱的约束。主机故障的行为仍然是将其发送到诊断。在 T T T结束时,我们重置节点可用性。
NoOp
NoOp是针对预测故障的一种特殊动作,在这种动作中控制器不采取任何操作。这是衡量预测和采取操作的益处的基线。
6 Decision Logic for Adaptive Mitigation
6.1 Online Experimentation with A/B testing
选择缓解动作的一个直接方法是离线估计每个可能的动作对预测故障的影响。根据我们的经验,鉴于云系统的复杂性,如果不在生产环境中进行尝试,就很难估计动作的影响,也很难知道哪一种动作表现最好。基于此,Narya采取了一种在线实验的方法,通过大规模测试来评估不同的缓解动作。
A/B测试,又称在线实验,是前端设计中广泛使用的测试UI功能效果的方法。Narya采用A/B测试方法,并将其用于发现良好的缓解操作。在经典的A/B测试中,一个实验对应一个UI功能,一个单元对应一个用户。对于Narya来说,一个实验对应一个故障预测的缓解(例如,CPU IERR,缓慢的内存访问延迟),一个单元对应由相应预测规则/模型标记的节点的故障缓解请求。
Narya中A/B测试的工作流如下:
① 每个预测节点一相同的概率被分配给不同的动作组合。
② 在采取每个操作之后,我们在观察窗口内测量对客户的影响。
③ 我们使用假设检验来测试一个行为是否比其他行为产生的客户影响更小。
④ 一旦达到统计学特性,我们就认为这种影响最小的操作是最优的,并将其应用于所有节点
⑤ 持续监测每个节点对所使用的操作的客户影响
⑥ 如果客户影响显著增加,我们会运行新的A/B测试实验,以验证操作仍然是最优的。
Cost
我们使用观察窗口期间节点中的VM中断次数,以及在实时迁移或服务修复中将VM迁移到的节点中的VM中断数来作为cost标准。
我们目前通过限制可以同时为同一集群中的同一规则标记为不可分配的节点数来纳入这一约束。这样一来,容量就间接地影响了标记节点为不可分配的代价。
Assignment Strategy
A/B测试的一个关键点是为故障预测器标记的每个节点决定它应该进入哪个实验组。在经典的A/B测试中,每个实验单元都是随机分配的,前提是这些单元是独立且同分布的。
对于Narya,我们做了几个改变。
-
对于每个节点,通过节点ID和实验名称的散列来确定组(图4);

-
Narya允许同时进行不同的实验。有些试验是相互影响的,我们需要测试所有的动作组合。例如,对于测试动作{a,b}的实验X和测试动作{c,d}的相关实验Y,我们需要有采用以下四种场景中的每一种的观察:(a,c)、(a,d)、(b,c)、(b,d)。
Action Overriding
由于许多故障处理策略(包括我们的A/B实验)可以同时发生,因此一个主机可能会被标记为几个预测规则。因此,宿主可能需要同时执行不同的复合操作
为了处理这种情况,Narya根据表2中的顺序使用了特定的覆盖逻辑:优先级高的覆盖优先级低的,优先级相同则尊重较早的操作。
Effect Observation and Attribution
由于操作的复杂性,一些操作需要更长的时间才能触发。根据动作的复杂性,有些动作需要更长的时间才能被触发。在做出决策和动作开始之间的时间内,不相关的虚拟机中断会发生。然而,为了公平地比较动作,我们仍然应该计算这个时间间隙的代价,因为对于瞬时动作,不可能将动作造成的代价与不相关的代价区分开来。与覆盖一样,我们监测的是决策而不是动作,因此我们用决策时间而不是动作时间作为观察窗口的开始。
如果我们使用实际的动作时间,我们将忽略UA-SH-HI组中不相关的重启,NoOp组中不会忽略,尽管两组中都会发生不相关重启。

Hypothesis Testing
由于我们的成本函数复杂且依赖于外部变量,因此我们假设每个节点的VM重启次数是独立同分布并服从正态分布,从而简化了假设检验。
由于不同的操作会在很大程度上改变每个节点的VM重启,因此我们不会假定不同的操作具有相同的差异。
在这些假设下,我们使用Welch's t-test来测试两个操作,使用Welch ANOVA来测试三个或更多的操作。在后者中,我们使用事后分析来删除所有统计学上较差的操作,直到剩下一个操作。
6.2 Bandit Modeling
A/B测试的一个缺点是它的静态组分配。在统计学意义之前,我们不会利用各组之间的估计差异来最小化我们的成本,而一旦实验达到统计学意义,我们几乎总是会使用发现的最佳动作。这实质上是典型的 e x p l o r a t i o n − e x p l o i t a t i o n exploration-exploitation exploration−exploitation困境。
M u l t i − A r m e d B a n d i t s Multi-Armed Bandits Multi−ArmedBandits 问题:目标是通过确保在探索潜在的更好的动作和利用发现的最佳动作之间的保持平衡,使对客户的影响随着时间的推移最小化。
在训练时,我们观察元组(node, rule, chosen action, cost)来估计选择每个动作的概率;而在服务时间,我们将请求元组(节点、规则)与学习的动作进行匹配。
Actions
Bandit模型的输出是我们要尝试的复合动作。每个实验通常基于对预测信号特性的离线分析来定义可用动作:假阳性率、故障/影响时间和动作可行性。
Exploration Algorithm
我们需要在短期和长期利益之间取得平衡。我们试验了多种不同的探索模型,包括Epsilon贪婪模型和UCB模型,并决定使用Thompson Sampling模型,因为它提供了更好的解释能力和连续的概率变化。
在Thompson Sampling模型中,我们将reward建模为动作和模型参数的函数,并根据最大化预期奖励的概率来选择动作。该贝叶斯方法使用所采取的动作的观察结果来更新先验,并以等于其最小预期代价的概率来选择每个动作:
P
(
a
∗
)
=
∫
I
(
E
(
c
∣
a
∗
,
θ
)
=
m
i
n
a
E
(
c
∣
a
∗
,
θ
)
)
P
(
θ
∣
o
b
s
)
d
θ
P(a*)=\int I(E(c|a*,\theta)=min_aE(c|a*,\theta))P(\theta|obs)d\theta
P(a∗)=∫I(E(c∣a∗,θ)=minaE(c∣a∗,θ))P(θ∣obs)dθ
其中
P
(
a
∗
)
P(a*)
P(a∗)是选择动作
a
∗
a*
a∗的概率,
θ
θ
θ是隐藏参数,
c
c
c是代价,
o
b
s
obs
obs是作为元组列表
(
a
i
,
c
i
)
(a_i,c_i)
(ai,ci)的过往观测。
6.3 Extension to Bandits
与传统的Bandits方法不同,我们做了如下四方面的改变:
Accommodate Temporal Changes
我们使用指数衰减权重来将重点放在最近的数据。对过去的观察结果应用乘法权重,格式如下:
衰变
=
σ
T
−
T
o
b
s
衰变=\sigma^{T-T_{obs}}
衰变=σT−Tobs
其中
σ
σ
σ是衰减因子,
T
T
T是当前时间,
T
o
b
s
T_{obs}
Tobs是观测时间。
σ默认设置为0.99,3个月后权重将接近0。
伽玛先验下的Thompson Sampling演变为:
P
(
θ
∣
a
,
o
b
s
)
∼
Γ
(
1
+
∑
i
,
a
i
=
a
c
i
σ
T
−
T
i
,
1
+
∑
i
,
a
i
=
a
σ
T
−
T
i
)
P(\theta|a,obs)\sim\Gamma(1+\sum_{i,a_i=a}c_i\sigma^{T-T_i},1+\sum_{i,a_i=a}\sigma^{T-T_i})
P(θ∣a,obs)∼Γ(1+i,ai=a∑ciσT−Ti,1+i,ai=a∑σT−Ti)
Delayed Reward Collection
在我们的环境中,一个关键的挑战是所采取的动作和其影响之间可能存在很长的时间。这迫使我们至少观察10天,最多30天,观察选择每一项动作的影响。
而观察窗口高度依赖于动作的持续时间及其效果:7天的 U A − L M − H I UA-LM-HI UA−LM−HI将需要大约10天,而15天的 A v o i d − R H Avoid-RH Avoid−RH将需要整整30天来观察健康重置后的潜在故障。长观察窗口的缺点是将reward整合到模型中会有延迟。因此,在观察到的cost可以重新调整概率之前,可能会使用错误的估计一段时间。抵消这种影响的一种方法是观察奖励的到来,但我们可能会受到相反的影响,即在临近决定的时候重新启动,从而产生偏移。我们的经验表明,我们需要等待完整的初始观察窗口,然后才能逐步获得部分reward。
Bandit stickiness
由于选择每个操作的概率会随着时间的推移而变化,因此我们不能依赖A/B测试中的散列函数来确保始终将节点分配给相同的操作。我们将时间 T T T的 Bandit stickiness \text{Bandit stickiness} Bandit stickiness定义为如果节点在 T T T时间窗口内具有相同规则的可用决策则重复使用之前选择的复合动作。
Deal with Unexpected Spikes
我们系统中的另一个潜在问题是虚拟机中断事件的意外高峰,这可能会对一个动作组产生比另一个动作组更大的影响。我们用下面描述的Safe Guard机制来解决这个问题。
6.4 Safe Guards
在Narya缓解决策逻辑中,安全是重中之重。
除了action override(第6.1节)之外,我们还应用safety constraints——特定于域的限制来禁止某些故障场景中的某些操作。Narya Decision Engine还要求在遵循Bandit的建议之前进行最低数量的观察。Bandit模型将为不充分的观察输出一个过早的标志,在这种情况下,我们将退回到类似于A/B测试的默认操作概率。这也有助于在更大的观察组中冲淡高峰的潜在影响。
此外,我们支持为每个动作概率配置最小和最大约束。最大约束限制了对high cost的可能反应,而最小约束保证了对在特定时间看起来不相关的动作的一些探索。
在实验上,我们发现,当每天标记的节点少于100时,使用10%的探测,当它更高时,使用5%的探测可以产生最好的结果。
7 Narya System Design and Implementation
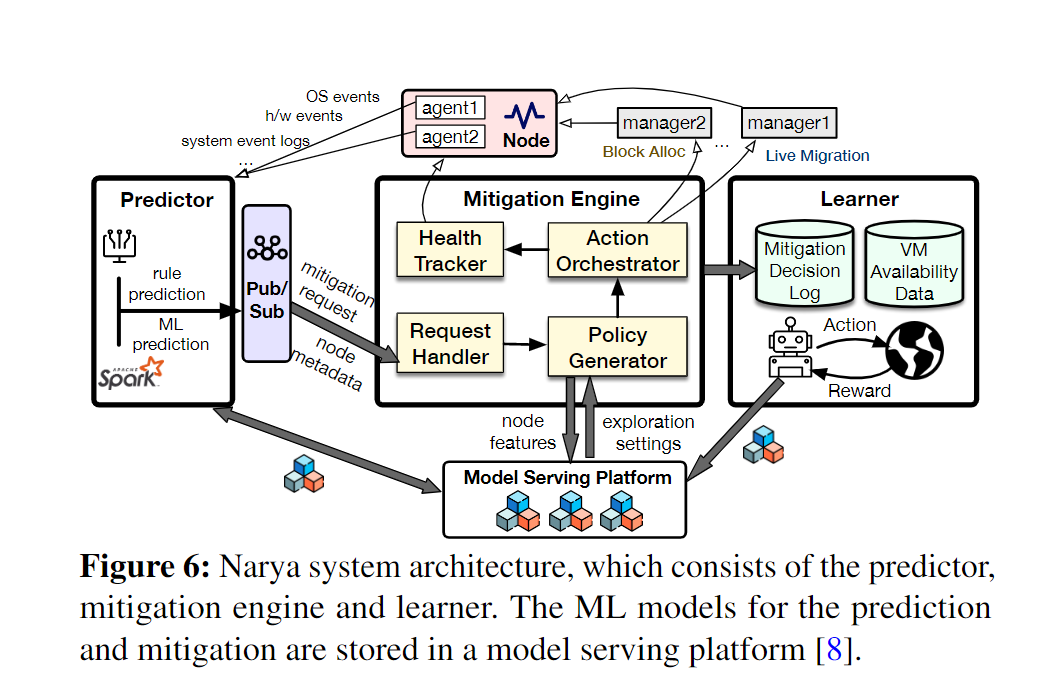
在本节中,我们将介绍对Narya的系统支持。下图是Narya的系统架构。

7.1 Failure Predictor
Azure在每个节点中部署各种代理,以监控主机环境的运行状况。Narya预测器从这些监控代理获取信号,并运行基于规则的预测和基于ML的预测。
基于规则的预测具有成本低、优先级高的特点。因此,其预测逻辑直接在主机中执行。基于ML的预测检查更多的信号,如性能计数器,并运行更复杂的预测逻辑。因此,ML预测器被实现为集中式服务。
LightGBM用于决策树模型,PyTorch用于深度学习模型。ML推理任务以小时级Spark作业的形式运行,该作业读取最新的信号和经过训练的ML模型,以计算每个主机的故障概率。
Pub/Sub Service
如果预测节点以很高的概率发生故障,则创建
mitigation request
\text{mitigation request}
mitigation request。预测器将请求与关于主机的元数据信息(例如,硬件代数、操作系统版本)一起发布到我们在Kafka之上实现的中央发布/订阅服务。我们选择Kafka是因为它允许可扩展、低延迟和实时的流处理来快速交付
mitigation request
\text{mitigation request}
mitigation request。
7.2 Mitigation Engine
缓解引擎是Narya的核心部件。在内部,它由四大微服务组成。这些微服务使用REST API相互通信,并与Azure中的其他服务进行通信
Create Mitigation Job
请求处理程序微服务使用来自发布/订阅服务的 mitigation request \text{mitigation request} mitigation request。收到 mitigation request \text{mitigation request} mitigation request后,它会创建具有作业ID的缓解作业。其他微服务使用此作业ID来跟踪缓解并查询其进度
Instantiate Mitigation Policy
对于新的缓解作业,策略生成器创建缓解策略,该策略将请求中的信息映射到要采取的操作。它被表示为决策树。有两种类型的树节点:选择节点,它根据某个C#谓词选择下一个要访问的树节点;操作节点,它执行用户定义的C#函数。
决策树结构允许我们轻松地指定决策逻辑。例如,我们可以基于故障类型(软件或硬件)、故障代码(例如,Req.FaultCode==0x123)、集群类型(存储或计算)、hardware generations(例如,HostNode.Gen!="ABC")等来决定缓解措施。图7示出了示例。

策略源自模板(Json配置文件)。对于A/B测试,动作分布在模板中指定。对于Bandit,动作树节点根据上下文信息动态生成。特别地,它调用了一个ML模型服务平台Resource Central,该平台具有诸如故障代码、VM计数等相关特性。该平台返回一个exploration setting——缓解动作的概率分布。然后,策略生成器对检索到的exploration setting应用安全约束,以获得调整后的动作概率分布。此外,缓解策略允许对树节点施加速率限制,以避免过度缓解可能导致容量问题或级联故障。
Walk Policy Tree
策略生成器进一步按DFS顺序遍历策略树,并创建一个action plan。在这个过程中,生成器执行了许多步骤,如检查谓词、检查速率限制条件等。如果一个节点被输入,生成器首先检查我们是否需要应用粘性缓解动作(第6.1节),以及是否在一定时间内对同一实验和树节点做出过决策。在这种情况下,最后的缓解动作会从分布式存储服务中检索出来。
否则,如果在A/B测试模式下,将根据配置的概率分布抽出一个动作,如果在老虎机模式下,将从资源中心抽出一个动作。如果在老虎机模式下没有足够的数据,就会返回一个特定的标志,表明老虎机模式是不成熟的。然后,生成器会退回到使用A/B测试模式的动作概率。这使我们能够安全地从A/B测试中引导老虎机学习,特别是考虑到反馈回路中的延迟成本。如果在调用模型服务平台时有任何错误,我们也遵循同样的回退策略。
Carry out Action Plan
Action Orchestrator微服务负责从策略树遍历会话中执行动作计划。这一步涉及到对相应的计算管理器进行API调用,因为不同的动作可能由不同的管理器实现。协调器异步执行操作以避免阻塞
Log Actions
日志对于数据分析、Bandit训练和不同缓解策略的反事实评估都非常重要
Track Node Health
Health Tracker跟踪缓解过程中的节点和虚拟机运行状况信息。例如,在重新启动一个节点时,如果我们得到一个新的信号(例如,一个WindowsEvent),这是一个硬件问题,那么我们可以提前 H I HI HI该节点,而不是等待重新启动失败/超时。
7.3 Learner
Learner是Narya的一个集中组件。它了解不同数据中心区域的缓解操作的效果。与区域化的Learner设计相比,全局Learner的优点是可以观察到更多的数据点,因此在成本估算中更可信。此外,软件/固件更新而导致的某些区域的缓解效果变化也可以快速获悉,并应用到具有相同更新的其他区域。
Learner主要负责两项工作:cost收集和Bandit模型训练。
- cost收集作业从日志中检索缓解引擎的决策。然后将此信息与VM可用性度量和其他重要信息(LM状态、VM工作负载等)相关联,以确定用于训练的缓解操作的成本。的
- Bandit模型训练在Spark集群上运行。
学习者的输出模型是一个分类分布,模型服务器可以很容易地从中提取样本。
8 Evaluation
我们的评估回答了几个问题:
- Narya在避免虚拟机中断方面有多有效?
- 故障预测的准确性和及时性如何?
- Bandit模型与A/B测试相比如何?
8.1 VM Interruption Savings
计算了三个指标:the estimated daily AIR savings—— S ^ \hat S S^,the oracle daily AIR savings(已知最佳操作)—— S ∗ S^{*} S∗,the regret(额外节约的AIR)。
经过评估,2020年3月, S ^ \hat S S^改善了26.2%——Narya成功比静态策略减少约26.2%的AIR。

尽管考虑到Azure的规模,26%看起来并不大,但它代表了大量VM重启,每一次都对客户产生了巨大影响。有了针对更多故障类型和新操作的新预测规则,Narya可能会带来进一步的改进。
8.2 Savings Trend Over Time
图9显示了随着时间的推移AIR的改进。总的来说,节省在20%到40%之间波动。7月份出现了突然上升。这是因为在6月至7月期间发生了一次主要的固件修复。该固件部署修复了一个驱动程序问题,我们通过提前预测故障减少了很多AIR。

8.3 Accuracy and Timeliness of Prediction
总体准确率为79.49%,总体召回率为50.7%,假阳性率为20.51%
我们进一步评估了不同信号(特征)对预测准确率的贡献。我们使用SHAP方法计算特征的重要性,根据它们的重要性对特征进行排序,并将它们分组到10个bin中。然后,我们使用单个容器或聚合容器评估精度和召回率。图10显示了结果。我们可以看到一些特性比其他的更重要。第一个bin(包含read error rate, flush count, AvailableSpare, HostReadCommands)的作用尤其显著。

除了精度和召回率,对Narya来说,重要的是要考虑预测前置时间(或故障时间),定义为预测时间和故障时间之间的间隔。更长的前置时间使Narya有更多的时间采取预防措施。图11显示了ML预测时间到故障的CDF(累计分布函数),前置时间的中位数为2.44天。图12比较了基于ML的预测和基于规则的预测的时效性:基于ml的预测在时效性方面具有显著优势。

我们衡量早期预测对实时迁移成功的量化效益。对于预测为失败的节点,每个节点的平均活体实时成功率为5.57。随着前置时间的缩短,每个节点的实时迁移成功率下降到了3。
8.4 Comparing AB Testing and Bandit
在2020年2月和3月的2个月期间,使用Bandit而不是A/B测试进行正在进行的实验,可以帮助减少14.4%的VM中断数量。与Bandit测试相比,A/B测试更安全,并且允许使用多种cost metirc。

8.5 Convergence to Optimal Action
表3给出了不同实验A/B测试的收敛时间。不收敛通常表示实验动作之间没有显著差异。

Bandit可以实现更快的收敛到最好的动作。图14显示了结果。Bandit收敛约50步,而AB测试收敛需要125步。更快的收敛也能节省更多的AIR。如图15所示,Bandit测试产生的重启比AB测试少得多。

8.6 Case Studies
Blobcache error是一种症状,可能是由硬件问题或一些可恢复的故障引起的。
E11是指示磁盘控制器错误的Windows事件。当此事件发生时,通常意味着硬盘正在经历一些问题,极有可能表明即将发生故障。
8.7 Reward Collection Schemes
我们比较了三种可能的reward收集方案:
(a) 延迟式奖励收集。
(b) 立即式奖励收集。
© 递增式奖励收集。
reward奖励收集(§6.3)是我们的默认方案。在(b)中,我们将虚拟机的中断cost与当天完成的动作联系起来,并更新Bandit模型。在(c)中,我们每天更新并关联cost。
在我们进行的不同的A/B测试实验中,(b)平均提高了7.12%的AIR,而(a)平均提高了8.50%的AIR。这是因为即时reward收集很容易受到噪音的影响。图17说明了一个实验中的比较。

在我们的实验中,增量方案的性能略差于延迟方案,AIR提高了8.45%。一个原因是,如果环境相对稳定,增加部分观测并不能提供太多新信息
8.8 Safe Guards
安全防护程序可以在许多方面影响系统。首先,它允许不断探索所有动作,以便及时适应系统变化;其次,它防止过早地向错误的政策靠拢;第三,Safe Guards降低了意外峰值的影响。
8.9 Scale and Performance
Narya在Azure的每个数据中心区域运行。缓解引擎每天处理数百到数千的请求。故障预测器每天处理数十个TB的信号。图18a显示了每天缓解请求会话的数量(包括所有故障处理),以及通过我们的A/B测试实验的请求和由我们的Bandit模型处理的请求的数量。图18b显示了缓解动作会话持续时间的CDF。

11. Conclusion
们在云基础设施的背景下研究容错系统设计中的一个重要主题——故障避免。根据我们在运行大型生产云系统方面的经验,我们提出了一种新的在线实验和学习方法来解决这个问题。我们介绍了Narya,一个端到端服务,包括故障预测和智能缓解。Narya使用A/B测试和Bandit模型持续评估生产环境下中的最佳缓解动作。Narya已经在Azure计算基础设施中运行了15个月,与之前的静态策略相比,在减少虚拟机中断方面产生了26%的改进。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)