Spark 环境搭建 (hadoop之上)
1、前提是Hadoop环境已经搭建完成,ssh当然也已经配置完成,官网下载软件包:scala-2.11.0.tgzspark-2.1.0-bin-hadoop2.6.tgz使用了两台虚拟机master 和slave01,其中master是Hadoop的namenode节点所在,同时也配置了一个datanode,即:master担任主机、也担任一个从机,slave01担任一个从机,同
1、前提是Hadoop环境已经搭建完成,ssh当然也已经配置完成,官网下载软件包:
scala-2.11.0.tgz
spark-2.1.0-bin-hadoop2.6.tgz
使用了两台虚拟机master 和slave01,其中master是Hadoop的namenode节点所在,同时也配置了一个datanode,即:master担任主机、也担任一个从机,slave01担任一个从机,同时担任secondarynamenode ;
2、安装scala:
master上操作:
将scala-2.11.0.tgz 解压:
# tar xzvf scala-2.11.0.tgz
移动到想要安装的目录
# mv scala-2.11.0/ /usr/local/share/
环境配置
# vi /etc/profile
export SCALA_HOME=/usr/local/share/scala-2.11.0
export PATH=$SCALA_HOME/bin:$PATH
#source /etc/profile
测试scala:
安装成功!
slave01上操作:
# scp -r /usr/local/share/scala-2.11.0/ slave01:/usr/local/share/
环境配置
# vi /etc/profile
export SCALA_HOME=/usr/local/share/scala-2.11.0
export PATH=$SCALA_HOME/bin:$PATH
#source /etc/profile
测试scala:

安装成功!
3、安装spark
master上操作:
将spark-2.1.0-bin-hadoop2.6.tgz 解压
# tar xzvf spark-2.1.0-bin-hadoop2.6.tgz
我放置的路径: /usr/local/spark/
配置环境:
# vi /usr/local/spark/conf/spark-env.sh
添加(根据自己的实际环境添加):
export SPARK_HOME=/usr/local/spark
export JAVA_HOME=/usr/java/jdk1.7.0_79
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
SPARK_MASTER_HOST=192.168.126.137
#web页面端口
SPARK_MASTER_WEBUI_PORT=28686
#Spark的local目录
SPARK_LOCAL_DIRS=/usr/local/spark/tmp/local
#worker目录
SPARK_WORKER_DIR=/usr/local/spark/tmp/work
#Driver内存大小
SPARK_DRIVER_MEMORY=1G
#Worker的cpu核数
SPARK_WORKER_CORES=2
#worker内存大小
SPARK_WORKER_MEMORY=1g
#Spark的log日志目录
SPARK_LOG_DIR=/usr/local/spark/tmp/logs
# vi /usr/local/spark/conf/slaves
添加:
master
slave01
slave01上操作:
用scp 将spark文件放到slave01 上,和master上的配置、位置等都是一样的。
master上操作:
配置完成,启动spark:
# cd /usr/local/spark/
# ./sbin/start-all.sh
# jps
出现了master 和worker 进程,则成功~
去Web的UI上瞅瞅:
访问:http://master:28686 注意:端口是上面自己配置的~
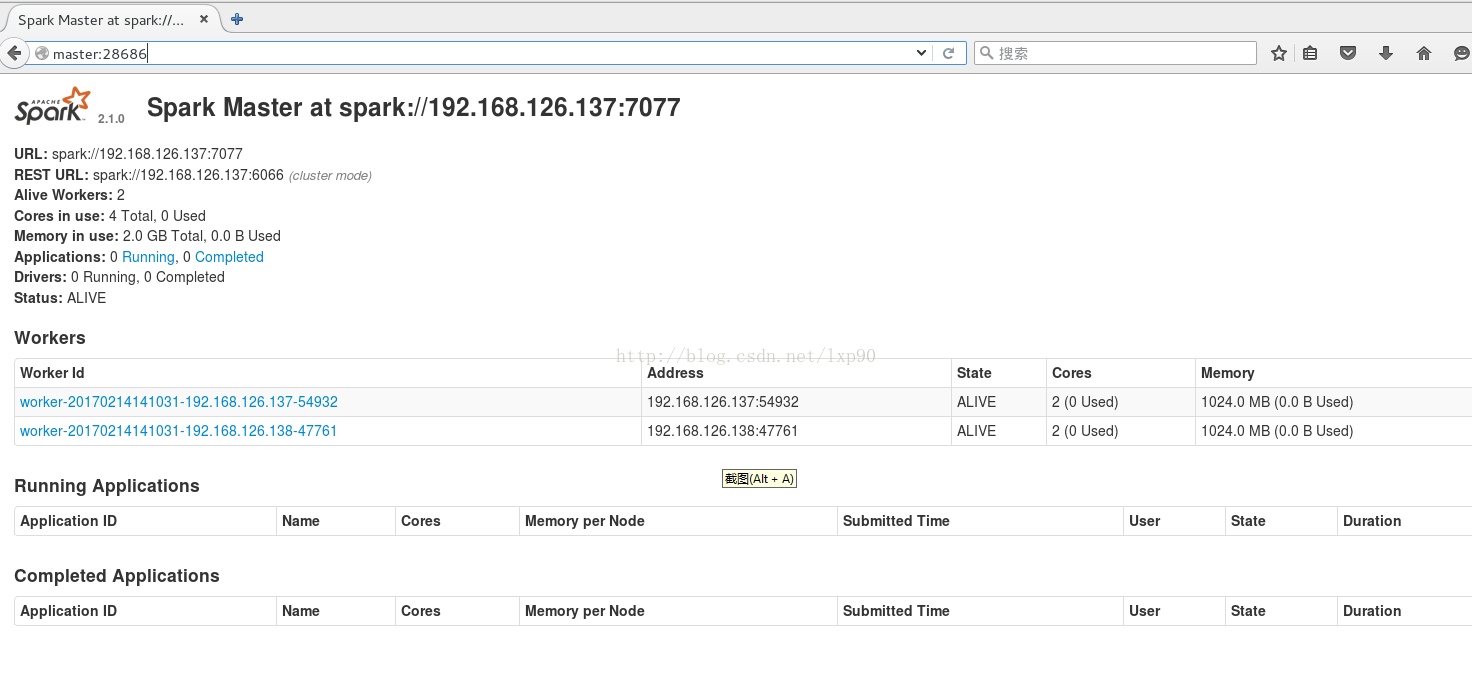
看,果然是有2个worker,
slave01上操作:
# jps
出现了worker 进程,则成功~
至此,spark配置成功~
当然,你也可以在 /etc/profile 中配置export SPARK_HOME= /usr/local/spark 之类的配置,来方便spark的操作。
4、Spark简单例子测试:
第3步之后,jps发现Spark的master和worker都成功了,但是没有Hadoop的一系列进程(namendoe、datanode……)
启动Hadoop
master上操作:
# /usr/local/hadoop/sbin/start-all.sh
# jps
结果如下
hadoop@master:/usr/local/spark> jps
14744 DataNode
17218 Jps
14986 ResourceManager
15107 NodeManager
14598 NameNode
15614 SparkSubmit
14146 Worker
14061 Master
slave01上操作:
#jps
结果如下:
hadoop@slave01:/usr/local/spark> jps
3884 SecondaryNameNode
3766 DataNode
3615 Worker
4155 NodeManager
5370 Jps
现在是Hadoop和Spark 模块都启动了,666~
开始运行简单实例(实例运行只需在master上操作了,slave01只是负责干活……):
1)向HDFS文件上放个文件:
# ./bin/hdfs dfs -put spda.data input
在HDFS上的文件路径是这样的:/user/hadoop/input
spda.data文件内容:
123
456
2)运行
# /usr/local/spark/bin/spark-shell
进入scala>
加载文件(文件在HDFS上,不是本机哟~~):
# scala> val infile=sc.textFile("/usr/local/spark/tmp/spda.data")
读取文件第一行:
# scala> infile.first()
结果:
scala> infile.first();
res2: String = 123()
简单来看,Spark是可以运行了~
行了,任道而重远,开始学习scala 吧~~~

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)