centos7三个节点的 spark集群搭建
一.前期准备:三台centos7虚拟机hadoop01,hadoop02,hadoop03(已成功完成hadoop集群搭建),xshell,xftp,spark安装包(https://www.apache.org/dyn/closer.lua/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz)说明:以下全部使用root用户进行操作二.针对h...
一.前期准备:
三台centos7虚拟机hadoop01,hadoop02,hadoop03(已成功完成hadoop集群搭建),xshell,xftp,spark安装包(https://www.apache.org/dyn/closer.lua/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz)
说明:以下全部使用root用户进行操作
二.针对hadoop01虚拟机进行如下操作
1. cd /usr/local 进入共享文件目录
mkdir spark 创建放置spark解压文件的文件夹
ll 查看spark文件夹是否已经成功创建

2. xshell 最上方: 窗口 -> 传输新建文件 打开xftp文件传输界面
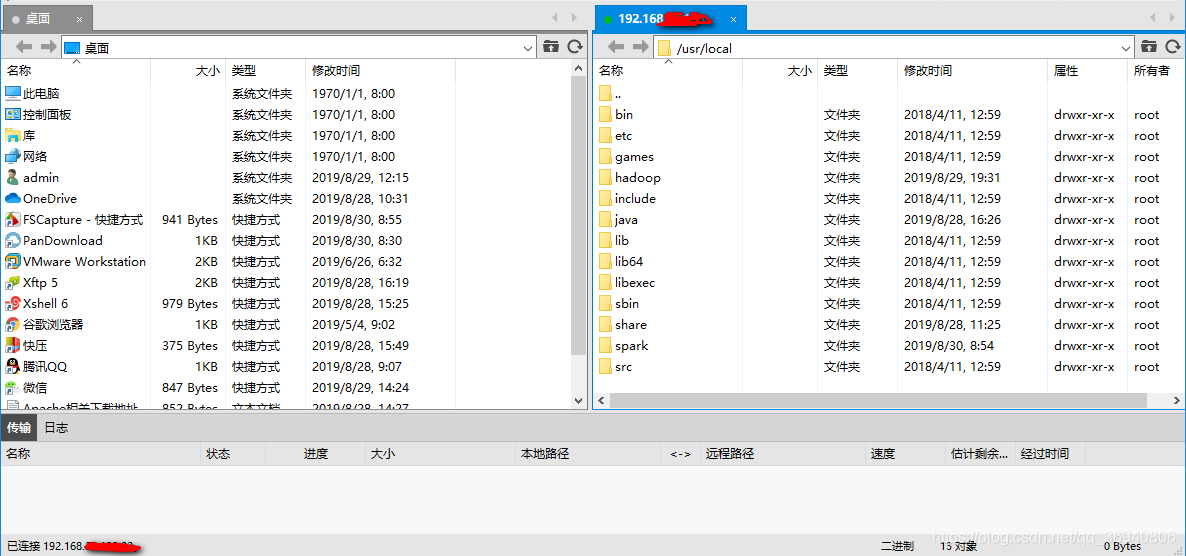
左侧栏进入对应的spark安装包目录,右侧栏进入到第一步创建好的spark目录,鼠标右击,点击传输,完成之后关闭xftp
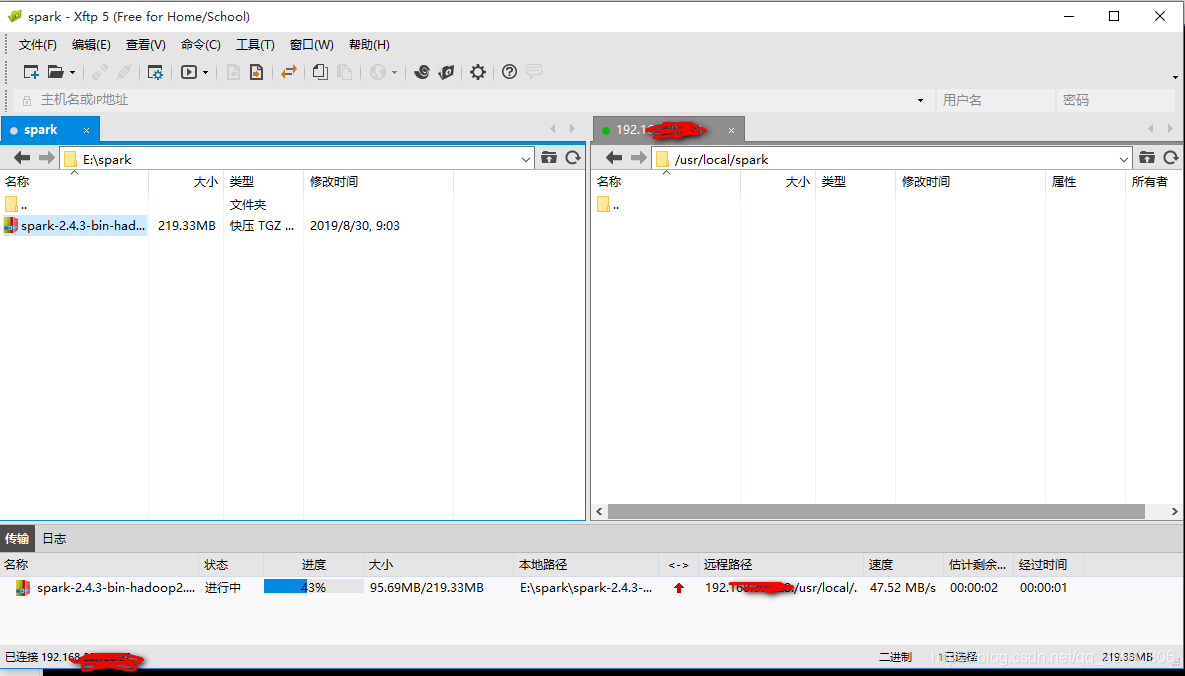
3. cd spark 进入spark目录
ll 查看spark安装包是否已成功上传
tar -xvf spark-2.4.3-bin-hadoop2.7.tgz (可输入spark 之后,按Tab自动补全文件名)

解压完成之后 rm -rf spark-2.4.3-bin-hadoop2.7.tgz 删除 spark安装包
ll 查看是否成功删除spark安装包

安装目录文件名过长 mv spark-2.4.3-bin-hadoop2.7 spark-2.4.3 重命名
ll 查看是否修改名字成功

4. vim /etc/profile 进入环境变量配置界面
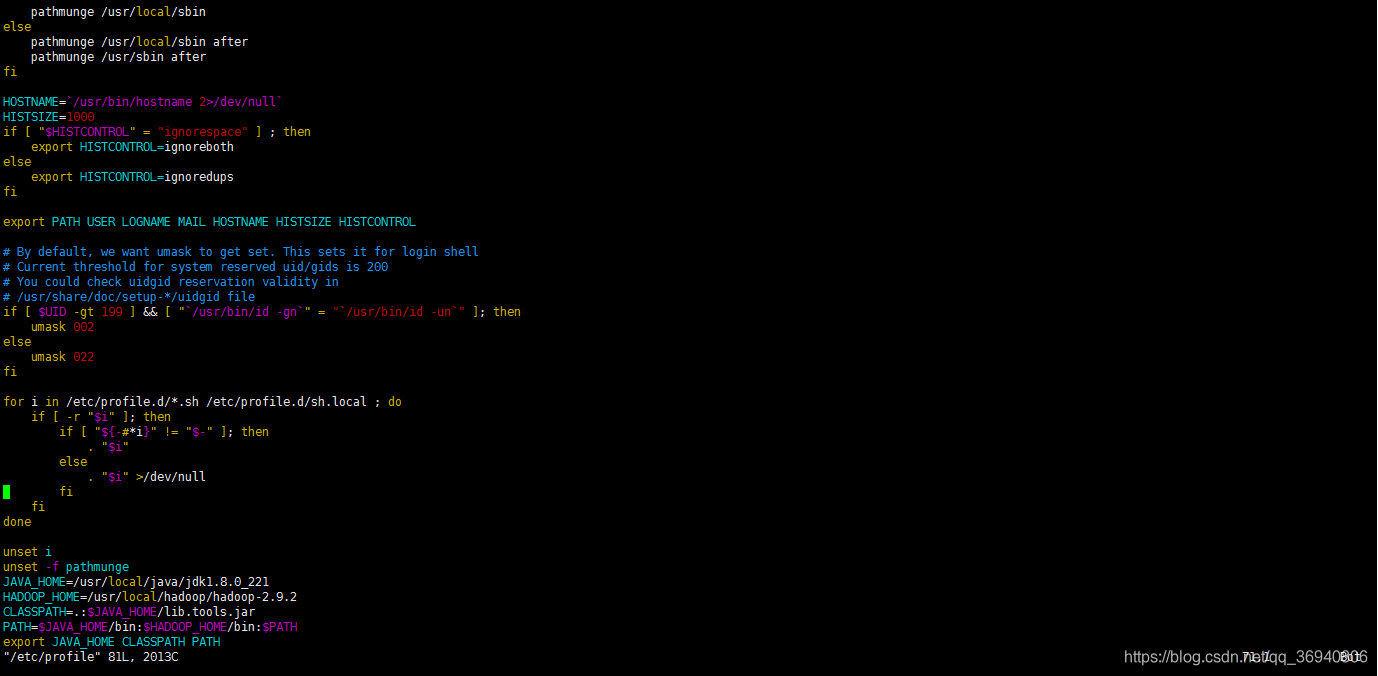
点击 i 键进入编辑模式,最下方出现 --INSERT-- 字样即进入到该模式
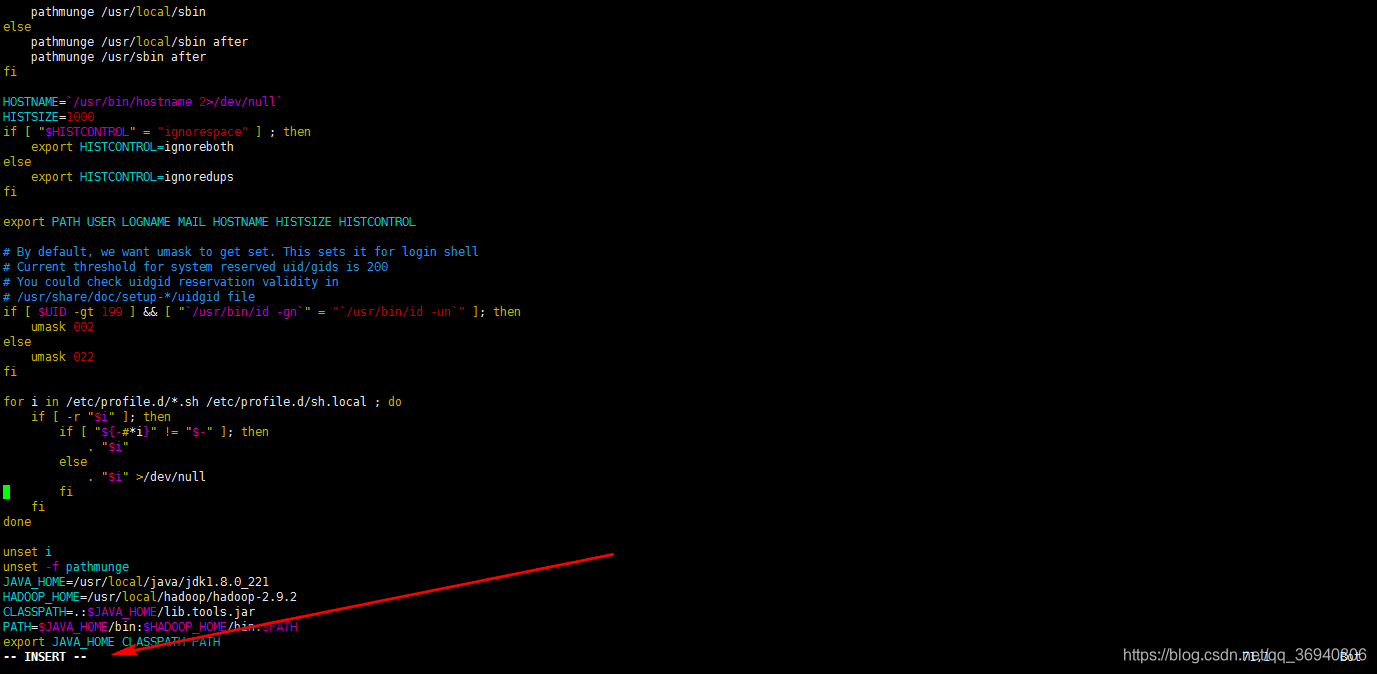
输入 SPARK_HOME=/usr/local/spark/spark-2.4.3
在 PATH中添加 $SPARK_HOME/bin

点击 Esc 键退出编辑模式,最下方--INSERT-- 字样消失

输入:wq 按 Enter 键退出vim编辑器

执行 source/etc/profile 使环境变量立即生效
![]()
5. cd /usr/local/spark/spark-2.4.3/conf 进入到conf文件夹
cp spark-env.sh.template spark-env.sh 复制spark-env.sh.template并重命名为spark-env.sh

vim spark-env.sh 进入编辑界面
![]()
点击 i 键进入编辑模式
方向键接将光标移动到最下方,输入
JAVA_HOME=/usr/local/java/jdk1.8.0_221
HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.2
HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.9.2/etc/hadoop
SPARK_MASTER_IP=hadoop01
SPARK_WORKER_MEMORY=512M
export JAVA_HOME HADOOP_HOME HADOOP_CONF_DIR SPARK_MASTER_IP SPARK_WORKER_MEMORY
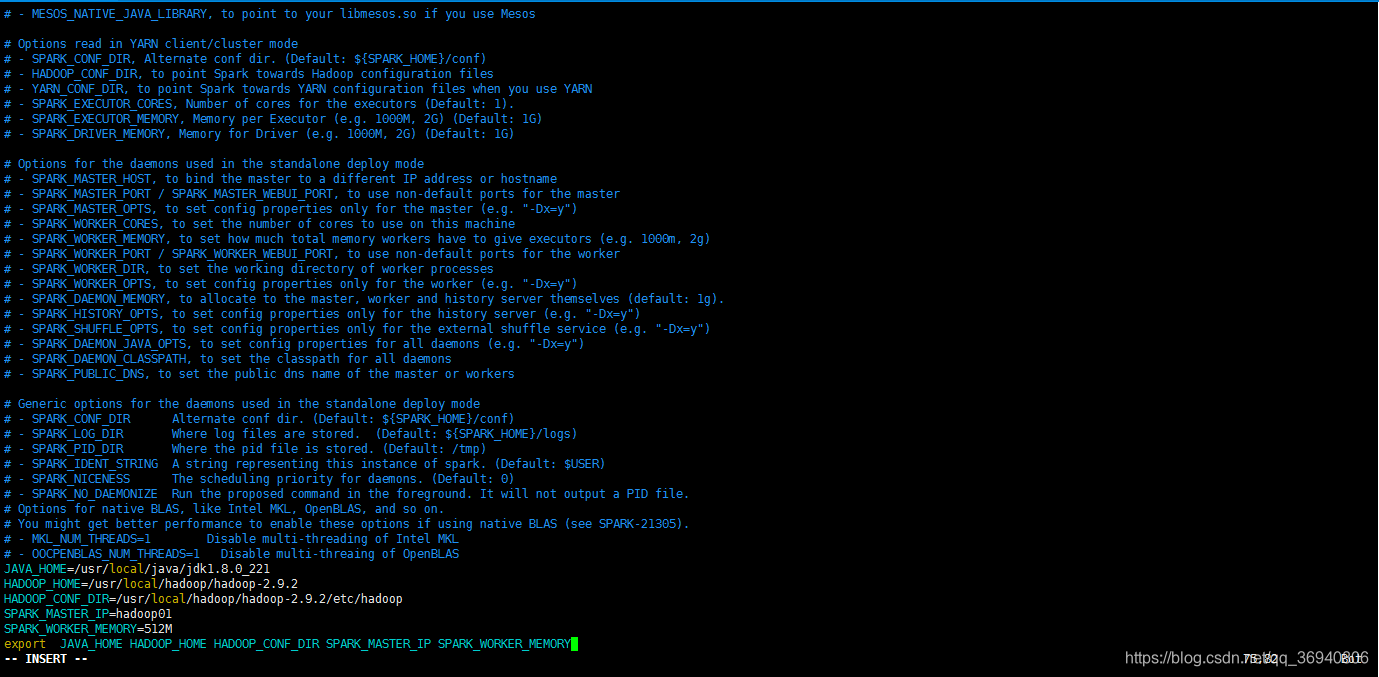
按 Esc 键退出编辑模式,输入 :wq 退出编辑器
6. cp slaves.template slaves 复制 slaves.template 重命名为 slaves
![]()
vim slaves 编辑 slaves
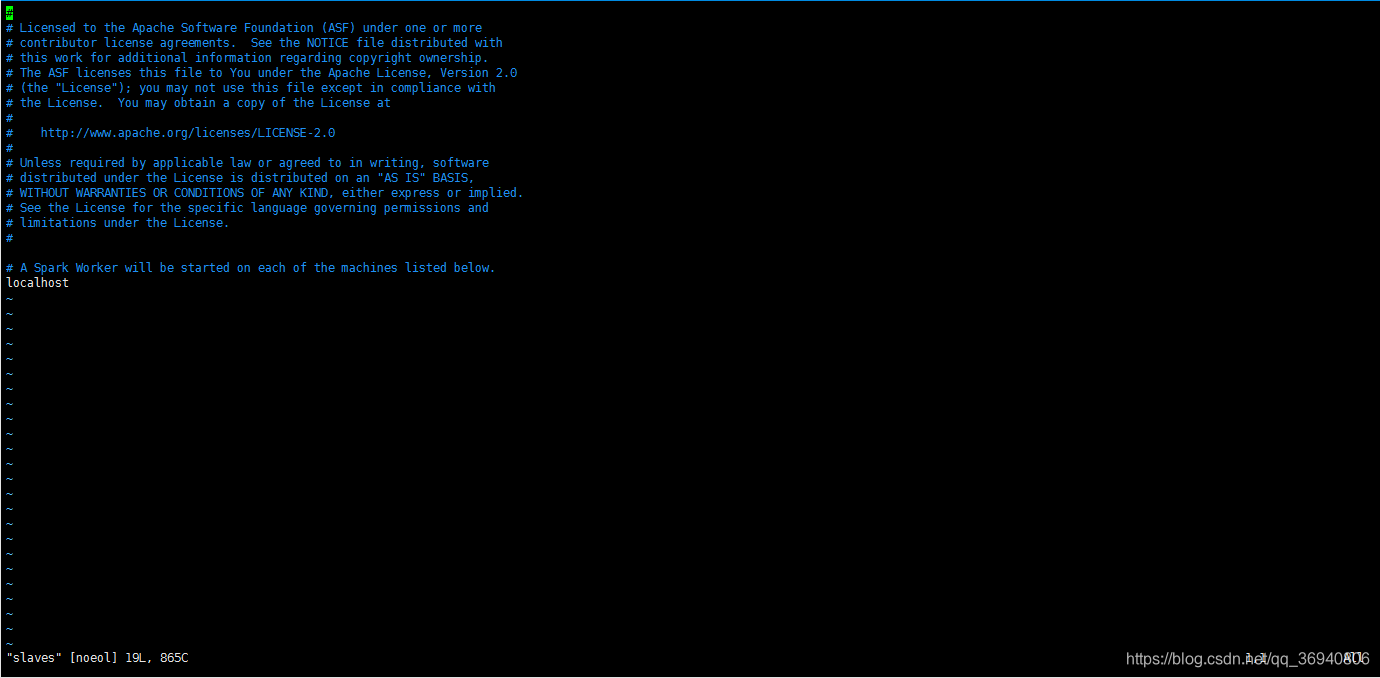
按 i 键进入编辑模式
删除 localhost ,加入 hadoop02 ,hadoop03
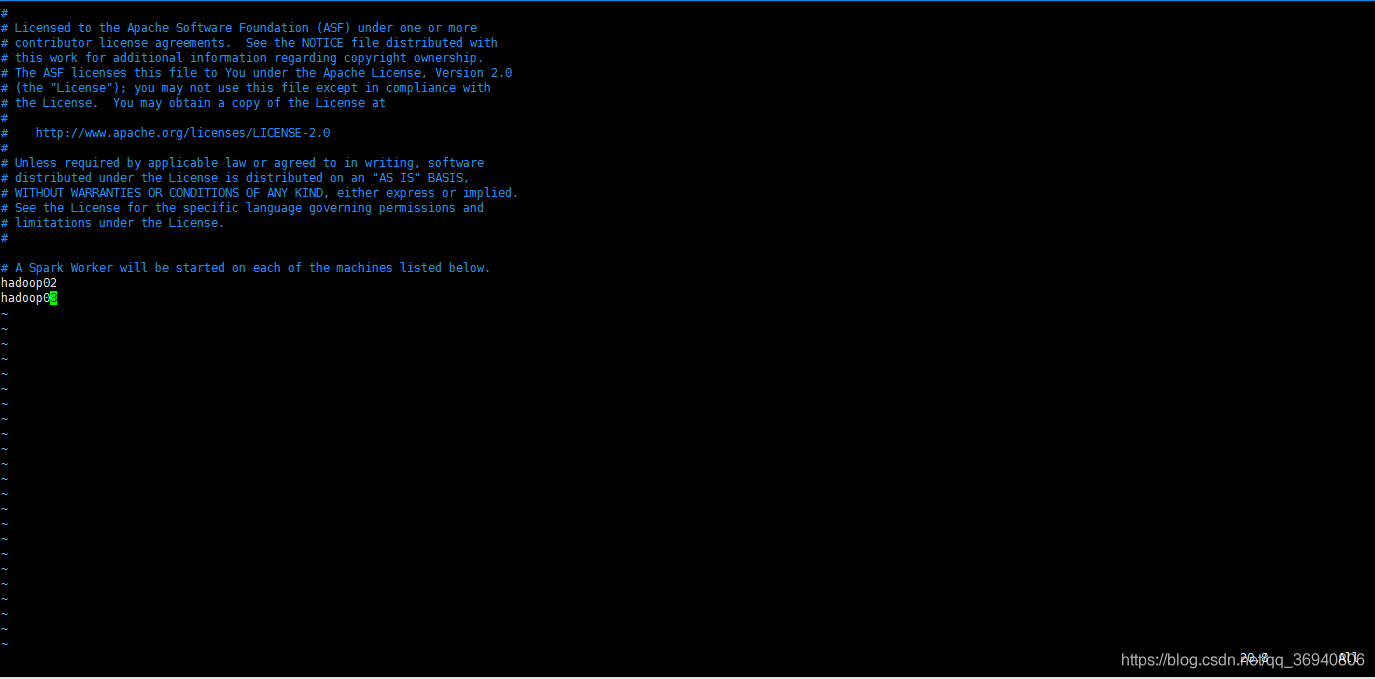
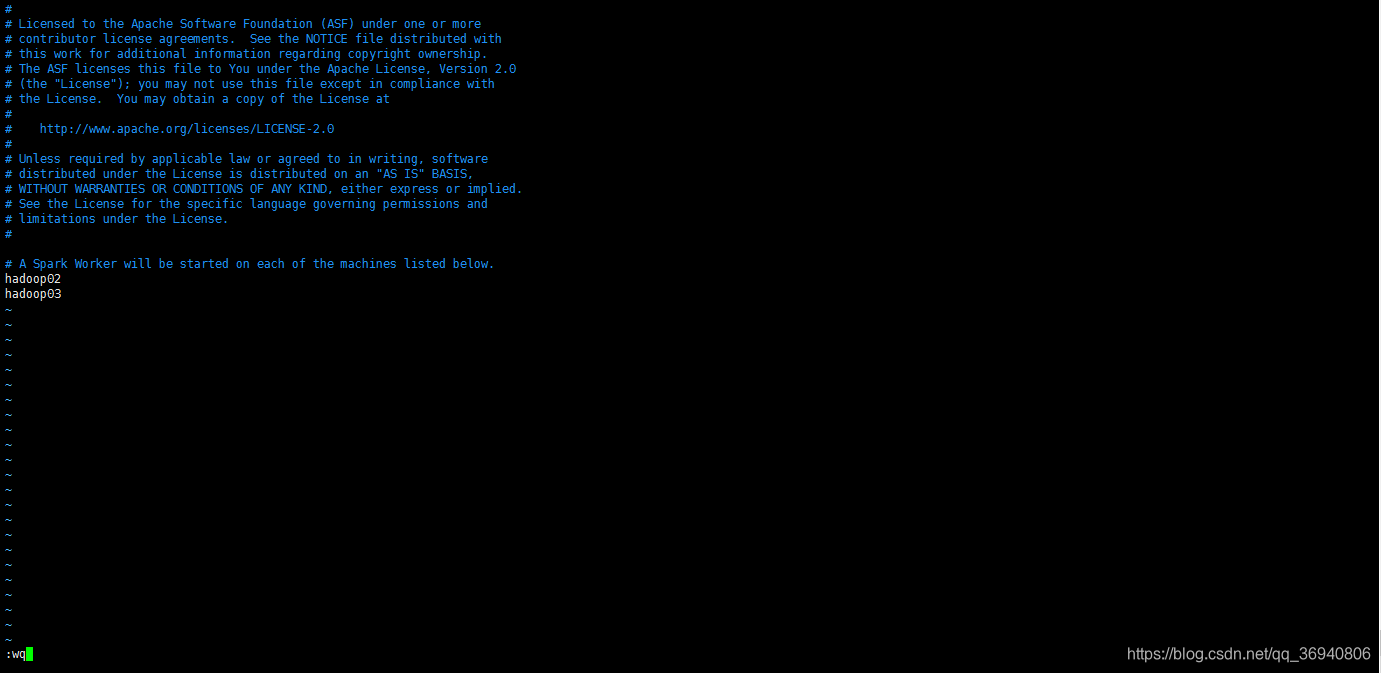
按 Esc 键退出编辑模式
输入 :wq 按 Enter 键退出编辑器
7. 执行
scp -r /usr/local/spark hadoop02:/usr/local
![]()
scp -r /usr/local/spark hadoop03:/usr/local
![]()
将 spark 分发到 其他两个节点 hadoop02,hadoop03上(注:hadoop02 ,hadoop03需开机)
三.针对hadoop02虚拟机进行如下操作
vim /etc/profile
![]()
进入环境变量配置界面
点击 i 键进入编辑模式,最下方出现 --INSERT-- 字样即进入到该模式
输入 SPARK_HOME=/usr/local/spark/spark-2.4.3
在 PATH中添加 $SPARK_HOME/bin
点击 Esc 键退出编辑模式,最下方--INSERT-- 字样消失
输入:wq 按 Enter 键退出vim编辑器
执行 source/etc/profile 使环境变量立即生效
![]()
四.针对hadoop03虚拟机进行如下操作
vim /etc/profile
![]()
进入环境变量配置界面
点击 i 键进入编辑模式,最下方出现 --INSERT-- 字样即进入到该模式
输入 SPARK_HOME=/usr/local/spark/spark-2.4.3
在 PATH中添加 $SPARK_HOME/bin
点击 Esc 键退出编辑模式,最下方--INSERT-- 字样消失
输入:wq 按 Enter 键退出vim编辑器
执行 source/etc/profile 使环境变量立即生效
![]()
五.测试
针对hadoop01虚拟机:
cd sbin 进入到sbin目录
./start-all.sh 启动spark集群

输入 jps 查看启动进程

针对hadoop02虚拟机:
输入 jps 查看启动进程

针对hadoop03虚拟机:
输入 jps 查看启动进程

六.补充
spark-defaults.conf
spark.master spark://centos1:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.eventLog.enabled true
spark.eventLog.dir hdfs:///tmp/spark-events
spark.driver.host centos1
spark.executor.memory 1g
spark.driver.memory 1g
spark.executor.logs.rolling.maxRetainedFiles 100
spark.executor.logs.rolling.maxSize 1g
spark.yarn.historyServer.address centos1:18080
spark.history.fs.logDirectory hdfs://centos1:9000/historyserverforSparkspark-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export HADOOP_HOME=/usr/local/hadoop-2.6.1
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.1/etc/hadoop
export SPARK_MASTER_IP=192.168.20.101
export SPARK_MASTER_PORT=7077
export YARN_HOME=/usr/local/hadoop-2.6.1
export YARN_CONF_DIR=/usr/local/hadoop-2.6.1/etc/hadoop
export SCALA_HOME=/usr/local/scala-2.11.12
export SPARK_MASTER_IP=192.168.20.101
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)