跟我学storm教程2-并行机制及数据流分组
topology的四个组成部分Nodes(服务器)即为storm集群中的supervisor,会执行topology的一部分运算,一个storm集群一般会有多个nodeworkers(JVM虚拟机)node节点上运行的相互独立的jvm进程,每个节点上可以运行一个或者多个worker。一个复杂的topology会分配到多个worker上运行。Executor(线程)指某个jvm进程中运行的j
·
原文地址:http://blog.csdn.net/hongkangwl/article/details/71103019 请勿转载
topology的四个组成部分
Nodes(服务器)
- 即为storm集群中的supervisor,会执行topology的一部分运算,一个storm集群一般会有多个node
workers(JVM虚拟机)
- node节点上运行的相互独立的jvm进程,每个节点上可以运行一个或者多个worker。一个复杂的topology会分配到多个worker上运行。
Executor(线程)
- 指某个jvm进程中运行的java线程。多个task可以指派给同一个executor运行。storm默认给每个executor分配一个task。
task(spout/bolt实例)
- task是spout或者bolt的实例,他们的netTuple()和execute()方法会被executor线程调用执行
示例
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
// SentenceSpout --> SplitSentenceBolt
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2)
.setNumTasks(4)
.shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
builder.setBolt(COUNT_BOLT_ID, countBolt, 6)
.fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt)
.globalGrouping(COUNT_BOLT_ID);
Config conf = JStormHelper.getConfig(null);
conf.setNumWorkers(2);如上述配置的拓扑,其并发示意图如下图所示:
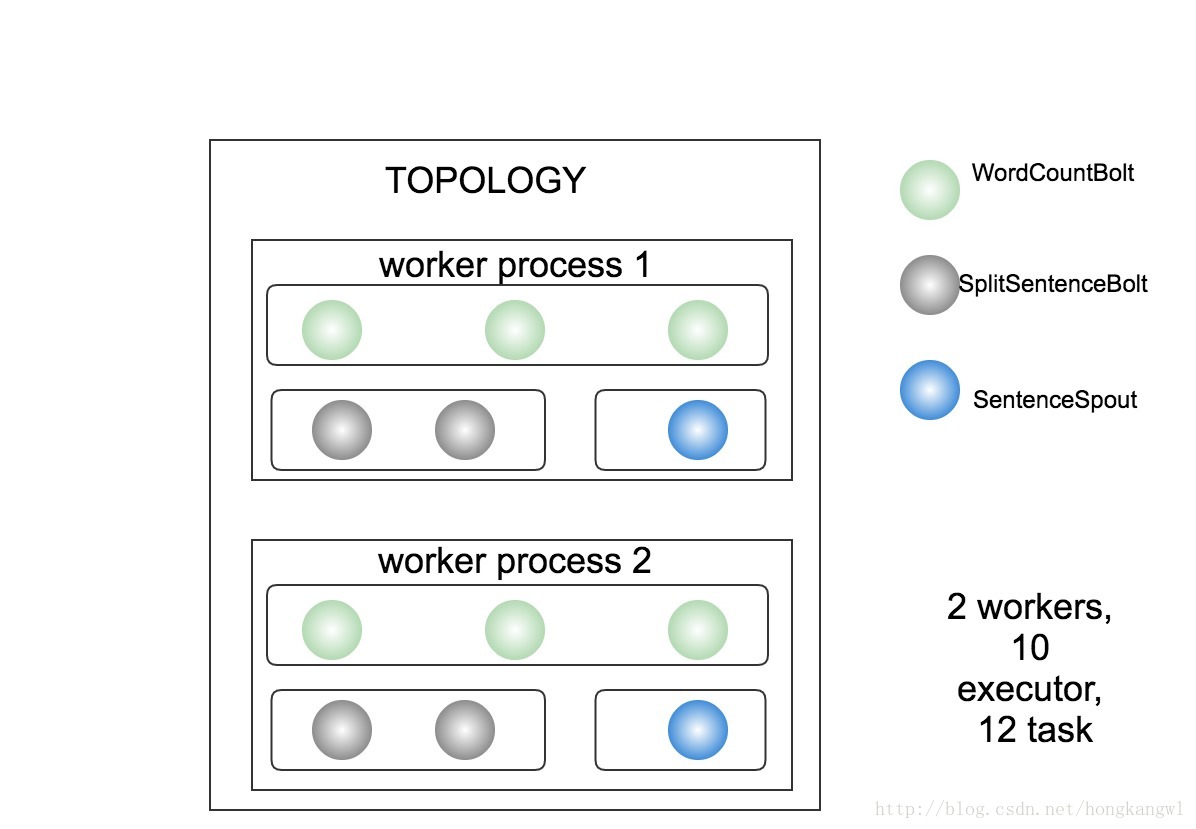
- 其共有2个worker,10个executor,带圆角的矩形为executor,共12个task(2个spout, 10个bolt)
数据流分组
- Stream Grouping,告诉topology如何在两个组件之间发送tuple 。定义一个topology的其中一步是定义每个bolt接收什么样的流作为输入。stream grouping就是用来定义一个stream应该如果分配数据给bolts上面的多个tasks
- Storm里面有7种类型的stream grouping
Shuffle Grouping
- 随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
Fields Grouping
- 按字段分组,比如,按”user-id”这个字段来分组,那么具有同样”user-id”的 tuple 会被分到相同的Bolt里的一个task, 而不同的”user-id”则可能会被分配到不同的task。
All Grouping
- 广播发送,对亍每一个tuple,所有的bolts都会收到
Global Grouping
- 全局分组,整个stream被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
None Grouping
- 不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(如果可能的话)。
Direct Grouping
- 指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
Local or shuffle grouping
- 本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致。
其他
messageId
- 这里插入讲下messageId,messageId可以标识唯一一条消息,我们通过messageId可以追踪消息的处理以及验证分组是否符合我们的预期等待。可通过tuple.getMessageId()获取messageId。
taskId
- storm中的每一个task对会对应唯一一个taskId,其可以通过topologyContext.getThisTaskId()获取。
演示
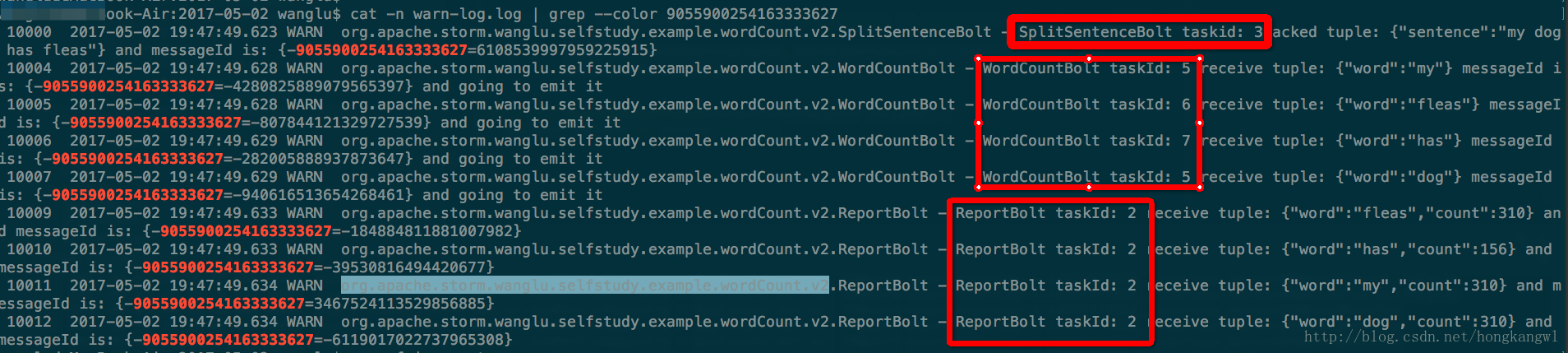
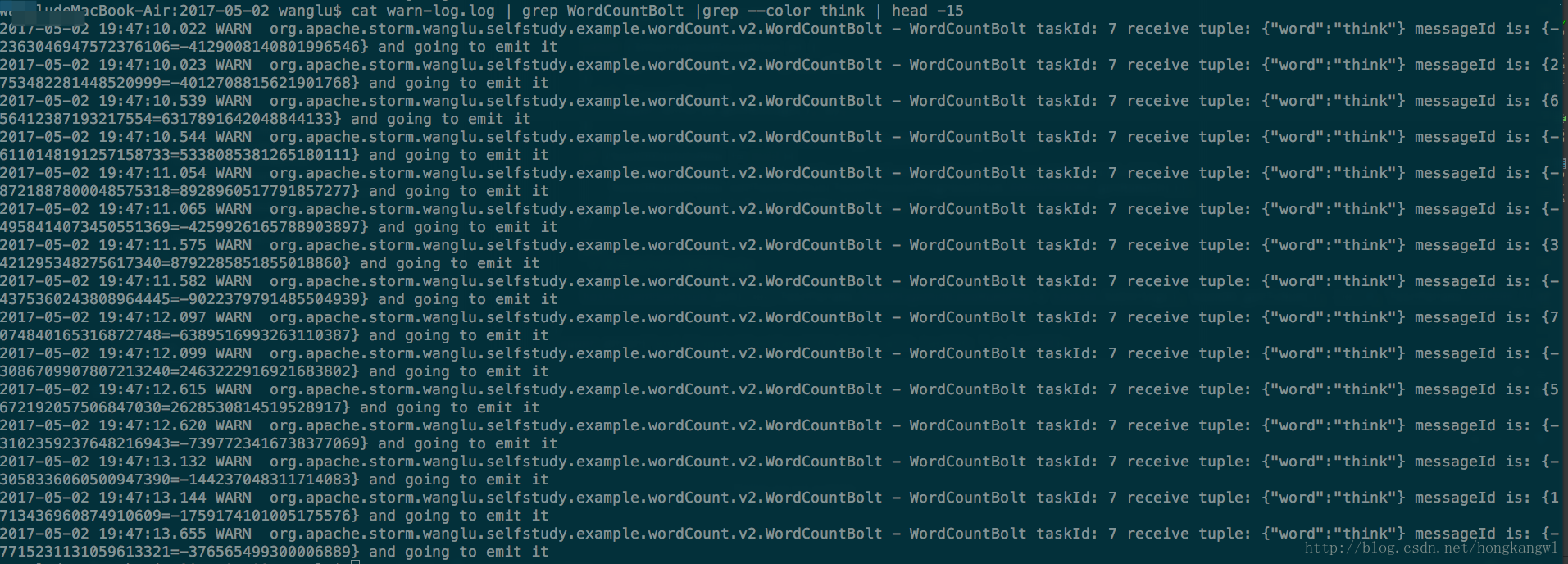
- 我们通过messageId追踪一条消息的声明周期,如下图所示。
-
-
可以清晰的看到一个语句被SplitSentenceBolt接收后并切分成单次发送给WordCountBolt,WordCountBolt接收到各单次后计算然后发送给ReportBolt进行打印。
- 由于SplitSentenceBolt split后的字段是按照fieldgroup后传递给WordCountBolt,从下图中可以看到字段相同的单次被发往同一个WordCountBolt。大家也可以换成别的单次grep下看结果。
代码
SentenceSpout
public class SentenceSpout extends BaseRichSpout {
private static final Logger logger = LoggerFactory.getLogger(SentenceSpout.class);
private ConcurrentHashMap<UUID, Values> pending;
private SpoutOutputCollector collector;
private String[] sentences = {
"my dog has fleas",
"i like cold beverages",
"the dog ate my homework",
"don't have a cow man",
"i don't think i like fleas"
};
private AtomicInteger index = new AtomicInteger(0);
private Integer taskId = null;
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
public void open(Map config, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
this.pending = new ConcurrentHashMap<UUID, Values>();
this.taskId = context.getThisTaskId();
}
public void nextTuple() {
Values values = new Values(sentences[index.getAndIncrement()]);
UUID msgId = UUID.randomUUID();
this.pending.put(msgId, values);
this.collector.emit(values, msgId);
if (index.get() >= sentences.length) {
index = new AtomicInteger(0);
}
logger.warn(String.format("SentenceSpout with taskId: %d emit msgId: %s and tuple is: %s",
taskId,
msgId,
JSONObject.toJSON(values)));
Utils.waitForMillis(100);
}
public void ack(Object msgId) {
this.pending.remove(msgId);
logger.warn(String.format("SentenceSpout taskId: %d receive msgId: %s and remove it from the pendingmap",
taskId,
JSONObject.toJSONString(msgId)));
}
public void fail(Object msgId) {
logger.error(String.format("SentenceSpout taskid: %d receive msgId: %s and remove it from the pendingmap",
taskId,
JSONObject.toJSONString(msgId)));
this.collector.emit(this.pending.get(msgId), msgId);
}
}
SplitSentenceBolt
public class SplitSentenceBolt extends BaseRichBolt {
private static final Logger logger = LoggerFactory.getLogger(SplitSentenceBolt.class);
private OutputCollector collector;
private Integer taskId = null;
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.taskId = context.getThisTaskId();
}
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words){
this.collector.emit(tuple, new Values(word));
}
this.collector.ack(tuple);
logger.warn(String.format("SplitSentenceBolt taskid: %d acked tuple: %s and messageId is: %s",
taskId,
JSONObject.toJSONString(tuple, SerializerFeature.WriteMapNullValue),
tuple.getMessageId()));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WordCountBolt
public class WordCountBolt extends BaseRichBolt {
private static final Logger logger = LoggerFactory.getLogger(WordCountBolt.class);
private OutputCollector collector;
private HashMap<String, Long> counts = null;
private Integer taskId = null;
public void prepare(Map config, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
this.counts = new HashMap<String, Long>();
this.taskId = context.getThisTaskId();
}
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(count == null){
count = 0L;
}
count++;
this.counts.put(word, count);
this.collector.ack(tuple);
logger.warn(String.format("WordCountBolt taskId: %d receive tuple: %s messageId is: %s and going to emit it",
taskId,
JSONObject.toJSONString(tuple),
tuple.getMessageId()));
this.collector.emit(tuple, new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
WordCountTopology
public class WordCountTopology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws Exception {
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
// SentenceSpout --> SplitSentenceBolt
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2)
.setNumTasks(4)
.shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
builder.setBolt(COUNT_BOLT_ID, countBolt, 6)
.fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt)
.globalGrouping(COUNT_BOLT_ID);
Config conf = JStormHelper.getConfig(null);
conf.setNumWorkers(2);
conf.setDebug(true);
boolean isLocal = true;
JStormHelper.runTopology(builder.createTopology(), TOPOLOGY_NAME, conf, 10,
new JStormHelper.CheckAckedFail(conf), isLocal);
}
}
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)