VMWare虚拟机安装CentOS 7 Linux及Hadoop与Eclipse学习环境(2-伪分布模式hadoop环境)
伪分布模式hadoop环境安装、配置练习笔记。
3. 安装Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。[
3.1. 安装环境
操作系统:CentOS 7 (VMWare虚拟机)
JDK: 1.7(详见博客[1])
IP:192.168.184.139 (详见3.1.1章节配置)
主机名:hadoop_master (详见3.1.2章节配置)
安装用户:hadoop(如果安装时未设置用户,需要单独新建hadoop用户)
3.1.1. 虚拟机(NAT网络)设置静态IP
Centos7默认是不启用有线网卡的,需要手动开启。
首先,打开终端,进入 /etc/sysconfig/network-scripts/目录,查看结果如下:

其中,ifcfg-eno16777736文件就是需要配置的网卡文件。
切换到root用户,修改此文件中ONBOOT参数,由no改成yes。
[hadoop@localhost network-scripts]$ su root
密码:
[root@localhost network-scripts]# vi ifcfg-eno16777736修改结果如下:
TYPE=Ethernet
BOOTPROTO=dhcp
......
NAME=eno16777736
UUID=f9c01566-03da-42ea-9a26-aeb5bf12b7fc
DEVICE=eno16777736
ONBOOT=yes[hadoop@localhost ~]$ ifconfig
eno16777736: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.184.139 netmask 255.255.255.0 broadcast 192.168.184.255
inet6 fe80::20c:29ff:fe98:ac1f prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:98:ac:1f txqueuelen 1000 (Ethernet)
......
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 0 (Local Loopback)
......
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:68:da:27 txqueuelen 0 (Ethernet)
......
上述内容中,”eno16777736“是虚拟机网卡名称,”virbr0“则是对应的默认网关及IP地址。
再次修改配置文件ifcfg-eno16777736,设置为静态IP地址,其中BOOTPROTO由dhcp改为static,同时注释掉IPV6项目,增加IPADDR、NETMASK、GATEWAY、DNS1的设置项目,仍使用vi编辑器进行配置。
[root@localhost network-scripts]# vi ifcfg-eno16777736设置结果如下所示。
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
#IPV6INIT=yes
#IPV6_AUTOCONF=yes
#IPV6_DEFROUTE=yes
#IPV6_PEERDNS=yes
#IPV6_PEERROUTES=yes
#IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=f9c01566-03da-42ea-9a26-aeb5bf12b7fc
DEVICE=eno16777736
ONBOOT=yes
IPADDR=192.168.184.139
NETMASK=255.255.255.0
GATEWAY=192.168.184.2
DNS1=192.168.184.2注意:要配置DNS1,与默认网关一致就可以,CentOS的默认网关一般是X.X.X.2。
重启网络服务。
[root@localhost etc]# service network restart3.1.2. 修改主机名和网络别名
把centos的网络配置文件,/etc/sysconfig/network 把hostname栏目修改
[root@bogon hadoop]# vim /etc/hostname
hadoop_master #修改localhost.localdomain为hadoop_master#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.184.139 hadoop_master3.2. 安装Hadoop
首先以hadoop用户登录系统,进入/home/hadoop目录,拷贝hadoop-2.7.3.tar.gz文件到此目录中。
[hadoop@localhost ~]$ cd /home/hadoop
[hadoop@localhost ~]$ mv /mnt/hgfs/dev/hadoop-2.7.3.tar.gz hadoop-2.7.3.tar.gz
[hadoop@localhost ~]$ ls
hadoop-2.7.3.tar.gz 公共 视频 文档 音乐 模板 图片 下载 桌面在此目录(/home/hadoop)解压hadoop-2.7.3.tar.gz文件。
[hadoop@localhost ~]$ tar -zvxf hadoop-2.7.3.tar.gz
[hadoop@localhost ~]$ ls
hadoop-2.7.3 公共 视频 文档 音乐
hadoop-2.7.3.tar.gz 模板 图片 下载 桌面解压后出现 hadoop-2.7.3 目录,其中,/home/hadoop/hadoop-2.7.3 以后就是hadoop的主目录了,hadoop相关文档中,如果没有注明绝对路径,那起始位置就是这里。
3.2.1. SSH无密码互信
ssh的无密码登陆是使得hadoop集群中的各个节点可以安全方便的通信,两个要点:一个是安全,这个是首要;另外一个是方便,可以不用每次操作都输入密码。
[root@hadoop_master ~]# su root
[root@hadoop_master ~]#
[root@hadoop_master ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
1e:ed:76:fb:27:dd:40:c8:24:e2:12:8f:e2:ed:08:69 root@hadoop_master
The key's randomart image is:
+--[ DSA 1024]----+
| |
| . . . . |
| = . + . |
| . o o. o . |
| o o .S . . |
| E . .. o . |
| . . o . o . o.|
| . . . . .. +|
| ...o |
+-----------------+
[root@hadoop_master ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys验证ssh,# ssh localhost ,不需要输入密码即可登录。
[root@hadoop_master ~]# ssh localhost
Last login: Tue Nov 22 22:42:50 20163.2.2. 配置环境变量
查看hadoop目录,结构如下:
[hadoop@hadoop_master hadoop-2.7.3]$ ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
修改.bash_profile配置
[hadoop@hadoop_master ~]$ pwd
/home/hadoop
[hadoop@hadoop_master ~]$ vim .bash_profile# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3 #根据实际情况配置
export PATH=$PATH:$HADOOP_HOME/bin #根据实际情况配置
export PATH配置hadoop-env.sh
[hadoop@hadoop_master hadoop-2.7.3]$ pwd
/home/hadoop/hadoop-2.7.3
[hadoop@hadoop_master hadoop-2.7.3]$ vim etc/hadoop/hadoop-env.sh#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera/3.2.3. 配置伪分布模式Hadoop
配置hadoop,需要配置core-site.xml[2]、hdfs-site.xml、mapred-site.xml文件,这些文件在/home/hadoop/hadoop-2.7.3/etc/hadoop/目录下。
3.2.3.1. 配置HDFS(hdfs-site.xml)
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。
[hadoop@hadoop_master hadoop-2.7.3]$ pwd
/home/hadoop/hadoop-2.7.3
[hadoop@hadoop_master hadoop-2.7.3]$ vim etc/hadoop/hdfs-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
......
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> 其中<property> 是补充定义内容,参数dfs.replication,设置数据块的复制次数,默认是3,如果slave节点数少于3,则写成相应的1或者2
3.2.3.2. 配置FS文件系统(core-site.xml)
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
......
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>这里的值指的是默认的HDFS路径。
3.2.3.3. 配置MapReduce工作
配置etc/hadoop/mapred-site.xml文件:
[hadoop@hadoop_master hadoop-2.7.3]$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[hadoop@hadoop_master hadoop-2.7.3]$ vim etc/hadoop/mapred-site.xml<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
......
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置etc/hadoop/yarn-site.xml文件:
[hadoop@hadoop_master hadoop-2.7.3]$ vim etc/hadoop/yarn-site.xml<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
......
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>3.3. 运行hadoop
3.3.1. input
新建input文件夹,用于存放需要统计的文本。
[hadoop@hadoop_master hadoop-2.7.3]$ pwd
/home/hadoop/hadoop-2.7.3
[hadoop@hadoop_master hadoop-2.7.3]$ mkdir input
[hadoop@hadoop_master hadoop-2.7.3]$ cp etc/hadoop/*.xml input3.3.2. 运行伪分布式hadoop
执行hadoop之前要对namenode进行格式化操作 bin/hdfs namenode -format
[hadoop@hadoop_master hadoop-2.7.3]$ bin/hdfs namenode -format
16/11/23 14:21:31 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop_master/192.168.184.139
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.3
STARTUP_MSG: classpath = /home/hadoop/hadoop-2.7.3/etc/hadoop:/home/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar
...
3.3.3. 启动hadoop
首先检查ssh localhost,如果需要密码,则运行无密码SSH命令:$ ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa
[hadoop@hadoop_master ~]$ ssh localhost
hadoop@localhost's password:
Last login: Wed Nov 23 14:36:41 2016 from localhost
[hadoop@hadoop_master ~]$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
3e:65:9d:ef:fc:6d:4c:92:9b:6a:9d:68:17:cc:97:7a hadoop@hadoop_master
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| |
| . . |
| S o oo ..|
| . o .*.o|
| o ooX |
| . ++*E+|
| o.o+oo|
+-----------------+
[hadoop@hadoop_master ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@hadoop_master ~]$ chmod 0600 ~/.ssh/authorized_keys
[hadoop@hadoop_master ~]$
执行start程序 sbin/start-all.sh
停止的话,输入命令,sbin/stop-all.sh
3.3.3.1. 启动dfs
执行start程序sbin/start-dfs.sh(dfs):
[hadoop@hadoop_master hadoop-2.7.3]$ sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-hadoop_master.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-hadoop_master.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-hadoop_master.out设置HDFS目录执行MapReduce任务(Make the HDFS directories required to execute MapReduce jobs)。
[hadoop@hadoop_master hadoop-2.7.3]$ bin/hdfs dfs -mkdir /user
[hadoop@hadoop_master hadoop-2.7.3]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@hadoop_master hadoop-2.7.3]$ bin/hdfs dfs -put etc/hadoop input3.3.3.2. 启动yarn
执行启动sbin/start-yarn.sh(mapreduce):
[hadoop@hadoop_master hadoop-2.7.3]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-hadoop_master.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-hadoop_master.out3.3.4. 验证服务
3.3.4.1. 验证DFS服务
通过浏览器检查服务运行情况:http://localhost:50070/
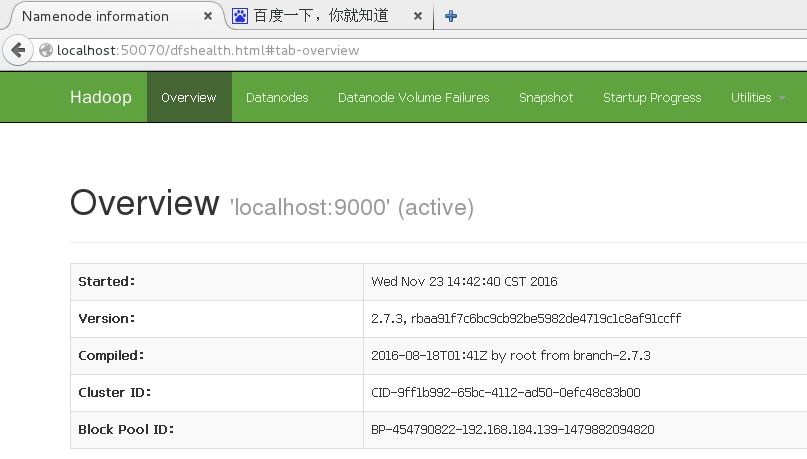
停止服务:$ sbin/stop-dfs.sh
停止虚拟机防火墙,$ systemctl stop firewalld,则在宿主机上,可以查看服务状态,http://192.168.184.139:50070/。
[hadoop@hadoop_master hadoop-2.7.3]$ systemctl stop firewalld
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
3.3.4.2. 验证Mapreduce服务
通过浏览器检查服务运行情况:http://localhost:8088/
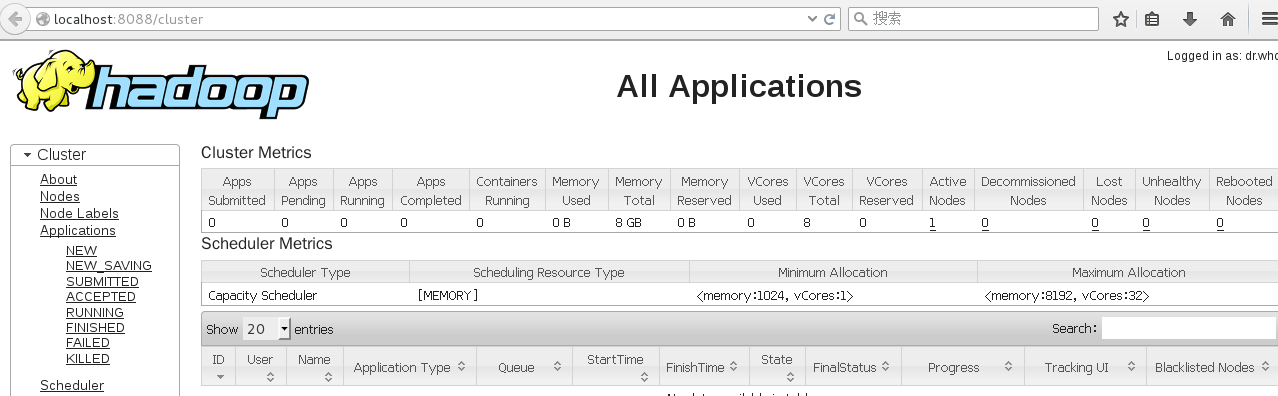
3.3.5. 停止服务
(1)停止dfs:
[hadoop@hadoop_master hadoop-2.7.3]$ sbin/stop-dfs.sh
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
(2)停止Mapreduce:
待续……
参考:
[1].VMWare虚拟机安装CentOS 7 Linux及Hadoop与Eclipse学习环境(1-虚拟机) 肖永威 2016.11

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)