溯源图搭建工具SPADE的安装与使用
版本:Ubuntu 18.04.6x86-64注意:虚拟机需要至少8g运存,SPADE才可以顺利运行由于SPADE下载安装略有小困难,所以下面是一个安装好SPADE的虚拟机镜像,可自取链接:https://pan.baidu.com/s/1H8yDvK35UrS5tAgsbTK7sA?pwd=mc9v提取码:mc9v注:该镜像配置仅完成了Graphviz输出,可从SPADE启动开始。
参考文章与SPADE的官方文档
System-level Provenance 收集工具 SPADE 部署与使用 - 知乎 (zhihu.com)
设置 SPADE ·ashish-gehani/SPADE 维基 ·GitHub上
攻击溯源-手把手教你利用SPADE搭建终端溯源系统-腾讯云开发者社区-腾讯云 (tencent.com)
Linux 安全审计工具Audit在Ubuntu系统中安装-CSDN博客
目录
二、安装Git,Linux Audit、lsof、uthash
一、安装
安装教程
搭建环境介绍
版本:Ubuntu 18.04.6 x86-64
注意:虚拟机需要至少8g运存,SPADE才可以顺利运行
由于SPADE下载安装略有小困难,所以下面是一个安装好SPADE的虚拟机镜像,可自取
链接:https://pan.baidu.com/s/1H8yDvK35UrS5tAgsbTK7sA?pwd=mc9v
提取码:mc9v注:该镜像配置仅完成了Graphviz输出,可从SPADE启动开始
安装步骤
一、安装OpenJDK11
由于在所有情况下,编译 SPADE 都需要 Open Java 开发工具包(OpenJDK 11、12、13 或 14)。这可以从 OpenJDK 下载。
在这里我们选择安装openJDK11
-
方法一
直接安装
sudo add-apt-repository -y ppa:openjdk-r/ppa
sudo apt-get update
sudo apt-get install -y openjdk-11-jdk
-
方法二
我们在本机下载完成后,将文件拖拽入虚拟机中,进行解压安装

可自行搜索安装,在此不多做赘述
二、安装Git,Linux Audit、lsof、uthash
除了 JDK 之外,构建 SPADE 还需要在系统上安装 Git。它用于下载源文件进行编译。您还需要 Linux Audit、FUSE、lsof 和 uthash。在 Ubuntu 上,所有这些都可以通过以下命令安装:
sudo apt-get install -y auditd bison clang cmake curl flex fuse git ifupdown libaudit-dev libfuse-dev linux-headers-`uname -r` lsof pkg-config unzip uthash-dev wget
三、安装并编译SPADE
首先,使用以下命令下载 SPADE。请确保使用命令中指定的修订号,因为最新版本的源代码可能不稳定:
git clone https://github.com/ashish-gehani/SPADE.git
这将创建一个目录并下载其中所有必要的文件。SPADE
要编译 SPADE 代码,请在执行命令之前导航到此新创建的目录和包,如下所示:
cd SPADE
./configure
make
四、启动
启动 SPADE 服务器,需要在SPADE的bin目录下使用此命令:SPADE/bin
./spade start
要改为将 SPADE 作为前台进程启动,请使用以下命令:
./spade debug
要启动用于配置SPADE服务器的控制器,请执行以下命令(在目录中):SPADE/bin
./spade control
将出现以下内容,即可确认安装成功:
SPADE 3.0 Control Client
Available commands:
add reporter|storage <class name> <initialization arguments>
add analyzer|sketch <class name>
add filter|transformer <class name> position=<number> <initialization arguments>
remove reporter|analyzer|storage|sketch <class name>
remove filter|transformer <position number>
list reporters|storages|analyzers|filters|sketches|transformers|all
config load|save <filename>
exit
->
一开始,没有报告器、存储、滤波器、变压器或草图。这可以通过以下命令看到(或使用list all):
-> list reporters
No reporters added
-> list storages
No storage added
-> list filters
No filters added
-> list transformers
No transformers added
-> list sketches
No sketches added
要在不停止SPADE服务器的情况下退出控制器,请使用以下命令:exit
->exit
要停止 SPADE 服务器,请使用以下命令(在目录中):SPADE/bin
./spade stop
二、使用
一、配置输入
由于实际使用需求,只详细介绍Linux系统中的Audit的输入方式,其他方式可自行在官方文档查询
Collecting system wide provenance on Linux with Audit · ashish-gehani/SPADE Wiki · GitHub
Audit reporter 可以使用Linux内核的系统调用audit事件流收集provenance。(NOTE : SPADE本身的活动信息不会被收集)
首先,在终端进行以下配置以使普通用户可以配置和访问audit数据流:
sudo chmod ug+s `which auditctl`
sudo chmod ug+s `which iptables`
sudo chmod ug+s `which kmod`
# 以下两条命令要在SPADE目录下执行
sudo chown root bin/spadeAuditBridge
sudo chmod ug+s bin/spadeAuditBridge
接下来需要对 /etc/audisp/plugins.d/af_unix.conf 文件进行修改,我们可以使用vi编辑器编辑,可自行搜索vi编辑器命令:
active = no
改为
active = yes
重新启动以激活调度程序 :
sudo service auditd restart
然后打开SPADE控制器进行配置
./spade control
1.调用保存的日志文件
可以使用已经保存的日志文件或者是非本机的日志文件。收集日志的计算机的硬件体系结构必须为 x86-64。要从x86-64计算机上收集的文件中读取记录,可以使用以下命令在SPADE控制器中启动报告器:(其中/tmp/audit.log是自己设置的文件读取路径)
-> add reporter Audit inputLog=/tmp/audit.log
Adding reporter Audit... done
日志必须按事件标识符排序。这是在预处理期间自动完成的。审核日志处理的结束在 SPADE 的日志中报告。(log/SPADE_<date>-<time>.log)
2.保存日志审计记录
出于调试目的,可以使用该参数将已处理的 Linux 审核记录存储在文件中。例如,通过使用以下命令在 SPADE 控制器中启动报告器,可以将记录存储在文件中。
-> add reporter Audit outputLog=/tmp/audit.log
Adding reporter Audit... done
3.实时收集
-> add reporter Audit
Adding reporter Audit... done
剩余输入配置可知官方文档查看
二、配置输出
由于实际使用需求,输出配置依旧只着重介绍neo4j图形数据库输出以及Graphviz输出,如有需求,请移步官方文档
1.neo4j图形数据库输出
Neo4j在编译SPADE时已经自动下载了
进入SPADE目录,修改配置:
sudo vi lib/neo4j-community-4.1.1/conf/neo4j.conf
# 将dbms.directories.data的值设为database location的值,即在配置storage时database的值
#删除原来的#
dbms.directories.data = spade.graph
# 为了启动远程访问,我们添加如下配置
不添加#
dbms.connector.http.listen_address=0.0.0.0:7474
dbms.connector.bolt.listen_address=0.0.0.0:7687
配置环境变量,方便neo4j启动:
sudo vi /etc/profile
# 添加
export PATH=$PATH:/home/alston/SPADE/lib/neo4j-community-4.1.1/bin
source /etc/profile
配置图形数据库输出需要在SPADE控制器中使用如下命令:
-> add storage Neo4j database=spade.graph
Adding storage Neo4j... done
neo4j对应的数据库在SPADE的/bin/neo4j-community-4.1.1/spade.graph/目录下
删除命令为:
-> remove storage Neo4j
Shutting down storage Neo4j... done
启动neo4j:
由于spade.graph/databases/store_lock在SPADE启动时会被锁定,导致neo4j无法启动,因此SPADE和neo4j只能有一个在运行 。
#关闭SPADE
./spade stop
#在SPADE的/lib/neo4j-community-4.1.1/bin/
./neo4j start
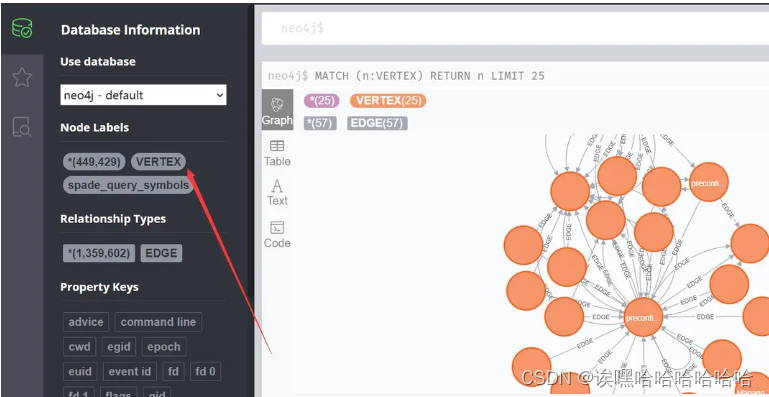
打开虚拟机自带火狐浏览器,输入网址:127.0.0.1:7474 进入neo4j界面
默认账号密码都为neo4j ,进入后自行修改密码

可自行搜索neo4j的操作方法。
2.Graphviz输出
配置Grapgviz输出依旧需要在SPADE的控制器中:/tmp/provence.dot 中/tmp/已经为自定义的路径
-> add storage Graphviz output=/tmp/provenance.dot
Adding storage Graphviz... done
删除配置:
-> remove storage Graphviz
Shutting down storage Graphviz... done
虚拟机安装Graphviz,可渲染文件:
dot -Tsvg -o /tmp/provenance.svg /tmp/provenance.dot
生成的文件可用浏览器打开
三、错误解决
1.配置调用保存好的日志文件出错

控制器中使用 list all 命令:
-> list all
发现reporter中1.Audit()为空,删除该reporter后再次安装成功

2. neo4j配置失败
打开浏览器后并未出现Node labels,该问题未解决。

配置这里使时要注意,没有#号 自己在配置时加了#号,#号是注释的意思,要注意这个地方


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容
 免费领云主机
免费领云主机



 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)