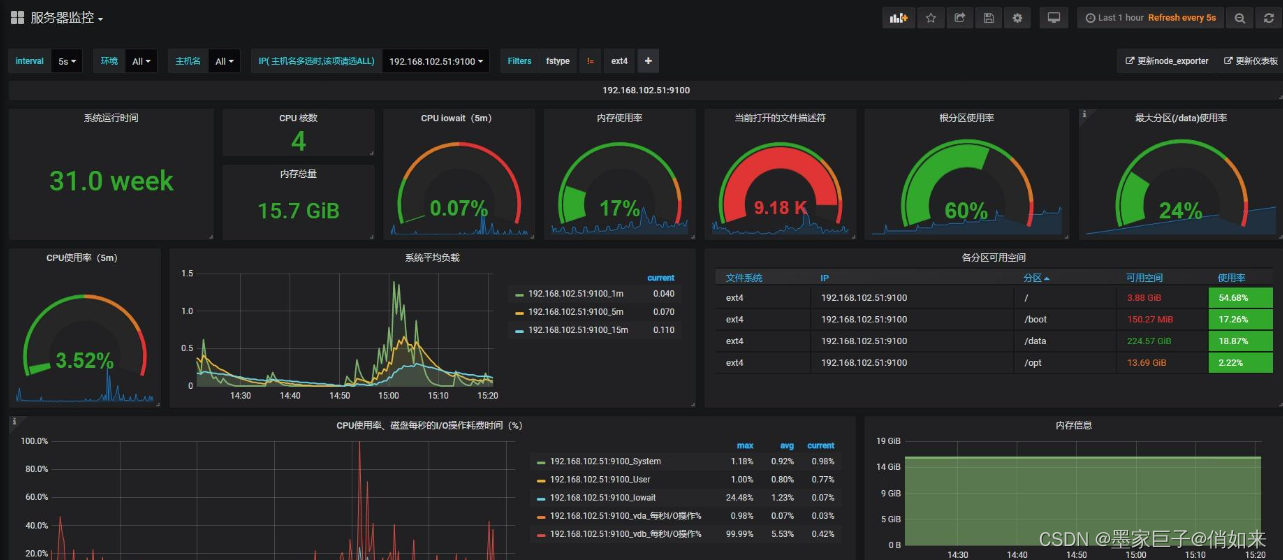
六.逼格拉满-Prometheus+Grafana微服务监控告警
微服务架构是一个分布式系统,由多个独立的服务组成,每个服务可能运行在不同的容器、虚拟机或物理机上,那么在生产环境中我们需要随时监控服务的状态,以应对各种突发情况,比如:内存爆满,CPU标高等等。Prometheus作为一种开源的监控和告警系统,天生就是为分布式系统设计的。它能够轻松地收集、存储和查询各个微服务的监控数据,为微服务架构提供全面的监控能力。Prometheus(普罗米修斯)是一个最初在
前言
微服务架构是一个分布式系统,由多个独立的服务组成,每个服务可能运行在不同的容器、虚拟机或物理机上,那么在生产环境中我们需要随时监控服务的状态,以应对各种突发情况,比如:内存爆满,CPU标高等等。Prometheus作为一种开源的监控和告警系统,天生就是为分布式系统设计的。它能够轻松地收集、存储和查询各个微服务的监控数据,为微服务架构提供全面的监控能力。

一.Prometheus概述
1.认识Prometheus
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。Prometheus有如下特点:
强大的数据收集和处理能力:Prometheus采用Pull模型从被监控目标中拉取指标数据,并且提供了多维度的数据模型和灵活的查询接口(PromQL)。这使得Prometheus能够轻松地收集和处理微服务中的各种监控数据,包括CPU、内存、网络、磁盘等系统级指标,以及应用程序级指标(如请求量、响应时间、错误率等)。
服务发现和动态配置:微服务架构中的服务是动态变化的,服务实例的创建、销毁和迁移是常态。Prometheus支持多种服务发现机制(如Kubernetes、Consul、Eureka等),能够自动发现新的被监控目标,并动态调整监控规则和告警配置。这使得Prometheus能够自动适应微服务架构的动态变化,确保监控的准确性和实时性。
告警和通知:Prometheus支持基于查询结果的告警规则配置,当满足特定条件时,会自动触发告警并发送通知。这对于微服务架构来说非常重要,因为微服务之间的依赖关系复杂,一旦某个服务出现故障,可能会影响到整个系统的稳定性。通过Prometheus的告警和通知功能,运维人员可以及时发现并处理故障,确保系统的稳定性和可用性。
可视化与仪表盘:Prometheus提供了内置的Web界面(Prometheus UI)来展示监控数据和仪表盘,同时还支持与第三方可视化工具(如Grafana)的集成。这使得运维人员可以直观地了解微服务的运行状态和性能指标,及时发现潜在问题并进行优化。
社区支持和扩展性:Prometheus是一个开源项目,拥有庞大的用户社区和活跃的开发者群体。这使得Prometheus具有强大的社区支持和扩展性,用户可以根据需求定制和扩展Prometheus的功能。同时,Prometheus也提供了丰富的插件和扩展接口,方便用户集成其他系统和工具,实现更全面的监控和管理。
2.Prometheus的架构
下面是Prometheus的架构图,Prometheus可以看做是一个数据采集中心,它需要去收集和存储数据,并通过UI展示出来,如下:

Prometheus的架构图通常展示了其核心组件以及它们之间的交互方式。以下是一个Prometheus架构图及其组件的解释:
- Prometheus Server:
这是Prometheus系统的核心组件,负责收集和存储时间序列数据。Prometheus Server会定期从配置的目标(targets)中拉取(pull)监控数据。
Prometheus Server还提供了一个HTTP API,允许用户查询存储的数据、配置告警规则等。Prometheus Server使用内置的时间序列数据库(TSDB)来存储监控数据,这使其具有高性能的写入和查询能力。 - Exporters:
Exporters是负责从各种服务和系统(如数据库、中间件、硬件等)中抓取监控数据的组件。它们将监控数据转换为Prometheus可以理解的格式(通常是文本格式),并通过HTTP接口暴露给Prometheus Server。
Prometheus提供了许多官方的Exporters,同时也支持第三方开发的Exporters。这些Exporters使得Prometheus能够监控各种类型的应用和服务。 - Pushgateway:
Pushgateway是Prometheus的一个组件,用于接收短期作业(如批处理任务)的监控数据。由于这些作业的生命周期较短,可能无法被Prometheus Server及时抓取到数据。因此,这些作业可以将数据推送到Pushgateway,然后由Prometheus Server从Pushgateway中拉取数据。
Pushgateway通常用于监控那些生命周期较短、或者网络位置不便于直接抓取的服务。 - Alertmanager:
Alertmanager负责处理Prometheus Server发送的告警通知。用户可以配置告警规则,当满足特定条件时,Prometheus Server会发送告警通知给Alertmanager。
Alertmanager会对告警通知进行去重、分组、路由和静默等操作,并通过各种方式(如邮件、Slack、Webhook等)将告警发送给相关人员。 - Web UI & Grafana:
Prometheus提供了一个内置的Web UI,用于展示监控数据和仪表盘。用户可以通过Web UI浏览监控数据、配置告警规则等。
同时,Prometheus也支持将监控数据集成到Grafana等第三方可视化工具中,提供更丰富的可视化效果和仪表盘定制能力。
二.Prometheus安装
我这里准备了2台机器,一个是作为Prometheus+Grafana的安装,一个是作为被监控的目标
172.168.120.150 : Prometheus
172.168.120.190 : 被监控主机
1.安装Docker
没有安装Docker的需要先安装Docker,
[root@root ~]# wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@root ~]# yum install docker-ce -y
[root@root ~]# systemctl start docker
[root@root ~]# systemctl enable docker
2.准备工作目录
mkdir /opt/prometheus
创建一个目录,后续容器映射的相关文件将会在放到该目录中
3.创建配置文件
普罗米修斯的配置是通过yaml来配置的,我们在工作目录中创建配置文件。配置文件参考官网:https://prometheus.io/docs/prometheus/latest/getting_started/
vi /opt/prometheus/prometheus.yml
global:
scrape_interval: 15s #15s抓取一次目标数据
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus #一个监控目标配置一个 job_name,这里在监控prometheus 自己
scrape_interval: 5s #5s一次数据抓取
static_configs:
- targets: ['localhost:9090'] #监控目标主机,监控prometheus 自己
labels:
instance: prometheus #给监控目标制定标签名
注意:上面主要配置了一下监控的目标主机:9090是prometheus容器的端口,9100是grafana的端口。我这里打算把prometheus安装到一起,如果不是本机安装那么需要把localhost改成对应的机器IP
4.安装Prometheus容器
官方安装文档:https://prometheus.io/docs/prometheus/latest/installation/
docker run --name=prometheus -d \
-p 9090:9090 \
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
启动好容器之后,可以通过:192.168.112.30:9090 访问prometheus ,在菜单:status - Targets 中可以看到监控的目标

注意:如果出现了警告提示 需要在服务器更正时间:ntpdate ntp.aliyun.com

三.Grafana 安装
Grafana是一款开源的数据可视化和监控平台。它主要用于时序数据的监控,能够将复杂的数据转化为易于理解的图表和仪表盘,并在一个界面中集中展示多个数据源的数据。
Grafana支持多种数据源,包括时序数据库、关系型数据库、日志文件等,用户可以方便地从不同数据源中查询和聚合数据。同时,它提供了丰富的图表和面板,可以将数据以直观的方式展示出来,帮助用户更好地理解数据。
Grafana还具备实时监控和告警功能,能够实时了解系统状态、性能等指标的变化情况,并在达到预设阈值时发送通知,提醒用户关注和处理。此外,Grafana支持插件式的开发模式,用户可以通过插件扩展功能,满足自己的特定需求。
总之,Grafana是一个功能强大的数据可视化工具,可以帮助用户实时监控和分析数据,提高数据分析效率和工作效率。

1.创建挂载数据目录
mkdir /opt/grafana-storage
设置目录权限,因为这个文件需要写入所以要给一定的权限,这里为了方便测试给777,具体权限要根据具体实际情况而定。
chmod 777 -R /opt/grafana-storage
2.启动Grafana容器
需要制定-v目录映射,Grafana的端口是3000
docker run -d \
-p 3000:3000 \
--name=grafana \
-v /opt/grafana-storage:/var/lib/grafana \
grafana/grafana
安装好之后,通过 3000端口访问,账号密码都是admin ,第一个登录会要求修改密码 ,登录成功之后,如下:

3.配置Grafana 数据源
登录之后,找到 Data Source ,给Grafana添加数据源 。大概意思就是 Grafana要从Prometheus中获取数据用来做图表展示,所以需要把Prometheus作为 Data Source配置给Grafana

点击 add datasource 按钮添加数据源。 然后在添加面板中指定 Prometheus 的URL,然后点击下面的 Save 保存,如下

四.监控Docker
接下来是对目标主机做监控,通常情况下我们有Linux监控 和 Docker监控两种方式,Docker监控我们可以使用cAdvisor:用于收集正在运行的容器资源使用和性能信息。的,他会把数据采集到Prometheus中,Grafana再从Prometheus抓取数据做展示,官方文档:https://github.com/google/cadvisor
1.在目标主机安装cadvisor
注意:我是在另外一台【ip :172.168.120.190】机器上安装的
docker run -d \
-v /:/rootfs:ro \
-v /var/run:/var/run:ro \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
-v /dev/disk/:/dev/disk:ro \
-p 9200:8080 \
--name=cadvisor \
google/cadvisor
通过访问9200端口即可看到cadvisor的界面,但是它的界面并不友好,且cadvisor只有数据采集能力,没有数据存储能力,我们还是需要把数据交给Prometheus去存储

2.Prometheus监控cadvisor
cadvisor通过目录映射的方式拿到容器的监控信息,端口是9200,然后Prometheus需要从cadvisor中拿到数据。接下来配置Prometheus,在Prometheus机器上修改配置文件,增加对cadvisor的监控
vi /opt/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: docker #增加对目标主机的监控
scrape_interval: 5s
static_configs:
- targets: ['172.168.120.190:9200'] #目标主机的地址和端口
labels:
instance: docker
修改完配置后需要重启prometheus : docker restart prometheus
3.通过Grafana监控Docker主机
现在我们在190机器上安装了cadvisor,他会负责采集Docker主机的数据,然后prometheus 会从cadvisor中pull数据,那么我们需要在Grafana可视化界面中添加pannel来展示数据

我们可以在 create 菜单中,自己去创建Panel来展示数据,但是自己去添加挺麻烦的,Grafana内置了一些监控模板。找到:import 菜单点击进去
这里我们可以输入模板的下载地址,或者模板的编号ID,比如:
- Docker主机监控模板 :193
- Lingux主机监控模板 :9276
在输入框中输入:193,然后点击load,界面效果如下:

这里指定监控的名字,下面选择 Prometheus ,然后点击import导入,效果如下:

面板中可以看到容器情况,CPU情况,内存情况,网络情况等
五.监控Linux
接下来是对目标主机做监控,通常情况下我们有Linux监控 和 Docker监控两种方式,Linux监控我们可以使用node_exporter:node_exporter是用于监控Linux系统的指标采集器,他会把数据采集到Prometheus中,Grafana再从Prometheus抓取数据做展示,官方文档:https://prometheus.io/docs/guides/node-exporter/
1.安装node-exporter
下载安装包:https://github.com/prometheus/node_exporter/releases,通过下面命令直接下载
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
下载成功后需要解压
tar -zxvf node_exporter-1.7.0.linux-amd64.tar.gz
mv node_exporter-1.7.0.linux-amd64 /usr/local/node_exporter
2.安装node_expoter服务
将node_expoter部署到被监控端,并配置为系统服务管理:
# vi /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
[Service]
ExecStart=/usr/local/node_exporter/node_exporter
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
创建好服务之后就可以启动服务了
systemctl daemon-reload
systemctl start node_exporter
# systemctl enable node_exporter
启动成功之后,可以通过:ps -ef | grep node 来查看是否启动成功

通过浏览器访问:172.168.120.190:9100 ,如果访问不成功可能是防火墙问题,可以通过:systemctl stop firewalld 暂时关闭防火墙,或者直接开放端口firewall-cmd --zone=public --add-port=9100/tcp --permanent

3.配置Prometheus
接下来配置Prometheus,在Prometheus机器上修改配置文件,增加对NodeExporter的监控
vi /opt/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: docker #增加对目标主机的监控
scrape_interval: 5s
static_configs:
- targets: ['172.168.120.190:9200'] #目标主机的地址和端口
labels:
instance: docker
- job_name: linux #增加对目标主机的监控
scrape_interval: 5s
static_configs:
- targets: ['172.168.120.190:9100'] #目标主机的地址和端口
labels:
instance: linux
修改之后使用 docker restart prometheus 重启,然后再Grafana左边菜单 import中去导入 9276图表模板:成功导入后效果如下

如果某些图标没数据,那是因为收集数据的表达式中的属性名没有对上,比如可以点中图表右键编辑。比如:网卡名是 enp0s3(通过:ifconfig查看) ,而默认 $inc 所以出不来数据,修改保存即可

六.设置告警
当我们的设备指标过高,比如:cpu标高到90%以上我们可以通过Grafana触发报警,然后通过邮件,webhook或其他方式,给管理员告警,管理员可以及时进行抢修。
1.Grafana配置邮件
如果要实现邮件报警就需要有发送邮件的邮箱 和 接受邮件的邮箱,下面我使用QQ邮箱来测试,登录QQ邮箱后找到 设置 - 账号 - 找到 POP3/IMAP/SMTP … 邮件服务,然后去开通smtp服务功能,开通过后会得到一个授权码,是一个随机字符串。

然后我们需要把该发送放邮箱配置给grafana,因为是docker启动的,所以我这里把配置文件拷贝出来修改
Grafnan的配置文件在容器中的这个位置/etc/grafana/grafana.ini,把容器中的配置文件拷贝出来方便修改
docker cp grafana:/etc/grafana/grafana.ini ./
编辑配置文件vi grafana.ini,修改smtp邮箱配置,你需要把对应的内容修改为你自己的哦
[smtp]
enabled = true
host = smtp.qq.com:587
user = xxxx@qq.com
password = 邮箱你的授权码
;cert_file =
;key_file =
;skip_verify = false
from_address = xxxx@qq.com
from_name = Grafana
ehlo_identity =
startTLS_policy =
[emails]
welcome_email_on_sign_up = true
templates_pattern = emails/*.html, emails/*.txt
content_types = text/html
把配置文件拷贝进去 docker cp grafana.ini grafana:/etc/grafana , 然后重启 docker restart grafana 。 重启成功后,进入到Grafana界面 - 找到setting - 查看邮件是否配置成功

2.配置告警规则
我们首先找到监控面板,比如我要对CPU做告警监控,点击标题右键 - Edit编辑

在编辑页面 - 下方 - 有一个 alert 菜单,去创建一个Alert 如下

第一步:填写好 rule name ; floder 可以自定义一个然后create 如下:

第二步:设置预警值:在项目 A 点击 run queries可以显示CPU的监控数据,然后在 B(有可能不是B)项目中When的地方选择预警条件: when(当) , last(最后一次数据) , is Above (超过某个值),然后图标中会出现一个红色的线条就是预警值了。

第三步:设置告警条件 , 往下滚动在Define alert conditions , 下面的含义是:每隔1分钟做一次检测,如果持续5分钟都超过告警值就会触发告警。

设置好之后,点击右上角的保存按钮:
3.设置告警接受邮箱
设置了alert告警规则后在 alert 菜单中可以看到告警规则

我们点击Contact points配置联系人,也就是邮件接受者,点击 new Contact points

这里需要填写name, Contact point type 选择 email即可,这个地方可以选择多种报警方式,比如:wehook,钉钉等。
然后填写好收件人邮箱,右边点击 test 测试 。 如果能发送就点击save即可。

那么当CPU的使用率达到了 我们设置的阈值机会自动告警并且触发邮件发送。效果如下

文章结束,如果对你有帮助请给好评哦

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 27
27 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)