【Linux】BPF学习笔记 - 技术背景[2]
【BPF】学习笔记 - 技术背景[2]本学习笔记来自于阅读 Brendan Gregg的《BPF Performance Tools》一、CLASSICAL BPF (BPF)用户使用针对BPF虚拟机的指令集(也称为BPF字节码)定义过滤器表达式, 然后传递给内核以供解释器执行. 这使得过滤可以在内核级别进行,而无需将每个数据包复制到用户级别的进程中, 提升了tcpdump使用的数据包筛选的...
本学习笔记来自于阅读 Brendan Gregg的《BPF Performance Tools》
一、CLASSICAL BPF (BPF)
用户使用针对BPF虚拟机的指令集(也称为BPF字节码)定义过滤器表达式, 然后传递给内核以供解释器执行. 这使得过滤可以在内核级别进行,而无需将每个数据包复制到用户级别的进程中, 提升了tcpdump使用的数据包筛选的性能.
它还提供了安全性,因为可以在执行之前验证用户空间中不受信任的筛选器的安全性.

# 打印出用于过滤器表达式的BPF指令
tcpdump -d host 127.0.0.1 and port 80
# output
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 18
(002) ld [26]
(003) jeq #0x7f000001 jt 6 jf 4
(004) ld [30]
[...]
最初的BPF (classical BPF) 是一台有限的虚拟机, 它有两个寄存器, 一个由十六个存储插槽组成的暂存存储器 以及 一个程序计数器. 这些都以 32-bit 寄存器大小运行. 自从将BPF添加到Linux内核以来,已有一些重要的改进.
- Linux 3.0中添加了BPF即时(JIT)编译器, 从而提高了解释器的性能
- 2012年为 seccomp (安全计算) 系统调用策略添加了BPF过滤器, 这是BPF在
networking外部的首次使用,并显示了将BPF用作通用执行引擎的潜力
二、EXTENDED BPF (EBPF)
EBPF将使BPF扩展成为通用虚拟机, 它添加了更多的寄存器,从 32-bit 改为 64-bit. 另外, 创建了灵活的BPF “map” 存储,并允许调用某些受限制的内核功能.
它还设计成通过一对一映射到 native 指令和寄存器进行JIT,从而允许将先前的 native指令优化技术重新用于BPF。 BPF验证程序也进行了更新以处理这些扩展,并拒绝任何不安全的代码
1. 运行时体系机构
Linux BPF运行时的体系结构如下图所示,显示了BPF指令如何通过BPF验证程序以由BPF虚拟机执行。
BPF虚拟机实现同时具有解释器和JIT编译器:JIT编译器生成用于直接执行的本机指令。 验证者拒绝不安全的操作,包括无界的循环: BPF程序必须在有界的时间内完成。
BPF可以利用帮助程序来获取内核状态,并使用BPF映射来进行存储。 BPF程序在事件中执行,这些event包括kprobes,uprobes和tracepoint

2. 为什么性能工具要使用BPF
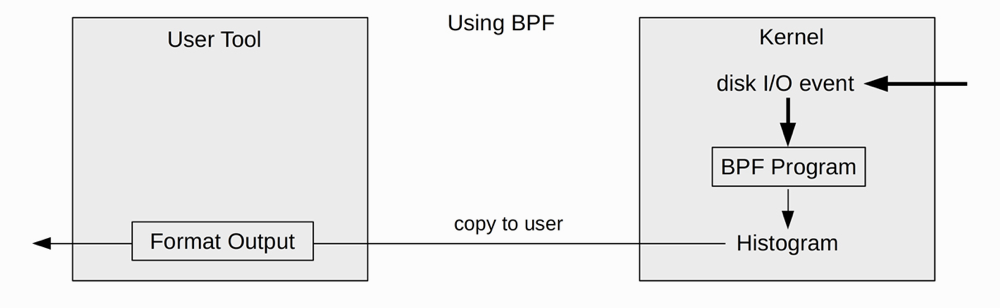
性能工具使用BPF来实现其可编程性, BPF程序可以执行自定义等待时间计算和统计摘要。另外它还高效且生产安全,并且内置于Linux内核中。 使用BPF,可以在生产环境中运行这些工具,而无需添加任何新的内核组件。
举例说明: bitehist以直方图的形式显示磁盘I/O
bitehist
Tracing block device I/O... Interval 5 secs. Ctrl-C to end.
kbytes : count distribution
0 -> 1 : 3 | |
2 -> 3 : 0 | |
4 -> 7 : 3395 |************************************* |
[...]
Before BPF: 步骤2-4对于高I/O系统具有高性能开销。例如, 每秒将一万个磁盘I/O跟踪记录传输到用户空间程序以进行分析和汇总
内核中
- 启用对磁盘I/O事件的插桩
- 对于每个事件, 将一条记录写入
perf buffer如果使用跟踪点(首选),则记录包含有关磁盘I/O的元数据的几个字段
用户空间中
-
定期将所有事件的缓冲区复制到用户空间
-
遍历每个事件,为字节字段解析事件元数据,其他字段将被忽略
-
生成字节字段的直方图(
Histogram)摘要

Using BPF: 关键的变化是直方图可以在内核中生成,避免了将事件复制到用户空间并对其进行重新处理的成本, 还避免了复制未使用的元数据字段。从而大大减少了复制到用户空间的数据量。
内核中
- 启用对磁盘I/O事件的插桩,并附加一个由bitesize定义的BPF程序
- 对于每个事件, 运行BPF程序. 它仅获取字节字段,并将其保存到自定义BPF映射直方图中
用户空间
- 一次读取BPF映射直方图并打印出来
3. 对比内核模块
使用BPF而不是内核模块进行跟踪的好处是
- BPF程序通过验证程序进行检查; 内核模块可能会引入错误或安全漏洞
- BPF通过
map提供了丰富的数据结构 - BPF程序可以编译一次,然后在任何地方运行,因为BPF指令集,map,帮助程序和基础结构是稳定的ABI
- BPF程序不需要编译内核构建工件
- BPF编程比开发内核模块所需的内核工程更容易学习,使更多的人可以使用它
使用内核模块好处是
- 可以使用其他内核功能和设施,而不仅限于BPF helper 调用
三、bpftool
在Linux 4.15中添加了bpftool来查看和操作BPF对象,包括程序和map
1. bpftool
默认输出显示bpftool操作的对象类型
bpftool
# output
Usage: bpftool [OPTIONS] OBJECT { COMMAND | help }
bpftool batch file FILE
bpftool version
OBJECT := { prog | map | cgroup | perf | net | feature | btf }
OPTIONS := { {-j|--json} [{-p|--pretty}] | {-f|--bpffs} |
{-m|--mapcompat} | {-n|--nomount} }
每个OBJECT都有一个单独的帮助页面, 例如: bpftool prog help
2.bpftool perf
该指令显示了通过perf_event_open()附加的BPF程序
bpftool perf
# output: shows three different PIDs with various BPF programs.
pid 1765 fd 6: prog_id 26 kprobe func blk_account_io_start offset 0
pid 1765 fd 8: prog_id 27 kprobe func blk_account_io_done offset 0
pid 1765 fd 11: prog_id 28 kprobe func sched_fork offset 0
[...]
prog_id是BPF的 program ID,可以使用以下命令来打印
3. bpftool prog show
列出了bpftrace的program ID (232), BCC的program ID (263) 以及其他BPF programs.
请注意,BCC kprobe程序具有BPF类型格式(BTF)信息,此输出中存在btf_id来显示该信息
bpftool prog show
# output
[...]
232: kprobe name END tag b7cc714c79700b37 gpl
loaded_at 2019-06-18T21:29:26+0000 uid 0
xlated 168B jited 138B memlock 4096B map_ids 130
[...]
258: cgroup_skb tag 7be49e3934a125ba gpl
loaded_at 2019-06-18T21:31:27+0000 uid 0
xlated 296B jited 229B memlock 4096B map_ids 153,154
[...]
263: kprobe name trace_req_done tag d9bc05b87ea5498c gpl
loaded_at 2019-06-18T21:37:51+0000 uid 0
xlated 912B jited 567B memlock 4096B map_ids 158,157
btf_id 5
[...]
4. bpftool prog dump xlated
每个BPF程序都可以通过其ID打印dump, xlated模式将打印转换为汇编的BPF指令.
输出显示了BPF可以使用的受限内核调用之一: bpf_probe_read()
bpftool prog dump xlated id 234
# output
0: (bf) r6 = r1
1: (07) r6 += 112
2: (bf) r1 = r10
3: (07) r1 += -8
4: (b7) r2 = 8
5: (bf) r3 = r6
6: (85) call bpf_probe_read#-51584”
将其与BCC 块 program ID 263对比: 其包括来自BTF的源信息, 例如 ; struct request *req = ctx->di;
bpftool prog dump xlated id 263
# output
int trace_req_done(struct pt_regs * ctx):
; struct request *req = ctx->di;
0: (79) r1 = *(u64 *)(r1 +112)
; struct request *req = ctx->di;
1: (7b) *(u64 *)(r10 -8) = r1
; tsp = bpf_map_lookup_elem((void *)bpf_pseudo_fd(1, -1), &req);
2: (18) r1 = map[id:158]
4: (bf) r2 = r10
;
5: (07) r2 += -8”
linum修饰符将包括源文件和行号信息,也来自BTF(如果有的话).其中行号信息是指BCC在运行程序时创建的虚拟文件
如下所示, 多了[file:/virtual/main.c line_num:42 line_col:29]
int trace_req_done(struct pt_regs * ctx):
; struct request *req = ctx->di; [file:/virtual/main.c line_num:42 line_col:29]
0: (79) r1 = *(u64 *)(r1 +112)”
opcodes修饰符将包含BPF指令操作码
; struct request *req = ctx->di;
0: (79) r1 = *(u64 *)(r1 +112)
79 11 70 00 00 00 00 00”
visual 修饰符,它以DOT格式发出控制流程图信息,以供外部软件可视化
bpftool prog dump xlated id 263 visual > biolatency_done.dot
# 使用GraphViz及其dot有向图工具
dot -Tpng -Elen=2.5 biolatency_done.dot -o biolatency_done.png
四、BPF API
1. BPF Helper Functions
详细信息可查看bpf.h文件
bpf_probe_read(): BPF中的内存访问仅限于BPF寄存器和堆栈(以及通过 helper 的BPF map)。 要读取任意内存,必须通过该方法进行读取,内存会执行安全检查。 它还可以在读取此任意内存时,禁用页面错误,以确保读取不会引起探针上下文的错误。除了读取内核内存外,该帮助程序还用于将用户空间内存读入内核空间。
2. BPF Program Types
部分 BPF map types
| bpf_map_type | 描述 |
|---|---|
| BPF_MAP_TYPE_HASH | 哈希表: 键/值对 |
| BPF_MAP_TYPE_PERCPU_HASH | 基于每个CPU维护的更快的哈希表 |
| BPF_MAP_TYPE_ARRAY | 元素数组 |
五、BPF并发控制
通过跟踪,并行线程可以并行查找和更新BPF map 字段,存在一个线程覆盖另一个线程的更新的问题,这也称为丢失更新问题,其中并发读写导致更新丢失。
BCC和bpftrace尽可能使用 per-CPU 哈希和数组 map 类型,以避免这种破坏。为每个CPU创建使用实例, 从而防止并行线程更新共享位置。 例如,可以将计数事件的映射更新为每个CPU的映射,然后可以在需要总计数时组合每个CPU的值。
示例: 以下bpftrace使用 per-CPU 哈希值进行计数:
strace -febpf bpftrace -e 'k:vfs_read { @ = count(); }'
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERCPU_HASH, key_size=8, value_size=8, max_entries=128, map_flags=0, inner_map_fd=0}, 72) = 3
[...]
以下bpftrace使用普通哈希进行计数:
strace -febpf bpftrace -e 'k:vfs_read { @++; }'
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=8, value_size=8, max_entries=128, map_flags=0, inner_map_fd=0}, 72) = 3
[...]
在8-CPU系统上同时使用它们,并跟踪一个频繁且可能并行运行的功能:
bpftrace -e 'k:vfs_read { @cpuhash = count(); @hash++; }'
Attaching 1 probe...
^C
# 结果表明, 普通哈希将事件计数降低了0.01%
@cpuhash: 1061370
@hash: 1061269
还存在其他方式进行并发控制, 详见原书P93
六、BPF 的限制
- BPF程序不能调用任意内核功能, 仅限于API中列出的BPF helper 程序功能
- BPF程序也不能执行循环,因为它们必须在一定时间内完成
- BPF堆栈大小限制为MAX_BPF_STACK,设置为512. 在开发工具时有时会遇到此限制,尤其是在堆栈上存储多个字符串缓冲区时: char[256]
- 解决方案是改为使用BPF映射存储, 而不是堆栈存储
- 指令数限制为4096,长BPF程序有时会遇到此限制
参考资料

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)