《Kubernetes与云原生应用》系列之六——容器设计模式实践案例:工作队列模式
原文转自InfoQK8s与容器设计模式目前,K8s社区推出的容器设计模式主要分为三大类:第一类,单容器管理模式第二类,单节点多容器模式第三类,多节点多容器模式一类比一类更复杂。根据复杂性的不同,本系列文章给出不同篇幅的实践案例介绍。 所有在云计算平台上运行的应用业务都可以分成两大类,即长时运行服务和批处理业务。工作队列模式是一系列容器设计模式中,第一个面向批处理业务
K8s与容器设计模式
目前,K8s社区推出的容器设计模式主要分为三大类:
第一类,单容器管理模式
第二类,单节点多容器模式
第三类,多节点多容器模式
一类比一类更复杂。根据复杂性的不同,本系列文章给出不同篇幅的实践案例介绍。
所有在云计算平台上运行的应用业务都可以分成两大类,即长时运行服务和批处理业务。工作队列模式是一系列容器设计模式中,第一个面向批处理业务的模式,在K8s集群中,以API对象Job为基础处理批处理任务。本文将借助示例介绍多节点多容器模式中的工作队列模式。
工作队列模式
分布式系统的一个重要作用是能够充分利用多个物理计算资源的能力,特别是在动态按需调动计算资源完成计算任务。设想如果有大量的需要处理的任务随即的到来,对计算资源需要的容量是不确定的;显然,按照最大可能计算量和最小可能计算量设置计算节点都是不合理的。这种情况下,可以把需要处理的任务放到一个待处理的队列里,根据需要启动计算节点从队列读取任务进行处理。在容器技术广泛应用之前,也有诸多的分布式处理系统依靠队列来处理大量计算任务,例如大数据处理系统Hadoop和Spark等。这些系统的一个限制是实现队列处理模式大多要遵循特定的编程模式和特定的编程语言,同时搭建基础设施也大多复杂而耗时。而基于容器和Kubernetes编排技术的工作队列模式的好处在于,利用非常简单的编排脚本就可以实现工作队列模式,而用Pod作为轻量级处理节点的模式,使得动态的调度计算资源变得非常容易。
在K8s中应用工作队列模式的逻辑示意图如下。在K8s集群中,可以启动一个队列服务,用来存储等待处理的任务。这种队列可以用通用的消息队列RabbitMQ,ActiveMQ或Kafka来实现,也可以用Redis这类支持集合存储的内存数据库实现。
向工作队列输入待处理任务的是工作队列前端服务,这可以是一个REST服务,一个可视化的界面服务,也可以是一个可以提交任务的命令行或客户端API。无论是何种,工作队列前端服务的作用是向工作队列添加任务。真正处理任务的是包含了应用程序的应用Pod。由于在K8s中,Pod有能力支持多容器,这使得在同一个Pod中,从工作队列里读取任务的容器和处理任务的容器可以来自不同的容器镜像,其中处理应用任务的容器根据不同的任务各不相同,而读取任务的容器是可以在任何应用处理中重用的。正如图Fig01所显示的,在这样一个工作队列模式的分布式系统中,工作队列服务、工作队列前端服务、工作队列读取容器这几个模块都是可以重用的,只有跟具体应用工作处理相关的部分要根据不同应用编写。
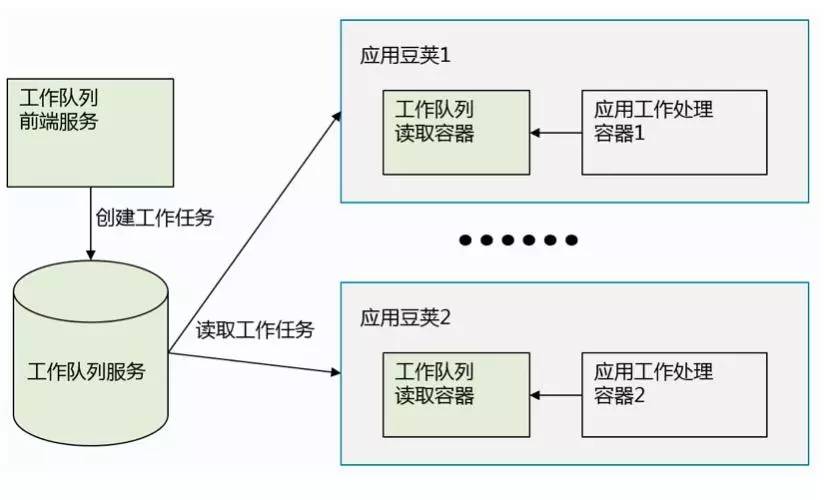
利用Redis作为工作队列验证工作队列模式
本文用一个简单案例来展示在K8s集群中应用工作队列模式的方法。在K8s集群中用Job这个API对象来执行批处理任务,如下图所示。我们创建一个Job用来处理工作任务,它会产生Job Controller并控制生成多个处理任务的Pod。同时,我们创建一个Redis Pod和一个Service用来存储工作任务。为了向工作队列输入任务和察看工作队列中的任务,我们创建一个redis-cli pod作为客户端操作工作队列。
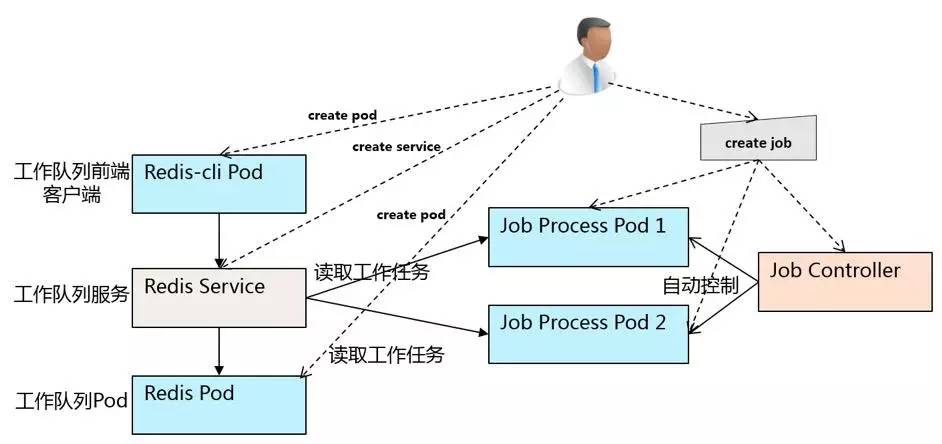
本文案例代码
用于操作Redis队列的python代码清单
#!/usr/bin/env python
import redis
import uuid
import hashlib
class RedisWQ(object):
def __init__(self, name, **redis_kwargs):
self._db = redis.StrictRedis(**redis_kwargs)
self._session = str(uuid.uuid4())
self._main_q_key = name
self._processing_q_key = name + ":processing"
self._lease_key_prefix = name + ":leased_by_session:"
def sessionID(self):
return self._session
def _main_qsize(self):
return self._db.llen(self._main_q_key)
def _processing_qsize(self):
return self._db.llen(self._processing_q_key)
def empty(self):
return self._main_qsize() == 0 and self._processing_qsize() == 0
def _itemkey(self, item):
return hashlib.sha224(item).hexdigest()
def _lease_exists(self, item):
return self._db.exists(self._lease_key_prefix + self._itemkey(item))
def lease(self, lease_secs=60, block=True, timeout=None):
if block:
item = self._db.brpoplpush(self._main_q_key, self._processing_q_key, timeout=timeout)
else:
item = self._db.rpoplpush(self._main_q_key, self._processing_q_key)
if item:
itemkey = self._itemkey(item)
self._db.setex(self._lease_key_prefix + itemkey, lease_secs, self._session)
return item
def complete(self, value):
self._db.lrem(self._processing_q_key, 0, value)
itemkey = self._itemkey(value)
self._db.delete(self._lease_key_prefix + itemkey, self._session)在这个Python文件中定义了RedisWQ类,用来操作Redis的队列。在创建RedisWQ对象的时候,会传入所要连接的Redis的主机URL和队列名称。在类RedisWQ中定义了lease方法,用来锁定队列中的一个任务,这样可以保证每个任务只被一个Pod处理,在处理时,任务被这个Pod锁定,其它Pod就不会再取得这个任务进行处理了。在处理完成后,处理的Pod调用complete方法,标志这个任务已经被处理完的同时,将这个任务从队列中删除。为了保证同一个任务不被一个Pod永远锁定,在调用lease方法时,同时可以设置一个过期时间,超过这个过期时间,万一正在处理的Pod已经死掉了,队列可以自己解锁这个任务,让其它Pod来处理。
调用RedisWQ来处理任务的代码
#!/usr/bin/env python
import time
import rediswq
#host="redis"
import os
host = os.getenv("REDIS_SERVICE_HOST")
job = os.getenv("REDIS_JOB_NAME")
print("host=" + str(host))
def processQueue(host):
print("Process started")
q = rediswq.RedisWQ(name=job, host=host)
print("Worker with sessionID: " + q.sessionID())
print("Initial queue state: empty=" + str(q.empty()))
while not q.empty():
item = q.lease(lease_secs=10, block=True, timeout=2)
if item is not None:
itemstr = item.decode("utf=8")
print("Working on " + itemstr)
time.sleep(10) # Put your actual work here instead of sleep.
q.complete(item)
else:
print("Waiting for work")
print("Process finished")
processQueue(host)
print("Queue empty, exiting")利用rediswq.py和work.py,我们可以构建一个容器镜像,这个镜像专门用来处理Redis队列中的任务。本文作者已经构建了一个镜像在Docker hub的景象仓库xwangqingyuan/rediswq。该镜像的Dockerfile如下:
FROM python
RUN pip install redis
COPY ./worker.py /worker.py
COPY ./rediswq.py /rediswq.py
CMD python worker.py用Redis准备任务工作队列
用于创建Redis Pod的yaml文件清单。
apiVersion: v1
kind: Pod
metadata:
labels:
name: redis
name: redis
spec:
containers:
- name: master
image: kubernetes/redis:v1
env:
- name: MASTER
value: "true"
ports:
- containerPort: 6379
resources:
limits:
cpu: "0.1"
volumeMounts:
- mountPath: /redis-master-data
name: data
volumes:
- name: data
emptyDir: {}用kubectl create命令创建一个Redis的Service
# kubectl create -f /gitws/github.com/xwangqingyuan/kube-templates/examples/job/redis-service.yaml 用kubectl run命令启动一个Redis作为客户端操作Redis队列
# kubectl run -i --tty temp --image redis --command "/bin/sh"在Redis客户端用rpush命令向工作队列Job中添加工作任务,我们添加5个任务
# redis-cli -h 10.0.0.180
10.0.0.180:6379> rpush job "apple"
(integer) 1
10.0.0.180:6379> rpush job "banana"
(integer) 2
10.0.0.180:6379> rpush job "cherry"
(integer) 3
10.0.0.180:6379> rpush job "date"
(integer) 4
10.0.0.180:6379> rpush job "fig"
(integer) 5在Redis客户端用lrange命令查看工作队列job中的任务,我们可以查询到5个任务
10.0.0.180:6379> lrange job 0 -1
1) "apple"
2) "banana"
3) "cherry"
4) "date"
5) "fig"用rediswq镜像处理工作队列任务
我们在同一个K8s的namespace里,创建一个Job,来处理工作队列中的任务,处理任务的Job的Yaml文件清单如下:
apiVersion: batch/v1
kind: Job
metadata:
name: job-wq-1
spec:
parallelism: 2
template:
metadata:
name: job-wq-1
spec:
containers:
- name: c
image: xwangqingyuan/rediswq
env:
- name: REDIS_SERVICE_HOST
value: "10.0.0.180"
- name: REDIS_JOB_NAME
value: "job"
restartPolicy: OnFailure我们用kubectl create命令创建一个Job
# kubectl create -f /gitws/github.com/xwangqingyuan/kube-templates/examples/job/job.yaml查看Job的处理结果
首先,利用kubectl describe命令,查看对应job-wq-1的两个pod的名字,我们看到分别为job-wq-1-45qeb和job-wq-1-dpnnj
# kubectl describe jobs/job-wq-1
Name: job-wq-1
Namespace: default
Image(s): xwangqingyuan/rediswq
Selector: controller-uid=c264f9ab-8efc-11e6-a013-c6d712fdf0e2
Parallelism: 2
Completions: <unset>
Start Time: Mon, 10 Oct 2016 23:18:12 +0800
Labels: <none>
Pods Statuses: 2 Running / 0 Succeeded / 0 Failed
No volumes.
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
17s 17s 1 {job-controller } Normal SuccessfulCreate Created pod: job-wq-1-45qeb
17s 17s 1 {job-controller } Normal SuccessfulCreate Created pod: job-wq-1-dpnnj然后,我们用kubectl logs命令,分别察看两个pod的日志。在日志中,我们可以看到两个pod分别处理的任务:job-wq-1-45qeb处理了fig、cherry和apple,而job-wq-1-dpnnj处理了date和banana,两个加起来刚好处理了所有的工作任务。
# kubectl logs pods/job-wq-1-45qeb
host=10.0.0.180
Process started
Worker with sessionID: 6737e166-3350-476d-bf71-ec37ecb273b6
Initial queue state: empty=False
Working on fig
Working on cherry
Working on apple
Process finished
Queue empty, exiting# kubectl logs pods/job-wq-1-dpnnj
host=10.0.0.180
Process started
Worker with sessionID: d9f3711b-4323-4c97-99c3-4d96b1013bd9
Initial queue state: empty=False
Working on date
Working on banana
Waiting for work
Waiting for work
Process finished
Queue empty, exiting然后,我们在管理Redis工作队列的客户端上,用lrange命令查看当前工作队列Job的任务数量,可以发现所有任务已经被处理完了。
# lrange job 0 -1
(empty list or set)总结
本文主要介绍了K8s集群中,多节点容器模式中的工作队列模式。工作队列模式,是分布式计算系统的一种基本的工作模式,通过将待处理的任务放入队列,由应用处理模块自发去队列里读取任务并处理任务,提交任务请求的模块和处理任务请求的模块之间得到了解耦。在K8s系统中,原生用Job API对象来支持批处理任务选举的目的,Job控制器可以控制同时执行任务的工作Pod数量。
由于在一个节点上启动一个Pod来处理任务要比分配一整个节点来处理任务开销小得多,基于K8s的工作队列模式比传统基于物理机或虚拟机的分布式工作队列处理系统更加敏捷高效。另一方面,因为Pod支持多容器组合的模式,使得工作队列任务获取模块和应用逻辑处理模块可以独立交付但组合部署,增强了工作队列模式中的模块重用性。
F&Q
Q:Kubernetes集群有一个很大的问题,就是镜像的分发和加载,服务很多的时候,比如pod要升级,加载的镜像会很大,本地的容量会不够,这会涉及一个定期清理的问题。有没有什么解决方案?
王昕:最新的Kubernetes已经支持垃圾收集功能Garbage Collection。可以设置磁盘容量的限额,例如90%,触发垃圾收集,回收不用的容器和镜像所占用的空间。基于K8s自身的机制处理这个问题会比较安全。因为自己处理可能很复杂而且有可能造成误删依赖镜像的错误。当然从长期自动化运维的角度出发,可以在k8s的垃圾回收基础上,结合对节点存储和镜像情况的监控,给管理员一个比较全面的空间监控展示。例如集成磁盘的监控告警,在k8s的GC基础上二次开发一些工具,允许管理员方便的设置垃圾回收的门限等。
Q:这种队列可以用通用的消息队列RabbitMQ,ActiveMQ或Kafka来实现,也可以用Redis。为什么这里选用了Redis,Redis有什么优势?
王昕:Redis本质上是用来做缓存的,一般来说并不用来做消息队列使用。实际生产中用RabbitMQ,ActiveMQ或Kafka较好,本文中用Redis主要是因为Redis比较简单,容易搭建管理。另外笔者公司多处地方都用Redis,比较喜欢也比较熟悉这个。对于喜欢和熟悉Redis的公司来说,Redis可以发展出很多种用途,很多互联网公司可能也是这样。本文中的案例相当于试验演示作用,是一个说明工作队列模式的简单案例。生产环境中消息队列一般主要还是用通用的消息队列中间件RabbitMQ,ActiveMQ或Kafka等来实现。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)