在颠覆性技术时代的信用卡欺诈检测:系统性综述 Credit card fraud detection in the era of disruptive technologies: A systemat
随着创新技术和通信方法的出现,如非接触支付,信用卡欺诈正变得日益严重且普遍。本文对2015年至2021年间进行的有关检测和预测信用卡欺诈交易的前沿研究进行了深入审查。我们选择了40篇相关文章,并根据涉及的主题(类别不平衡问题、特征工程等)和使用的机器学习技术(建模传统和深度学习)对其进行了分类。我们的研究显示,迄今对深度学习的调查有限,揭示了需要更多研究来解决通过新技术(如大数据分析、大规模机器学
文章目录
论文名称:Credit card fraud detection in the era of disruptive technologies: A systematic review
文章信息
关键词:
信用卡欺诈检测
机器学习
深度学习
类别不平衡
摘要
随着创新技术和通信方法的出现,如非接触支付,信用卡欺诈正变得日益严重且普遍。本文对2015年至2021年间进行的有关检测和预测信用卡欺诈交易的前沿研究进行了深入审查。我们选择了40篇相关文章,并根据涉及的主题(类别不平衡问题、特征工程等)和使用的机器学习技术(建模传统和深度学习)对其进行了分类。我们的研究显示,迄今对深度学习的调查有限,揭示了需要更多研究来解决通过新技术(如大数据分析、大规模机器学习和云计算)检测信用卡欺诈所面临的挑战。通过提出当前的研究问题并强调未来的研究方向,我们的研究为指导学术和工业研究人员评估金融欺诈检测系统和设计稳健解决方案提供了有用的参考。
https://doi.org/10.1016/j.jksuci.2022.11.008
1. 引言
1.1. 动机
随着 COVID-19 大流行,数字商务已经开始取代现金支付。信用卡支付正在成为全球经济中当代数字商务的主要代表。
包括发卡机构、银行、支付处理商和商家在内的不同利益相关者不断寻求利用多种技术进步,以更好地满足他们最终用户的偏好。新技术为创新的支付解决方案铺平了道路。物联网设备的丰富和改进的连接性、应用内支付和移动设备的普及正在促进信用卡支付系统的发展和颠覆。例如,许多公司如 Amazon Go 目前正在尝试基于生物识别的支付。通过标记化(Liu 等,2020),移动物联网设备如智能手表用于与附近系统交换信息以进行即时支付,从而产生了执行交易的新通信模型。
信用卡在网上银行业务中很受欢迎,在在线交易和电子商务中被广泛使用。然而,信用卡的演变和扩展导致了多种形式的欺诈的出现。欺诈分子正在使用越来越复杂的方法进行非法交易,导致持卡人和银行遭受重大损失。从盗窃、钓鱼信用卡信息到制作仿真卡以模仿合法用户行为,今天的欺诈分子可以比以往更轻松地进行欺诈交易。
同时,数据的规范化和神经网络的广泛使用使得人工智能(AI)和深度学习技术对发卡机构和银行服务至关重要。如今,AI 正在为设计新方法铺平道路,以更好地处理下一代信用卡欺诈检测,支持提高批准率、最小化拒绝交易,并实现对信用额度的主动监控。然而,在导航智能银行交易处理时存在许多挑战,包括需要解决的客户行为变化,以维护合法操作。由于这些转变和挑战,银行和支付处理商正在快速现代化其支付技术,这可能会带来安全问题。
因此,建立健壮且最新的信用卡欺诈检测系统至关重要。信用卡欺诈检测有助于通过将传入交易分类为合法和非法交易来识别可疑交易。信用卡欺诈可能采取在线和离线两种形式。在在线欺诈的情况下,欺诈分子进行涉及在线购买的欺诈交易;而在离线欺诈中,他们使用被盗的信用卡进行恶意交易。
许多研究作品已经解决了信用卡欺诈问题。因此,分析他们报告的解决方案以为该领域的研究人员提供路线图至关重要。尽管之前有过一些调查(见第 2 节),但最近提出了许多新方法,需要进行分析。此外,现有的调查主要集中在检测模型,而不是利用新技术和计算方法。因此,我们的研究提供了一项全面的调查,考虑了信用卡欺诈检测的几个方面,重点关注深度学习方法和颠覆性技术。
1.2. 贡献
我们的研究工作提供了一项关于信用卡检测的全面调查,重点是利用最新进展和新技术,不仅涵盖机器学习算法,还包括最近进展的整合,如大数据技术、类别不平衡问题和检测的实时方面。我们还旨在审查 2020 年至 2021 年间发表的最新研究,为未来研究人员提供相关指导,因为过去两年间涌现了大量新解决方案。
本调查的贡献有三个方面:
- 分析最近进行的研究,以解决信用卡欺诈检测问题,从三个角度:(i)使用的机器学习方法及其解决检测问题的有效性,(ii)类别不平衡问题以及文献中如何解决它,以及(iii)特征工程问题。
- 深入审查最新解决方案的实施和测试。讨论并分析了该领域中使用的主要指标,根据其相关性进行分析。
- 全面介绍研究挑战以及可能的研究方向,帮助研究人员和开发人员提供更强大和最新的解决方案,以应对信用卡欺诈检测问题。
1.3. 论文结构
本文的其余部分组织如下。第 2 节解释了进行此审查时的方法论。第 3 节介绍了研究背景。第 4 节展示了基于传统机器学习的提出作品,而第 5 节浏览了基于深度学习的解决方案。第 6 节强调了类别不平衡问题,并总结了用于信用卡欺诈检测的最新技术。第 7 节详细介绍了与信用卡欺诈问题相关的测试指标。它还展示了文献中包含的不同数据集以及所审查作品取得的最佳结果。第 8 节突出了存在的问题并提出了一些研究方向。最后,第 9 节总结了本文。
表 1 显示了本文中使用的缩写。
2. 方法论
这项研究遵循了图 1 中呈现的策略。它包括三个主要阶段:研究设计、研究方法和研究输出。
2.1. 相关调查
研究人员首先搜索了该领域的调查论文,并选择了最相关的论文。这些论文根据以下标准进行了分析:
- 发表日期;
- 覆盖范围;
- 讨论的主题。
虽然已经提出了许多调查,调查智能信用卡欺诈检测系统,但其中大多数要么范围广泛,涵盖商业领域的许多其他领域,从而分散了研究人员,要么在该领域的一个子领域中范围非常有限(短调查、监督方法或深度学习方法)。此外,一些论文仅描述了最新解决方案,而没有对所涵盖文献的优缺点进行深入分析。
Al-Hashedi 和 Magalingam(2021)的工作涵盖了从 2009 年至 2019 年的金融欺诈研究论文。它主要讨论基于数据挖掘技术的作品,并根据多种因素对文献进行分类,包括发表年份、出版商、使用的方法和研究领域(信用卡欺诈、加密货币欺诈、保险、金融)。这是一项关于检测金融欺诈、信用卡欺诈、保险欺诈和其他类型欺诈的研究的全面回顾。描述了用于检测金融欺诈的数据挖掘技术。还指定了数据集和验证指标。最后,在论文中指定了每种数据挖掘技术的优缺点。然而,该调查仅限于仅“分类”技术,并未描述完整的检测链,这对于了解用于检测的特征至关重要。此外,作者没有关注信用卡欺诈,并未涵盖类别不平衡问题或特征工程问题。对于新趋势如大数据也缺乏考虑。
表 1
本文中使用的缩写。
| 缩写 | 描述 |
|---|---|
| ADASYN | 自适应合成 |
| AI | 人工智能 |
| ANN | 人工神经网络 |
| AUC | 曲线下面积 |
| AUC-PR | 精确率-召回率曲线下面积 |
| AUC-ROC | 接收者操作特征曲线下面积 |
| BBE | 平衡装袋集成 |
| BMR | 贝叶斯最小风险 |
| BMR-DT | 贝叶斯最小风险决策树 |
| BMR-LR | 贝叶斯最小风险逻辑回归 |
| BMR-RF | 贝叶斯最小风险随机森林 |
| BPNN | 反向传播神经网络 |
| CNN | 卷积神经网络 |
| CNP | 不持卡人 |
| DDM | 数据驱动模型 |
| DL | 深度学习 |
| DT | 决策树 |
| DWE | 动态加权熵 |
| FDS | 欺诈检测系统 |
| FN | 假阴性 |
| FP | 假阳性 |
| FPR | 假阳性率 |
| G-mean | 几何平均 |
| GBT | 梯度提升 |
| GNB | 高斯朴素贝叶斯 |
| GRU | 门控循环单元 |
| IoT | 物联网 |
| KNN | K近邻 |
| LinR | 线性回归 |
| LOF | 局部离群因子 |
| log R \log R logR | 逻辑回归 |
| LSTM | 长短期记忆网络 |
| MCC | 马修斯相关系数 |
| ML | 机器学习 |
| MLP | 多层感知器 |
| MOPSO | 多目标粒子群优化 |
| NB | 朴素贝叶斯 |
| NN | 神经网络 |
| PCA | 主成分分析 |
| PNN | 概率神经网络 |
| R F \mathrm{RF} RF | 随机森林 |
| RNN | 循环神经网络 |
| ROC | 受试者工作特征曲线 |
| ROS | 随机过采样 |
| RUS | 随机欠采样 |
| SEPA | 单一欧洲支付区 |
| SMOTE | 合成少数过采样 |
| SVM | 支持向量机 |
| SVM-RFE | 支持向量机-递归特征消除 |
| T N \mathrm{TN} TN | 真阴性 |
| T P \mathrm{TP} TP | 真阳性 |
| TNR | 真阴性率 |
| TPR | 真阳性率 |
| WELM | 加权极限学习机 |
在Lucas和Jurgovsky(2020)中,作者考虑了数据驱动的信用卡欺诈检测面临的挑战。具体来说,他们关注了数据不平衡问题以及如何解决最先进解决方案中的演变行为问题(数据集漂移)。

图1. 研究策略。
然而,一些论文太旧,没有提供比较分析。Popat和Chaudhary(2018)是一篇简短的调查,仅讨论了七篇相关作品,基于它们的机器学习技术。然而,作者没有讨论每个被审查作品的细节。在Kanika和Singla(2020)中,作者分析了基于深度学习的在线交易欺诈检测技术。作者还提供了所使用的主要数据集和取得的结果信息。然而,该研究的范围仅限于深度学习技术。
在Mittal等人(2020)中,作者对信用卡欺诈进行了分类,并总结了被审查研究中描述的主要特征。他们还讨论了信用卡欺诈检测。提出了一些研究方向的简短名单,但缺乏更详细的细节以更好地指导研究人员。
表2显示了本研究与最近调查的比较。
在确定现有调查的局限性后,制定了以下研究目标:
- 回顾最近的研究论文;
- 调查使用深度学习技术的论文;
- 分析颠覆性技术和新方法对信用卡欺诈检测的实用性;
- 研究与信用卡欺诈检测相关的安全问题。
2.2. 论文的选择和筛选
前一步骤导致了研究关键词的定义以及选择数字图书馆以获取符合条件的研究,即Elsevier、Springer、IEEE explore、ACM等。
第二阶段确定了以下搜索标准:
- 包括2015年以后发表的作品;
- 包括与数据挖掘和人工智能领域相关的作品;
- 包括调查新技术的作品,如物联网、大数据和云计算;
- 考虑与信用卡欺诈研究相关的安全方面。
表2
与最近调查论文的比较。


图2. 根据出版商分布的论文。

图3. 根据使用技术分布的论文。

图4. 根据研究问题分布的论文。
表3
分类法。
| 主题 | 参考文献 |
|---|---|
| 检测 | (Srivastava等,2016)(Kewei等,2021)(Sudha和Akila,2021)(Fu等,2016)(Ingole等,2021)(Ali Yeşilkanat等,2020)(Mohammed等,2018)(Wang等,2018)(Padmanabhuni等,2019)(Roy等,2018)(Babu和Pratap,2020)(Rtayli和Enneya,2020)(RB和KR,2021)(Forough和Momtazi,2021)(Bagga等,2020)(Carcillo等,2021) |
| 类别不平衡 | (Benchaji等,2018)(Thennakoon等,2019)(Tran和Dang,2021)(Li等,2021)(Kim等,2019)(Dornadula和Geetha,2019)(Rtayli和Enneya,2020)(Zhu等,2020)(Ingole等,2021)(Yang等,2019)(Baabdullah等,2020)(Akila和Srinivasulu Reddy,2018)(Olowookere和Adewale,2020) |
| 特征工程 | (Thennakoon等,2019)(Lucas等,2019,2020)(Correa Bahnsen等,2016)(Zhang等,2021)(Lucas等,2020)(Cochrane等,2021)(Han等,2021)(Jurgovsky等,2018)(Sudha和Akila,2021) |
| 推荐系统 | (Cui等,2021) |
| 优化 | (Han等,2021)(Soltani Halvaiee和Akbari,2014)(Benchaji等,2021)(Zhu等,2020) |
| 实时性 | (Ali Yeşilkanat等,2020)(Soltani Halvaiee和Akbari,2014)(Thennakoon等,2019)(Zhou等,2021) |
| 大数据技术 | (Zhou等,2021)(Soltani Halvaiee和Akbari,2014) |
| 安全/隐私 | (Yang等,2021)(Yang等,2019) |
符合这些搜索标准的所有检索到的论文的标题和摘要经过筛选,排除了标记为不合格(不相关或超出研究范围)的记录。最终检索到的符合条件的全文相关文章数量为40。图2显示了根据出版商分布的保留论文。
2.3. 研究输出
对每个选定的模型进行了描述性审查,以将作品分类为综合分类法,如下图所示。图3总结了根据使用的技术分布的选定论文。
由于每篇研究论文都有一个特定的研究问题,根据领域面临的主要挑战,审查的作品也根据研究问题进行了分类,如图4所示。表3显示了根据主题分布的论文。图5显示了针对信用卡欺诈检测问题提出的最先进技术的分类法,根据研究人员调查的主题和子主题。
3. 研究背景
欺诈是为了获取金钱利益而计划的欺骗行为。电子支付方式的增加,如信用卡和借记卡,导致了信用卡欺诈的增加。移动银行的普及导致了欺诈支付交易的增加。因此,金融损失也在增加。信用卡可以在线或离线使用来购买物品。在线支付不需要卡的实际存在,因此卡数据容易受到攻击。这种欺诈也被称为非面对面(CNP)欺诈。

图5. 信用卡欺诈检测分类法。
此外,通过芯片卡的非接触式支付和通过近场通信(NFC)进行的移动设备支付的使用正在增加,因为这样可以实现更快的支付。这些支付类型在新冠疫情后变得尤为普遍。它们使用短距离无线通信技术,实现非接触支付(Vishwakarma等,2021)。与传统支付不同,NFC支付依赖于另外两个合作伙伴:手机制造商和移动运营商。这些合作伙伴的安全政策可能被电话市场操纵,而不是支付市场(Gerbaix,2010),这导致了更多的安全问题,并使客户比使用实体卡支付时更容易受到信用卡欺诈的威胁。虽然这些类型的支付允许小额支出,但骗子可以从用户行为中学习,并在客户通知银行之前进行大量交易。因此,提供强大的检测解决方案至关重要。
根据2021年发布的第七个单一欧洲支付区(SEPA)报告(Sepa报告,2022)和对2019年数据的分析,欺诈交易的总价值为18.7亿欧元,其中80%为CNP支付。相比之下,ATM和销售点终端的欺诈价值份额分别降至总欺诈价值的5%和15%(见图6)。与面对面欺诈相比,CNP欺诈近年来有所增加。因此,CNP欺诈对信用卡行业是一个非常严重的问题。
3.1. 信用卡欺诈检测系统设计
DDM使用先前训练过的历史交易数据构建分类器,或依赖另一个统计模型来检测欺诈交易。合法交易的分数被估计出来。如果分数超过一个既定的阈值,交易将被拒绝,然后转发给专家进行进一步分析。DDM通常是从一个带标签的数据集中训练出来的,并且是完全自动化的。预期DDM将检测到欺诈交易,超越调查人员的经验,这是基于规则的模块所缺乏的[^0]。
如果分类器或统计模型未能检测到欺诈交易,那么当持卡人报告时,警报将立即转发给调查人员。评分模块必须返回准确的警报,以减少误报和漏报的欺诈交易数量。这个过程如图7.(a)所示。
上述模型稍作修改,由Kim等人(2019)进行(见图7.(b))。改进主要是自动化评分模型,并将其与DDM模型组合成一个组合的数据驱动评分模型(DDSM)。新设计还强调了FDS的实时性,通过将整个过程视为实时处理,与Dal Pozzolo等人(2018)设计的将评分和DDM都作为准实时处理不同。
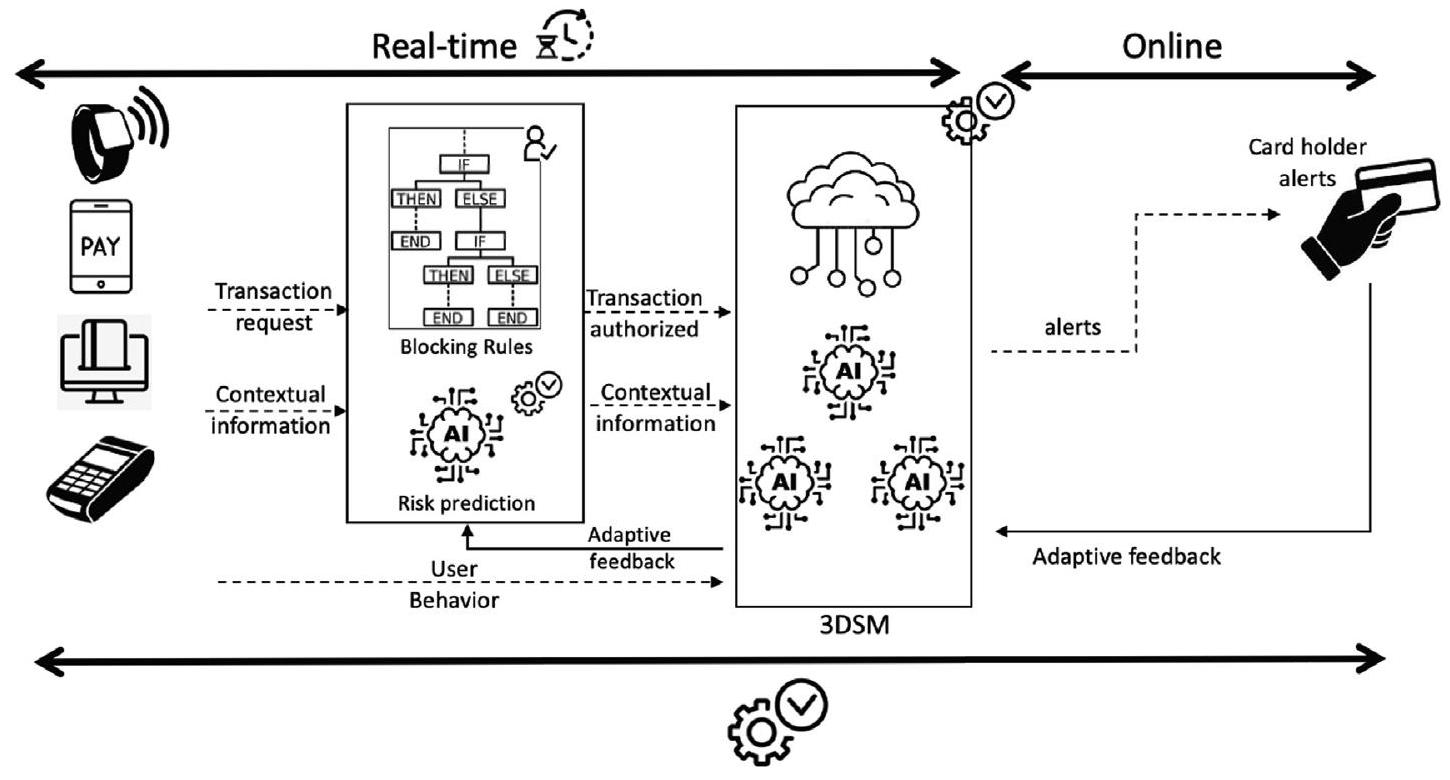
总的来说,欺诈检测问题包括一个二元分类问题。传入的交易必须被分类为欺诈或真实。然而,在实践中,一个能够量化欺诈程度的FDS更有用。由于调查可疑交易是耗时的,而调查人员数量有限,FDS需要以完全自动化和分布式的方式运作。为了实现这一点,欺诈检测系统进行了重新设计,如图8所示。建议通过智能模型来补充阻塞规则模块,以估计交易的风险。如果风险很高,交易将被拒绝。只有在风险较低且通过了所有预定义规则时,系统才会继续。这确保即使阻塞规则被验证且操作存在风险,它也将在早期被拒绝。然后,一旦风险降低到中等水平,交易将被传递给一个名为3DSM的分布式DDSM。这确保了学习模块的分布,并依赖于新技术(边缘/云计算)。应尽量减少人为干预,以供给学习系统并更新其行为。这一设计还强调了使用多个数据输入来进行学习模块的必要性。这包括上下文信息(例如位置)和用户行为信息(例如消费或输入)。
3.2. 信用卡FDS挑战
在处理信用卡欺诈检测时面临许多挑战,如图9所示。这些问题主要分为三类:
- 与数据相关的挑战:这些挑战与构建强大的信用卡欺诈检测系统所需的数据有关。它们包括:
- 类别不平衡;
- 缺乏真实数据;
- 数据漂移/转移;
- 数据重叠。
- 与安全相关的挑战,主要涉及隐私问题。
- 部署/实施挑战与最终FDS的效率有关,涵盖:
- 分布式实施。
- 时间复杂度。
与数据相关的挑战。FDS依赖于DDSM模块,这主要需要一个高质量的数据集来构建有效的检测模型。然而,研究人员在处理信用卡数据集时面临许多问题。
- 类别不平衡:一个不平衡或倾斜的数据集是一个已知类别中样本分布倾斜(或偏倚)的数据集。分布可以从轻微偏斜到严重不平衡,其中少数类别的原始数据量少于多数类别。不平衡分类对预测建模构成挑战。事实上,大多数用于分类的机器学习算法都假设每个类别的样本数相等(Sun等,2009年)。数据不平衡导致预测模型的预测性能较差,特别是对于少数类别。模型会偏向于多数类别,而少数类别通常更相关。因此,模型对于少数类别的分类错误更多。传统的机器学习算法需要一个平衡的数据集(Zheng,2020年)。然而,在实践中,与正常样本相比,异常类别中的样本要少得多。特别是在欺诈检测中,欺诈交易的数量非常少,与合法交易相比。不平衡的数据集降低了大多数机器学习算法的性能,如支持向量机(SVM)和随机森林(Dablain等,2022年)。解决这个问题的技术提议沿着两个方向进行,要么调整算法使其足够强大以处理不平衡数据集,要么使用预处理抽样方法解决不平衡数据集(Lucas和Jurgovsky,2020年)。

来源:所有报告卡支付方案运营商。
图6. 使用SEPA发行的卡总欺诈价值。
- 缺乏真实数据:这个挑战也被称为缺乏足够标记数据。事实上,出于许多原因,主要与隐私问题有关,缺乏用于构建准确模型的真实数据。在许多情况下,数据没有标记,这需要额外的工作来标记数据行。因此,异常检测是检测欺诈的常用方法之一。然而,这高度依赖于用户行为,任何变化都可能被检测为欺诈。异常系统依赖于用户的历史行为,这可能是有限的(Zheng等,2018年)。一些研究通过利用其他类似用户的信息来解决这一限制,但这增加了选择相似个体的问题(Cui等,2021年)。
- 数据重叠:当不同类别的样本出现在数据空间的同一区域时,就会出现重叠,使分类器难以区分它们(Denil和Trappenberg,2010年)。在信用卡欺诈检测的背景下,欺诈和非欺诈交易通常重叠,因为欺诈者模仿真实持卡人的行为以欺骗FDS。大多数研究处理数据重叠问题都认为它类似于类别不平衡问题(Li等,2021年;Vuttipittayamongkol和Elyan,2020年)。Denil和Trappenberg(2010年)的研究表明,类别不平衡和数据重叠对分类器性能有相互依赖的影响。此外,同一研究表明,与类别不平衡问题不同,数据重叠导致分类器性能线性下降。
文献中报告的克服类别不平衡和重叠问题的最常见解决方案包括三个主要步骤。第一步涉及将原始数据集分为重叠子集和非重叠子集。然后对重叠子集进行欠采样,以删除多数类别的样本。最后,使用分类器来检测少数样本(Li
实施/部署挑战
- 分布式实施:一个强大的金融数据系统(FDS)应该是分布式的,以实现更强大的解决方案,可以轻松扩展。长期以来,银行服务一直以单块架构为特征。尽管这种集中化是安全的,但它有几个局限性,即扩展以满足不断增加的客户数量的高成本。随着云计算的出现,银行已经发展到遵循这种计算范式。云提供的弹性可扩展性,以及它所达到的成熟水平,使许多银行能够转向云部署。一个良好的金融数据系统应该遵守分布原则,以适应新一代银行系统的基础设施。然而,分发FDS的组件是具有挑战性的,许多方面都应该考虑在内,比如延迟、采用新技术和框架,以及异构数据的集成。

图8. 信用卡系统完全自动化设计。

图9. 信用卡欺诈检测挑战。
- 时间复杂度:在线交易的实时性要求金融数据系统在毫秒内做出决策。当前系统通常存在欺诈检测时间与欺诈用户被排除在平台之外的时间之间存在差距。FDS应该能够基于流式大数据即时提供决策(Ali Yeşilkanat等,2020年)。完美的FDS寻求在交易获批之前甚至检测到欺诈。由于信息获取会导致不可避免的延迟,这种实时要求很难实现(Dal Pozzolo等,2015年;Mittal等,2020年)。然而,这也可能导致可用性问题和客户不满,如果存在许多误报。欺诈检测可能在交易过程中应用,但应提供高响应性。处理流式数据并提供实时分析的新技术,如Apache Spark(Chambers和Zaharia,2018年),可能在响应性方面提供更好的解决方案。只有少数研究调查了欺诈检测系统的实时方面。本调查探讨了这些内容,以为未来相关研究提供见解。此外,预测模型的评估必须考虑模型的响应性。为此,该指标在第7节中进行了描述。
这一类模型主要是人工神经网络(ANNs)(也称为NNs)。人工神经网络是受人类大脑生物神经网络启发而设计的模型。这种方法包括ANN、强化学习和深度学习等模型。在连接主义中,一个输入可能有一个输出;但到达输出的路径是隐藏的。ANN由一组相互连接的人工神经元组成。一般来说,ANN是自适应的,即在学习阶段通过网络结构传递的外部或内部信息改变其内部结构。现代神经网络是非线性统计数据建模工具。它们被用来建模输入和输出之间的复杂关联,或者发现数据集中的隐藏模式 [Daniel, 2013]。ANN已被用作监督和无监督技术来解决信用卡欺诈检测问题。
前馈神经网络(FNN)是最简单的一种ANN(Schmidhuber, 2015),信息仅在一个路径中流动:从输入节点,经过隐藏节点(如果有的话),最终到达输出节点。值得注意的是,FNN结构不包含循环或回路。概率神经网络(PNN)是一种特殊类型的FNN,具有广泛应用于分类问题的复杂结构(Mohebali等,2020)。Donald Specht提出了这种网络(Specht, 1990; Specht, 1990),它基于贝叶斯理论,并源自贝叶斯网络。它包括一个输入层、一个模式层、一个求和层和一个输出层。
深度学习是机器学习的一个子集。它与传统机器学习不同,因为它处理的数据类型以及遵循的学习方法不同。根据Goodfellow等人(2016)的说法,深度学习网络是具有两个或更多隐藏层的神经网络。事实上,增加更多隐藏层可以提高和优化准确性。只有一个隐藏层的网络通常被称为“浅层”。
卷积神经网络(CNN)(又称ConvNet)是一类最常用于各种计算机视觉任务的深度网络(Yamashita等,2018)。CNN被设计用于通过反向传播自动学习空间特征层次结构。它使用许多构建模块,包括卷积层、池化层和全连接层。尽管CNN主要应用于图像和视频识别以及医学图像分析,但也被用于在Babu和Pratap(2020, 2021)中检测欺诈交易。
循环神经网络(RNN)是一种深度ANN,它识别输入数据的顺序特征,使用模式来预测下一个可能的情景。它通常用于语音识别和自然语言处理。与前馈神经网络不同,RNN使用反馈循环来处理数据序列,从而允许信息持续存在。这连接了输入,使RNN能够处理序列和时间数据。这对于建模消费行为和识别异常行为如欺诈交易可能非常有用。RNN的主要问题是梯度消失和梯度爆炸问题(Yue等,2018)。前者是由于训练阶段中的错误造成的。如果梯度开始爆炸,神经网络将变得不稳定,无法从训练数据中学习。
通过递归反向传播学习存储信息的时间间隔很长(Hochreiter和Schmidhuber,1997)。这个问题被长短期记忆(LSTM)所解决,其每个时间步和权重的计算复杂度为0.1(Hochreiter和Schmidhuber,1997)。与FNN不同,LSTM具有反馈连接。因此,它不仅处理单个数据点(如图像),还处理序列数据,如语音或视频。LSTM被应用于Jurgovsky等人(2018)的信用卡欺诈检测中,以建立持卡人的消费购买概况。这提高了对新输入交易的欺诈检测准确性。研究发现,LSTM可以建模隐藏的序列模式和交易历史,从而提高了欺诈检测的准确性。然而,与标准前馈网络相比,LSTM较弱。
门控循环单元(GRU)是最常见的强大RNN模型之一,由Cho等人(2014)提出。它被认为是LSTM的改进和简化,因为它的门数量较少(LSTM门数量的一半),将输入和遗忘门合并为一个门,将隐藏和细胞状态合并为一个状态。GRU具有简化的结构,因为它使用的参数比LSTM少,这提供了更好的性能。实验结果表明,GRU对入侵检测系统效果更好(Xu等,2018)。将LSTM和GRU结合起来使得结果网络能够从两种单元的优势中受益,因此它可以学习长期关联和短期模式。实际上,GRU类似于带有遗忘门的长短期记忆(LSTM)。它的参数比LSTM少,因为它没有输出门。此外,Roy等人(2018)表明,LSTM和GRU远远优于基准人工神经网络,并能够正确地建模账户交易的顺序。这代表了宝贵的知识,使得可以区分欺诈和非欺诈交易。
自编码器(Baldi, 2011)是一种用于无监督学习的人工神经网络。它将输入数据压缩成较低维度的表示形式,以便可以从这种压缩表示重建输出。最近,它已被用于特征提取、降维和欺诈检测,因为即使有少量欺诈训练数据,它也能检测到欺诈交易(Chaquet-Ulldemolins等,2022)。它在分析实时、大规模和复杂数据方面表现出色(Fan等,2018)。
DeepWalk(Perozzi等,2014)是一种用于学习节点嵌入的可扩展算法,用于将图网络中的顶点表示为基于社交表征的向量。它将网络图作为输入,然后使用随机游走将图转换为一系列连接节点的随机路径,以便使用Word2Vec模型进行训练。它由两部分组成,即随机游走生成器和更新过程,并且通常用于社交网络检测。随机游走生成器基于图从根开始生成一个随机顶点,直到达到最大长度( t \mathrm{t} t)。此外,更新过程包括Skip-Gram,通过最大化相似性来更新节点嵌入。另一个用于嵌入图网络的算法是Node2Vec。这个算法是一种半监督机制,用于表示网络中的节点。它类似于DeepWalk算法;然而,随机游走的生成方式不同(Grover和Leskovec,2016)。
4. 传统基于机器学习的模型
以下部分描述了基于传统技术的信用卡欺诈检测研究。这些工作根据其方法分为监督和无监督技术。每个小节末尾提供了一个总结表,以突出每个类别的主要贡献。
4.1. 监督技术
在Correa Bahnsen等人(2016)中,作者侧重于在使用聚合特征和周期变量进行信用卡欺诈检测的背景下进行特征工程。他们扩展了交易聚合策略,并基于检查交易时间的重复行为,使用von Mises分布(Mahmoudi和Duman,2015),这是一种围绕圆周的连续概率分布。他们将最先进的信用卡欺诈检测模型(DT、logR、RF)与他们先前提出的基于贝叶斯最小风险(BMR)的改进进行比较(BMR决策树(BMR-DT)、BMR逻辑回归(BMR-LR)和BMR随机森林(BMR-RF))(Bahnsen等,2014),并评估不同特征集对结果的影响,另外还有成本敏感的RF和成本敏感的linR(Bahnsen等,2014)。他们证明周期特征可以提高储蓄(见第7节)13%,并将性能提高了超过200%。
Wang等人(2018)提出了一种基于反向传播神经网络(BPNN)的检测系统。该模型依赖于群体智能,即鲸鱼种群最优解(Mirjalili和Lewis,2016),来找到神经网络训练模型的初始权重和阈值。所使用的神经网络包含2层输入和2层输出,20个隐藏层,并在欧洲数据集的500个样本上进行了测试。鲸鱼算法用于找到模型的初始最优值,而BPNN用于校正和调整这些值,以输出最佳模型参数。这种技术解决了与BPNN相关的一些问题,如网络缺陷、收敛速度慢和系统稳定性差。这项研究的主要优势在于使用群体智能优化神经网络模型,以提高准确性。
Padmanabhuni等人(2019)建议使用由五个个体机器学习分类器组成的集成学习方法:SVM、KNN、
log
\log
log R、NN、DT。他们将最终结果与单独的机器学习模型进行了比较,另外还比较了Adaboost、RF、NN和概率神经网络(PNN)等其他学习技术。建议的模型的准确率高于研究中考虑的其他模型(82.47%),但灵敏度低于Adaboost、RF、NN和PNN。
Thennakoon等人(2019)提出了一个实时欺诈检测系统,该系统使用主成分分析(PCA)进行降维。作者还使用了10折交叉验证。为了测试他们的模型,他们使用了一个包含欺诈交易日志和非欺诈交易的私人数据集。该模型使用了四种机器学习算法(SVM、NB、KNN和 log R \log R logR)。然而,并不清楚实时特性是如何实现的,也没有进行测试来证明交易是否是实时检查的。
Kim等人(2019)介绍了一个框架,用于比较冠军模型和挑战者模型,其中前者是合作银行信用卡欺诈检测系统中使用的混合集成模型,后者基于深度学习(见第5节)。集成模型基于决策树、逻辑回归和浅层神经网络。提出的模型在实际系统中进行了评估。此外,作者使用离线测试和上线后在真实数据集上比较了两种模型(冠军和挑战者)。测试结果显示,使用基于深度学习的模型(挑战者)获得了最佳性能。
Rtayli和Enneya(2020)提出了一种基于混合方法的信用卡欺诈检测方法,使用支持向量机递归特征消除(SVMRFE)方法选择预测特征,并使用超参数优化(HPO)方法估计RF的最佳超参数值。该方法基于三个数据集进行了验证,结果显示与现有模型相比具有较高的准确性表现。
Ali Yeşilkanat等人(2020)使用了梯度提升树(GBT)模型来建模实时信用卡欺诈检测系统。该系统用于流式CNP交易。对于特征工程,作者结合了许多特征,包括数值、手工制作的数值、分类和文本特征。主要贡献是对分类值的聚合和词嵌入模型的使用。此外,作者在给定时间范围内使用滑动窗口方法解决数据漂移问题。建议的系统包括两个训练模块:离线训练和实时检测。该方案用于实时检测,并使用字符级词方法为每个商家表示不同类型的特征。然而,它没有考虑商家和卡交互的时间顺序。
Olowookere和Adewale(2020)提出了一个框架,结合元学习集成学习和成本敏感学习来检测欺诈交易。在第一阶段,利用元学习集成的原理结合了三个分类器的预测结果,即KNN、DT和多层感知器。在第二阶段,使用了成本敏感逻辑回归算法。它在元分类器的训练阶段包含了成本敏感学习。这是通过考虑基于实例的成本矩阵上的每个交易实例的误分类成本来实现的。最后,为了对属于测试数据的新交易进行分类,首先使用基本分类器对每个新交易进行分类。然后将得到的分类结果发送到成本敏感集成分类器,将最终分类标记为欺诈或非欺诈。尽管这个框架可能需要大量计算,但根据报告的结果,在高类别不平衡的情况下,成本敏感集成分类器的性能优于纯集成方法。
Sudha和Akila(2021)提出了一个系统,利用用户的操作和交易特征来检测可疑操作。该系统使用RF和M类支持向量机(M类SVM)来将收集的数据分类为合法或可疑。它包括两个阶段,第一个阶段使用RF将用户的操作特征分类为支付时的合法和欺诈操作(例如时间、显示余额、更改密码)。其次,使用M类SVM将交易特征(如账号、金额和类型)分类为欺诈行为。该模型易于实现,但如果RF中有许多树会减慢算法并使其不适合实时检测(Speiser等人,2019)。
Tran和Dang(2021)解决了数据不平衡问题,并比较了四种机器学习算法(RF、 log \log log、KNN、DT)以评估获得的平衡数据集的性能。结果显示,平衡数据集的性能优于倾斜不平衡数据集。类似地,(RB和KR,2021)调查了多种算法的使用,如SVM、KNN和ANN,以检测欺诈信用卡交易。算法的比较得出结论,ANN算法在准确性方面优于其他机器学习算法。然而,建议的模型非常简单,没有提供关于数据预处理、归一化和采样的详细信息。测试仅基于准确性、精确度和召回率,因此重要考虑额外的指标进行验证。
Sudha和Akila(2021)利用银行网站用户的行为来将交易分类为真实或欺诈。操作和交易特征合并为一个模型,包括三个阶段。首先,收集并分析用户行为,使用基于马尔可夫链的Web马尔可夫骨架过程。估计从网站页面到页面的转换的概率矩阵,以及在每个页面上花费的时间。其次,操作特征可以是操作类型、操作模式、操作设备、操作时间、源IP地址或位置信息。然后,将这些特征传递给RF算法,将操作分类为诚实或可疑。交易特征包括交易类型、交易设备、交易金额、账号和交易后余额。它们被发送到M类SVM分类器,以将交易分类为诚实或可疑。最后,使用多数投票集成分类来准确预测欺诈交易。然而,并未指定执行时间。此外,该模型依赖于分析个体用户行为,这可能具有计算成本高的特点。此外,作者未提供与最先进技术的性能比较。另一个问题是,分析用户在访问银行网站时的行为是否有助于改进欺诈检测。
Lucas等人(2020)将信用卡欺诈检测的特征视为一系列交易而不是单独的交易。在特征生成方面,使用了隐马尔可夫模型(HMM)构建历史特征和基于HMM的多个视角的特征。这些特征应用于随机森林,结果将精确度-召回AUC提高到18.1%。为了验证提出的解决方案,作者还将新的特征工程方法应用于Adaboost和逻辑回归分类器,并展示了这种增加的稳定性。这项工作的主要优点是改进了特征工程阶段。
Baabdullah等人(2020)提出了一种信用卡欺诈检测方法,用于解决与不平衡数据相关的问题,使用不同技术进行数据重采样(过采样和欠采样)。此外,为了提高分类性能,对重采样后的数据集应用了几种监督算法,即 log \log log、NB、DT、RF和KNN。最后,为了评估性能,将五种分类模型的性能评估指标与不同数据集的指标进行了比较。
Bagga等人(2020)评估并比较了九种技术(
log
\log
log R、NB、RF、KNN、多层感知器(MLP)、Adaboost、四象限判别分析等)在信用卡欺诈检测问题上的性能,使用了管道和集成学习进行特征选择。集成学习通过装袋分类器实现。为了克服不平衡数据,应用了ADASYN方法。然而,该模型的准确率为100%,这可能是由于过拟合问题导致的。需要使用不同数据集进行更多测试。
Ingole等人(2021)提出了一种以Oracle SOA套件为重点的信用卡欺诈检测系统。他们测试了不同的机器学习模型(监督、无监督、传统和深度学习)。测试的监督传统分类器包括SVM、隔离森林、随机森林回归器、局部离群因子(LOF)和NNP。Oracle SOA套件模型已部署在Google Cloud Platform(GCP)上,提供在线解决方案。作者在预处理阶段删除了时间属性,这个选择是因为对预测结果的影响较小。然而,时间属性在欺诈检测中可能非常重要,因为它是用户行为的一部分。此外,尽管该模型是在基于云的环境中实施的,但并未提供实时解决方案。
Han等人(2021)提出了一种名为INUM的系统,这是一种信息利用方法。INUM可用于辅助任何多模态多目标进化算法MMEA解决多模态多目标问题MMOP。INUM通过从最佳决策向量中提取一个决策向量,以产生精英解决方案。该方法增强了目标空间和决策空间的性能。通过优化特征选择结合极限学习,即WELM(加权极限学习)来用于信用卡欺诈检测,这是一种特殊类型的单层前馈神经网络。作者使用了MRPS(MO_Ring_PSO_SCD)(Yue等人,2018),这是一种改进的粒子群优化算法。这种解决方案的主要优点是考虑了决策空间和目标空间。此外,它可用于增强任何多模态多目标进化算法的性能。然而,该模型在处理一些不平衡的多模态多目标问题时,增长率(大规模人口和更多计算预算)会导致低结果。
表4总结了先前讨论的工作,并突出了使用的关键概念和机器学习算法。
4.2. 无监督技术
在Soltani Halvaiee和Akbari(2014)中,提出了一种基于人工免疫系统算法的AFDM(AIS-based Fraud Detection Model)用于欺诈检测。作者还并行化计算,并使用Hadoop来分发计算,从而将准确性提高了25%。本文提出使用云计算,通过在基于云的文件系统Hadoop上部署欺诈检测系统,从而实现数据并行化。然而,并行化更多关注计算成本,而非检测欺诈交易的准确性。
Srivastava等人(2016)提出了一种基于人工神经网络(ANN)的欺诈检测系统。该模型基于过去的交易进行训练,基于交易参数和用户配置文件输出概率值。根据该值,输出被分类为四类(非欺诈、可疑、可疑和欺诈)。虽然建议的模型简单易懂且易于实施,但未提供有关数据集、归一化阶段和测试的详细信息。该模型仅训练一次,不清楚如何解决数据漂移问题。此外,文献的比较研究没有得到合理解释。
表4

在Cui等人(2021)中,作者提出了一种异常检测机制,用于检测在线银行欺诈。该系统旨在解决先前欺诈检测系统的问题,即用户的历史数据量有限、交易数据的倾斜性以及处理用户属性值的统一方式的缺失。作者提出了一种称为ReMEMBeR的排名度量嵌入系统,它利用多上下文行为来减少误报率和错误率。他们设计了一个伪推荐系统,将个体视为伪用户,将其行为视为伪项目,以解决历史用户数据问题。该系统利用协同过滤来从其他相似用户的行为中获益。排名方法(合法/欺诈)基于将伪用户映射到伪项目,即他/她是否喜欢或不喜欢这个项目。该系统的性能在四个概念下进行了测试:真实世界交易、倾斜数据、模型组合(与机器学习算法SVM、RF、NN2L、 log R \log R logR)和多上下文行为。
Lucas等人(2019)提出了一种基于量化协变量转移(即行为差异)的信用卡欺诈检测方法。在这种方法中,将每天的交易与其他日进行分类以测试效率。如果分类有效,则表示这些日子相似;否则,意味着这些日子之间存在协变量转移。为了表征数据,它们被呈现在距离矩阵中以澄清协变量转移。然后使用 R F \mathrm{RF} RF算法对距离矩阵进行聚类。在聚类之后,作者观察到四个类似的簇与其他簇不同,即工作日、学校假期、星期六和星期日。数据转移被集成为信用卡欺诈检测系统的新特征。主要优点是所提出的模型解决了用户购买行为和欺诈机制的多样性问题,因为它随时间变化。然而,使用的数据集相对较旧(来自2015年),而欺诈策略在过去七年中已经发生了变化。此外,结果显示,与不应用协变量转移作为特征相比,只有轻微差异。
Ingole等人(2021)使用了无监督模型等技术来解决信用卡检测问题,将其视为异常检测问题。他们使用了隔离森林,类似于随机森林模型,建立在DT之上,但允许进行异常检测。他们还使用了局部离群因子,该因子基于计算异常分数,衡量样本与其相邻样本的孤立程度。
表5总结了用于信用卡欺诈检测的监督技术,并突出了使用的关键概念、实时性(如果有)以及考虑到的行为特征算法。
5. 深度学习模型
最近提出了一些基于深度学习的欺诈检测解决方案,其中大多数研究调查了监督深度模型。
Fu等人(2016)提出了一种基于CNN的监督模型,用于捕获主要商业银行的真实大规模交易中欺诈行为的内在模式。该模型分为两个阶段:训练阶段(离线)和预测阶段(在线)。在训练阶段,从原始数据中提取和转换特征在固定时间段内。基于先前用户的交易提取了多个特征,但这些传统特征本身不能用于表示复杂的消费者模式。因此,作者引入了一种称为交易熵的新特征,旨在表示用户交易和特定时间间隔内总交易金额之间的关系。尽管作者声称与一些最先进的方法相比取得了优越性能,但F1分数很低,检测准确性需要提高。此外,需要更多指标来更好地评估模型。
表5
总结了用于信用卡欺诈检测的无监督传统机器学习技术。

表6
总结了用于信用卡欺诈检测的深度学习模型。

Roy等人(2018)评估了四种深度学习算法的有效性:RNN、GRU、LSTM和ANN。通过向数据集提供新特征进行特征工程。值得注意的是,数据集包含由金融机构在8个月内收集的8000万笔匿名交易。灵敏度指标用于发现对模型性能影响最大的超参数。作者得出结论,模型性能受网络规模影响:网络越大,性能越好。此外,性能分析显示LSTM和GRU优于基线ANN模型。然而,根据Kim等人(2019)的观点,Roy等人(2018)提出的评估机制对于真实世界的欺诈检测系统不适用,因为其复杂性和多个约束条件。
Kim等人(2019)提出了一种冠军挑战者框架,其中冠军模型是一个集成学习模型,而挑战者是一个基于深度学习的模型。作者进行了参数调整并测试了几种模型。他们选择了前馈架构,并忽略了循环神经网络,因为每张卡的平均交易次数约为10次,62%的卡只有少于五次交易。测试结果显示,挑战者模型优于传统的集成学习。
在 Forough 和 Momtazi (2021) 中,作者提出了一种用于信用卡欺诈检测的集成模型,该模型使用了两个顺序分类模型,即 LSTM 和 GRU 网络。这些模型的输出被聚合并馈送到一个多层 FNN 中,作为一种投票方法来预测欺诈交易。作者声称,这种方法是第一个在欺诈检测中使用顺序模型集成的方法。该模型基于两个真实数据集进行验证,并与两个基准深度顺序模型(独立的 LSTM 和独立的 GRU)以及文献中的第三个集成模型进行了比较。结果显示,所提出的集成方法优于前三个模型。作者在比较中没有讨论如何使用 Precision-Recall 曲线下面积(AUC-PR)来处理不平衡数据。选择这种方法是因为它适用于高度类别不平衡的情况(参见第 7 节)。
Jurgovsky 等人(2018)提出了另一种使用 LSTM 进行序列分类的方案。该方案利用 LSTM 网络来聚合用户的历史行为,以提高欺诈检测的准确性。该模型经过了真实数据集的测试,并与 RF 进行了比较。结果显示,LSTM 提高了欺诈检测的效果,并在面对面交易中表现良好。然而,它并没有改善在线电子商务交易的效果。此外,这种解决方案在分类之前需要进行手动特征构建,这可能不适用于大规模和复杂的实际检测系统。
在 Kewei 等人(2021)中,作者使用了一个包含 512、256 和 32 个神经元的三个隐藏层的深度学习架构。他们结合了几种技术,包括特征工程、内存压缩、混合精度和集成损失,以提升建议模型的性能。他们使用了聚合特征,并强调了小时特征,因为它影响用户行为。实验表明,建议的模型优于测试过的传统机器学习方法,如朴素贝叶斯和支持向量机。
Ingole 等人(2021)使用 CNN 对欺诈交易进行分类,作为面向服务的系统的一部分。尽管 CNN 通常用于图像数据集,作者还展示了它在 FDS 上取得了良好的结果。Ingole 等人(2021)还在他们的模型中使用了自动编码器作为无监督深度学习分类器,该分类器包含了几个其他分类器。自动编码器用于异常检测,其中它通过真实交易进行训练。当欺诈交易输入模型时,它无法在输出层再现,因此被视为欺诈。最终解决方案使用 REST-API 实现。然而,与 SOAP 服务相比,REST 服务存在安全问题。
在 Zhou 等人(2021)中,作者提出了一种使用 Node2Vec 的大数据互联网金融欺诈检测方法,Node2Vec 是一种半监督图算法,用于表示节点和边。Node2Vec 使用随机游走将特征表示为低维向量。大型数据集在 Apache Spark GraphX 集群和 Hadoop 上进行处理。所提出的方法包括四个主要模块:
- 重新处理以清理数据,去除冗余和空字段;
- 通过将数据分成部分并分析每个部分来对正常数据特征进行采样,以收集正常特征;
- 使用 Node2Vec 算法进行图嵌入,以在网络图中表示拓扑特征的低维向量(在 Apache Spark GraphX 中实现);
- 预测,使用深度神经网络执行分类过程,输出最终结果。
为了评估实验结果,比较了三种机器学习算法:SVM、DeepWalk、Node2Vec。该模型的主要优势在于它提供了使用图形和分布方面的低维表示。此外,图算法可以检测高欺诈风险特征。最后,该模型仅能检测到 60 % 60 \% 60% 到 69 % 69 \% 69% 的欺诈样本。然而,Node2Vec 是一个静态图;一旦添加新节点,就需要在整个图上重复嵌入新节点。此外,节点拓扑影响节点嵌入,而不是节点属性或特性。
在 Zhang 等人(2021)中,提出了一个基于同质性导向行为分析(HOBA)的特征工程框架。基于信用卡交易的分析通常使用最近性-频率-货币(RFM)原则。在 Zhang 等人(2021)中,作者建议将交易的地理位置添加到 RFM 中,形成 RFM-Location(RFML)原则。此外,由于交易是异质的(例如购买交易和取现),四种以上的客户行为与给定特征(例如给定取现的货币价值)一起进行分析。为实现 HOBA,使用了两种策略:交易聚合策略(聚合特征、聚合周期、基于 RFML 的交易行为度量、聚合统计)和基于规则的策略以生成一些分类特征变量。这四个聚合元素的组合产生了 160 个可能的特征值。使用这么多特征,模型将过于复杂,无法实时更新用于欺诈检测系统。因此,作者建议使用分层特征选择。他们通过堆叠多个受限玻尔兹曼机(RBM)构建了深度信念网络(DBN),然后训练第一层的 RBM。第二层,伯努利-伯努利 RBM,通过将第一个 RBM 的隐藏层作为下一个层的可见输入层来构建。以此类推,可以逐层使用更多的 RBM 来构建 DBN,其中较低 RBM 的隐藏层被用作下一层 RBM 的可见层。这种逐层贪婪训练方法的主要优势在于它不需要类别标记。最后,添加一个表示训练数据类别标签的最终层,以处理分类问题。CNN 和 RNN 也在这项研究中使用。
表 6 总结了用于信用卡欺诈检测的深度学习技术,并突出了关键概念、类型(监督/无监督)和使用的算法。
6. 类别不平衡解决方案
数据不平衡发生在数据集中类别分布不均匀的情况下。类别不平衡可能是固有属性,也可能是由于收集数据困难,成本高昂,涉及隐私问题和需要大量工作(Elrahman 和 Abraham, 2014)。信用卡交易通常包括一个不平衡的数据集,其中欺诈交易非常少,相对于真实交易。
为了解决这个问题,提出了一系列方法,包括欠采样(Yen 和 Lee, 2006)和过采样(Chawla 等, 2002)。然而,这些解决方案具有挑战性,因为信用卡数据集非常不平衡,数据集的实例单独携带相关信息(例如同一持卡人的交易)(Ali Yeşilkanat 等, 2020)。
解决类别不平衡问题的另一个方法是使用成本敏感学习。这是机器学习的一个子领域,专注于在进行预测时使用具有不同惩罚或成本的数据模型(Balaji 等, 2011)。成本代表与错误预测相关联的惩罚。
许多研究已经将类别不平衡问题作为设计信用卡欺诈检测模型时面临的挑战性问题之一。
6.1. 过采样技术
在 Benchaji 等人(2018)中,作者提出使用遗传算法结合 K-均值聚类从少数类(欺诈实例)生成新的输入数据。这将产生一个更平衡的数据集,从而提高系统的准确性。自动编码器也用于特征选择,为欺诈实例生成具有区分性的特征。然而,作者更多地讨论了每个算法的理论,而不是提出的解决方案本身,并没有为所提出的模型提供证据。
在 Dornadula 和 Geetha(2019)中,作者为持卡人开发了个人资料,并使用合成少数过采样技术(SMOTE)和一类支持向量机(One-class SVM)来处理不平衡数据。他们使用 Matthews 相关系数(MCC)来衡量性能,该系数用于处理不平衡数据集。类似地,Rtayli 和 Enneya(2020)使用过采样来解决类别不平衡问题,并提出了一个使用 SMOTE 的混合系统。
在 Tran 和 Dang(2021)中,作者尝试通过利用两种不平衡数据的重采样技术:SMOTE 和自适应合成(ADASYN,一种改进的 SMOTE)来提高机器学习模型检测信用卡欺诈的效果。作者采用了四种机器学习算法(RF、logR、KNN 和 DT)来比较和评估从 SMOTE 和 ADASYN 产生的平衡数据集的性能。然而,使用的重采样方法可能导致数据过拟合。类似地,Bagga 等人(2020)使用 ADASYN 来解决类别不平衡问题。然而,他们实现了 100 % 100 \% 100% 的准确率,这可能表明由于使用的过采样技术导致了过拟合。
在 Yang 等人(2019)中,SMOTE 也被用作一种过采样技术来平衡数据集。在大规模真实数据集上对模型的性能测试显示,联邦学习实现了平均测试曲线下面积(AUC)达到 95.5 % 95.5 \% 95.5%,比传统系统高约 10 % 10 \% 10%。然而,该方案需要考虑可靠的测量方法,以保护隐私。
6.2. 欠采样技术
如第5节所述,(Roy等,2018)比较了几种深度学习模型。此外,他们通过随机欠采样解决了类别不平衡和可扩展性问题。他们测试了几种比例,发现10:1的非欺诈:欺诈是最适合信用卡检测的。然而,这一结果高度依赖于使用的数据集。
Li等 (2021) 提出了一种基于分治方法处理重叠类别不平衡的方法。他们训练了一个异常检测模型来排除少数类别的一些离群值和大量多数类别的样本。因此,剩下的样本构成了一个重叠子集,具有较低的不平衡比例。随后,他们通过使用非线性分类器来区分样本来处理所得到的重叠子集。他们还提出了一个新的评估标准称为动态加权熵(DWE),用于评估集合的质量,该标准考虑了排除少数类别的离群值数量和重叠子集的类别不平衡比例之间的权衡。
6.3. 混合技术
Mohammed等 (2018) 对大规模数据集测试了随机过采样(ROS)与多种分类器。他们还测试了各种类型的SMOTE,即原始版本、边界1和边界2、SVM-SMOTE、SMOTEENN和SMOTETomek结合RUS。他们测试了BBE,这是一个与随机欠采样(RUS)和SMOTE内部平衡的混合平衡模型。结果表明,混合技术具有可扩展性,并且取得了最佳性能。
Thennakoon等 (2019) 提出了一种欺诈检测系统,该系统使用过采样和欠采样技术来解决数据不平衡问题。它使用SMOTE来过采样欺诈实例,以及最近邻CNN和RUS来欠采样真实记录。
Baabdullah等 (2020) 进行了一项比较性实验研究,以检测信用卡欺诈,并通过应用不同的机器学习算法处理不平衡数据集以及过采样和欠采样方法来解决不平衡分类问题。该研究允许获得关于使用机器学习技术检测卡片欺诈的实验见解,尤其是在不平衡数据集中。作者使用SMOTE作为过采样技术,NearMiss作为欠采样技术。
6.4. 其他平衡技术
除了过采样、欠采样和结合过采样与欠采样的混合技术外,许多研究人员提出了其他解决方案来处理类别不平衡问题,如成本敏感学习和极限学习。成本敏感学习为不同类型的错误分类分配不同的成本。然后,使用专门的方法考虑这些成本。成本敏感学习旨在最小化模型在训练数据集上的成本,而不是像常规学习中那样最小化预测错误(Sammut和Webb,2010)。
此外,Li等 (2018) 提出了并行单类极限学习(P-ELM)来解决类别不平衡问题。它结合了单类分类器和极限学习机(ELM)。建议的解决方案适用于多类和二元分类问题。单类ELM依赖于一个事实,即所有训练对象应该在一个只包含目标类别的特征空间中,因此在仅有目标类别数据时对离群值进行检测是有用的(Leng等,2015)。PELM使用贝叶斯理论解决类别不平衡问题。训练数据集根据类别特征分为 k k k个子集,其中 k k k是类别数。然后,将得到的数据集并行输入到独立的基于高斯核的单类ELM中,然后使用条件概率来确定输出类别。另一个解决不平衡问题的基于ELM的方法在Xiao等 (2017)中提出。它使用了类特定成本调节极限学习机(CCRELM)并处理了二元和多类分类问题。在这种方法中,需要调整正则化参数以获得最佳结果,这在计算上是昂贵的。尽管CCRELM中使用了核扩展来提高性能,但正则化参数的计算并未考虑类别分布和重叠样本(即接近的负样本和正样本数据点)(Raghuwanshi和Shukla,2018)。因此,在Raghuwanshi和Shukla (2018)中进一步改进了CCRELM,提出了一种用于解决ELM不平衡问题的类别特定解决方案(CS-ELM)。它比CCRELM性能更好,并使用类别偏斜参数有效处理重叠样本。
在信用卡欺诈检测领域,已经提出了成本敏感学习和极限学习。例如,Kim等 (2019) 使用成本敏感学习以及随机抽样来解决类别不平衡问题。Olowookere和Adewale (2020) 通过在集成学习中结合成本敏感学习和处理类别不平衡的方法,为信用卡欺诈检测领域的类别不平衡问题做出了贡献。主要思想是在集成学习的主分类器中结合成本敏感学习,而不是在每个单独的分类器上强制执行成本敏感学习。作者表明,他们的解决方案在高类别不平衡下优于纯集成方法。Akila和Srinivasulu Reddy (2018) 通过向其装袋集成模型添加约束来解决类别不平衡问题,以减少包中的不平衡水平,从而实现改进的预测。作者提出了一个重叠多数装袋(OMB)模型,该模型通过为每个新包选择 60 % 60 \% 60%的训练样本来创建包,同时确保从少数类实例中选择所有样本,而其余样本则从多数类中随机选择。 60 % 60 \% 60%的值是基于多次实验选择的,并建议作为避免内部不平衡的最低阈值。另一篇解决类别不平衡问题的论文是 F u \mathrm{Fu} Fu等 (2016),其中应用了基于成本的采样到CNN分类器。
根据Zong等 (2013),WELM非常适合不平衡数据集。通过为每个示例分配不同的权重,加权ELM可以推广到成本敏感学习(Zong等,2013)。一些研究专注于在信用卡检测中使用WELM,主要是为了处理不平衡问题。Zhu等 (2020) 应用了多种优化技术来优化WELM,并将其性能与信用卡不平衡分类问题进行了比较。实验结果表明,具有蒲公英算法(即受蒲公英行为启发的群体智能算法)(Li等,2017)和基于概率的突变(Zhu等,2019)的WELM比改进的粒子群优化的WELM表现更好,以及蝙蝠算法、遗传算法、蒲公英算法和自学习蒲公英算法。
Han等 (2021) 通过提供一个与WELM相结合的特征选择优化模型来解决类别不平衡问题。Han等 (2021)中的模型与其他优化算法进行了比较,即多目标粒子群优化(MOPSO),并展示了良好的性能结果。
表7总结了文献中提出的用于解决领域中类别不平衡问题的技术。
表7
文献中使用的采样技术总结。

表8
公开信用卡欺诈检测数据集。

表9
文献中使用的数据集类型。

7. 欺诈检测数据集和测试参数
本节讨论了用于信用卡欺诈检测的可用数据集,并旨在深入了解研究人员依赖的评估指标,以测试他们的模型。讨论了这些指标的适用性,并呈现了文献中取得的最佳性能。
提供信用卡欺诈数据集的主要公共存储库包括 Kaggle 数据集 [2]、UCI 存储库 [3]、GitHub [4] 和 Kilthub 存储库 [5]。
Kaggle 数据集提供了一个发布数据集的公共平台,已成为许多研究人员测试其算法的来源。Kaggle 包含了几个用于信用卡的公共和合成数据集[^1],在信用卡欺诈检测领域得到了广泛应用。
信用卡欺诈检测的主要存储库和公共数据集列在表8中。其中包括 PaySim、信用卡欺诈检测和 IEEE-CIS。除了 Kaggle 外,UCI 存储库是一个用于机器学习的数据集、数据库和领域理论的集合。这是分析机器学习算法的重要来源。此外,它包含了588个数据集,其中包括一些信用卡数据集,如 Statlog(德国信用数据)数据集和信用批准数据集(用于 Padmanabhuni 等人(2019)、Han 等人(2021)、Zhu 等人(2020))。
此外,GitHub 包含了几个用于信用卡欺诈检测的合成数据集。其中一个数据集是由 Brandon Harris 制作的,用于 Sparcov 程序 [6]。这是一个合成数据集,包含使用 Faker 生成的带标签的交易,以提供有关商家和客户的信息。另一个合成数据集是从先前的数据集改编而来,用于实时信用卡欺诈分析 [7]。它是在2021年6月至10月之间生成的,使用 Faker 生成交易和客户资料。
最后,Kilthub 存储库是由卡内基梅隆大学图书馆管理的机构来源。大学研究人员使用这个存储库分享他们的材料,包括数据集,比如 Zheng(2020)中使用的 CERT 内部威胁数据集。
表9分类列出了用于最先进解决方案的主要数据集,并引用了它们所用的论文。
7.2. 欺诈检测测试指标
选择正确的指标对评估机器学习模型至关重要。不同的指标已被建议用于评估各种应用中的 ML 模型。本节提供了在调查的论文中使用的指标,并强调了最有用的那些,更适合信用卡欺诈检测问题的特定性。事实上,仅检查一个指标通常无法提供问题的全面图景。同时,使用的数据集的不平衡性使得依赖基本的 ML 指标毫无意义,如下所示。此外,大多数研究都使用误分类度量来评估各种解决方案,因此不考虑欺诈交易的财务成本(Correa Bahnsen 等人,2016)[^2]。
下一节首先介绍了用于定义测试指标的混淆矩阵(术语表,1998),然后总结了最常用的指标,以展示它们对信用卡欺诈检测问题的适用性。
混淆矩阵,或错误矩阵,是分类性能中的关键概念。它是模型预测与实际标签之间的表格化可视化。混淆矩阵的每一行描述了预测类别中的实例,而每一列定义了实际类别中的实例。在欺诈检测等二类问题中,目标是区分欺诈和非欺诈交易。这样,欺诈事件可以被分配在第一行为正类,非欺诈事件在第二行为负类。然后,“真实”被分配给正确预测,“假”被分配给错误预测。因此,在第一行中给出了真正例(TP)预测和假正例(FP)预测。类似地,在第二行中指定了假负例(FN)预测和真负例(TN)预测。

分类指标、统计指标和成本指标之间有所区别。
7.2.1. 分类指标
- 准确率:准确率是最直接的指标。它定义为正确预测的数量除以总实例数,乘以100:
准确率 = 100 × ( T P + T N ) / N \text { 准确率 }=100 \times(T P+T N) / N 准确率 =100×(TP+TN)/N
在许多情况下,准确率不是 ML 模型性能的良好指标,特别是当类别分布不平衡时,这在信用卡数据集中是常见的情况。在这种情况下,即使所有样本都被预测为最频繁的类别,模型也会有很高的准确率,但这是没有意义的,因为模型并没有学到任何东西。它实际上是将所有东西预测为多数类。因此,应考虑精确率。
- 精确率:这是最常用的指标之一。它用于通过找到真正例占总正例预测的比率来检查系统的正预测。
精确率 = T P ( T P + F P ) \text { 精确率 }=\frac{T P}{(T P+F P)} 精确率 =(TP+FP)TP
- 召回率(也称为敏感度或真正例率(TPR)):这是另一个重要的指标。它指的是模型在真实为欺诈时正确检测交易的能力。它用于衡量正确识别的实际正例的百分比(Wang 和 Zheng,2013)。
召回率 = T P R = T P T P + F N \text { 召回率 }=T P R=\frac{T P}{T P+F N} 召回率 =TPR=TP+FNTP
- 特异性(也称为真负率(TNR)):这指的是模型正确识别非欺诈交易的能力。因此,它用于衡量正确识别的实际负例的百分比,并定义为:
特异性 = T N T N + F P \text { 特异性 }=\frac{T N}{T N+F P} 特异性 =TN+FPTN
- 假正率(FPR):表示被分类或视为正的欺诈交易的比率。为了实现系统的最佳性能,此率应该较低(Kumari 和 Mishra,2019)。
F P R = F P F P + T N F P R=\frac{F P}{F P+T N} FPR=FP+TNFP
- F1 分数:在许多应用中,召回率和精确率都很重要。因此,F1 分数(或得分)将这两者合并为一个单一指标,即精确率和召回率的调和平均数,定义为:
F 1 − 分数 = 2 × 精确率 × 召回率 精确率 + 召回率 F 1-\text { 分数 }=2 \times \frac{\text { 精确率 } \times \text { 召回率 }}{\text { 精确率 }+ \text { 召回率 }} F1− 分数 =2× 精确率 + 召回率 精确率 × 召回率
然而,当数据平衡时,F-度量表现良好。调整后的 F1-度量(AGF)是 F-度量的改进,更适合不平衡的数据(Akosa,2017)。
- F2 分数:此度量将召回率视为比精确率重要两倍。定义为:
F2 − 分数 = 5 × 精确率 × 召回率 4 × 精确率 + 召回率 \text { F2 }- \text { 分数 }=5 \times \frac{\text { 精确率 } \times \text { 召回率 }}{4 \times \text { 精确率 }+ \text { 召回率 }} F2 − 分数 =5×4× 精确率 + 召回率 精确率 × 召回率
- 警报率:警报率是所有交易中被警报的交易比率。警报率由 Kim 等人(2019)定义:
A = T P + F P N A=\frac{T P+F P}{N} A=NTP+FP
7.2.2. 可视化表示
- 接收者操作特征(ROC)曲线:这是显示二元分类器性能的图表,作为其截断阈值的函数。它主要显示不同阈值值的 TPR 对 FPR 的曲线(Hanley 和 McNeil,1982)。ROC 曲线是检查选择良好截断阈值的整体模型性能的著名曲线。
- 曲线下面积(AUC):AUC 代表曲线下面积。它是一种可视化的图表,显示了每个阈值的 TPR 和 FPR 之间的权衡。对于每个阈值,TPR 越高,FPR 越低越好。因此,曲线更靠左上方的模型更好。
- 接收者操作特征下面积(AUC-ROC)(又称 AUROC):接收者操作特征下面积(AUROC)是用于检查任何分类模型性能的最重要指标之一。AUROC 是用于区分的性能指标;它显示模型是否能够正确排列示例并区分案例。然而,当数据严重不平衡时,不应使用此指标。实际上,对于高度不平衡的数据集,由于大量真负例,假正例率被拉低(Saito 和 Rehmsmeier,2015)。
- 精确率-召回曲线下面积(AUC-PR)(又称 AUCPRC):它依赖于精确率-召回曲线,将精确率和召回率合并在一个可视化中。对于每个阈值,计算并绘制精确率和召回率。曲线在 y 轴上越高,模型性能越好。了解精确率何时开始快速下降有助于选择阈值并提供更好的模型。与 AUCROC 分数类似,可以计算精确率-召回曲线下面积,以获得描述模型性能的一个指标。AUC-PR 可以被视为为每个召回阈值计算的精确度分数的平均值。在需要选择适合给定业务问题的阈值时,AUCPR 是相关的。当数据严重不平衡时,AUC-PR 集中在正类上,因此非常有用(Saito 和 Rehmsmeier,2015)。
G − mean = sensitivity × specificity G-\text { mean }=\sqrt{\text { sensitivity } \times \text { specificity }} G− mean = sensitivity × specificity
- K-S 统计量:K-S 检验是一种非参数和无分布假设的检验。事实上,这种统计检验对数据分布不做任何假设。K-S 检验可用于比较样本与参考概率分布,或者比较两个样本。给定一个分布 P,K-S 检验用于评估:
- 零假设:样本来自 P
- 备择假设:样本不来自 P
7.2.4. 成本指标
- 成本降低率:欺诈评分模型为真实交易估计分数。如果分数超过预定义的截断值 δ \delta δ,则拒绝该交易并将其发送给调查人员进行进一步分析。为了减少因错过警报而造成的成本,评分模型旨在通过返回精确的警报来降低误报率。一个误报的成本与交易分析相同,并产生联系持卡人 C c C_{c} Cc 的成本。一个漏报的欺诈 FN 的成本与交易 t i t_{i} ti 的金额 Amount i { }_{i} i 相同。模型的总成本 C C C 可以针对每笔交易 t i t_{i} ti 进行如下测量:
C δ = ∑ i = 1 N c i × C c + y i × ( 1 − c i ) × Amount i \begin{equation*} C_{\delta}=\sum_{i=1}^{N} c_{i} \times C_{c}+y_{i} \times\left(1-c_{i}\right) \times \text { Amount }_{i} \tag{1} \end{equation*} Cδ=i=1∑Nci×Cc+yi×(1−ci)× Amount i(1)
其中,如果系统为交易 t i t_{i} ti 引发警报,则 c i = 1 c_{i}=1 ci=1,否则为 0。交易的实际状态(欺诈与否)由变量 y i y_{i} yi 反映,其中如果交易是欺诈,则 y i = 1 y_{i}=1 yi=1,否则为 0。为了比较新的欺诈检测模型与第二个模型的性能,一个关注点是通过成本降低率 C r δ \mathrm{Cr}_{\delta} Crδ 来衡量新模型减少了多少成本。计算方法如下:
C r δ = C δ new C δ old \begin{equation*} C r_{\delta}=\frac{C_{\delta}^{\text {new }}}{C_{\delta}^{\text {old }}} \tag{2} \end{equation*} Crδ=Cδold Cδnew (2)
其中, C δ new C_{\delta}^{\text {new }} Cδnew 和 C δ old C_{\delta}^{\text {old }} Cδold 分别是新模型和旧模型的成本。成本指标是一个有价值的指标,在信用卡欺诈检测领域并未被广泛使用。
- 平均运行时间:运行时间是算法执行的持续时间。当一个算法在相同数据输入上执行多次时,计算所有获得的运行时间的平均值,得到平均运行时间。这个指标很重要,因为它比较了检测结果的可靠性与实现这些结果所需的时间持续时间。
- 成本节约:使用算法的成本节约 S \mathscr{S} S 定义为算法的成本与根本不使用任何算法的成本之间的比较。由 Correa Bahnsen 等人 (2016) 表示为:
S = C − C δ C \begin{equation*} \mathscr{S}=\frac{C-C_{\delta}}{C} \tag{3} \end{equation*} S=CC−Cδ(3)
在信用卡欺诈的情况下,不使用算法的成本
C
=
∑
i
=
1
N
y
i
×
C=\sum_{i=1} N y_{i} \times
C=∑i=1Nyi× Amount
i
_{i}
i。在这种情况下,成本节约由以下公式定义:
S
=
∑
i
=
1
N
y
i
c
i
A
m
o
u
n
t
i
−
c
i
C
c
∑
i
=
1
N
y
i
A
mount
i
S=\frac{\sum_{i=1}^N y_i c_i A m o u n t_i-c_i C_c}{\sum_{i=1}^N y_i A \text { mount }_i}
S=∑i=1NyiA mount i∑i=1NyiciAmounti−ciCc
- 基于分类指标的成本函数 (CCF) (Gadi 等人, 2008):一些研究作品如 (Soltani Halvaiee 和 Akbari, 2014, Akila 和 Srinivasulu Reddy (2018)) 使用基于分类指标的成本度量,如下所示:
C C F = α × F N + β × F P + γ × T P C C F=\alpha \times F N+\beta \times F P+\gamma \times T P CCF=α×FN+β×FP+γ×TP
例如,(Soltani Halvaiee 和 Akbari, 2014) 使用 100、10 和 1 作为 α , β \alpha, \beta α,β 和 γ \gamma γ 的值,而 (Akila 和 Srinivasulu Reddy, 2018) 使用交易金额作为 α \alpha α 的值, β = γ \beta=\gamma β=γ 指的是行政成本。
7.2.5. 讨论
已经提出了几种指标来评估信用卡欺诈检测模型的性能。表 10 总结了审阅模型取得的结果。它提供了对每篇论文描述的指标所获得的测试结果的概述,从而提供了对最先进技术性能的统一总体视图。事实上,不同的解决方案可能针对测试指标使用不同的术语。
从表 10 中可以看出,一些指标中广泛使用准确率,但不足以允许对检测系统进行适当评估。从表中可以看出,大多数研究依赖于分类指标,而少数使用统计和成本指标。值得注意的是,在测试模型的效率时,考虑成本指标是重要的,除了考虑更适合不平衡数据集的指标如 MCC。应该将额外的研究工作集中在统一使用信用卡欺诈检测中使用的测试指标,以便更好地比较最先进解决方案。此外,评估所提出模型的处理时间也很重要,因为许多研究声称是实时的,但并未考虑平均运行时间指标。
8. 开放研究问题和研究方向
在本节中,我们对对信用卡欺诈检测产生影响的最新进展进行了详尽的概述。我们强调了主要挑战和应该进行研究的未来研究方向。
表 10
受调查论文使用的指标。

8.1. 大数据技术
大量数据不断生成和收集。随着社交媒体的日益使用,收集的文本和图像数据越来越多。同时,物联网的增加,以及智能技术和智能城市的出现导致了大量需要处理以为决策者提供更清晰洞察的感知数据。
大数据和数据科学描述了将软件和技术与尖端算法和技术相结合,以获得更好的理解,产生明智的发现,并预测风险和收益(Doko 和 Miskovski, 2019)。大数据的特点是更多的多样性、不断增长的容量和速度,被称为三个 V。研究人员提出了更多的 V,如真实性,指的是数据质量和价值,即将数据海啸转化为业务 (Ishwarappa, 2015)。因此,大数据提供了更大更复杂的数据集,主要来自新数据和异构来源。这些数据集的特点是容量巨大,传统数据处理软件无法处理。同时,这些大量数据对支持商业智能非常有用。特别是,大数据可以支持实时处理大规模银行数据,从而增强欺诈检测。此外,大数据技术允许整合来自多个来源的异构数据,更有效地确定欺诈的作用。
数据并行性涉及将大型数据集分区到集群中的多个节点。每个节点负责处理一小部分数据,然后将结果组合以产生最终结果。这是允许快速响应和快速决策的最有效选项。Google 的 MapReduce (Dean 和 Ghemawat, 2010) 应用两个阶段并行处理数据:映射和减少。在映射阶段,数据在分配给各个节点的不同作业中分散。每个映射任务产生一组键值对,这些键值对被馈送到减少任务,也称为减少器。这些减少器将这些键值对聚合成一个较小的集合,形成最终输出。Hadoop 是支持大数据分析的主要框架,基于 Google 的 MapReduce,另外还有分布式文件系统 HDFS (Shvachko 等人, 2010) 和资源协调器 Yarn (Vavilapalli 等人, 2013)。然而,Hadoop 在执行映射和减少任务时会导致数据在磁盘上读取和写入两次的额外开销。这导致了 Spark 框架的提出。Spark 的主要原则是可以用于在内存中处理数据,相对于 Hadoop,它在效率和可伸缩性方面提供了显著的改进。Spark 类似于 MapReduce,它提供了映射和减少功能。但是,它支持更多的操作,可以在大型和分布式数据集上执行,例如在分布式和弹性数据结构 RDDs 和数据框上进行过滤和类似 SQL 的操作。
随着金融交易数据规模不断增长,使用传统技术可靠地实时检测欺诈操作变得越来越具有挑战性。因此,需要采用大数据分析方法,从大量历史数据中学习模式,然后部署分布式基础设施来减轻繁重的计算。尽管分布式方法的重要性,本研究显示很少有研究作品研究了在分布式架构中利用大数据分析来检测和/或预测信用卡欺诈 (Chen 等人, 2020; Zhou 等人, 2021)。因此,需要进一步的研究来提供实时系统,并研究可能阻碍有效利用这些技术的挑战,同时保护用户隐私。此外,将来自多个异构来源的多个数据集集成在一起以获得更准确的结果是很重要的。此外,仍然需要开放的大型数据集来支持研究人员研究大数据分析。一个可能的研究方向是开发有价值的合成大型数据集。
8.2. 云计算
特别是,云计算可以从成本节约和提供计算能力等不同角度为信用卡欺诈检测带来显著的好处。在云计算中,由于利用大型数据中心作为资源,内存、计算或存储没有限制。对于使用小型设备进行信用卡欺诈检测的增加使用,提出了有关将计算迁移到云端的价值,同时设计新的轻量级解决方案和算法以适用于远程设备的有趣研究问题。采用基于云的架构并重复使用云智能服务和基础设施以增强信用卡欺诈检测也是一个有趣的方向。在信用卡检测领域,很少有研究探讨了云计算,可以在该领域探索几个开放的研究方向,即利用云来收集和存储客户数据,以及在云中托管计算和人工智能模型。此外,聚集异构数据源和多个组织之间的互操作性可以帮助增立即欺诈检测。
未来的研究可能会探讨联邦机器学习和使用云/边缘计算将信用卡欺诈检测问题建模为涉及来自多家银行的多个异构数据集的分布式机器学习系统,同时保护持卡人的隐私。
8.3. 物联网和信用卡交易
物联网技术正在推动信用卡支付领域的全球进程。全球金融服务部门正在经历重大变革。特别是,数字支付正处于快速发展的深度阶段,由消费者对便捷、连接的支付解决方案需求的增加引领,并受到强大的当代和创新技术浪潮的推动。除了越来越先进的数据分析、人工智能和基于云的架构之外,对信用卡领域影响最大的颠覆性技术之一是物联网。物联网的发展迅速,促使多个领域的巨大增长。预计在未来十年内,全球物联网技术的支出可能高达1.1万亿美元,其中金融服务是最容易与其采用相关的领域之一。
在过去的十年里,每部智能手机都成为了一个潜在的购物工具。同样,预计任何设备都将在不久的将来成为购买商品和服务的平台,正如万事达卡的负责人所宣布的。这催生了支付互联网的概念。尽管这个术语尚未在学术界进行研究,但在与物联网制造商合作时,在工业环境中越来越多地使用。万事达卡和Visa正在开创支付互联网服务,推出面向金融机构的新型解决方案,旨在通过物联网连接的设备提供无缝的信用卡支付。这是通过可替代信用卡的可穿戴物联网设备实现的。例如,Fitbit可以通过手势实现支付。此外,许多汽车制造商提供车载应用程序,以实现无缝支付。现在甚至可以使用三星冰箱购物等。支付互联网正在渗透到我们日常经济和社会活动的多个方面。新冠疫情增加了在线交易的数量,并鼓励许多客户转向在线服务提供商,导致通过物联网设备和手机进行支付的次数增加(Wiścicka-Fernando, 2021)。然而,移动和物联网金融支付服务的快速发展不仅为消费者提供了便利和效率,也带来了额外的隐藏欺诈风险。复杂网络的隐藏可能成为犯罪分子欺诈活动的温床。控制和管理欺诈风险变得越来越复杂,因为欺诈行为越来越频繁,给商业银行和金融机构带来了高额损失。
未来的研究方向可能包括考虑将交易数据和从物联网设备收集的外部数据相结合的混合数据集,或涉及从物联网设备收集的数据的新系统设计和学习方法。此外,从物联网设备收集的行为生物特征可能用于验证用户身份并避免欺诈交易。因此,应该研究新的检测和认证模型。
8.4. 安全和隐私问题
最近,研究集中于提供技术来保护金融服务领域免受欺诈的影响。然而,仍有一些安全问题需要考虑。首先,为了构建准确的欺诈检测模型,我们需要收集大量用户行为数据(过去-现在)以检测任何与正常情况的偏差。保护这些信息至关重要,因为泄露它会侵犯用户的隐私,这意味着攻击者可以利用它们并尝试冒充他们。此外,这些数据可能帮助欺诈者创建新颖的模式来规避系统。值得注意的是,当DDoS攻击变得非常频繁时,服务容易变得不可用。此外,欺诈者的活动发展迅速,因此仅使用传统的机器学习技术构建机制是不够的,因为它们没有得到更新,也不需要考虑到客户行为的变化,如地区、假期等。Benchaji等人(2021)。研究人员还可以利用新技术,如区块链,构建安全的金融系统。只有少数研究人员考虑了这一领域。例如,区块链技术可用于防止信用卡欺诈(Balagolla等人,2021)和退款欺诈(Liu和Lee,2021)。
为了减轻客户的计算负担,一些数字交易依赖委托认证,以允许通过受信任的服务器进行通信。然而,攻击者可以破坏认证服务器以冒充客户,并削弱数字交易的安全性。在Yang等人(2021)中,作者提出了基于相互认证的协议来检测身份欺诈。尽管轻量级委托认证协议,性能评级是不现实的。实际上,任何旨在检测欺诈的解决方案都应该是实用的,并且涉及最小的计算开销。它还必须得到经验性能研究的支持,以解决高度影响的参数,如延迟和网络带宽。欺诈检测协议都是出于保护客户的善意,但在设计和使用中往往缺乏人性化维度。因此,定性和定量研究需要让用户参与数字交易,以阐明他们的安全感知和使用行为。虽然机器学习技术是欺诈检测协议的基石,但隐私问题减缓了它们在行业中的采用,因为监管变得越来越严格(例如GDPR:通用数据保护条例)。尽管新兴的隐私保护机器学习技术使用同态加密来保护个人数据,但欺诈检测的计算开销增加仍然是一个严重障碍。因此,无数据共享的协作学习正日益成为一个有前途的研究方向。
显然,区块链技术有潜力成为数字经济的新引擎。它可以消除欺诈并增加数字交易流动的透明度。然而,使用这种技术需要银行遵守将区块链代币与传统货币系统联系起来的规定。尽管其主要优势包括去中心化、透明度、不可变性和自动化,但它也受到与交易吞吐量、延迟、大小和带宽相关的限制。此外,由于支持跟踪的所有交易的无限存储,基于区块链的系统可能容易受到用户画像和匿名化违规行为带来的隐私问题的影响。
信用卡安全违规通常超出了行业当前法律法规的范围,工业法规正在被支付互联网的创新发展削弱,揭示了处理信用卡违规行为的法律法规不足的问题。诸如联邦贸易委员会(FTC)、通用数据保护条例(GDPR)和支付卡行业数据安全标准(PCI DSS)等法规需要进行调整,以符合保护个人身份信息(PII)的安全要求。
9. 结论
物联网技术和数据驱动金融的兴起严重影响了客户的日常生活和行为。数字支付正在迅速传播并变得越来越重要,尤其是自新冠疫情爆发以来。最近的研究表明,人工智能、大数据和云计算等新技术引起了研究人员的极大兴趣。尽管近年来在这一领域进行了大量研究,但也极少进行了全面的综述调查。因此,本研究旨在提供关于信用卡欺诈检测的最新和最相关研究,影响该领域的新技术。我们的研究分析了从 Scopus 和 Web of Science 数据库中提取的 40 项作品。文献样本还进行了探讨,重点关注研究趋势、理论成就、方法论、优势和劣势、建模和测试。证据显示,一些最先进的模型专注于使用深度学习模型、大数据分析和技术、物联网、实时和安全方面,而大多数先前的作品则侧重于比较传统的检测模型,没有明确努力提供更适合信用卡欺诈检测问题的新设计和模型。此外,值得注意的是,大多数分析作品依赖于不适合信用卡数据集的测试指标。还提出了一些未来工作的相关方向。本文中的每个主题都包含了在信用卡欺诈领域进行的研究概述,每个类别考虑了关键概念。因此,对先前研究结果的彻底分析使研究人员能够避免重复经验研究,并确定相关的研究空白。这项研究是原创的,为填补现有研究空白提出了新的未来工作方向。我们全面的文献综述汇编了许多学术文章,建立了一个坚实的基础,准确地代表了迄今在这一领域中的重要贡献。我们相信,我们的研究为深入了解客户对数字支付的当前态度提供了一个起点。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)