保定学院人工智能专业大数据实训手册
本文还有配套的精品资源,点击获取简介:保定学院的人工智能专业利用大数据实训作业集,提供了一系列实践教学活动,旨在深化学生对大数据处理技术和应用的理解。学生们将在实训中通过接触多个课题来提高数据处理技能,包括数据的采集、存储、处理、分析和展示。实训内容涵盖使用Hadoop、Spark等大数据工具,利用VMware创建虚拟机环境,以及使用Flume收集和传输数据。学生将完成包...

简介:保定学院的人工智能专业利用大数据实训作业集,提供了一系列实践教学活动,旨在深化学生对大数据处理技术和应用的理解。学生们将在实训中通过接触多个课题来提高数据处理技能,包括数据的采集、存储、处理、分析和展示。实训内容涵盖使用Hadoop、Spark等大数据工具,利用VMware创建虚拟机环境,以及使用Flume收集和传输数据。学生将完成包括编写Flume配置、基于Hadoop MapReduce或Spark的数据处理任务、以及通过Hive或Pig进行数据分析等在内的实际操作。该实训作业集帮助学生在实践中提高大数据处理和分析能力,为未来从事人工智能领域的工作做好准备。 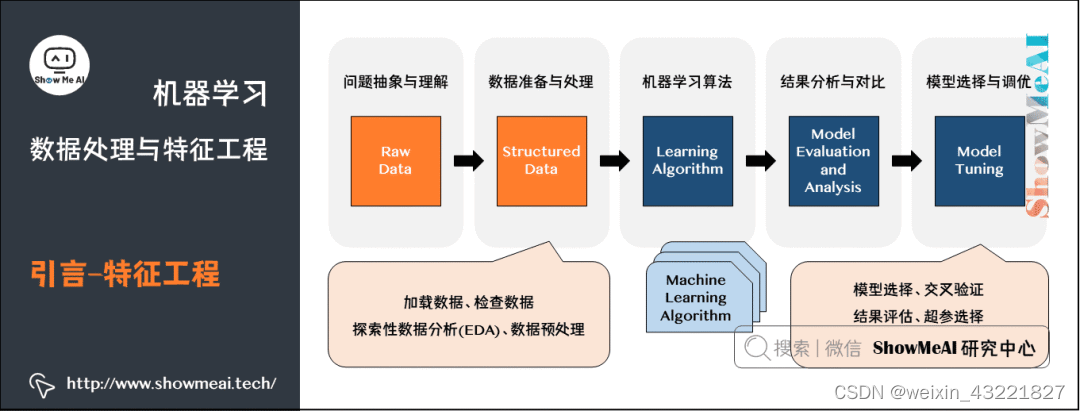
1. 大数据技术实践教学概述
大数据技术的发展,使得相关的教学内容和实践方法也在不断地更新和迭代。本章旨在为读者提供大数据技术教学的综述,以期帮助教育者和学习者更好地理解和实践大数据技术。
1.1 大数据技术教学的意义
大数据技术的教学不仅仅是对相关技术的传授,更是培养未来数据分析师和数据科学家的重要途径。掌握大数据技术,对于理解和利用海量数据进行决策分析,具有重大意义。
1.2 教学内容和方法
大数据技术教学内容包括数据采集、存储、处理、分析和可视化等多个环节。教学方法应结合理论知识与实际操作,重视案例分析,鼓励学生动手实践。
1.3 教学资源和工具
大数据教学资源丰富,从在线课程到专业图书,从开源工具到商业平台,教师和学生可选择的资源和工具种类繁多。开源工具如Hadoop、Spark等,已在大数据教学中广泛应用。
通过本章内容,我们将构建起对大数据技术教学的初步认识,为接下来深入探讨人工智能、Hadoop、Spark等具体技术在大数据教学中的应用打下基础。
2. 人工智能技术在大数据中的应用
2.1 人工智能技术基础
2.1.1 人工智能与大数据的关系
人工智能(AI)和大数据是当今IT行业的两个热门领域,它们之间的关系错综复杂,但又紧密相连。大数据提供了大量的信息资源,是AI发展的基础养料,而AI技术又是处理和分析大数据的重要手段,两者相互依赖,共同促进发展。
在大数据的背景下,AI技术可以挖掘出数据中的模式和关系,帮助我们理解数据背后隐藏的复杂现象。通过机器学习和深度学习等方法,AI系统可以从海量的数据中自我学习和适应,提高预测和决策的准确性。这不仅推动了AI技术的进步,也推动了大数据的进一步应用和发展。
2.1.2 人工智能技术的基本概念和原理
人工智能技术的核心在于模拟人类智能行为,它包括了各种子领域,例如机器学习、深度学习、自然语言处理、计算机视觉等。这些技术通过从数据中学习,进行预测或决策,从而实现自动化任务。
- 机器学习 是一种实现人工智能的方法,它使计算机系统可以从数据中学习并改进其性能,而无需进行明确的编程。
- 深度学习 是机器学习的一个分支,它使用神经网络来模仿人脑处理信息的方式,处理非结构化数据。
- 自然语言处理 (NLP)使计算机能够理解、解释和生成人类语言,是人工智能领域的重要研究方向。
2.2 人工智能技术在大数据中的应用实例
2.2.1 机器学习在大数据中的应用
机器学习在大数据中的应用广泛而深入,涵盖了金融风控、医疗诊断、市场营销等多个方面。
在金融行业,通过分析交易数据、客户行为等大数据,机器学习模型可以用于识别欺诈行为、评估信贷风险。机器学习模型能够处理大量非结构化数据,提取出有意义的特征,并做出预测。
2.2.2 深度学习在大数据中的应用
深度学习则在图像识别、语音识别、自然语言处理等领域大放异彩。它通过构建多层神经网络,处理复杂的数据结构,给出高精度的结果。
在医疗领域,深度学习可以从大量的医学影像中,快速准确地识别疾病标志,辅助医生诊断。而在自动驾驶技术中,深度学习模型通过处理视频数据,实时识别路面状况,从而指导车辆安全行驶。
2.3 人工智能技术在大数据中的发展趋势
2.3.1 人工智能技术的未来发展
随着硬件性能的不断提升和算法的不断优化,人工智能技术未来将拥有更加强大的计算能力。同时,随着大数据量的增加,AI模型将变得更加精准,其应用场景也将更加广泛。
未来人工智能的一个重要发展方向是,更加深入地理解数据的上下文含义,不仅仅是从数据中提取特征,还要理解这些特征背后的深层含义。例如,在自然语言处理中,不仅要识别词汇,还要理解句子的语义。
2.3.2 人工智能技术对大数据的影响
人工智能技术的发展对大数据产业有着深远的影响。它使得大数据分析的速度和精度得到前所未有的提升,也使得原本无法分析的复杂数据变得可处理。
此外,AI技术还推动了大数据从“批量分析”向“实时分析”的转变。通过实时数据分析,企业可以快速响应市场变化,做出即时决策。
在本章节中,我们已经了解了人工智能与大数据的密切关系,探索了人工智能的基本原理,并通过实例分析了它在大数据中的应用。接下来,我们将深入探讨Hadoop和Spark这两种大数据处理工具的应用情况。
3. Hadoop、Spark大数据处理工具的应用
3.1 Hadoop大数据处理工具的应用
3.1.1 Hadoop的基本概念和原理
Apache Hadoop 是一个开源框架,它支持数据密集型分布式应用,允许在商品硬件集群上运行应用程序,这些应用程序能够处理超大量的数据(TB级别以上)。Hadoop实现了一个分布式文件系统(HDFS),能够跨计算机存储大量数据并提供高吞吐量访问。此外,Hadoop还提供了MapReduce编程模型,用于在数据集上执行并行操作。
Hadoop架构的核心是YARN(Yet Another Resource Negotiator),它负责资源管理和任务调度。Hadoop工作原理可以分解为三个主要组件:
- HDFS:分布式文件系统,用于存储和读取数据块。
- YARN:负责集群资源管理和作业调度。
- MapReduce:一个处理数据的编程模型。
3.1.2 Hadoop的实际应用案例
Hadoop已经在多个行业中得到了广泛应用,包括金融服务、医疗保健、媒体和零售业。一个典型的应用案例是搜索引擎的后台数据处理。比如,搜索引擎公司会使用Hadoop对网页进行索引和分类,以提供快速准确的搜索结果。Hadoop的分布式处理能力使得处理海量的网页数据变得可行。
在此过程中,Hadoop集群将网页数据分散存储在HDFS中,然后利用MapReduce处理这些数据,进行词频统计、链接分析等任务。经过处理后的数据被索引并存储起来,等待用户的查询请求。
3.2 Spark大数据处理工具的应用
3.2.1 Spark的基本概念和原理
Apache Spark是另一种大数据处理工具,它在Hadoop的基础上进行了优化和扩展。Spark使用了内存计算,可以更快地处理数据,而且它的处理速度比基于磁盘的Hadoop MapReduce快很多。Spark提供了一个快速的分布式计算系统,支持各种数据处理任务,包括批处理、流处理、机器学习和图形计算。
Spark运行在YARN之上,但它自己的集群管理器也可以运行。Spark的核心概念包括弹性分布式数据集(RDDs)、数据框(DataFrames)和数据集(Datasets)。这些抽象允许Spark优化其执行计划以提高效率。
3.2.2 Spark的实际应用案例
一个著名的Spark应用案例是实时分析服务。例如,一个大型电子商务网站可能会使用Spark来处理用户的点击流数据。网站希望实时了解哪些产品最受欢迎,以便提供个性化的购物体验和优化推荐引擎。
通过Spark Streaming,该网站可以实时捕获用户的点击数据,使用Spark进行实时分析,并将分析结果用于更新推荐系统。由于Spark可以缓存数据在内存中,它能够快速处理这些实时数据,为用户生成个性化的推荐。
3.3 Hadoop与Spark的比较
3.3.1 Hadoop与Spark的优缺点比较
Hadoop和Spark各自拥有不同的优点和局限性:
-
Hadoop :适合于大规模数据的批处理作业,能够存储和处理PB级别的数据。然而,由于其依赖于磁盘的处理方式,它在处理速度上通常慢于Spark。此外,Hadoop的MapReduce编程模型比较复杂,学习曲线陡峭。
-
Spark :由于其基于内存的计算机制,Spark在处理速度上远超Hadoop。它提供了一个更为简单的API,如Spark SQL,用于处理结构化数据,支持多种数据源。然而,Spark对内存的需求较高,如果数据集太大而内存不足以存储,性能将会受到影响。
3.3.2 Hadoop与Spark的应用场景比较
选择Hadoop还是Spark,取决于特定的应用场景:
-
Hadoop :适用于不需要快速响应时间的大规模数据批处理任务。由于其成熟稳定和拥有广泛的生态系统,Hadoop适合于数据仓库和数据湖的构建,以及需要长时间运行的复杂数据处理任务。
-
Spark :在需要快速数据处理和实时分析的场景中表现得更好。在机器学习、实时数据分析和迭代算法的场合,Spark能够提供显著的性能提升。由于其易用性和灵活性,Spark也适合于数据科学家和工程师快速开发应用。
通过将两者结合使用,可以利用Hadoop的稳定性与Spark的快速处理能力,以此满足多样化的数据处理需求。
flowchart LR
A[Hadoop] -->|适合批处理| B[大规模数据批处理]
C[Spark] -->|适合实时处理| D[快速数据处理与实时分析]
B --> E[数据仓库与数据湖]
D --> F[机器学习与迭代算法]
在上述流程图中,展示了Hadoop与Spark针对不同类型处理需求的应用场景。Hadoop是批处理的首选,特别是在大规模数据仓库和数据湖的构建上,而Spark在需要实时处理的场景中,如机器学习和迭代算法,更显得游刃有余。
在本章节中,我们深入了解了Hadoop和Spark的基本概念、原理以及实际应用案例。通过对比两者的优缺点和应用场景,我们可以更好地理解如何针对特定需求选择合适的大数据处理工具。在下一章节中,我们将继续探索VMware虚拟环境的搭建与应用,以及它在大数据实训中的重要角色。
4. VMware虚拟环境搭建与应用
4.1 VMware虚拟环境搭建
4.1.1 VMware的基本概念和原理
VMware是一个虚拟机软件品牌,它通过软件来模拟计算机硬件系统,使得在一个物理硬件上可以运行多个虚拟机,每个虚拟机都像是一个完全独立的物理设备。VMware的虚拟化技术允许用户在同一台计算机上安装多个操作系统,并能实现操作系统之间的无缝切换,就如同操作一台物理计算机一样。
VMware虚拟环境的核心技术之一是虚拟化平台(Hypervisor),它分为类型1和类型2。类型1的Hypervisor直接运行在物理硬件之上,如VMware ESXi,而类型2的Hypervisor则运行在宿主机操作系统之上,如VMware Workstation和Player。虚拟化技术让每个虚拟机都有自己的虚拟硬件,包括CPU、内存、硬盘、网络接口等,实现资源隔离和独立运行。
4.1.2 VMware的搭建过程和步骤
搭建VMware虚拟环境通常分为几个主要步骤:
-
硬件需求确认 :确定主机的CPU支持Intel VT-x或AMD-V虚拟化技术,以及足够的内存和存储空间。
-
选择VMware软件 :根据实际需求选择合适的VMware产品,如VMware Workstation Pro、VMware Player或企业级的VMware ESXi。
-
下载和安装VMware软件 :前往VMware官方网站下载所需的软件版本,并按照官方指导手册完成安装过程。
-
创建新的虚拟机 :打开VMware软件,选择创建新的虚拟机,然后按向导步骤进行操作系统安装,例如选择“自定义(高级)”配置。
-
配置虚拟机硬件 :为虚拟机配置处理器数量、内存大小、网络类型、硬盘大小等资源。
-
安装操作系统 :插入操作系统安装介质(如ISO文件),按照提示进行操作系统的安装。
-
安装VMware Tools :在虚拟机操作系统安装完成后,安装VMware Tools以优化性能和管理虚拟机。
-
测试和配置网络 :确保虚拟机的网络设置正确,能够连接到外部网络。
-
使用VMware虚拟环境 :完成上述步骤后,就可以在虚拟机上进行各种实验和操作。
下面是一个示例代码块,展示如何在VMware Workstation上创建一个新的虚拟机。
# 注意:本代码仅为示例,不是真实的命令行操作代码。
vmware createvm --name "UbuntuServer" --location "/path/to/ubuntu.iso" --type "linux" --version "ubuntu64" --datastore "LocalDS_0"
vmware modifyvm --name "UbuntuServer" --memory 2048 --cpus 2
vmware startvm --name "UbuntuServer"
请注意,这个示例并不反映VMware Workstation的真实命令,因为VMware Workstation主要通过图形用户界面(GUI)进行操作,而不是命令行接口(CLI)。实际上,大多数虚拟机操作在VMware中都是通过图形界面来完成的,而不是命令行。
4.2 VMware虚拟环境的应用
4.2.1 VMware在大数据实训中的应用
在大数据实训的场景中,VMware可以用来创建多个虚拟机,每台虚拟机可以配置成不同的角色,例如一个作为Hadoop集群的Master节点,其他的作为Slave节点。这种设置对于学习Hadoop、Spark等大数据处理工具非常有用,因为它允许学生在一个隔离的环境中尝试安装和配置大数据集群,而不会影响到宿主机或其他应用程序。
4.2.2 VMware的优缺点和应用场景
VMware在虚拟化技术方面具有很多优点,例如:
- 稳定性和可靠性 :VMware虚拟机运行稳定,故障率低,能够提供长时间的连续服务。
- 高性能 :对于计算密集型任务,VMware的性能接近物理机。
- 多平台支持 :能够在Windows、Linux等不同平台上运行。
- 强大的网络功能 :VMware提供了灵活的网络配置选项,支持多种网络模式。
然而,VMware也有一些不足:
- 成本问题 :相比一些开源的虚拟化解决方案,VMware的商业版本可能会涉及较高的许可费用。
- 复杂性 :对于初学者来说,VMware的设置和配置可能会显得复杂。
应用场景方面,VMware适合以下场景:
- 企业级部署 :对于需要高度稳定性和强大技术支持的环境。
- 教育和培训 :在教学和实验环境中创建隔离的系统以供学习。
- 应用开发和测试 :开发人员可以在安全的虚拟环境中测试和部署应用程序。
以上概述了VMware虚拟环境搭建与应用的各个方面,从基本概念到实际应用,再到VMware在大数据实训中的实际应用案例。这一章节为读者提供了一个全面的视角来了解和应用VMware虚拟环境。
5. Flume数据采集系统应用
Flume作为Apache的一个子项目,是一个分布式、可靠且可用的系统,用于有效地收集、聚合和移动大量日志数据。其设计灵感来源于一个简单、可靠的流式架构,它基于流式数据模型,能够从不同的源收集数据,并将其高效地传送到目的地。
5.1 Flume数据采集系统概述
5.1.1 Flume的基本概念和原理
Flume的基本工作原理是基于事件驱动的。一个事件被定义为一条数据记录,例如网络日志、文件中的日志条目、事件日志等。Flume中的数据流通过源(Sources)进行收集,通过通道(Channels)进行暂存,并最终传送到目的地(Sinks)。
Flume架构的主要组件包括:
- 源(Source) :数据输入点,能够从不同的源中收集数据,例如文件、网络等。
- 通道(Channel) :暂存数据流的临时存储区域,它确保了数据传输的可靠性。即使系统出现故障,Flume也能够保证数据不会丢失。
- 目的地(Sink) :数据的输出点,将数据从通道中取出并移送到下一个处理系统。
5.1.2 Flume的数据采集过程和原理
数据采集过程遵循一个简单的“拉取”模型:
- 源(Source)负责监听数据源并将捕获的数据封装成事件。
- 事件被发送到通道(Channel),通道作为数据的暂存站,其目的是将源(Source)和目的地(Sink)解耦。
- 目的地(Sink)从通道(Channel)中取出事件,并将其发送到配置的目的地,如HDFS、数据库等。
由于Flume具有容错性,即使在某一阶段出现故障,数据仍然可以在通道内存或磁盘中保留,并在恢复正常后继续传输。
5.2 Flume数据采集系统的应用
5.2.1 Flume在大数据实训中的应用
在大数据实训中,Flume通常用于日志数据的实时采集。例如,开发人员可以在Web服务器上配置Flume源来监听访问日志,并通过Flume通道将这些日志数据实时传输到Hadoop的HDFS中。这个过程可以保证日志数据被及时存储,并为后续的大数据分析提供实时数据支持。
5.2.2 Flume的优缺点和应用场景
优点 :
- 可靠性和容错性 :Flume保证了数据传输的可靠性,即使在传输过程中遇到系统故障,数据也不会丢失。
- 可扩展性 :Flume支持集群模式,能够通过增加更多的Flume代理来水平扩展数据采集能力。
- 灵活性 :Flume允许用户自定义数据流向,可以定义多个源、通道和目的地,并以任意顺序组合它们来满足复杂的采集需求。
缺点 :
- 配置复杂性 :对于新手来说,配置Flume较为复杂,需要理解各个组件之间的关系。
- 性能开销 :由于Flume采用的是内存和磁盘双重保障的机制,可能会带来一定的性能开销。
应用场景 :
Flume非常适合于日志数据的实时采集,尤其是对于需要高性能和高可靠性的应用场景,比如网络服务的日志收集、实时分析系统的数据输入等。此外,Flume还可以作为其他数据采集系统的补充,集成到更复杂的生态系统中。
5.3 Flume的具体操作示例
5.3.1 配置Flume采集环境
为了使用Flume,需要编写一个配置文件,该文件定义了源、通道和目的地。以下是一个简单的配置示例:
# Define a source
agent.sources = r1
agent.sources.r1.type = ***
***mand = tail -F /var/log/mylog.log
# Define a channel
agent.channels = c1
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
# Define a sink
agent.sinks = k1
agent.sinks.k1.type = hdfs
agent.sinks.k1.hdfs.path = hdfs://namenode/path/to/flume/events/%y-%m-%d/%H%M/%S
agent.sinks.k1.hdfs.fileType = DataStream
agent.sinks.k1.hdfs.writeFormat = Text
# Bind the source and the sink to the channel
agent.sources.r1.channels = c1
agent.sinks.k1.channel = c1
这个配置文件定义了一个Flume代理,它从 /var/log/mylog.log 文件中收集日志,并将其写入HDFS。
5.3.2 执行和监控Flume代理
启动Flume代理的命令如下:
flume-ng agent --conf /path/to/flume/conf --conf-file /path/to/flume.conf --name agent
为了监控Flume代理的状态,可以使用以下命令:
flume-ng admin --conf /path/to/flume/conf --代理名 agent --list
flume-ng admin --conf /path/to/flume/conf --代理名 agent --show-config
以上步骤展示了如何配置和运行一个简单的Flume代理,用于实时采集日志数据,并存储到HDFS中。对于实际应用,根据数据源的不同,Flume的配置可能会更加复杂。此外,Flume还提供了丰富的扩展机制,以满足不同的数据采集需求。
6. HDFS分布式文件系统管理和数据处理
Hadoop分布式文件系统(HDFS)是Hadoop项目的核心组件,它是一种高度容错的系统,适合在廉价硬件上运行。HDFS为大数据存储提供了高吞吐量,使得数据的分布式存储成为可能。接下来,我们将深入探讨HDFS的管理以及如何进行数据处理。
6.1 HDFS分布式文件系统管理
6.1.1 HDFS的基本概念和原理
HDFS是一个高度容错的分布式文件系统,适合运行在普通硬件上。它能存储超大文件,支持高吞吐量的数据访问。HDFS的设计理念是将大数据分成块(block)进行存储,每个块默认大小为128MB(可配置),并跨多个数据节点(DataNode)进行复制,以实现数据的冗余备份。
HDFS有两部分组成:一个主节点(NameNode)和多个数据节点(DataNode)。NameNode负责管理文件系统的命名空间和客户端对文件的访问;DataNode则负责存储实际的数据。
6.1.2 HDFS的文件存储和管理过程
在HDFS中存储文件涉及以下几个步骤:
- 文件切分成块:文件被切分成若干块,块大小可以通过配置文件进行定义。
- 副本存储:每个块会被复制存储到多个DataNode上,通常默认的副本数量为3,以确保数据的可靠性和高可用性。
- 元数据存储:NameNode保存文件系统的元数据信息,如文件和块的映射关系,块在各个DataNode的存储位置等。
- 命名空间管理:NameNode还管理文件系统的命名空间,包括文件的创建、删除和重命名等操作。
6.2 数据处理与分析实战任务
6.2.1 数据处理与分析的基本方法和步骤
在HDFS上进行数据处理与分析,通常涉及以下步骤:
- 数据上传:使用
hadoop fs -put命令将本地文件上传到HDFS中。 - 数据预处理:使用Hive或Pig等工具进行数据的清洗、转换等预处理操作。
- 数据分析:应用MapReduce程序进行数据分析。
- 数据存储:将处理结果存储回HDFS,或导出到本地文件系统。
6.2.2 数据处理与分析的实际操作和应用
数据处理与分析的实际操作可以通过编写MapReduce程序来实现。以下是一个简单的MapReduce程序的框架:
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
在上述示例中,我们通过MapReduce程序对文本数据进行单词计数的操作。
6.3 编写数据处理报告和结果解读
6.3.1 数据处理报告的编写方法和步骤
编写数据处理报告通常包括以下几个步骤:
- 引言:简述数据处理的目的和背景。
- 数据描述:描述数据来源、数据类型和数据规模。
- 数据处理方法:详细说明使用的工具和技术,如MapReduce程序设计。
- 结果展示:使用图表和文字描述分析结果。
- 结论和建议:基于分析结果提出结论和改进建议。
6.3.2 数据处理结果的解读和应用
对于数据处理的结果,需要根据数据本身的特性和业务需求进行深入解读。例如,在单词计数结果中,我们可以发现数据中的关键词或高频词汇,进而分析文本数据所表达的主题或趋势。
通过解读分析结果,我们可以对业务过程进行优化,例如在搜索引擎中优化关键词的搜索权重,或在市场分析中调整产品策略。
根据上述章节的介绍和操作步骤,相信读者已经对HDFS的管理、数据处理以及分析报告编写有了一定的了解。通过实践操作,可以进一步加深对大数据技术的认识,并将理论应用于实际工作中。
简介:保定学院的人工智能专业利用大数据实训作业集,提供了一系列实践教学活动,旨在深化学生对大数据处理技术和应用的理解。学生们将在实训中通过接触多个课题来提高数据处理技能,包括数据的采集、存储、处理、分析和展示。实训内容涵盖使用Hadoop、Spark等大数据工具,利用VMware创建虚拟机环境,以及使用Flume收集和传输数据。学生将完成包括编写Flume配置、基于Hadoop MapReduce或Spark的数据处理任务、以及通过Hive或Pig进行数据分析等在内的实际操作。该实训作业集帮助学生在实践中提高大数据处理和分析能力,为未来从事人工智能领域的工作做好准备。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 29
29 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容
 免费领云主机
免费领云主机


 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)